Не е ли страхотно да имате налична нова версия на SQL Server? Това е нещо, което се случва само на всеки няколко години и този месец видяхме, че един достигна Обща наличност. (Добре, знам, че получаваме нова версия на SQL база данни в Azure почти непрекъснато, но смятам това за различно.) Признавайки тази нова версия, този месец T-SQL вторник (домакин от Michael Swart – @mjswart) е по темата за всичко SQL Server 2016!
Не е ли страхотно да имате налична нова версия на SQL Server? Това е нещо, което се случва само на всеки няколко години и този месец видяхме, че един достигна Обща наличност. (Добре, знам, че получаваме нова версия на SQL база данни в Azure почти непрекъснато, но смятам това за различно.) Признавайки тази нова версия, този месец T-SQL вторник (домакин от Michael Swart – @mjswart) е по темата за всичко SQL Server 2016!
Така че днес искам да разгледам функцията Temporal Tables на SQL 2016 и да разгледам някои ситуации на плана на заявки, които може да видите. Обичам Temporal Tables, но попаднах на малко затруднение, за което може да искате да сте наясно.
Сега, въпреки факта, че SQL Server 2016 вече е в RTM, аз използвам AdventureWorks2016CTP3, който можете да изтеглите тук – но не изтегляйте просто AdventureWorks2016CTP3.bak , също вземете SQLServer2016CTP3Samples.zip от същия сайт.
Виждате ли, в архива на примерите има някои полезни скриптове за изпробване на нови функции, включително някои за Temporal Tables. Печеливша е – можете да изпробвате куп нови функции и не е нужно да повтарям толкова много скрипт в тази публикация. Както и да е, отидете и вземете двата скрипта за Temporal Tables, изпълнявайки AW 2016 CTP3 Temporal Setup.sql , последвано от Temporal System-Versioning Sample.sql .
Тези скриптове създават времеви версии на няколко таблици, включително HumanResources.Employee . Той създава HumanResources.Employee_Temporal (въпреки че технически можеше да се нарече както и да е). В края на CREATE TABLE изявление, се появява този бит, добавяйки две скрити колони, които да се използват, за да се посочи кога редът е валиден и показва, че трябва да се създаде таблица, наречена HumanResources.Employee_Temporal_History за да съхранявате старите версии.
... ValidFrom datetime2(7) ГЕНЕРИРАНО ВИНАГИ КАТО РЕД НАЧАЛО СКРИТ, НЕ НУЛЕН, ValidTo datetime2(7) ГЕНЕРИРАНО ВИНАГИ КАТО РЕД КРАЙ СКРИТ, НЕ НУЛЕН, ПЕРИОД ЗА SYSTEM_TIME (ValidFrom, ValidHLE SYSTEMWI_TO) =[Човешки ресурси].[Employee_Temporal_History]));
Това, което искам да проуча в тази публикация, е какво се случва с плановете за заявки, когато се използва историята.
Ако направя заявка в таблицата, за да видя последния ред за конкретен BusinessEntityID , получавам търсене на клъстериран индекс, както се очаква.
ИЗБЕРЕТЕ e.BusinessEntityID, e.ValidFrom, e.ValidToFROM HumanResources.Employee_Temporal КАТО eWHERE e.BusinessEntityID =4;
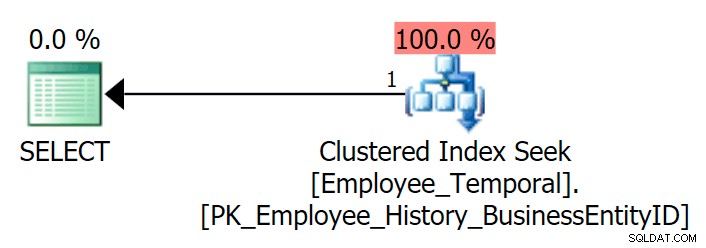
Сигурен съм, че мога да направя заявка за тази таблица, използвайки други индекси, ако има такива. Но в този случай не става. Нека създадем такъв.
СЪЗДАЙТЕ УНИКАЛЕН ИНДЕКС rf_ix_Login на HumanResources.Employee_Temporal(LoginID);
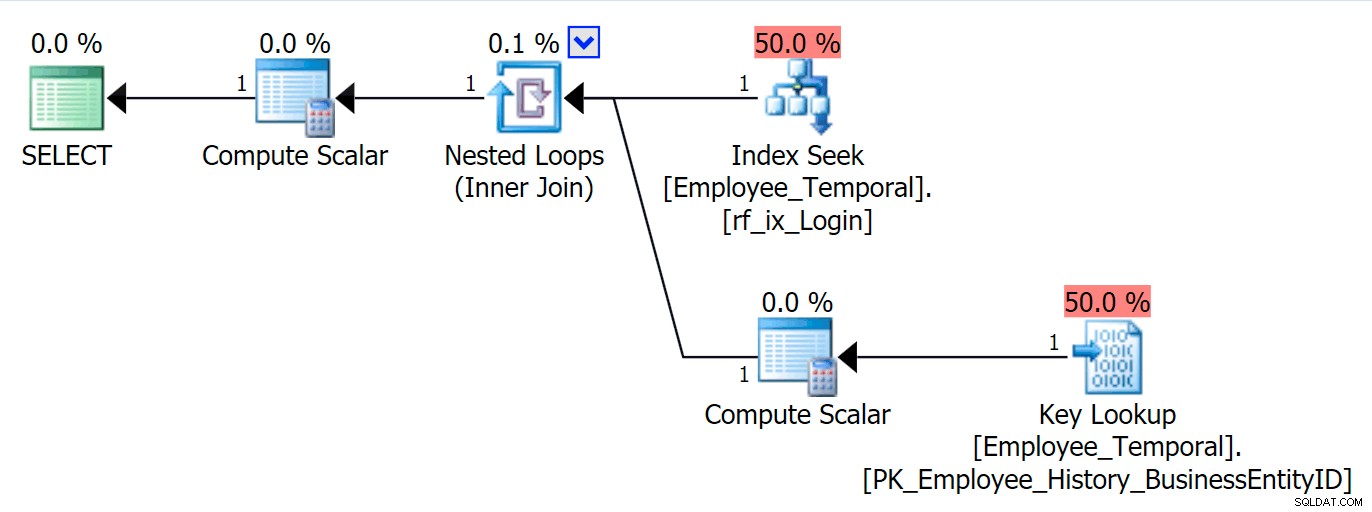
Сега мога да направя заявка за таблицата чрез LoginID , и ще видя Key Lookup, ако поискам колони, различни от Loginid или BusinessEntityID . Нищо от това не е изненадващо.
SELECT * FROM HumanResources.Employee_Temporal eWHERE e.LoginID =N'adventure-works\rob0';
Нека използваме SQL Server Management Studio за минута и да разгледаме как изглежда тази таблица в Object Explorer.

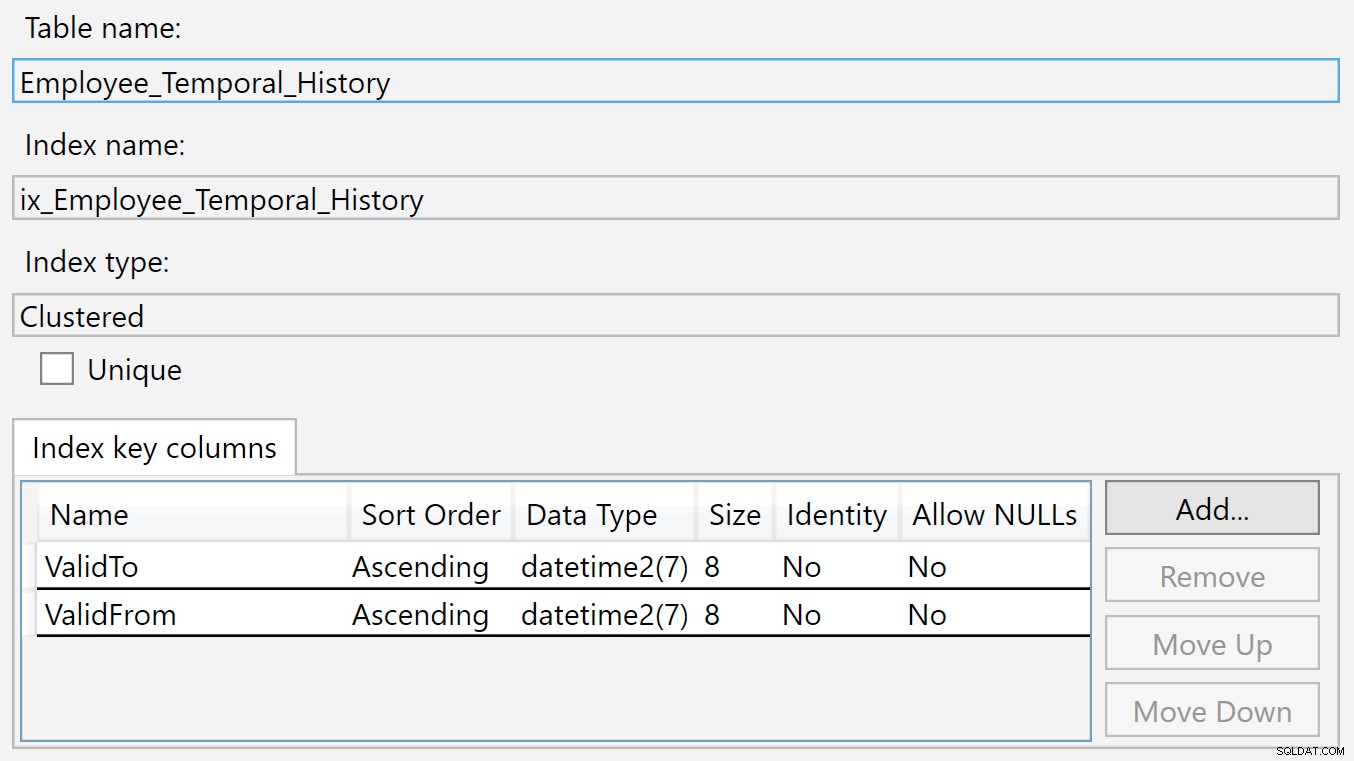
Можем да видим таблицата с история, спомената под HumanResources.Employee_Temporal , както и колоните и индексите както от самата таблица, така и от таблицата с историята. Но докато индексите на правилната таблица са първичният ключ (на BusinessEntityID ) и индекса, който току-що създадох, таблицата История няма съответстващи индекси.
Индексът на таблицата с история е на ValidTo и ValidFrom . Можем да щракнем с десния бутон върху индекса и да изберем Properties и виждаме този диалогов прозорец:
Нов ред се вмъква в тази таблица с история, когато вече не е валиден в основната таблица, защото току-що е бил изтрит или променен. Стойностите в ValidTo колоната естествено се попълват с текущото време, така че ValidTo действа като възходящ ключ, като колона за идентичност, така че нови вмъквания се появяват в края на структурата на b-дърво.
Но как действа това, когато искате да направите заявка към таблицата?
Ако искаме да запитаме нашата таблица за това, което е било актуално в определен момент от време, тогава трябва да използваме структура на заявка като:
ИЗБЕРЕТЕ * ОТ HumanResources.Employee_TemporalFOR SYSTEM_TIME ОТ '20160612 11:22';
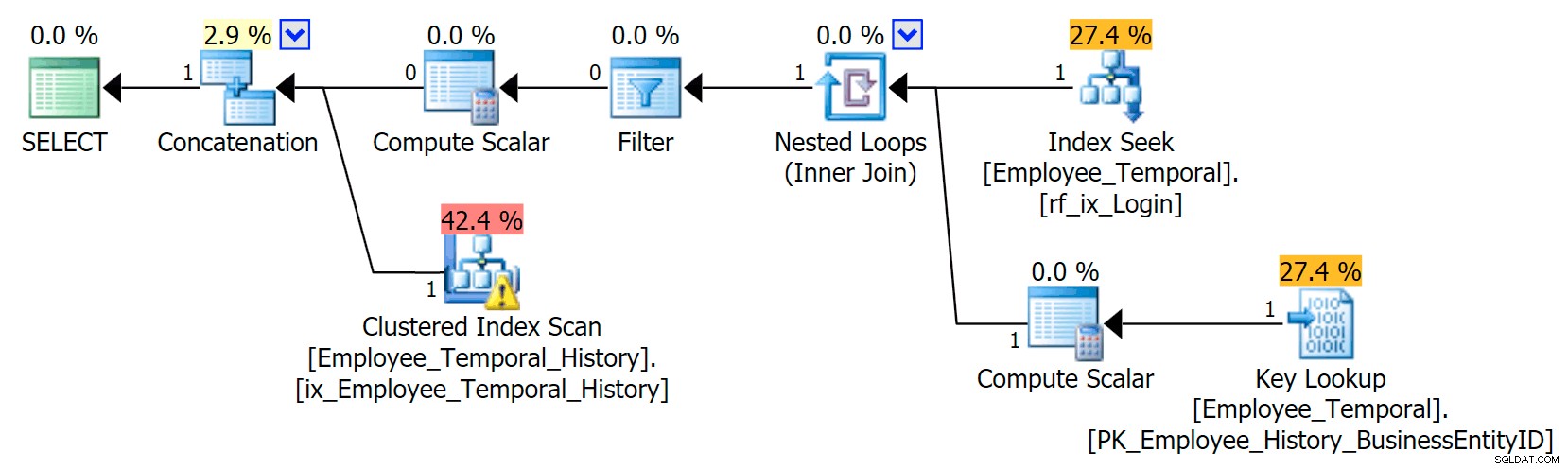
Тази заявка трябва да конкатенира съответните редове от основната таблица със съответните редове от таблицата на историята.
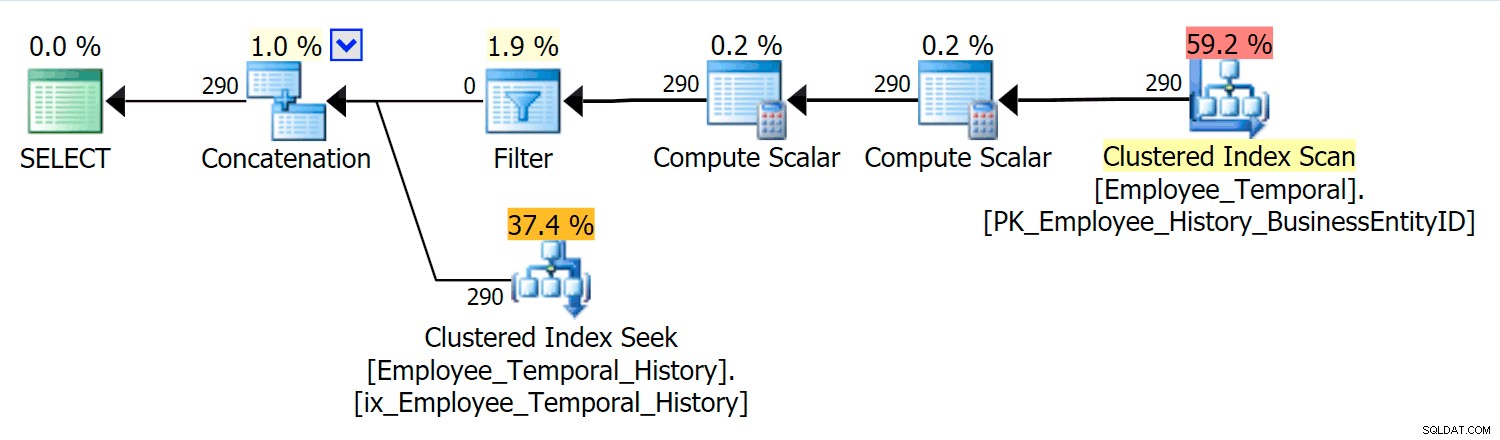
В този сценарий редовете, които бяха валидни за момента, който избрах, бяха всички от таблицата с историята, но въпреки това виждаме клъстерирано индексно сканиране срещу основната таблица, което беше филтрирано от оператор за филтриране. Предикатът на този филтър е:
[HumanResources].[Employee_Temporal].[ValidFrom] <='2016-06-12 11:22:00.0000000' И [HumanResources].[Employee_Temporal].[ValidTo]> '1:2012 :00,0000000'
Нека да разгледаме това след малко.
Клъстеризираното търсене на индекс в таблицата История трябва ясно да използва предикат за търсене на ValidTo. Началото на сканирането на диапазона на търсенето е HumanResources.Employee_Temporal_History.ValidTo > Скаларен оператор('2016-06-12 11:22:00') , но няма край, защото всеки ред има ValidTo след времето, което ни интересува, е ред кандидат и трябва да бъде тестван за подходящ ValidFrom стойност от остатъчния предикат, който е HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Сега интервалите са трудни за индексиране; това е известно нещо, което е обсъждано в много блогове. Най-ефективните решения разглеждат креативни начини за писане на заявки, но такива интелигентни решения не са вградени във времевите таблици. Можете обаче да поставите индекси и на други колони, като например на ValidFrom, или дори да имате индекси, които съответстват на типовете заявки, които може да имате в основната таблица. С клъстериран индекс, който е съставен ключ и на ValidTo и ValidFrom , тези две колони се включват във всяка друга колона, предоставяйки добра възможност за тестване на остатъчни предикати.
Ако знам кой логинид ме интересува, планът ми има различна форма.
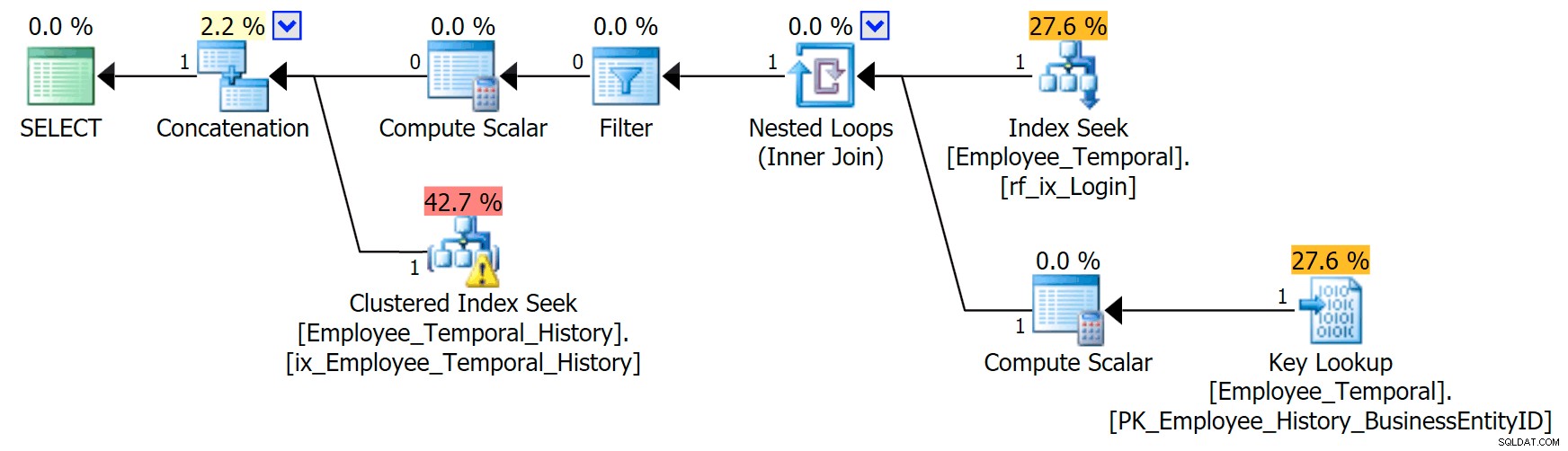
Горният клон на оператора за конкатенация изглежда подобен на преди, въпреки че този филтър оператор е влязъл в битката, за да премахне всички редове, които не са валидни, но търсенето на клъстериран индекс в долния клон има предупреждение. Това е предупреждение за остатъчен предикат, като примерите в по-ранна моя публикация. Той може да филтрира до записи, които са валидни до определен момент след времето, което ни интересува, но остатъчният предикат сега филтрира до LoginID както и ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <='2016-06-12 11:22:00.0000000' И [HumanResources].[Employee_Temporal_History =].[LoginID0'].[LoginID0] /предварително>Промените в редовете на rob0 ще бъдат малка част от редовете в историята. Тази колона няма да е уникална, както в основната таблица, тъй като редът може да е променян няколко пъти, но все още има добър кандидат за индексиране.
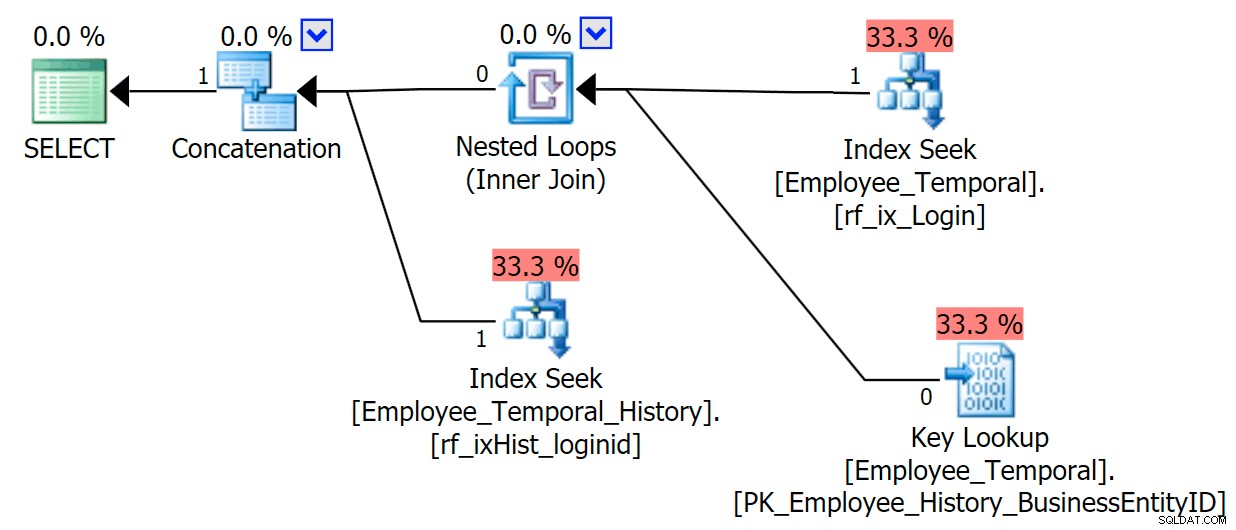
СЪЗДАВАЙТЕ ИНДЕКС rf_ixHist_loginidON HumanResources.Employee_Temporal_History(LoginID);Този нов индекс има забележимо влияние върху нашия план.
Вече промени нашето търсене на клъстериран индекс в сканиране на клъстериран индекс!!
Виждате ли, оптимизаторът на заявки вече работи, че най-доброто нещо, което трябва да направите, е да използвате новия индекс. Но също така решава, че усилията да се налага да се правят справки, за да се получат всички останали колони (защото питах за всички колони) би било просто твърде много работа. Повратната точка беше достигната (за съжаление неправилно предположение в този случай) и вместо това беше избрано Clustered Index SCAN. Въпреки че без неклъстерирания индекс, най-добрият вариант би бил да се използва търсене на клъстериран индекс, когато неклъстерираният индекс е бил разгледан и отхвърлен по причини на повратна точка, той избира да сканира.
Разочароващо, току-що създадох този индекс и статистиката му трябва да е добра. Трябва да знае, че търсене, което изисква точно едно търсене, трябва да е по-добро от сканиране на клъстериран индекс (само по статистика – ако си мислите, че трябва да знае това, защото
LoginIDе уникален в основната таблица, не забравяйте, че може да не е било винаги). Така че подозирам, че трябва да се избягват справки в таблиците на историята, въпреки че все още не съм направил достатъчно проучване по въпроса.Сега, ако искахме само колони, които се появяват в нашия неклъстериран индекс, щяхме да получим много по-добро поведение. Сега, когато не се изисква търсене, нашият нов индекс в таблицата с история се използва с удоволствие. Все още трябва да приложи остатъчен предикат въз основа само на възможността да филтрира до
LoginIDиValidTo, но се държи много по-добре, отколкото да се спусне в сканиране на клъстериран индекс.ИЗБЕРЕТЕ LoginID, ValidFrom, ValidToFROM HumanResources.Employee_TemporalFOR SYSTEM_TIME ОТ '20160612 11:22'WHERE LoginID =N'adventure-works\rob0'
Така че индексирайте таблиците си с история по допълнителни начини, като вземете предвид как ще ги питате. Включете необходимите колони, за да избегнете търсения, защото наистина избягвате сканирането.
Тези таблици с история могат да нараснат, ако данните се променят често. Така че имайте предвид как се обработват с тях. Същата ситуация възниква при използване на другия
FOR SYSTEM_TIMEконструкции, така че трябва (както винаги) да прегледате плановете, които вашите заявки произвеждат, и да индексирате, за да сте сигурни, че сте добре позиционирани да използвате това, което е много мощна функция на SQL Server 2016.