Всичките ми публикации тази година са свързани с реакции на коляно за изчакване на статистически данни, но в тази публикация се отклонявам от тази тема, за да говоря за конкретен мой бъг:броячът на продължителността на живота на страницата (който ще нарека PLE ).
Какво означава PLE?
В интернет има всякакви неверни твърдения за продължителността на живота на страниците, а най-впечатляващите са тези, които уточняват, че стойността 300 е прагът, за който трябва да се притеснявате.
За да разберете защо това твърдение е толкова подвеждащо, трябва да разберете какво всъщност е PLE.
Дефиницията на PLE е очакваното време в секунди, през което страница с файл с данни, прочетена в буферния пул (кеша в паметта на страниците с файлове с данни), ще остане в паметта, преди да бъде изтласкана от паметта, за да се освободи място за различни данни файлова страница. Друг начин да се мисли за PLE е мигновено измерване на натиска върху буферния пул, за да се освободи свободно място за страниците, които се четат от диска. И за двете определения по-голямо число е по-добре.
Какво е добър PLE праг?
PLE от 300 означава, че целият ви буферен пул ефективно се промива и препрочита на всеки пет минути. Когато насоките за прага за PLE от 300 бяха дадени за първи път от Microsoft, около 2005/2006 г., това число може да е имало повече смисъл, тъй като средното количество памет на сървъра е било много по-ниско.
В днешно време, където сървърите рутинно имат 64GB, 128GB и по-високи количества памет, четенето на приблизително толкова данни от диска на всеки пет минути вероятно би било причина за осакатяващ проблем с производителността
В действителност тогава, когато PLE достигне или под 300, вашият сървър вече е в тежко положение. Ще започнете да се притеснявате много преди PLE да е толкова нисък.
И така, какъв е прагът, който да използвате, когато трябва да се притеснявате?
Е, това е само смисълът. Не мога да ви дам праг, тъй като това число ще варира за всеки. Ако наистина, наистина искате число, което да използвате, моят колега Джонатан Кехайяс измисли формула:
( Памет на буферен пул в GB / 4 ) x 300Дори това число е донякъде произволно и вашият пробег ще варира.
Не обичам да препоръчвам никакви числа. Моят съвет е да измервате своя PLE, когато ефективността е на желаното ниво – това е прага, който използвате.
Така че започвате ли да се притеснявате веднага щом PLE падне под този праг? Не. Започвате да се притеснявате, когато PLE падне под този праг и остане под този праг, или ако падне рязко и не знаете защо.
Това е така, защото има някои операции, които ще причинят отпадане на PLE (например стартиране на DBCC CHECKDB или възстановяването на индекс може да го направи понякога) и не са причина за безпокойство. Но ако видите голям спад на PLE и не знаете какво го причинява, тогава трябва да се притеснявате.
Може би се чудите как DBCC CHECKDB може да причини спад на PLE, когато се окаже неблагоприятно и се опитва усилено да избегне промиването на буферния пул с данните, които използва (вижте тази публикация в блога за обяснение). Това е така, защото предоставянето на памет за изпълнение на заявка за DBCC CHECKDB е неправилно изчислен от оптимизатора на заявки и може да доведе до голямо намаляване на размера на буферния пул (паметта за разрешението е открадната от буферния пул) и последващ спад в PLE.
Как наблюдавате PLE?
Това е трудната част. Повечето хора ще отидат направо в Buffer Manager обект на производителност в PerfMon и наблюдавайте Page life expectancy брояч. Това правилният подход ли е? Най-вероятно не.
Бих казал, че голяма част от сървърите днес използват NUMA архитектура и това има дълбок ефект върху начина, по който наблюдавате PLE.
Когато участва NUMA, буферният пул се разделя на буферни възли, с един буферен възел на NUMA възел, който SQL Server може да „вижда“. Всеки буферен възел проследява PLE поотделно и Buffer Manager:Page life expectancy броячът е средната стойност на PLE на буферния възел. Ако просто наблюдавате общия буферен пул PLE, тогава натискът върху един от буферните възли може да бъде маскиран от осредняването (обсъждам това в публикация в блога тук).
Така че, ако вашият сървър използва NUMA, трябва да наблюдавате отделния Buffer Node:Page life expectancy броячи (ще има един обект за производителност на буферен възел за всеки NUMA възел), в противен случай сте добре да наблюдавате Buffer Manager:Page life expectancy брояч.
Още по-добре е да използвате инструмент за наблюдение като SQL Sentry Performance Advisor, който ще покаже този брояч като част от таблото, като вземе предвид NUMA възлите на сървъра и ще ви позволи лесно да конфигурирате сигнали.
Примери за използване на съветника за ефективност
По-долу е дадена примерна част от заснемане на екрана от Performance Advisor за система с един възел NUMA:
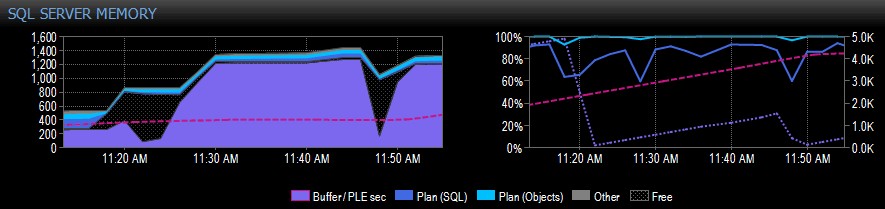
От дясната страна на заснемането, розовата пунктирана линия е PLE между 10.30 сутринта и около 11.20 сутринта – тя се изкачва постоянно до около 5000, наистина здравословно число. Малко преди 11.20 ч. има огромен спад и след това започва да се изкачва отново до 11.45 ч., където пада отново.
Това обикновено ще видите, ако буферният пул е пълен, с всички използвани страници и след това се изпълнява заявка, която кара огромно количество различни данни да бъдат прочетени от диска, измествайки голяма част от това, което вече е в паметта и причинявайки рязко спадане на PLE. Ако не знаете какво е причинило нещо подобно, бихте искали да проучите, както описвам по-долу.
Като втори пример, заснемането на екрана по-долу е от един от нашите Remote DBA клиенти, където сървърът има два NUMA възела (можете да видите, че има две лилави PLE линии) и където използваме съветника за производителност широко:

На сървъра на този клиент всяка сутрин около 5 часа сутринта започва работа по поддръжка на индекса и проверка на последователността, което кара PLE да пада в двата буферни възела. Това е очаквано поведение, така че няма нужда от разследване, стига PLE да се повиши отново през деня.
Какво можете да направите за отпадането на PLE?
Ако причината за падането на PLE не е известна, можете да направите няколко неща:
- Ако проблемът се случва сега, проучете кои заявки причиняват четения, като използвате
sys.dm_os_waiting_tasksDMV, за да видите кои нишки чакат страниците да бъдат прочетени от диска (т.е. тези, които чакатPAGEIOLATCH_SH), и след това коригирайте тези заявки. - Ако проблемът се е случил в миналото, потърсете в sys.dm_exec_query_stats DMV заявки с голям брой физически четения или използвайте инструмент за наблюдение, който може да ви даде тази информация (напр. изгледът Top SQL в Performance Advisor) и след това коригирайте тези заявки.
- Свържете изпускането на PLE с планираните задачи на агент, които извършват поддръжка на база данни.
- Потърсете заявки с много големи отпускания на памет за изпълнение на заявки, като използвате
sys.dm_exec_query_memory_grantsDMV и след това коригирайте тези заявки.
Предишната ми публикация тук обяснява повече за №1 и №2, а скрипт за разследване на изчаквания, възникващи на сървър, и връзка към техните планове за заявки е тук.
„Поправете тези заявки“ е извън обхвата на тази публикация, така че ще оставя това за друг път или като упражнение за читателя ☺
Резюме
Не попадайте в капана да вярвате на всеки препоръчан PLE праг, който може да прочетете онлайн. Най-добрият начин да реагирате на промените в PLE е, когато PLE падне под каквото и да е вашото нивото на комфорт е и остава там – това е индикацията за проблем с производителността, който трябва да проучите.
В следващата статия от поредицата ще обсъдя друга често срещана причина за настройка на производителността на коляното. Дотогава, щастливо отстраняване на неизправности!