Конкатенацията на два или повече набора от данни най-често се изразява в T-SQL с помощта на UNION ALL клауза. Като се има предвид, че оптимизаторът на SQL Server често може да пренарежда неща като съединения и агрегати, за да подобри производителността, е напълно разумно да се очаква, че SQL Server също ще обмисли пренареждане на входните данни за конкатенация, където това би осигурило предимство. Например, оптимизаторът би могъл да обмисли ползите от пренаписването на A UNION ALL B като B UNION ALL A .
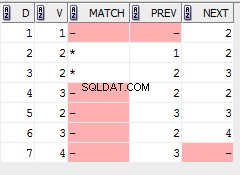
Всъщност оптимизаторът на SQL Server не направите това. По-точно, имаше известна ограничена поддръжка за пренареждане на конкатенация на входа в версиите на SQL Server до 2008 R2, но това беше премахнато в SQL Server 2012 и оттогава не се е появявал отново.
SQL Server 2008 R2
Интуитивно редът на входните данни за конкатенация има значение само ако има цел за ред . По подразбиране SQL Server оптимизира плановете за изпълнение на базата на това, че всички квалифицирани редове ще бъдат върнати на клиента. Когато целта за ред е в сила, оптимизаторът се опитва да намери план за изпълнение, който бързо ще създаде първите няколко реда.
Целите на редовете могат да бъдат зададени по различни начини, например чрез TOP , a FAST n намек за заявка или като използвате EXISTS (което по своята същност трябва да намери най-много един ред). Когато няма цел за ред (т.е. клиентът изисква всички редове), обикновено няма значение в кой ред се четат входните данни за конкатенация:във всеки случай всеки вход ще бъде напълно обработен в крайна сметка.
Ограничената поддръжка във версии до SQL Server 2008 R2 се прилага, когато има цел от точно един ред . При това специфично обстоятелство SQL Server ще пренареди входните данни за конкатенация на базата на очакваната цена.
Това не се прави по време на оптимизация, базирана на разходите (както може да се очаква), а по-скоро като пренаписване след оптимизация в последната минута на нормалния изход на оптимизатора. Това подреждане има предимството, че не увеличава пространството за търсене на план, базирано на разходите (потенциално една алтернатива за всяко възможно пренареждане), като същевременно създава план, който е оптимизиран за бързо връщане на първия ред.
Примери
Следните примери използват две таблици с идентично съдържание:милион реда цели числа от един до милион. Една таблица е купчина без неклъстерирани индекси; другият има уникален клъстериран индекс:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.Expensive( Val bigint NOT NULL); CREATE TABLE dbo.Cheap( Val bigint NOT NULL, CONSTRAINT [PK dbo.Cheap Val] UNIQUE CLUSTERED (Val));GOINSERT dbo.Cheap WITH (TABLOCKX) (Val)SELECT TOP (1000000) Val =ROW_NUMBER() НАД (ПОРЪЧКА ОТ SV1.number)ОТ master.dbo.spt_values КАТО SV1CROSS JOIN master.dbo.spt_values КАТО SV2 ПОРЪЧАЙТЕ ПО ValOPTION (MAXDOP 1);GOINSERT dbo.Скъпо С (TABLOCKX) (Val)ИЗБЕРЕТЕ C.ValFROM КАТО dbo.CheapDMAX. 1);
Без цел на ред
Следната заявка търси едни и същи редове във всяка таблица и връща конкатенацията на двата набора:
ИЗБЕРЕТЕ E.Val ОТ dbo.Expensive AS E КЪДЕТО E.Val МЕЖДУ 751000 И 751005 UNION ALL ИЗБЕРЕТЕ C.ValFROM dbo.Евтино КАТО C КЪДЕ C.Val МЕЖДУ 751000 И 751005;
Планът за изпълнение, създаден от оптимизатора на заявки, е:
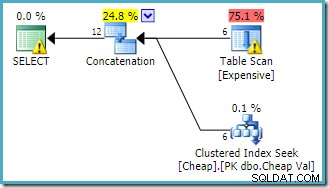
Предупреждението в основния SELECT операторът ни предупреждава за очевидния липсващ индекс в таблицата на heap. Предупреждението в оператора Table Scan се добавя от Sentry One Plan Explorer. Това привлича вниманието ни към цената на I/O на остатъчния предикат, скрит в сканирането.
Редът на входовете към конкатенацията тук няма значение, защото не сме задали цел за ред. И двата входа ще бъдат напълно прочетени, за да се върнат всички редове с резултати. От интерес (въпреки че това не е гарантирано) забележете, че редът на входовете следва текстовия ред на оригиналната заявка. Забележете също, че редът на крайните редове с резултати също не е посочен, тъй като не сме използвали ORDER BY от най-високо ниво клауза. Ще приемем, че това е умишлено и окончателното подреждане не е от значение за разглежданата задача.
Ако обърнем писмения ред на таблиците в заявката по следния начин:
ИЗБЕРЕТЕ C.ValFROM dbo.Cheap AS C, КЪДЕ C.Val МЕЖДУ 751000 И 751005 UNION ALL ИЗБЕРЕТЕ E.Val ОТ dbo.Скъпи AS E, КЪДЕТО E.Val МЕЖДУ 751000 И 751005;
Планът за изпълнение следва промяната, като първо има достъп до клъстерираната таблица (отново, това не е гарантирано):
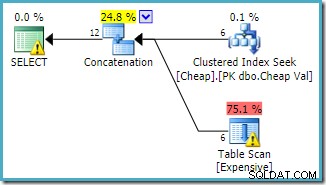
Може да се очаква и двете заявки да имат еднакви характеристики на производителност, тъй като изпълняват едни и същи операции, само в различен ред.
С цел на ред
Ясно е, че липсата на индексиране в таблицата на heap обикновено ще направи намирането на конкретни редове по-скъпо в сравнение със същата операция в клъстерираната таблица. Ако поискаме от оптимизатора план, който връща първия ред бързо, бихме очаквали SQL Server да пренареди входовете за конкатенация, така че първо да се консултира евтината клъстерирана таблица.
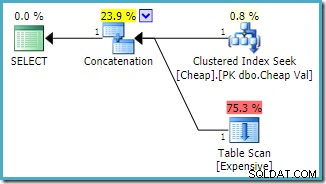
Използване на заявката, която първо споменава таблицата на heap, и използване на намек за заявка FAST 1, за да посочите целта на реда:
ИЗБЕРЕТЕ E.Val ОТ dbo.Скъпи AS E КЪДЕТО E.Val МЕЖДУ 751000 И 751005 UNION ALL ИЗБЕРЕТЕ C.ValFROM dbo.Евтино КАТО C, КЪДЕ C.Val МЕЖДУ 751000 И 751005 ОПЦИЯ);Прогнозният план за изпълнение, създаден на екземпляр на SQL Server 2008 R2 е:
Забележете, че входните данни за конкатенация са пренаредени, за да се намалят прогнозните разходи за връщане на първия ред. Имайте предвид също, че липсващият индекс и остатъчните I/O предупреждения са изчезнали. Нито един проблем не е от значение за тази форма на план, когато целта е да върнете един ред възможно най-бързо.
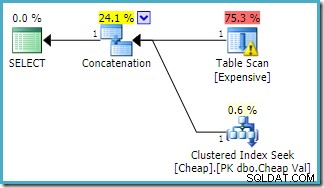
Същата заявка се изпълнява на SQL Server 2016 (използвайки всеки модел за оценка на мощността) е:
SQL Server 2016 не е пренаредил входовете за конкатенация. Предупреждението за I/O на Plan Explorer се върна, но за съжаление оптимизаторът не е дал предупреждение за липсващ индекс този път (въпреки че е уместно).
Общо пренареждане
Както споменахме, пренаписването след оптимизация, което пренарежда входните данни за конкатенация, е ефективно само за:
- SQL Server 2008 R2 и по-стари версии
- Цел на ред точно един
Ако наистина искаме да се върне само един ред, а не план, оптимизиран за бързо връщане на първия ред (но който в крайна сметка пак ще върне всички редове), можем да използваме TOP клауза с извлечена таблица или израз на обща таблица (CTE):
ИЗБЕРЕТЕ НАГОРЕ (1) UA.ValFROM( ИЗБЕРЕТЕ E.Val ОТ dbo.Скъпи КАТО E КЪДЕТО E.Val МЕЖДУ 751000 И 751005 UNION ВСИЧКИ ИЗБЕРЕТЕ C.Val ОТ dbo.Евтино КАТО C КЪДЕ C.Val МЕЖДУ 7510010 ) AS UA;
На SQL Server 2008 R2 или по-стара версия това създава оптималния план за пренаредено въвеждане:
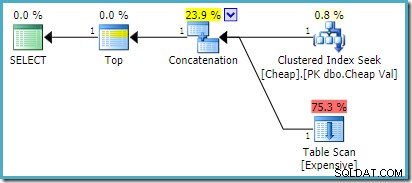
На SQL Server 2012, 2014 и 2016 не се извършва пренареждане след оптимизация:
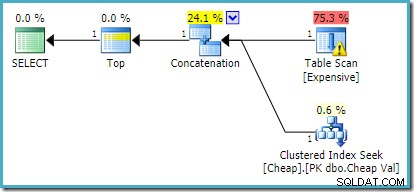
Ако искаме да бъдат върнати повече от един ред, например с помощта на TOP (2) , желаното презаписване няма да бъде приложено на SQL Server 2008 R2, дори ако FAST 1 използва се и подсказка. В тази ситуация трябва да прибягваме до трикове като използването на TOP с променлива и OPTIMIZE FOR намек:
ДЕКЛАРИРАНЕ @TopRows bigint =2; -- Брой действително необходими редове SELECT TOP (@TopRows) UA.ValFROM( SELECT E.Val ОТ dbo.Expensive AS E КЪДЕТО E.Val МЕЖДУ 751000 И 751005 UNION ALL ИЗБЕРЕТЕ C.Val ОТ dbo.Cheap КАТО C КЪДЕ C. Val МЕЖДУ 751000 И 751005) КАТО ОПЦИЯ (ОПТИМИЗИРАНЕ ЗА (@TopRows =1)); -- Само намек
Подсказката за заявката е достатъчна, за да зададе цел за ред от единица, докато стойността на променливата по време на изпълнение гарантира, че желаният брой редове (2) се връща.
Действителният план за изпълнение на SQL Server 2008 R2 е:
И двата върнати реда идват от пренаредения вход за търсене и сканирането на таблицата изобщо не се изпълнява. Plan Explorer показва броя на редовете в червено, тъй като оценката беше за един ред (поради намек), докато два реда бяха открити по време на изпълнение.
Без UNION ALL
Този проблем също не се ограничава до заявки, написани изрично с UNION ALL . Други конструкции като EXISTS и OR може също да доведе до въвеждане на оптимизатора на оператор за конкатенация, който може да страда от липсата на пренареждане на входа. Наскоро имаше въпрос за Stack Exchange на администратори на бази данни с точно този проблем. Преобразуване на заявката от този въпрос, за да използвате нашите примерни таблици:
ИЗБЕРЕТЕ СЛУЧАЙ, КОГАТО СЪЩЕСТВУВА ( ИЗБЕРЕТЕ 1 ОТ dbo. Скъпо КАТО E, КЪДЕТО E.Val МЕЖДУ 751000 И 751005 ) ИЛИ СЪЩЕСТВУВА ( ИЗБЕРЕТЕ 1 ОТ dbo. Евтино КАТО C, КЪДЕ C.Val МЕЖДУ 7510000 И 751005 ИЗБЕРЕТЕ МЕЖДУ 7510000N SE10;
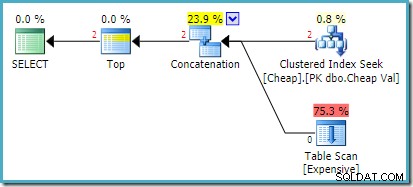
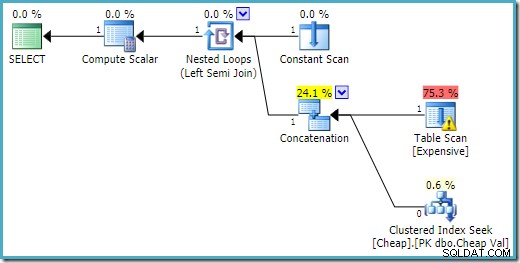
Планът за изпълнение на SQL Server 2016 има таблицата heap на първия вход:
На SQL Server 2008 R2 редът на входовете е оптимизиран, за да отразява целта на един ред на полусъединяването:
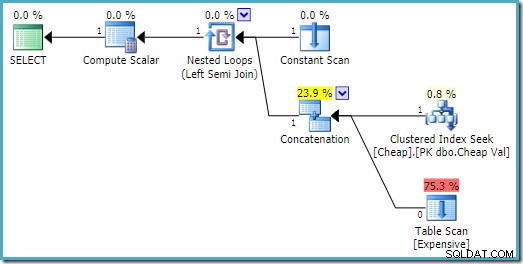
В по-оптималния план сканирането на хепа никога не се изпълнява.
Заобиколни решения
В някои случаи за автора на заявката ще бъде очевидно, че един от входните данни за конкатенация винаги ще бъде по-евтин за изпълнение от другите. Ако това е вярно, е напълно валидно да се пренапише заявката, така че по-евтините входове за конкатенация да се появяват първи в писмен ред. Разбира се, това означава, че авторът на заявки трябва да е наясно с това ограничение на оптимизатора и да е готов да разчита на недокументирано поведение.
По-труден проблем възниква, когато цената на входните данни за конкатенация варира в зависимост от обстоятелствата, може би в зависимост от стойностите на параметрите. Използване на OPTION (RECOMPILE) няма да помогне на SQL Server 2012 или по-нова версия. Тази опция може да помогне на SQL Server 2008 R2 или по-стара версия, но само ако е изпълнено и изискването за цел за един ред.
Ако има опасения относно разчитането на наблюдавано поведение (входове за конкатенация на плана на заявката, съответстващи на текстовия ред на заявката), може да се използва ръководство за план, за да се принуди формата на плана. Когато различните поръчки за въвеждане са оптимални за различни обстоятелства, могат да се използват множество ръководства за планове, където условията могат да бъдат точно кодирани предварително. Това обаче едва ли е идеално.
Последни мисли
Оптимизаторът на заявки на SQL Server всъщност съдържа базиран на разходите правило за изследване, UNIAReorderInputs , който е в състояние да генерира вариации на реда за въвеждане на конкатенация и да проучва алтернативи по време на оптимизация, базирана на разходите (а не като еднократно пренаписване след оптимизация).
Това правило в момента не е активирано за общо ползване. Доколкото мога да преценя, той се активира само когато има ръководство за план или USE PLAN намек е налице. Това позволява на машината успешно да наложи план, който е бил генериран за заявка, която отговаря на изискванията за пренаписване на входно пренареждане, дори когато текущата заявка не отговаря на изискванията.
Предполагам, че това правило за проучване е умишлено ограничено до тази употреба, тъй като заявките, които биха се възползвали от пренареждането на входните конкатенации като част от оптимизация, базирана на разходите, се считат за недостатъчно често срещани или може би защото има опасения, че допълнителните усилия няма да се изплатят изключен. Моето собствено мнение е, че пренареждането на въвеждане на оператор за конкатенация винаги трябва да се проучва, когато целта на ред е в сила.
Също така е жалко, че (по-ограниченото) пренаписване след оптимизация не е ефективно в SQL Server 2012 или по-нова версия. Това може да се дължи на тънък бъг, но не можах да намеря нищо за това в документацията, базата от знания или в Connect. Добавих нов елемент за свързване тук.
Актуализация на 9 август 2017 г. :Това вече е поправено под флаг за проследяване 4199 за SQL Server 2014 и 2016, вижте KB 4023419:
КОРЕКЦИЯ:Заявката с UNION ALL и цел на ред може да работи по-бавно в SQL Server 2014 или по-нови версии, когато се сравнява със SQL Server 2008 R2