В тази статия ще се съсредоточим върху оперативните анализи в реално време и как да приложим този подход към OLTP база данни. Когато разгледаме традиционния аналитичен модел, можем да видим, че OLTP и аналитичните среди са отделни структури. На първо място, традиционните среди за аналитичен модел трябва да създават ETL (Extract, Transform and Load) задачи. Защото трябва да прехвърлим транзакционни данни в хранилището за данни. Тези видове архитектура имат някои недостатъци. Те са цена, сложност и забавяне на данните. За да премахнем тези недостатъци, се нуждаем от различен подход.
Оперативен анализ в реално време
Microsoft обяви Оперативен анализ в реално време в SQL Server 2016. Възможността на тази функция е да комбинира транзакционна база данни и работно натоварване на аналитични заявки без проблем с производителността. Оперативният анализ в реално време предоставя:
- хибридна структура
- транзакционните и аналитични заявки могат да се изпълняват едновременно
- не причинява проблеми с производителността и забавянето.
- проста реализация.
Тази функция може да преодолее недостатъците на традиционната аналитична среда. Основната тема на тази функция е, че индексът на хранилището на колони поддържа копие на данни, без да засяга производителността на транзакционната система. Тази тема позволява на аналитичните заявки да се изпълняват, без да се засяга производителността. Така че това минимизира въздействието върху производителността. Основното ограничение на тази функция е, че не можем да събираме данни от различни източници на данни.
Неклъстериран индекс на съхранение на колони
SQL Server 2016 въвежда обновяем „Неклъстерен индекс на хранилище на колони“. Индексът на неклъстеризираното хранилище на колони е индекс, базиран на колони, който осигурява предимства на производителността за аналитични заявки. Тази функция ни позволява да създадем рамката за оперативен анализ в реално време. Това означава, че можем да изпълняваме транзакции и аналитични заявки едновременно. Имайте предвид, че имаме нужда от месечни общи продажби. В традиционен модел трябва да разработим ETL задачи, витрина с данни и хранилище за данни. Но в оперативни анализи в реално време можем да го направим, без да изискваме склад за данни или промени в структурата на OLTP. Трябва само да създадем подходящ индекс на хранилище с неклъстерирани колони.
Архитектура на индекса на хранилище с неклъстерирани колони
Нека накратко да разгледаме архитектурата на индекса на неклъстеризираното хранилище на колони и работещия механизъм. Индексът на неклъстеризираното хранилище на колони съдържа копие на част или на всички редове и колони в основната таблица. Основната тема на индекса на неклъстеризираното хранилище на колони е да поддържа копие на данните и да използва това копие на данните. Така че този механизъм минимизира въздействието върху производителността на транзакционната база данни. Индексът на неклъстеризираното хранилище на колони може да създаде една или повече от една колони и може да приложи филтър към колони.
Когато вмъкнем нов ред в таблица, която има неклъстериран индекс на хранилището на колони, първо, SQL Server създава „група на редове“. Rowgroup е логическа структура, която представлява набор от редове. След това SQL Server съхранява тези редове във временно хранилище. Името на това временно съхранение е “deltastore”. SQL Server използва тази област за временно съхранение, тъй като този механизъм подобрява съотношението на компресия и намалява фрагментацията на индекса. Когато броят на редовете достигне 1 048 577, SQL Server затваря състоянието на групата редове. SQL Server компресира тази група редове и променя състоянието на „компресирано“.
Сега ще създадем таблица и ще добавим индекса на хранилището на неклъстерирани колони.
ПРОСТЪПНЕТЕ ТАБЛИЦА, АКО СЪЩЕСТВУВА Analysis_TableTestCREATE TABLE Analysis_TableTest(ID INT ПЪРВЕН КЛЮЧ ИДЕНТИФИКАЦИЯ(1,1),Continent_Name VARCHAR(20),Country_Name VARCHAR(20),City_Name VARCHAR(20),Sales_GOINT_AmPro>СЪЗДАВАНЕ НА НЕКЛУСТРИРАН ИНДЕКС НА COLUMNSTORE [NonClusteredColumnStoreIndex] ВКЛЮЧЕНО [dbo].[Analysis_TableTest]( [Име_на_страна], [Име_на_град], Sales_Amnt)С (DROP_EXISTING) =ИЗКЛЮЧЕНО, COMPRES 0 [ON_EXISTING_OFF, COMPRES>]В тази стъпка ще вмъкнем няколко реда и ще разгледаме свойствата на индекса на хранилището на неклъстерирани колони.
INSERT INTO Analysis_TableTest VALUES('Европа','Германия','Мюнхен','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')GOТази заявка ще покаже състоянията на групата редове, общия брой на размера на редовете и други стойности.
SELECT i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, CSRowGroups.*, 100*(общо_редове - ISNULL(deleted_rows,0))/общо_редове AS PercentFull FROM sys.indexes КАТО i ПРИСЪЕДИНЕТЕ се към sys.column_store_row_groups КАТО CSRowGroups ON i.object_id =CSRowGroups.object_id И i.index_id =CSRowGroups.index_id ПОРЪЧАЙТЕ BY object_name(i.object_id;preupname_id;preupname_id;
Изображението по-горе ни показва състоянието на deltastore и общия брой редове, които не са компресирани. Сега ще попълним повече данни в таблицата и когато броят на редовете достигне 1 048 577, SQL Server ще затвори първата група редове и ще отвори нова група от редове.
INSERT INTO Analysis_TableTest VALUES('Европа','Германия','Мюнхен','100','12')INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180',' 19')INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')GO 2000000
SQL Server ще компресира тази група редове и ще създаде нова група редове. Опцията „COMPRESSION_DELAY“ ни позволява да контролираме колко дълго групата от редове чака в затворено състояние.
Когато изпълним командите за поддръжка на индекса (реорганизиране, повторно изграждане), изтритите редове се премахват физически и индексът се дефрагментира.
Когато актуализираме (изтриване + вмъкване) някои редове в тази таблица, изтритите редове са маркирани като „изтрити“, а новите актуализирани редове се вмъкват в deltastore.
Сравнение на ефективността на аналитични заявки
В това заглавие ще попълним данни в таблицата Analysis_TableTest. Вмъкнах 4 милиона записа. (Трябва да тествате тази стъпка и следващите стъпки във вашата тестова среда. Възможно е да възникнат проблеми с производителността и също така командата DBCC DROPCLEANBUFFERS може да навреди на производителността. Тази команда ще премахне всички буферни данни в буферния пул.)
Сега ще изпълним следната аналитична заявка и ще проверим стойностите на производителността.
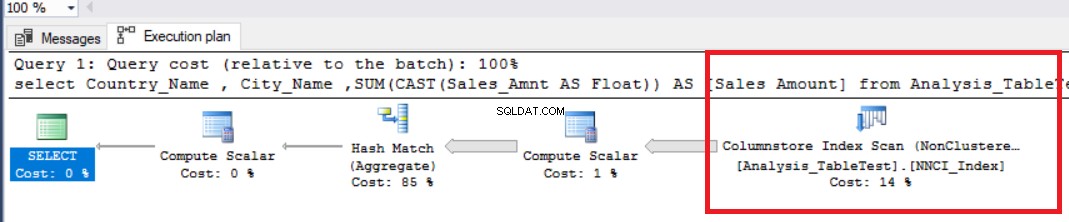
ЗАДАДЕТЕ СТАТИСТИКА ВРЕМЕ НА НАЧАЛНА СТАТИСТИКА IO ONDBCC DROPCLEANBUFFERSИзберете Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount]от Analysis_TableTest group byCountry_Name ,City_Name
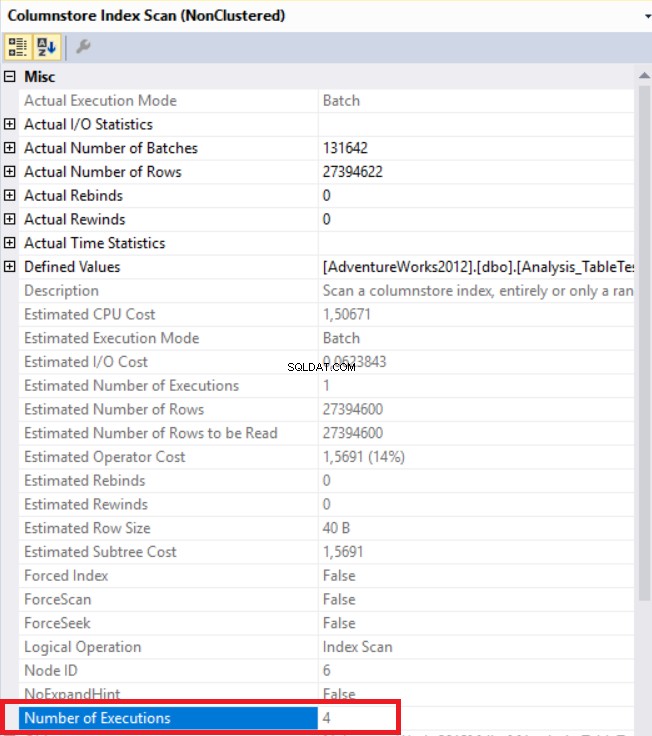
В изображението по-горе можем да видим оператора за сканиране на индекс за неклъстерирано хранилище на колони. Таблицата по-долу показва CPU и времената за изпълнение. Тази заявка отнема 1,765 милисекунди в процесора и се изпълнява за 0,791 милисекунди. Времето на процесора е по-голямо от изминалото време, тъй като планът за изпълнение използва паралелни процесори и разпределя задачите на 4 процесора. Можем да го видим в свойствата на оператора "Columnstore Index Scan". Стойността „Брой изпълнения“ показва това.
Сега ще добавим подсказка към заявката, за да намалим броя на процесорите. Няма да видим никакъв оператор на паралелизъм.
ЗАДАДЕТЕ ВРЕМЕ НА СТАТИСТИКАТА НА НАЧАЛНА СТАТИСТИКА IO ONDBCC DROPCLEANBUFFERSИзберете Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount]от Analysis_TableTest group byCountry_Name ,City_DOPTION1
Таблицата по-долу определя времената за изпълнение. В тази диаграма можем да видим, че изминалото време е по-голямо от времето на процесора, тъй като SQL Server използва само един процесор.
Сега ще деактивираме индекса на хранилището на неклъстерирани колони и ще изпълним същата заявка.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLEGOSET STATISTICS TIME ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSизберете Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS_TOPName) от [TOP Sales_Ameest] от [TOPNaest_на_наименование] от [TOP Sales_Name_група] 1)
Таблицата по-горе ни показва, че индексът на неклъстеризираното хранилище на колони осигурява невероятна производителност при аналитични заявки. Приблизително индексираната заявка в хранилището на колони е пет пъти по-добра от другата.
Заключение
Оперативният анализ в реално време осигурява невероятна гъвкавост, защото можем да изпълняваме аналитични заявки в OLTP системи без никакво забавяне на данните. В същото време тези аналитични заявки не влияят на производителността на OLTP базата данни. Тази функция ни дава възможност да управляваме транзакционните данни и аналитичните заявки в една и съща среда.
Препратки
Индекси на хранилището на колони – Насоки за зареждане на данни
Започнете с Column store за оперативен анализ в реално време
Оперативен анализ в реално време
Допълнително четене:
Индекс на SQL Server Обратно сканиране:разбиране, настройка
Използване на индекси в оптимизирани за паметта таблици на SQL Server