Тази публикация е част от поредица за редовите голове. Можете да намерите останалите части тук:
- Част 1:Задаване и идентифициране на целите на редовете
- Част 2:Полусъединяване
- Част 3:Anti Joins
Приложете Anti Join с оператор Top
Често ще видите оператор Top (1) от вътрешната страна в apply anti join планове за изпълнение. Например, като използвате базата данни AdventureWorks:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Планът показва оператор Top (1) от вътрешната страна на приложението (външни препратки) anti join:
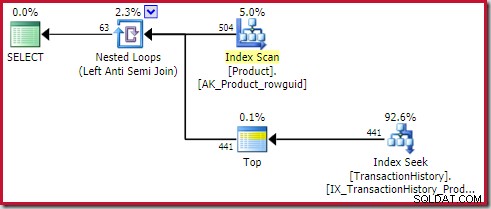
Този Топ оператор е напълно излишен . Не се изисква за коректност, ефективност или за да се гарантира, че е зададена цел за ред.
Операторът за прилагане на анти присъединяване ще спре да проверява за редове от вътрешната страна (за текущата итерация), веднага щом един ред се види при свързването. Напълно възможно е да се генерира план за прилагане срещу присъединяване без Top. И така, защо в този план има оператор Топ?
Източник на оператора Top
За да разберем откъде идва този безсмислен оператор Top, трябва да следваме основните стъпки, предприети по време на компилирането и оптимизирането на нашата примерна заявка.
Както обикновено, заявката първо се анализира в дърво. Това включва логически оператор „не съществува“ с подзаявка, която до голяма степен съответства на писмената форма на заявката в този случай:

Несъществуващата подзаявка се развива в прилагане срещу присъединяване:

Това след това допълнително се трансформира в логично ляво анти полусъединяване. Полученото дърво, предадено на оптимизация на базата на разходи, изглежда така:

Първото проучване, извършено от базирания на разходите оптимизатор, е да се въведе логическо различие операция на долния вход против присъединяване, за да произведе уникални стойности за ключа против присъединяване. Общата идея е, че вместо да тества дублирани стойности при присъединяването, планът може да се възползва от групирането на тези стойности отпред.
Правилото за отговорно изследване се нарича LASJNtoLASJNonDist (ляво анти полусъединяване към ляво анти полусъединяване на различно). Все още не е извършено физическо внедряване или изчисляване на разходите, така че това е просто оптимизаторът, който изследва логическата еквивалентност въз основа на наличието на дублиран ProductID стойности. Новото дърво с добавена операция за групиране е показано по-долу:

Следващата разглеждана логическа трансформация е да се пренапише присъединяването като apply . Това се изследва с помощта на правилото LASJNtoApply (ляво анти полусъединяване, за да се приложи с релационен подбор). Както бе споменато по-рано в поредицата, по-ранната трансформация от прилагане към присъединяване беше да позволи трансформации, които работят специално върху присъединения. Винаги е възможно да се пренапише присъединяване като приложение, така че това разширява обхвата от налични оптимизации.
Сега оптимизаторът не винаги обмислете прилагането на пренаписване като част от оптимизация, базирана на разходите. Трябва да има нещо в логическото дърво, за да си струва да избутате предиката за присъединяване надолу от вътрешната страна. Обикновено това ще бъде наличието на съвпадащ индекс, но има и други обещаващи цели. В този случай това е логическият ключ на ProductID създадена от агрегатната операция.
Резултатът от това правило е свързано анти присъединяване с селекция от вътрешната страна:

След това оптимизаторът обмисля преместване на релационния избор (корелирания предикат на присъединяване) по-надолу във вътрешната страна, покрай отделния (група по агрегат), въведен от оптимизатора по-рано. Това се прави от правилото SelOnGbAgg , който премества възможно най-много селекция (предикат) покрай подходяща група по агрегат (част от селекцията може да бъде изоставена). Тази дейност помага за натискане на селекции възможно най-близо до операторите за достъп до данни на ниво лист, за да елиминирате редовете по-рано и да улесните по-късното съпоставяне на индекси.
В този случай филтърът е в същата колона като операцията за групиране, така че трансформацията е валидна. Това води до изтласкване на цялата селекция под съвкупността:

Последната операция, представляваща интерес, се изпълнява от правило GbAggToConstScanOrTop . Тази трансформация изглежда да замени група по съвкупност с постоянно сканиране или Нагоре логическа операция. Това правило съвпада с нашето дърво, тъй като колоната за групиране е постоянна за всеки ред, преминаващ през избутаната надолу селекция. Гарантирано е, че всички редове имат един и същ ProductID . Групирането върху тази единствена стойност винаги ще произвежда един ред. Следователно е валидно да се трансформира агрегатът в Top (1). Така че оттук идва върха.
Внедряване и изчисляване на разходите
Оптимизаторът вече изпълнява серия от правила за внедряване, за да намери физически оператори за всяка от обещаващите логически алтернативи, които е разглеждал досега (съхранени ефективно в структура на бележка). Физическите опции против хеширане и сливане идват от първоначалното дърво с въведен агрегат (с любезното съдействие на правило LASJNtoLASJNonDist помня). Приложението се нуждае от малко повече работа, за да изгради физически връх и да съпостави селекцията с търсене на индекс.
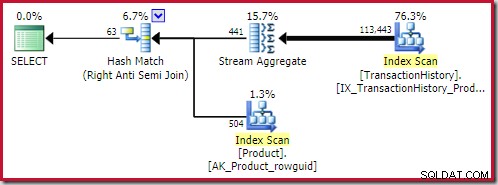
Най-добриятхеш анти присъединяване намереното решение е на цена 0,362143 единици:
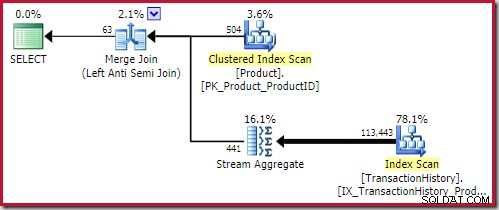
Най-доброто сливане против присъединяване решението идва на 0,353479 единици (малко по-евтино):
Приложете анти присъединяване струва0,091823 единици (най-евтини с голяма разлика):
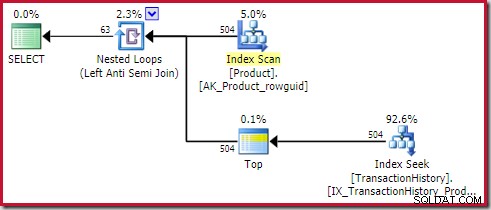
Проницателният читател може да забележи, че броят на редовете от вътрешната страна на прилагането против присъединяване (504) се различава от предишната екранна снимка на същия план. Това е така, защото това е прогнозен план, докато предишният план беше след изпълнение. Когато този план се изпълни, само общо 441 реда се намират от вътрешната страна за всички итерации. Това подчертава една от трудностите при показването на планове за прилагане на полу/анти присъединяване:Минималната оценка на оптимизатора е един ред, но полу- или анти присъединяването винаги ще намери един ред или нито един ред при всяка итерация. Показаните по-горе 504 реда представляват 1 ред на всяка от 504 итерации. За да съвпаднат числата, оценката ще трябва да бъде 441/504 =0,875 реда всеки път, което вероятно ще обърка хората също толкова.
Както и да е, планът по-горе е достатъчно „щастлив“, за да се класира за цел на ред от вътрешната страна на прилагането анти присъединяване по две причини:
- Анти присъединяването се трансформира от обединяване в приложение в базирания на разходите оптимизатор. Това задава ред цел (както е установено в част трета).
- Операторът Top(1) също задава цел за ред на своето поддърво.
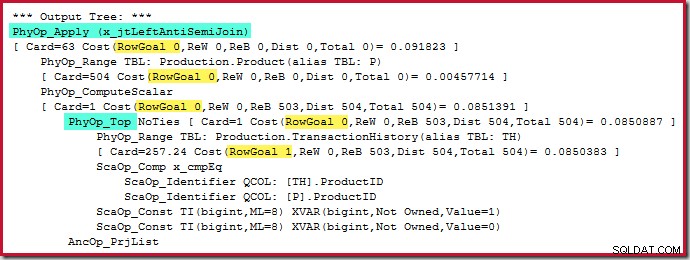
Самият оператор Top няма цел за ред (от приложението), тъй като целта на реда от 1 не би била по-малка отколкото обикновената оценка, която също е 1 ред (Карта=1 за PhyOp_Top по-долу):
Шаблонът Anti Join Anti
Следната обща форма на план е тази, която считам за антимодел:
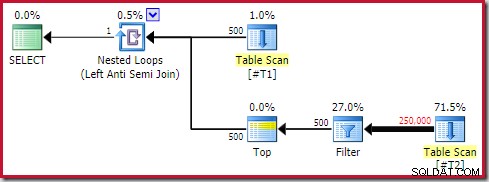
Не всеки план за изпълнение, съдържащ приложимо анти присъединяване с оператор Top (1) от вътрешната му страна, ще бъде проблематичен. Независимо от това, това е модел за разпознаване и почти винаги изисква допълнително проучване.
Четирите основни елемента, за които трябва да внимавате, са:
- Корелирани вложени цикли (прилагане ) анти присъединяване
- A Върх (1) оператор веднага от вътрешната страна
- Съществен брой редове на външния вход (така че вътрешната страна ще се изпълнява много пъти)
- Потенциално скъпо поддърво под горната част
Поддървото "$$$" е това, което е потенциално скъпо по време на изпълнение . Това може да бъде трудно за разпознаване. Ако имаме късмет, ще има нещо очевидно като сканиране на пълна таблица или индекс. В по-предизвикателни случаи поддървото ще изглежда напълно невинно на пръв поглед, но ще съдържа нещо скъпо, когато се погледне по-отблизо. За да дадете доста често срещан пример, може да видите търсене на индекс, което се очаква да върне малък брой редове, но което съдържа скъп остатъчен предикат, който тества много голям брой редове, за да намери няколкото, които отговарят на изискванията.
Предходният пример с код на AdventureWorks нямаше "потенциално скъпо" поддърво. Търсенето на индекс (без остатъчен предикат) би било оптимален метод за достъп, независимо от съображенията за целта на реда. Това е важен момент:предоставяне на оптимизатора свинаги ефективно Пътят за достъп до данни от вътрешната страна на свързано съединение винаги е добра идея. Това е още по-вярно, когато приложението работи в режим против присъединяване с оператор Top (1) от вътрешната страна.
Нека сега да разгледаме пример, който има доста мрачна производителност по време на изпълнение поради този анти шаблон.
Пример
Следващият скрипт създава две временни таблици на купчина. Първият има 500 реда, съдържащи цели числа от 1 до 500 включително. Втората таблица има 500 копия на всеки ред в първата таблица, за общо 250 000 реда. И двете таблици използват sql_variant тип данни.
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Ефективност
Сега изпълняваме заявка за търсене на редове в по-малката таблица, които не присъстват в по-голямата таблица (разбира се, няма такива):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); Тази заявка се изпълнява за около 20 секунди , което е ужасно дълго време за сравнение на 500 реда с 250 000. Изчисленият план за SSMS затруднява да се разбере защо производителността може да е толкова слаба:
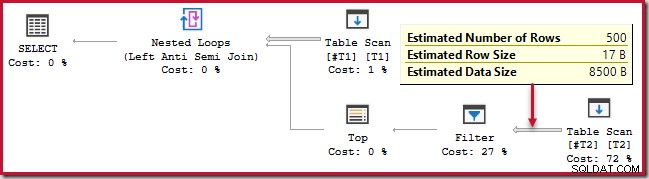
Наблюдателят трябва да е наясно, че прогнозните планове на SSMS показват вътрешни оценки на итерация на присъединяването на вложен цикъл. Объркващо е, че действителните планове на SSMS показват броя на редовете за всички итерации . Plan Explorer автоматично извършва простите изчисления, необходими за прогнозните планове, за да покаже и общия брой очаквани редове:
Въпреки това производителността по време на изпълнение е много по-лоша от очакваната. Планът за изпълнение (действително) след изпълнение е:
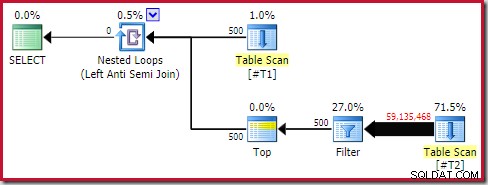
Обърнете внимание на отделния филтър, който обикновено би бил избутан надолу в сканирането като остатъчен предикат. Това е причината за използване на sql_variant тип данни; той предотвратява избутването на предиката, което прави огромния брой редове от сканирането по-лесно да се види.
Анализ
Причината за несъответствието се свежда до това как оптимизаторът оценява броя на редовете, които ще трябва да прочете от сканирането на таблицата, за да постигне целта за един ред, зададена във филтъра. Простото допускане е, че стойностите са равномерно разпределени в таблицата, така че за да срещне 1 от наличните 500 уникални стойности, SQL Server ще трябва да прочете 250 000 / 500 =500 реда. Над 500 повторения, което идва до 250 000 реда.
Предположението за еднородност на оптимизатора е общо, но тук не работи добре. Можете да прочетете повече за това в A Row Goal Request от Joe Obbish и да гласувате за предложението му във форума за обратна връзка за заместване на Connect в Use More Than Density, за да струва сканиране на вътрешната страна на вложен цикъл с TOP.
Моето виждане за този специфичен аспект е, че оптимизаторът трябва бързо да се откаже от простото предположение за еднородност, когато операторът е от вътрешната страна на присъединяване на вложени цикли (т.е. очакваното пренавиване плюс повторно свързване е по-голямо от единица). Едно е да приемем, че трябва да прочетем 500 реда, за да намерим съвпадение при първата итерация на цикъла. Да приемем това при всяка итерация изглежда ужасно малко вероятно да е точно; това означава, че първите 500 срещани реда трябва да съдържат по една от всяка отделна стойност. Малко вероятно е това да е така на практика.
Поредица от нещастни събития
Независимо от начина, по който се оскъпяват повтарящите се Топ оператори, струва ми се, че цялата ситуация трябва да се избягва на първо място . Припомнете си как е създаден Топът в този план:
- Оптимизаторът въведе отделен агрегат от вътрешната страна като оптимизиране на производителността .
- Този агрегат предоставя ключ на колоната за свързване по дефиниция (произвежда уникалност).
- Този конструиран ключ предоставя цел за преобразуване от присъединяване към приложение.
- Предикатът (селекция), свързан с приложението, се избутва надолу покрай агрегата.
- Сега се гарантира, че агрегатът работи с една отделна стойност на итерация (тъй като е корелационна стойност).
- Агрегатът се заменя с върха (1).
Всички тези трансформации са валидни поотделно. Те са част от нормалните операции на оптимизатора, тъй като той търси разумен план за изпълнение. За съжаление резултатът тук е, че спекулативният агрегат, въведен от оптимизатора, в крайна сметка се превръща в Топ (1) със свързана редова цел . Целта на реда води до неточно изчисляване на разходите въз основа на предположението за еднородност и след това до избор на план, който е малко вероятно да се представи добре.
Сега някой може да възрази, че прилагането анти присъединяване така или иначе ще има цел за ред - без горната последователност на трансформация. Контрааргументът е, че оптимизаторът не би обмислил трансформация от anti join към apply anti join (задаване на целта на реда) без въведения от оптимизатора агрегат, който дава LASJNtoApply правило нещо, към което да се обвърже. Освен това видяхме (в част трета), че ако анти присъединяването беше въвело оптимизация на базата на разходите като приложение (вместо присъединяване), отново нямаше да няма цел за ред .
Накратко, целта на реда в крайния план е изцяло изкуствена и няма основа в оригиналната спецификация на заявката. Проблемът с целта отгоре и ред е страничен ефект от този по-фундаментален аспект.
Заобиколни решения
Има много потенциални решения на този проблем. Премахването на която и да е от стъпките в оптимизационната последователност по-горе ще гарантира, че оптимизаторът няма да произведе прилагане срещу присъединяване с драстично (и изкуствено) намалени разходи. Надяваме се, че този проблем ще бъде решен в SQL Server по-скоро, отколкото по-късно.
Междувременно, моят съвет е да внимавате за анти присъединяване анти шаблон. Уверете се, че вътрешната страна на приложимо антисъединяване винаги има ефективен път за достъп за всички условия на изпълнение. Ако това не е възможно, може да се наложи да използвате подсказки, да деактивирате целите на редовете, да използвате ръководство за план или да принудите план за магазин за заявки, за да получите стабилна производителност от заявки срещу присъединяване.
Резюме на поредицата
Покрихме много въпроси в четирите вноски, така че ето обобщение на високо ниво:
- Част 1 – Задаване и идентифициране на цели на редове
- Синтаксисът на заявката не определя наличието или отсъствието на цел за ред.
- Цел за ред се задава само когато целта е по-малка от обичайната прогноза.
- Операторите на Physical Top (включително тези, въведени от оптимизатора) добавят цел за ред към своето поддърво.
FASTилиSET ROWCOUNTоператор задава цел за ред в основата на плана.- Полусъединяване и анти присъединяване могат добавете цел на ред.
- SQL Server 2017 CU3 добавя атрибута showplan EstimateRowsWithoutRowGoal за оператори, засегнати от цел на ред
- Информацията за целта на реда може да бъде разкрита чрез недокументирани флагове за проследяване 8607 и 8612.
- Част 2 – Полусъединяване
- Не е възможно да се изрази полусъединяване директно в T-SQL, затова използваме индиректен синтаксис, напр.
IN,EXISTS, илиINTERSECT. - Тези синтаксиси се анализират в дърво, съдържащо приложение (корелирано присъединяване).
- Оптимизаторът се опитва да трансформира приложението в редовно присъединяване (невинаги е възможно).
- Хеширане, сливане и обикновени вложени цикли, полусъединяване не задават цел за ред.
- Прилагане на полусъединяване винаги задава цел за ред.
- Прилагането на полуприсъединяване може да бъде разпознато чрез наличие на външни препратки към оператора за присъединяване на вложени цикли.
- Прилагане на полусъединяване не използва оператор Top (1) от вътрешната страна.
- Част 3 – Anti Joins
- Също анализиран в приложение с опит да се пренапише като присъединяване (невинаги е възможно).
- Хеширането, сливането и обикновените вложени цикли против присъединяване не задават цел за ред.
- Прилагането срещу присъединяване не винаги задава цел за ред.
- Само правилата за оптимизация на базата на разходи (CBO), които трансформират анти присъединяване към прилагане, задават цел за ред.
- Анти присъединяването трябва да влезе в CBO като присъединяване (не е приложимо). В противен случай присъединяването за прилагане на трансформацията не може да се осъществи.
- За да въведете CBO като присъединяване, пренаписването преди CBO от прилагане към присъединяване трябва да е било успешно.
- CBO изследва само пренаписването на анти присъединяване към приложение в обещаващи случаи.
- Опростенията преди CBO могат да се видят с недокументиран флаг за проследяване 8621.
- Част 4 – Anti Join Anti Pattern
- Оптимизаторът задава цел за ред за прилагане на анти присъединяване само когато има обещаваща причина за това.
- За съжаление, множеството взаимодействащи оптимизиращи трансформации добавят оператор Top (1) към вътрешната страна на приложимо антисъединяване.
- Операторът Top е излишен; не се изисква за коректност или ефективност.
- Върхът винаги задава цел за ред (за разлика от приложението, което се нуждае от основателна причина).
- Неоправданата цел на ред може да доведе до изключително лошо представяне.
- Внимавайте за потенциално скъпо поддърво под изкуствения връх (1).