Плановете за изпълнение предоставят богат източник на информация, който може да ни помогне да идентифицираме начини за подобряване на ефективността на важни заявки. Хората често търсят неща като големи сканирания и търсения като начин за идентифициране на потенциални оптимизации на пътя за достъп до данни. Тези проблеми често могат да бъдат бързо разрешени чрез създаване на нов индекс или разширяване на съществуващ с повече включени колони.
Можем също да използваме планове след изпълнение, за да сравним действителното с очакваното броене на редове между операторите на плана. Когато се установи, че те се различават значително, можем да се опитаме да предоставим по-добра статистическа информация на оптимизатора чрез актуализиране на съществуващи статистически данни, създаване на нови статистически обекти, използване на статистически данни за изчислени колони или може би чрез разделяне на сложна заявка на по-малко сложен компонент части.
Освен това можем да разгледаме и скъпи операции в плана, особено такива, които консумират памет, като сортиране и хеширане. Понякога сортирането може да бъде избегнато чрез промени в индексирането. Друг път може да се наложи да преработим заявката, използвайки синтаксис, който благоприятства план, който запазва определена желана подредба.
Понякога производителността все още няма да е достатъчно добра дори след прилагане на всички тези техники за настройка на производителността. Възможна следваща стъпка е да помислите малко повече за плана като цяло . Това означава да направим крачка назад, да се опитаме да разберем цялостната стратегия, избрана от оптимизатора на заявки, за да видим дали можем да идентифицираме алгоритмично подобрение.
Тази статия изследва този последен тип анализ, като използва прост примерен проблем за намиране на уникални стойности на колони в умерено голям набор от данни. Както често се случва при аналогични проблеми от реалния свят, колоната, която представлява интерес, ще има сравнително малко уникални стойности в сравнение с броя на редовете в таблицата. Този анализ има две части:създаване на примерни данни и писане на самата заявка за различни стойности.
Създаване на примерни данни
За да предоставим възможно най-простия пример, нашата тестова таблица има само една колона с клъстериран индекс (тази колона ще съдържа дублиращи се стойности, така че индексът не може да бъде обявен за уникален):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
За да изберем някои числа от въздуха, ще изберем да заредим десет милиона реда общо с равномерно разпределение вхиляда различни стойности . Често срещана техника за генериране на данни като тази е кръстосването на някои системни таблици и прилагане на ROW_NUMBER функция. Ние също така ще използваме модулния оператор, за да ограничим генерираните числа до желаните различни стойности:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Приблизителният план за изпълнение на тази заявка е както следва (щракнете върху изображението, за да го увеличите, ако е необходимо):

Това отнема около 30 секунди за да създам примерните данни на моя лаптоп. Това по никакъв начин не е огромен период от време, но все пак е интересно да обмислим какво можем да направим, за да направим този процес по-ефективен...
Анализ на плана
Ще започнем, като разберем за какво е предназначена всяка операция в плана.
Разделът от плана за изпълнение вдясно от оператора на сегмента се отнася до производствени редове чрез кръстосано свързване на системни таблици:

Операторът Segment е там, в случай че функцията на прозореца има PARTITION BY клауза. Тук не е така, но така или иначе присъства в плана на заявката. Операторът Sequence Project генерира номерата на редовете, а горната част ограничава изхода на плана до десет милиона реда:

Скаларът за изчисляване дефинира израза, който прилага модулната функция и добавя едно към резултата:

Можем да видим как се свързват етикетите на Sequence Project и Compute Scalar Expression с помощта на раздела Expressions на Plan Explorer:

Това ни дава по-пълно усещане за потока на този план:проектът за последователност номерира редовете и обозначава израза Expr1050; Compute Scalar обозначава резултата от изчисленията по модул и плюс едно като Expr1052 . Обърнете внимание и на имплицитното преобразуване в Изчислителния скаларен израз. Колоната на целевата таблица е от тип цяло число, докато ROW_NUMBER функцията произвежда bigint, така че е необходимо стеснително преобразуване.
Следващият оператор в плана е Sort. Според оценките на разходите на оптимизатора на заявки, това се очаква да бъде най-скъпата операция (88,1% оценено ):

Може да не е веднага очевидно защо този план включва сортиране, тъй като в заявката няма изрично изискване за подреждане. Сортирането се добавя към плана, за да се гарантира, че редовете пристигат в оператора за вмъкване на клъстериран индекс в клъстериран индексен ред. Това насърчава последователното записване, избягва разделянето на страници и е едно от предпоставките за минимално регистриран INSERT операции.
Всичко това са потенциално добри неща, но самият сорт е доста скъп. Всъщност, проверката на плана за изпълнение след изпълнение („действително“) разкрива, че Сортирането също е свършило памет по време на изпълнение и е трябвало да се разлее във физически tempdb диск:

Разливането на сортиране се случва, въпреки че приблизителният брой редове е точно правилен и въпреки факта, че на заявката е предоставена цялата памет, която е поискала (както се вижда в свойствата на плана за основния INSERT възел):

Разливането на сортиране се обозначава и с наличието на IO_COMPLETION чака в раздела за статистически данни на Plan Explorer PRO:

И накрая, за този раздел за анализ на плана, обърнете внимание на DML Request Sort свойството на оператора Clustered Insert Insert е зададено на true:

Този флаг показва, че оптимизаторът изисква поддървото под Insert да предоставя редове в сортирани по индексен ключ (оттук и необходимостта от проблемния оператор Sort).
Избягване на сортирането
Сега, когато знаем защо Сортиране се появява, можем да тестваме, за да видим какво ще се случи, ако го премахнем. Има начини, по които можем да пренапишем заявката, за да "залъжем" оптимизатора да мисли, че ще бъдат вмъкнати по-малко редове (така че сортирането няма да си струва), но бърз начин да избегнем сортирането директно (само за експериментални цели) е да използваме недокументиран флаг за проследяване 8795. Това задава DML Request Sort свойството на false, така че вече не са необходими редове, за да стигнат до вмъкването на клъстериран индекс в клъстериран ключов ред:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Новият план за заявка след изпълнение е както следва (щракнете върху изображението, за да го увеличите):

Операторът за сортиране изчезна, но новата заявка работи повече от 50 секунди (в сравнение с 30 секунди преди). Има няколко причини за това. Първо, губим всяка възможност за минимално регистрирани вмъквания, защото те изискват сортирани данни (DML Request Sort =true). Второ, по време на вмъкването ще възникнат голям брой „лоши“ разделяния на страници. В случай, че това изглежда противоинтуитивно, не забравяйте, че въпреки че ROW_NUMBER функцията изброява последователно редове, ефектът на модулния оператор е да представи повтаряща се последователност от числа 1…1000 към вмъкването на клъстериран индекс.
Същият основен проблем възниква, ако използваме T-SQL трикове, за да намалим очаквания брой редове, за да избегнем сортирането, вместо да използваме неподдържания флаг за проследяване.
Избягване на сортиране II
Разглеждайки плана като цяло, изглежда ясно, че бихме искали да генерираме редове по начин, който избягва изричното сортиране, но който все пак извлича предимствата на минималното регистриране и избягването на лошо разделяне на страници. Казано по-просто:искаме план, който представя редове в клъстериран ключов ред, но без сортиране.
Въоръжени с това ново прозрение, можем да изразим запитването си по различен начин. Следната заявка генерира всяко число от 1 до 1000 и кръстосано свързва този набор с 10 000 реда, за да произведе необходимата степен на дублиране. Идеята е да се генерира набор за вмъкване, който представя 10 000 реда, номерирани '1', след това 10 000 номерирани '2' ... и така нататък.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; За съжаление, оптимизаторът все още произвежда план със сортиране:

Тук няма много какво да се каже в защита на оптимизатора, това е просто глупав план. Той е избрал да генерира 10 000 реда, след което да се съединят кръстосано тези с числа от 1 до 1000. Това не позволява да се запази естественият ред на числата, така че сортирането не може да бъде избегнато.
Избягване на сортирането – най-накрая!
Стратегията, която оптимизаторът пропусна, е да вземе числата 1…1000 първи , и кръстосано съединете всяко число с 10 000 реда (правете 10 000 копия на всяко число последователно). Очакваният план ще избегне сортиране чрез използване на кръстосано присъединяване с вложени цикли, което запазва реда от редовете на външния вход.
Можем да постигнем този резултат, като принудим оптимизатора да получи достъп до извлечените таблици в реда, посочен в заявката, като използваме FORCE ORDER намек за заявка:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Най-накрая получаваме плана, който търсихме:
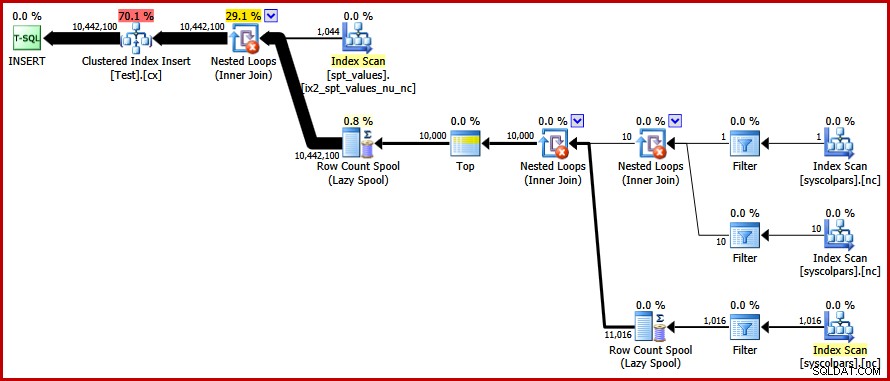
Този план избягва изрично сортиране, като същевременно избягва „лошо“ разделяне на страници и позволява минимално регистрирани вмъквания към клъстерирания индекс (ако приемем, че базата данни не използва FULL модел за възстановяване). Той зарежда всичките десет милиона реда за около 9 секунди на моя лаптоп (с един SATA въртящ се диск със 7200 rpm). Това представлява значително увеличение на ефективността за 30-50 секунди изминало време, видяно преди презаписването.
Намиране на отделните стойности
Сега имаме създадени примерни данни, можем да насочим вниманието си към писане на заявка за намиране на отделните стойности в таблицата. Естествен начин за изразяване на това изискване в T-SQL е както следва:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Планът за изпълнение е много прост, както бихте очаквали:

Това отнема около 2900 ms да работи на моята машина и изисква 43 406 логически чете:

Премахване на MAXDOP (1) намек за заявка генерира паралелен план:

Това завършва за около 1500 ms (но с изразходвано време на процесора 8764 ms) и 43 804 логически чете:

Същите планове и резултати се получават, ако използваме GROUP BY вместо DISTINCT .
По-добър алгоритъм
Показаните по-горе планове за заявка четат всички стойности от основната таблица и ги обработват чрез Stream Aggregate. Като се мисли за задачата като цяло, изглежда неефективно да се сканират всичките 10 милиона реда, когато знаем, че има сравнително малко различни стойности.
По-добра стратегия може да бъде да се намери единствената най-ниска стойност в таблицата, след това да се намери следващата най-висока и така нататък, докато не свършат стойностите. Най-важното е, че този подход се поддава на единично търсене в индекса, вместо да сканира всеки ред.
Можем да приложим тази идея в една заявка, използвайки рекурсивен CTE, където закотвената част намира най-ниската различна стойност, след това рекурсивната част намира следващата различна стойност и т.н. Първият опит за писане на тази заявка е:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); За съжаление, този синтаксис не се компилира:

Добре, така че агрегатните функции не са разрешени. Вместо да използвате MIN , можем да напишем същата логика, използвайки TOP (1) с ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Все още няма радост.
Оказва се, че можем да заобиколим тези ограничения, като пренапишем рекурсивната част, за да номерира редовете кандидати в необходимия ред, след което филтрираме за реда, който е номериран „едно“. Това може да изглежда малко заобиколено, но логиката е абсолютно същата:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Тази заявка прави компилира и създава следния план след изпълнение:

Забележете оператора Top в рекурсивната част на плана за изпълнение (маркиран). Не можем да напишем T-SQL TOP в рекурсивната част на рекурсивния израз на обща таблица, но това не означава, че оптимизаторът не може да използва такъв! Оптимизаторът въвежда горната част въз основа на разсъждения за броя на редовете, които ще трябва да провери, за да намери номерирания с „1“.
Производителността на този (непаралелен) план е много по-добра от подхода Stream Aggregate. Завършва за около 50 ms , с3007 логически четения спрямо изходната таблица (и 6001 реда, прочетени от работната таблица на макарата), в сравнение с предишното най-добро от 1500 мс (8764 ms CPU време при DOP 8) и 43 804 логически чете:


Заключение
Не винаги е възможно да се постигнат пробиви в производителността на заявките, като се вземат предвид отделните елементи на плана на заявката самостоятелно. Понякога трябва да анализираме стратегията зад целия план за изпълнение, след което да мислим странично, за да намерим по-ефективен алгоритъм и изпълнение.