Наскоро написах публикация за DISTINCT и GROUP BY. Това беше сравнение, което показа, че GROUP BY като цяло е по-добър вариант от DISTINCT. Това е на друг сайт, но не забравяйте да се върнете на sqlperformance.com веднага след това..
Едно от сравненията на заявките, които показах в тази публикация, беше между GROUP BY и DISTINCT за подзаявка, което показва, че DISTINCT е много по-бавно, тъй като трябва да извлече името на продукта за всеки ред в таблицата Sales, по-скоро отколкото само за всеки различен ProductID. Това е съвсем ясно от плановете за заявка, където можете да видите, че в първата заявка Aggregate работи с данни само от една таблица, а не с резултатите от обединяването. О, и двете заявки дават едни и същи 266 реда.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

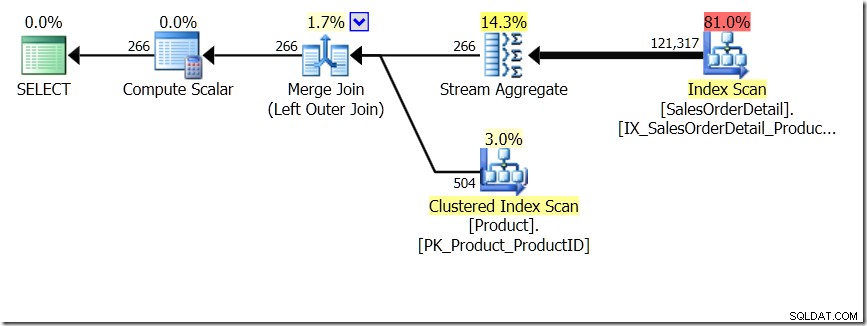
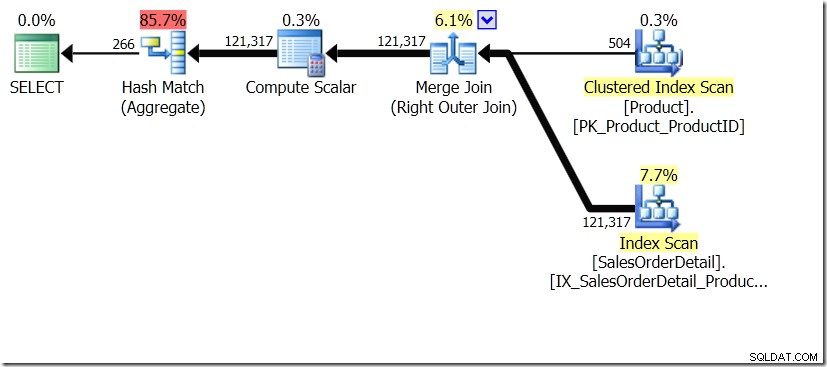
Сега беше посочено, включително от Адам Мачаник (@adammachanic) в туит, препращащ публикацията на Аарън за GROUP BY v DISTINCT, че двете заявки са по същество различни, че едната всъщност иска набор от различни комбинации за резултатите от подзаявка, вместо да изпълнява подзаявката през отделните стойности, които се предават. Това е, което виждаме в плана и е причината производителността да е толкова различна.
Работата е там, че всички бихме предположили, че резултатите ще бъдат идентични.
Но това е предположение и не е добро.
Ще си представя за момент, че Оптимизаторът на заявки е измислил различен план. Използвах съвети за това, но както знаете, оптимизаторът на заявки може да избере да създава планове във всякакви форми по всякакви причини.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
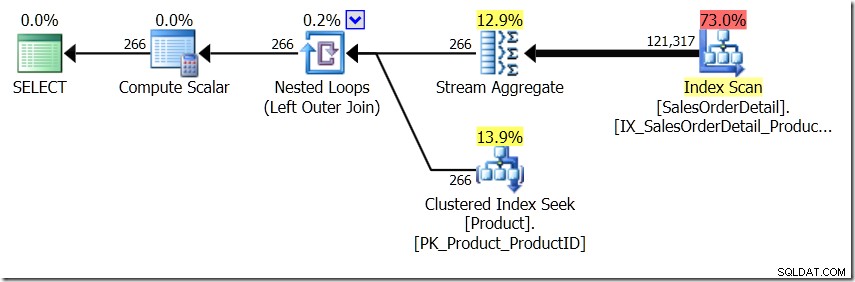
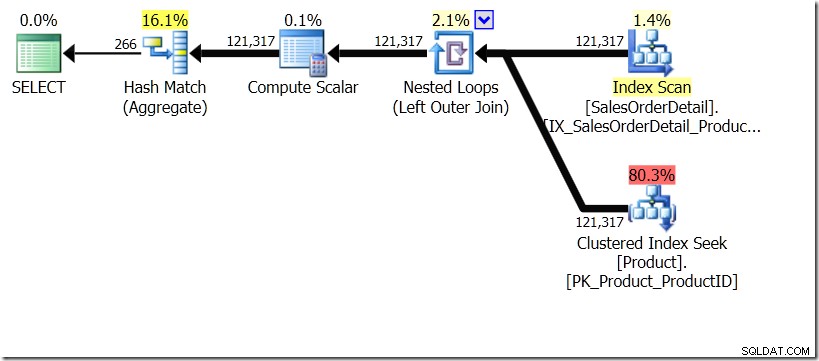
В тази ситуация или извършваме 266 търсения в таблицата с продукти, по едно за всеки различен ProductID, който ни интересува, или 121 317 търсения. Така че, ако мислим за конкретен ProductID, знаем, че ще получим едно име обратно от първото. И предполагаме, че ще получим обратно едно име за този ProductID, дори ако трябва да го поискаме сто пъти. Просто предполагаме, че ще получим същите резултати обратно.
Но какво ще стане, ако не го направим?
Това звучи като ниво на изолация, така че нека използваме NOLOCK, когато ударим таблицата с продуктите. И нека стартираме (в различен прозорец) скрипт за промяна на текста в колоните Име. Ще го правя отново и отново, за да се опитам да получа някои от промените между заявката си.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Сега резултатите ми са различни. Плановете са едни и същи (с изключение на броя на редовете, излизащи от Hash Aggregate във втората заявка), но резултатите ми са различни.
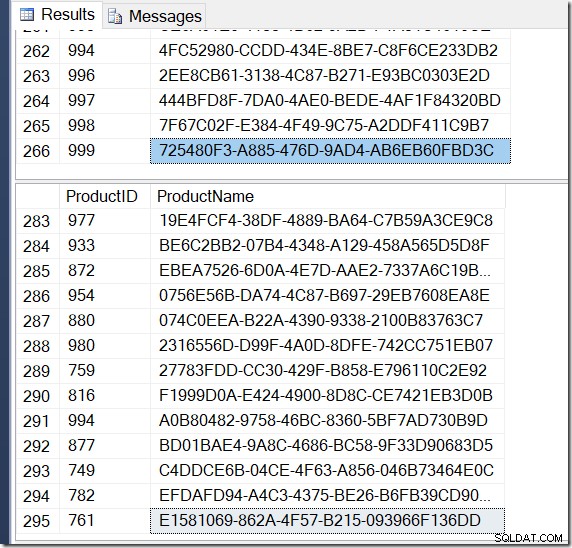
Разбира се, имам повече редове с DISTINCT, защото намира различни стойности на Name за един и същ ProductID. И не е задължително да имам 295 реда. Друго, когато го стартирам, може да получа 273, или 300, или евентуално 121 317.
Не е трудно да се намери пример за ProductID, който показва множество стойности на Name, потвърждавайки какво се случва.

Ясно е, че за да гарантираме, че не виждаме тези редове в резултатите, ще трябва или да НЕ използваме DISTINCT, или да използваме по-строго ниво на изолация.
Работата е там, че въпреки че споменах използването на NOLOCK за този пример, не ми беше необходимо. Тази ситуация възниква дори при READ COMMITTED, което е нивото на изолация по подразбиране в много системи на SQL Server.
Виждате ли, имаме нужда от ниво на изолация REPEATABLE READ, за да избегнем тази ситуация, за да задържим ключалките на всеки ред, след като бъде прочетен. В противен случай отделна нишка може да промени данните, както видяхме.
Но… не мога да ви покажа, че резултатите са фиксирани, защото не успях да избегна задънена улица на заявката.
Така че нека променим условията, като се уверим, че другата ни заявка е по-малко проблем. Вместо да актуализираме цялата таблица наведнъж (което така или иначе е много по-малко вероятно в реалния свят), нека просто актуализираме един ред наведнъж.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Сега все още можем да демонстрираме проблема при по-ниско ниво на изолация, като READ COMMITTED или READ UNCOMMITTED (въпреки че може да се наложи да стартирате заявката няколко пъти, ако получите 266 за първи път, тъй като шансът за актуализиране на ред по време на заявката е по-малко) и сега можем да демонстрираме, че REPEATABLE READ го коригира (без значение колко пъти стартираме заявката).
REPEATABLE READ прави това, което пише на тенекия. След като прочетете ред в транзакция, той е заключен, за да сте сигурни, че можете да повторите четенето и да получите същите резултати. По-ниските нива на изолация не премахват тези ключалки, докато не се опитате да промените данните. Ако вашият план за заявка никога не трябва да повтаря четене (какъвто е случаят с формата на нашите планове GROUP BY), тогава няма да имате нужда от ПОВТОРЯЩО ЧЕТЕНЕ.
Може да се спори, че винаги трябва да използваме по-високите нива на изолация, като REPEATABLE READ или SERIALIZABLE, но всичко се свежда до това да разберем от какво се нуждаят нашите системи. Тези нива могат да въведат нежелано заключване, а нивата на изолация на SNAPSHOT изискват версии, които също идват с цена. За мен мисля, че това е компромис. Ако питам за заявка, която може да бъде засегната от промяна на данни, може да се наложи да повиша нивото на изолация за известно време.
В идеалния случай просто не актуализирате данни, които току-що са били прочетени и може да се наложи да бъдат прочетени отново по време на заявката, така че да не се нуждаете от ПОВТОРЯЩО ЧЕТЕНЕ. Но определено си струва да разберем какво може да се случи и да признаем, че това е сценарият, когато DISTINCT и GROUP BY може да не са еднакви.
@rob_farley