В последната ми публикация видяхме как заявка, включваща скаларен агрегат, може да бъде трансформирана от оптимизатора в по-ефективна форма. Като напомняне, ето отново схемата:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Възможности за планиране
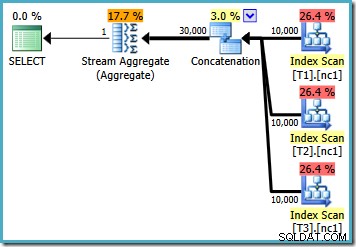
С 10 000 реда във всяка от базовите таблици, оптимизаторът предлага прост план, който изчислява максимума, като чете всички 30 000 реда в агрегат:
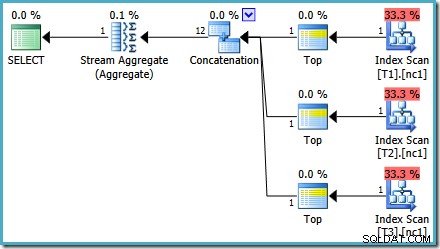
С 50 000 реда във всяка таблица, оптимизаторът отделя малко повече време на проблема и намира по-интелигентен план. Той чете само най-горния ред (в низходящ ред) от всеки индекс и след това изчислява максимума само от тези 3 реда:
Бъг в оптимизатора
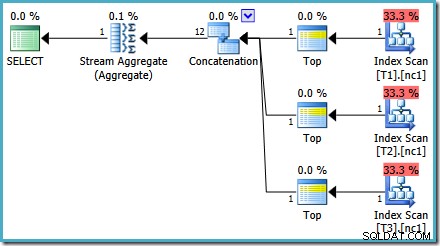
Може да забележите нещо малко странно в тази оценка план. Операторът за конкатенация чете един ред от три таблици и някак си произвежда дванадесет реда! Това е грешка, причинена от грешка в оценката на мощността, за която докладвах през май 2011 г. Тя все още не е коригирана от SQL Server 2014 CTP 1 (дори ако се използва новият оценител на мощността), но се надявам, че ще бъде адресиран за окончателно издание.
За да видите как възниква грешката, припомнете си, че една от алтернативите на плана, разгледана от оптимизатора за случай от 50 000 реда, има частични агрегати под оператора за конкатенация:
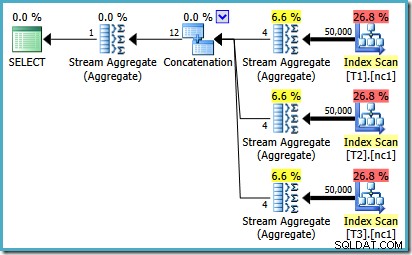
Това е оценката на мощността за тези частични MAX агрегати, което е виновно. Те оценяват четири реда, където резултатът гарантирано е един ред. Може да видите число, различно от четири – зависи от това колко логически процесора са на разположение на оптимизатора към момента на съставяне на плана (вижте връзката за грешки по-горе за повече подробности).
По-късно оптимизаторът заменя частичните агрегати с оператори Top (1), които преизчисляват правилно оценката за мощността. За съжаление, операторът за конкатенация все още отразява оценките за заменените частични агрегати (3 * 4 =12). В резултат на това получаваме конкатенация, която чете 3 реда и произвежда 12.
Използване на TOP вместо MAX
Поглеждайки отново към плана от 50 000 реда, изглежда, че най-голямото подобрение, открито от оптимизатора, е използването на оператори Top (1), вместо да четете всички редове и да изчислявате максималната стойност с помощта на груба сила. Какво ще стане, ако опитаме нещо подобно и пренапишем заявката, използвайки изрично Top?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Планът за изпълнение на новата заявка е:
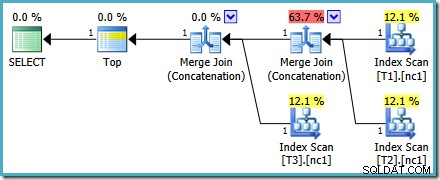
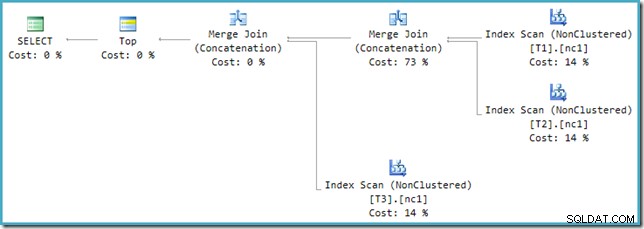
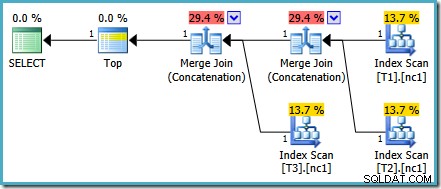
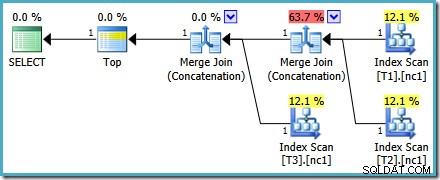
Този план е доста различен от този, избран от оптимизатора за MAX запитване. Той включва три подредени индексни сканирания, две Merge Join, работещи в режим на конкатенация, и един оператор Top. Този нов план за заявка има някои интересни функции, които си заслужава да бъдат разгледани малко подробно.
Анализ на план
Първият ред (в низходящ ред на индекси) се чете от неклъстерирания индекс на всяка таблица и се използва Merge Join, работещ в режим на конкатенация. Въпреки че операторът Merge Join не извършва обединяване в нормалния смисъл, алгоритъмът за обработка на този оператор е лесно адаптиран за конкатенация на неговите входове, вместо да прилага критерии за присъединяване.
Предимството от използването на този оператор в новия план е, че конкатенацията на сливане запазва реда на сортиране в своите входове. Обратно, обикновен оператор за конкатенация чете от своите входове последователно. Диаграмата по-долу илюстрира разликата (щракнете, за да разгънете):
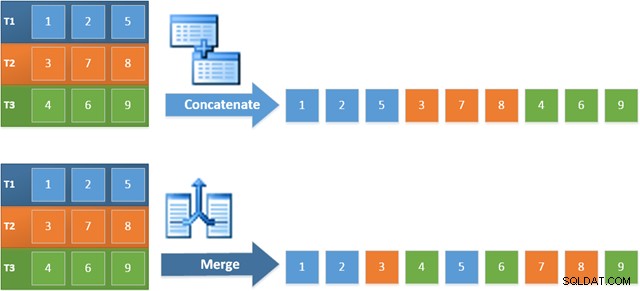
Поведението за запазване на реда на конкатенацията на сливане означава, че първият ред, произведен от най-левия оператор на сливане в новия план, гарантирано е редът с най-висока стойност в колона c1 във всичките три таблици. По-конкретно, планът работи както следва:
- Един ред се чете от всяка таблица (в низходящ ред на индекса); и
- Всяко сливане извършва един тест за да видите кой от неговите входни редове има по-висока стойност
Това изглежда много ефективна стратегия, така че може да изглежда странно, че MAX на оптимизатора планът има прогнозна цена на по-малко от половината от новия план. До голяма степен причината е, че се приема, че запазващата реда конкатенация е по-скъпа от обикновената конкатенация. Оптимизаторът не осъзнава, че всяко обединяване може да види само един ред и в резултат надценява цената му.
Още проблеми с разходите
Строго погледнато, тук не сравняваме ябълки с ябълки, защото двата плана са за различни заявки. Сравняването на разходи като това обикновено не е валидно нещо, въпреки че SSMS прави точно това, като показва процентите на разходите за различни изявления в партида. Но аз се отклонявам.
Ако погледнете новия план в SSMS вместо SQL Sentry Plan Explorer, ще видите нещо подобно:
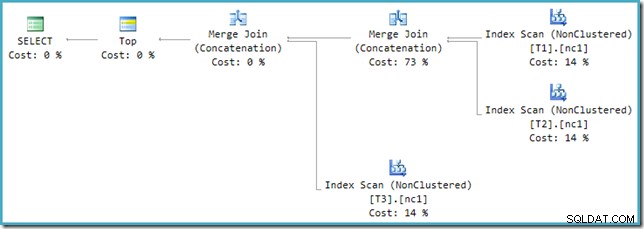
Един от операторите за конкатенация на сливане има приблизителна цена от 73%, докато вторият (работещ на точно същия брой редове) е показан като не струва абсолютно нищо. Друг знак, че тук нещо не е наред е, че процентите на разходите на оператора в този план не са 100%.
Оптимизатор срещу машина за изпълнение
Проблемът се крие в несъвместимост между оптимизатора и машината за изпълнение. В оптимизатора Union и Union All могат да имат 2 или повече входа. В машината за изпълнение само операторът за конкатенация може да приеме 2 или повече входове; Присъединяването за сливане изисква точно два входа, дори когато са конфигурирани да извършват конкатенация, а не обединяване.
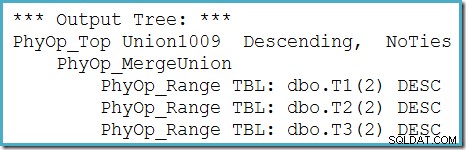
За да се разреши тази несъвместимост, се прилага пренаписване след оптимизация, за да се преведе изходното дърво на оптимизатора във форма, която машината за изпълнение може да обработва. Когато Union или Union All с повече от два входа се реализира чрез Merge, е необходима верига от оператори. С три входа към Union All в настоящия случай са необходими две Merge Unions:
Можем да видим изходното дърво на оптимизатора (с три входа към физическо обединение за сливане), използвайки флаг за проследяване 8607:
Непълна корекция
За съжаление, пренаписването след оптимизация не е перфектно внедрено. Това прави малко бъркотия в цифрите на разходите. Като оставим настрана проблемите за закръгляване, разходите по плана се добавят до 114%, като допълнителните 14% идват от входа към допълнителната конкатенация на присъединяване при сливане, генерирана от пренаписването:
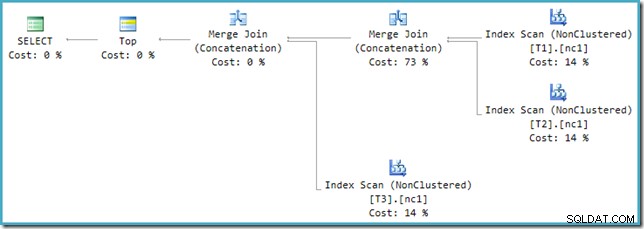
Най-десният Merge в този план е оригиналният оператор в изходното дърво на оптимизатора. Приписва му се пълната цена на операцията Union All. Другото сливане се добавя от пренаписването и получава нулева цена.
Какъвто и начин да изберем да го разгледаме (и има различни проблеми, които засягат редовното обединяване), числата изглеждат странни. Plan Explorer прави всичко възможно, за да заобиколи повредената информация в XML плана, като гарантира поне 100% сумиране на числата:
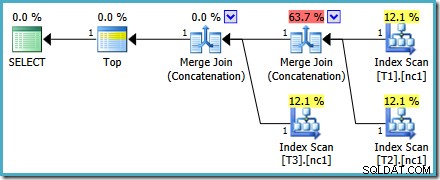
Този конкретен проблем с разходите е коригиран в SQL Server 2014 CTP 1:
Разходите за обединяването на сливането вече са равномерно разпределени между двата оператора, а процентите достигат до 100%. Тъй като основният XML е коригиран, SSMS също успява да покаже същите числа.
Кой план е по-добър?
Ако напишем заявката с помощта на MAX , трябва да разчитаме на оптимизатора да избере да извърши допълнителната работа, необходима за намиране на ефективен план. Ако оптимизаторът открие очевидно достатъчно добър план рано, той може да създаде относително неефективен план, който чете всеки ред от всяка от базовите таблици:
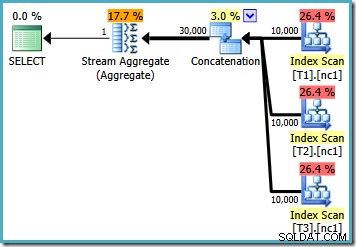
Ако използвате SQL Server 2008 или SQL Server 2008 R2, оптимизаторът пак ще избере неефективен план, независимо от броя на редовете в базовите таблици. Следният план беше създаден на SQL Server 2008 R2 с 50 000 реда:
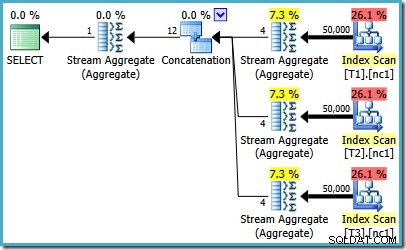
Дори с 50 милиона реда във всяка таблица, оптимизаторът за 2008 и 2008 R2 просто добавя паралелизъм, не въвежда най-добрите оператори:
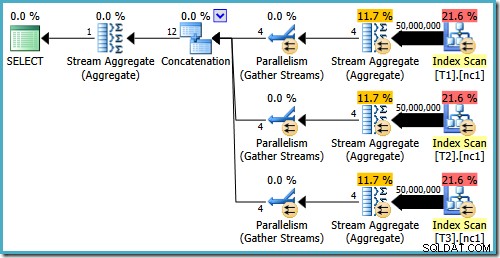
Както бе споменато в предишната ми публикация, флагът за проследяване 4199 е необходим, за да получите SQL Server 2008 и 2008 R2 за създаване на плана с Топ оператори. SQL Server 2005 и 2012 нататък не изискват флага за проследяване:
ГОРЕ с ORDER BY
След като разберем какво се случва в предишните планове за изпълнение, можем да направим съзнателен (и информиран) избор да пренапишем заявката, използвайки изрично TOP с ORDER BY:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Полученият план за изпълнение може да има проценти на разходите, които изглеждат странни в някои версии на SQL Server, но основният план е стабилен. Пренаписването след оптимизация, което кара числата да изглеждат странни, се прилага след завършване на оптимизацията на заявката, така че можем да сме сигурни, че изборът на план на оптимизатора не е бил засегнат от този проблем.
Този план не се променя в зависимост от броя на редовете в основната таблица и не изисква никакви флагове за проследяване за генериране. Малко допълнително предимство е, че този план се намира от оптимизатора по време на първата фаза на оптимизация въз основа на разходите (търсене 0):
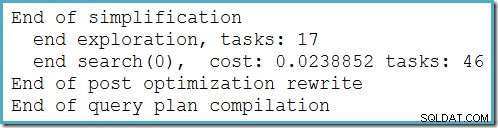
Най-добрият план, избран от оптимизатора за MAX заявката изисква изпълнение на два етапа на оптимизация въз основа на разходите (търсене 0 и търсене 1).
Има малка семантична разлика между TOP заявка и оригиналния MAX форма, която трябва да спомена. Ако никоя от таблиците не съдържа ред, оригиналната заявка ще доведе до един NULL резултат. Заместващият TOP (1) заявката изобщо не произвежда изход при същите обстоятелства. Тази разлика често не е важна при заявките в реалния свят, но е нещо, с което трябва да се знае. Можем да репликираме поведението на TOP използвайки MAX в SQL Server 2008 нататък чрез добавяне на празен набор GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Тази промяна не засяга плановете за изпълнение, генерирани за MAX заявка по начин, който е видим за крайните потребители.
MAX с конкатенация при сливане
Като се има предвид успехът на конкатенацията на присъединяване към сливане в TOP (1) план за изпълнение, естествено е да се чудите дали същият оптимален план може да бъде генериран за оригиналния MAX запитване, ако принудим оптимизатора да използва обединяване на сливане вместо редовно обединяване за UNION ALL операция.
За тази цел има намек за заявка – MERGE UNION – но за съжаление работи правилно само в SQL Server 2012 нататък. В предишни версии UNION намек засяга само UNION заявки, а не UNION ALL . В SQL Server 2012 нататък можем да опитаме това:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
Ние сме възнаградени с план, който включва обединяване на сливане. За съжаление, това не е всичко, на което може да се надяваме:
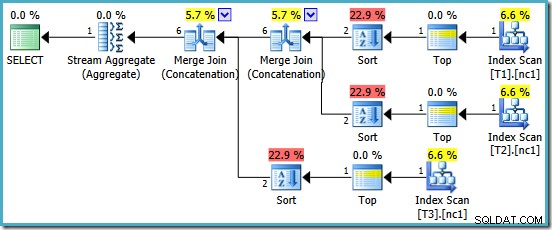
Интересните оператори в този план са сортовете. Забележете оценката на входната мощност от 1 ред и оценката на 4 реда на изхода. Причината вече трябва да ви е позната:това е същата грешка при оценката на частичната обобщена мощност, която обсъдихме по-рано.
Наличието на сортовете разкрива още един проблем с частичните агрегати. Те не само произвеждат неправилна оценка на мощността, но също така не успяват да запазят подреждането на индексите, което би направило сортирането ненужно (Конкатенацията при сливане изисква сортирани входни данни). Частичните агрегати са скаларни MAX агрегати, гарантирано да произвеждат един ред, така че въпросът за подреждането така или иначе би трябвало да е спорен (има само един начин за сортиране на един ред!)
Това е срамота, защото без сортовете това би било приличен план за изпълнение. Ако частичните агрегати са били внедрени правилно, и MAX написан с GROUP BY () клауза, може дори да се надяваме, че оптимизаторът може да забележи, че трите Tops и окончателният Stream Aggregate могат да бъдат заменени с един единствен окончателен Top оператор, даващ точно същия план като изричния TOP (1) запитване. Оптимизаторът не съдържа тази трансформация днес и не предполагам, че би бил полезен достатъчно често, за да си струва включването му в бъдеще.
Последни думи
Използване на TOP не винаги ще бъде за предпочитане пред MIN или MAX . В някои случаи това ще създаде значително по-малко оптимален план. Смисълът на тази публикация е, че разбирането на трансформациите, прилагани от оптимизатора, може да предложи начини за пренаписване на оригиналната заявка, които може да се окажат полезни.