Тази статия използва проста заявка за изследване на някои дълбоки вътрешни елементи относно заявките за актуализиране.
Примерни данни и конфигурация
Примерният скрипт за създаване на данни по-долу изисква таблица с числа. Ако вече нямате един от тях, скриптът по-долу може да се използва за ефективно създаване на такъв. Получената таблица с числа ще съдържа една колона с цели числа с числа от един до един милион:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Скриптът по-долу създава клъстерирана примерна таблица с данни с 10 000 идентификатора, с около 100 различни начални дати на идентификатор. Колоната за крайна дата първоначално е зададена на фиксираната стойност „99991231“.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Въпреки че точките, направени в тази статия, се прилагат доста общо за всички текущи версии на SQL Server, информацията за конфигурацията по-долу може да се използва, за да се гарантира, че виждате подобни планове за изпълнение и ефекти на производителността:
- SQL Server 2012 Service Pack 3 x64 издание за разработчици
- Максималната памет на сървъра е зададена на 2048 MB
- Четири логически процесора, налични за екземпляра
- Няма активирани флагове за проследяване
- Ниво на изолация на ангажимент за четене по подразбиране
- Опциите за база данни RCSI и SI са деактивирани
Разливи на хеш агрегати
Ако стартирате скрипта за създаване на данни по-горе с активирани действителни планове за изпълнение, хеш агрегатът може да се разлее в tempdb, генерирайки икона за предупреждение:

Когато се изпълнява на SQL Server 2012 Service Pack 3, допълнителна информация за разливането се показва в подсказката:
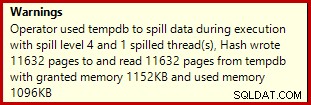
Това разливане може да е изненадващо, като се има предвид, че оценките на входния ред за съвпадението на хеш са точно правилни:
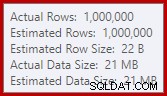
Свикнали сме да сравняваме оценки на вход за сортиране и хеш обединения (само въвеждане за изграждане), но нетърпеливите хеш агрегати са различни. Хеш агрегатът работи чрез натрупване на групирани редове с резултати в хеш таблицата, така че това е броят на изхода редове, които са важни:
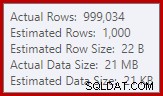
Оценката на мощността в SQL Server 2012 прави доста лошо предположение за броя на очакваните различни стойности (1 000 срещу 999 034 действителни); като следствие от това хеш агрегатът се разлива рекурсивно до ниво 4 по време на изпълнение. „Новият“ оценител на мощността, наличен в SQL Server 2014 нататък, произвежда по-точна оценка за изхода на хеш в тази заявка, така че няма да видите разлив на хеш в този случай:

Броят на действителните редове може да е малко по-различен за вас, като се има предвид използването на генератор на псевдослучайни числа в скрипта. Важният момент е, че разливите на Hash Aggregate зависят от броя на изведените уникални стойности, а не от размера на входа.
Спецификацията за актуализиране
Задачата е да се актуализират примерните данни, така че крайните дати да бъдат зададени на деня преди следващата начална дата (по SomeID). Например, първите няколко реда от примерните данни може да изглеждат така преди актуализацията (всички крайни дати са зададени на 9999-12-31):

След това след актуализацията:
1. Заявка за базова актуализация
Един разумно естествен начин за изразяване на необходимата актуализация в T-SQL е както следва:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
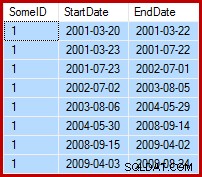
OPTION (MAXDOP 1); Планът за изпълнение (действително) след изпълнение е:
Най-забележителната характеристика е използването на Eager Table Spool за осигуряване на защита за Хелоуин. Това е необходимо за правилна работа тук поради самостоятелното присъединяване на целевата таблица за актуализиране. Ефектът е, че всичко вдясно от макарата се изпълнява до завършване, съхранявайки цялата информация, необходима за извършване на промени в работна таблица на tempdb. След като операцията за четене приключи, съдържанието на работната таблица се възпроизвежда, за да се прилагат промените в итератора за актуализиране на клъстериран индекс.
Ефективност
За да се съсредоточим върху максималния потенциал за производителност на този план за изпълнение, можем да изпълним една и съща заявка за актуализиране няколко пъти. Ясно е, че само първото стартиране ще доведе до промени в данните, но това се оказва незначително съображение. Ако това ви притеснява, не се колебайте да нулирате колоната за крайна дата преди всяко изпълнение, като използвате следния код. Общите точки, които ще направя, не зависят от броя на действително направени промени в данните.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
С деактивирано събиране на планове за изпълнение, всички необходими страници в буферния пул и без нулиране на стойностите на крайната дата между стартиранията, тази заявка обикновено се изпълнява за около 5700 мс на моя лаптоп. Статистическият изход за IO е както следва:(четене напред и броячите на LOB бяха нулеви и са пропуснати поради космически причини)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Броят на сканирането представлява колко пъти е стартирана операция по сканиране. За таблицата с примери, това е 1 за сканирането на клъстериран индекс и 999 034 за всеки път, когато корелираното търсене на клъстериран индекс е отскок. Работната маса, използвана от Eager Spool, има операция по сканиране, стартирана само веднъж.
Логически четения
По-интересната информация в IO изхода е броят на логическите четения:над 6 милиона за примерната таблица и почти 3 милиона за работната маса.
Логическите показания на таблицата с примери са свързани най-вече с търсенето и актуализирането. Търсенето извършва 3 логически четения за всяка итерация:по 1 за основното, междинното и листното ниво на индекса. Актуализацията също струва 3 четения всеки път на ред се актуализира, докато двигателят се движи надолу по b-дървото, за да намери целевия ред. Clustered Index Scan е отговорен само за няколко хиляди четения, по едно на страница прочетете.
Работната маса на макарата също е вътрешно структурирана като b-дърво и отчита множество четения, докато макарата локализира позицията на вложката, докато консумира нейния вход. Може би контраинтуитивно, макарата не отчита логически четения, докато се чете, за да управлява актуализацията на клъстерирания индекс. Това е просто следствие от внедряването:логическо четене се отчита всеки път, когато кодът изпълни BPool::Get метод. Записването в пулта извиква този метод на всяко ниво на индекса; четенето от макарата следва различен път на кода, който не извиква BPool::Get изобщо.
Забележете също, че изходът за IO от статистически данни отчита една обща сума за таблицата с примери, въпреки факта, че е достъпна от три различни итератора в плана за изпълнение (сканиране, търсене и актуализиране). Този последен факт затруднява съпоставянето на логически четения с итератора, който ги е причинил. Надявам се това ограничение да бъде разгледано в бъдеща версия на продукта.
2. Актуализиране с помощта на номера на редове
Друг начин за изразяване на заявката за актуализиране включва номериране на редовете по идентификатор и присъединяване:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
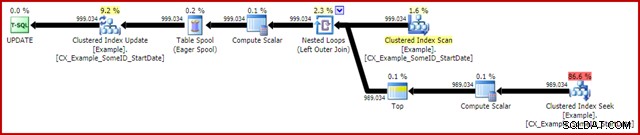
OPTION (MAXDOP 1, MERGE JOIN); Планът след изпълнение е следният:
Тази заявка обикновено се изпълнява за 2950 мс на моя лаптоп, което се сравнява благоприятно с 5700ms (при същите обстоятелства), наблюдавани за оригиналната декларация за актуализиране. Статистическият IO изход е:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Това показва две стартирани сканирания за Примерната таблица (по едно за всеки итератор за клъстерирано индексно сканиране). Логическите показания отново са съвкупност от всички итератори, които имат достъп до тази таблица в плана на заявката. Както и преди, липсата на разбивка прави невъзможно да се определи кой итератор (от двете сканирания и актуализацията) е отговорен за 3-те милиона четения.
Въпреки това мога да ви кажа, че сканирането на клъстерирания индекс отчита само няколко хиляди логически четения всяко. По-голямата част от логическите четения са причинени от клъстерната актуализация на индекса, която се движи надолу по индексното b-дърво, за да намери позицията на актуализацията за всеки ред, който обработва. За момента ще трябва да повярвате на думата ми; скоро ще има повече обяснения.
Недостатъците
Това е почти краят на добрите новини за тази форма на заявката. Той се представя много по-добре от оригинала, но е много по-малко задоволителен поради редица други причини. Основният проблем е причинен от ограничение на оптимизатора, което означава, че той не разпознава, че операцията за номериране на редове произвежда уникален номер за всеки ред в дял SomeID.
Този прост факт води до редица нежелани последствия. От една страна, присъединяването за сливане е конфигурирано да работи в режим на присъединяване много към много. Това е причината за (неизползваната) работна таблица в IO на статистиката (сливането много към много изисква работна таблица за пренавиване на дублирани клавиши за присъединяване). Очакването на присъединяване много към много също означава, че оценката за мощността на изхода на присъединяване е безнадеждно погрешна:
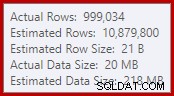
В резултат на това сортирането изисква твърде много предоставяне на памет. Свойствата на основния възел показват, че сортирането би искало 812 752 KB памет, въпреки че му бяха предоставени само 379 440 KB поради ограничената настройка за максимална памет на сървъра (2048 MB). Сортирането всъщност използва максимум 58 968 KB по време на изпълнение:
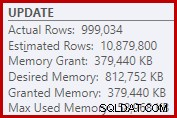
Прекомерната памет дава възможност за кражба на памет от други продуктивни употреби и може да доведе до чакащи заявки, докато паметта стане налична. В много отношения прекомерното предоставяне на памет може да бъде повече проблем, отколкото подценяването.
Ограничението на оптимизатора също обяснява защо е бил необходим намек за обединяване за сливане в заявката за най-добра производителност. Без този намек оптимизаторът неправилно оценява, че хеш присъединяването би било по-евтино от обединяването много към много. Планът за хеш присъединяване работи средно за 3350 мс.
Като крайна отрицателна последица, забележете, че сортирането в плана е различно сортиране. Сега има няколко причини за това сортиране (не на последно място защото може да осигури необходимата защита за Хелоуин), но това е само отличително Сортирайте, защото оптимизаторът пропуска информацията за уникалност. Като цяло е трудно да се хареса много на този план за изпълнение извън изпълнението.
3. Актуализирайте с помощта на LEAD аналитична функция
Тъй като тази статия е насочена предимно към SQL Server 2012 и по-нови, можем да изразим заявката за актуализиране съвсем естествено, използвайки аналитичната функция LEAD. В идеален свят бихме могли да използваме много компактен синтаксис като:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); За съжаление това не е законно. Това води до съобщение за грешка 4108, "Прозоречни функции могат да се появяват само в клаузите SELECT или ORDER BY". Това е малко разочароващо, защото се надявахме на план за изпълнение, който би могъл да избегне самостоятелно присъединяване (и свързаната с него актуализация Halloween Protection).
Добрата новина е, че все още можем да избегнем самоприсъединяването с помощта на общ израз на таблица или производна таблица. Синтаксисът е малко по-подробен, но идеята е почти същата:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
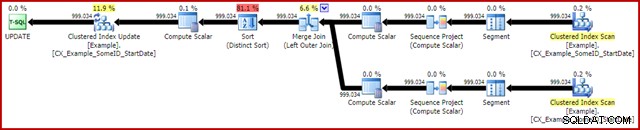
OPTION (MAXDOP 1); Планът след изпълнение е:

Това обикновено се изпълнява за около 3400 мс на моя лаптоп, което е по-бавно от решението за номера на редове (2950ms), но все пак много по-бързо от оригинала (5700ms). Едно нещо, което се откроява от плана за изпълнение, е разливането на сортиране (отново, допълнителна информация за разливане с любезното съдействие на подобренията в SP3):
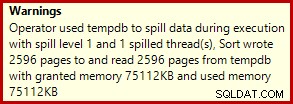
Това е доста малък разлив, но все пак може да повлияе до известна степен на производителността. Странното при това е, че входната оценка за сортирането е точно правилна:
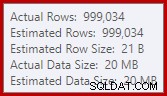
За щастие има „поправка“ за това специфично условие в SQL Server 2012 SP2 CU8 (и други версии – вижте статията KB за подробности). Изпълнението на заявката с активиран флаг за корекция и изисквано проследяване 7470 означава, че сортирането изисква достатъчно памет, за да гарантира, че никога няма да се разлее на диск, ако не бъде надвишен прогнозният размер за сортиране на входа.
LEAD заявка за актуализиране без разлив на сортиране
За разнообразие заявката с активирана корекция по-долу използва синтаксис на извлечена таблица вместо CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Новият план след изпълнение е:

Елиминирането на малкия разлив подобрява производителността от 3400 мс до 3250 мс . Статистическият IO изход е:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Ако сравните това с логическите показания за заявката с номериран ред, ще видите, че логическите показания са намалели от 3,001,808 на 2,999,455 – разлика от 2,353 прочитания. Това съответства точно на премахването на едно сканиране на клъстериран индекс (едно четене на страница).
Може би си спомняте, че споменах, че по-голямата част от логическите четения за тези заявки за актуализация са свързани с актуализацията на клъстерирания индекс и че сканиранията бяха свързани с „само няколко хиляди четения“. Сега можем да видим това малко по-директно, като изпълним проста заявка за преброяване на редове към таблицата с примери:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
IO изходът показва точно разликата от 2353 логически четения между номера на реда и актуализациите на потенциалните клиенти:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
По-нататъшно подобрение?
Фиксираната за разливане водеща заявка (3250ms) все още е доста по-бавна от заявката с номер с двоен ред (2950ms), което може да е малко изненадващо. Интуитивно може да се очаква, че една функция за сканиране и анализ (Window Spool и Stream Aggregate) ще бъде по-бърза от две сканирания, два набора номериране на редове и обединяване.
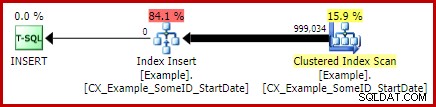
Независимо от това, нещото, което изскача от плана за изпълнение на водещата заявка, е сортирането. Той също присъстваше в заявката с номериран ред, където допринесе за защита на Хелоуин, както и за оптимизиран ред на сортиране за актуализацията на клъстерирания индекс (която има зададено свойство DMLRequestSort).
Работата е там, че това сортиране е напълно ненужно в плана за водеща заявка. Не е необходимо за защитата на Хелоуин, защото самоприсъединяването е изчезнало. Не е необходимо и за оптимизиран ред на сортиране на вмъкване:редовете се четат в ред на клъстерни ключове и в плана няма нищо, което да нарушава този ред. Истинският проблем може да се види, като се разгледат свойствата на сортиране:

Обърнете внимание на раздела „Поръчай по“ там. Сортирането се подрежда по SomeID и StartDate (клъстерираните индексни ключове), но също и по [Uniq1002], който е унификаторът. Това е следствие от недекларирането на клъстерирания индекс като уникален, въпреки че предприехме стъпки в заявката за популация от данни, за да гарантираме, че комбинацията от SomeID и StartDate всъщност ще бъде уникална. (Това беше умишлено, за да мога да говоря за това.)
Въпреки това, това е ограничение. Редовете се четат от клъстерирания индекс по ред и съществуват необходимите вътрешни гаранции, така че оптимизаторът да може безопасно да избегне това сортиране. Това е просто пропуск, че оптимизаторът не разпознава, че входящият поток е сортиран по uniquifier, както и по SomeID и StartDate. Той разпознава, че поръчката (SomeID, StartDate) може да бъде запазена, но не и (SomeID, StartDate, uniquifier). Отново се надявам, че това ще бъде разгледано в бъдеща версия.
За да заобиколим това, можем да направим това, което трябваше да направим на първо място:да изградим клъстерирания индекс като уникален:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
Ще го оставя като упражнение на читателя, за да покаже, че първите две (не-LEAD) заявки не се възползват от тази промяна в индексирането (пропуснати чисто от съображения за пространство – има много за покриване).
Окончателната форма на заявката за актуализиране на възможни клиенти
С уникалното клъстериран индекс на място, точно същата LEAD заявка (CTE или производна таблица, както желаете) произвежда прогнозния (предварително изпълнение) план, който очакваме:

Това изглежда доста оптимално. Една операция за четене и запис с минимум оператори между тях. Разбира се, изглежда много по-добре от предишната версия с ненужното сортиране, което се изпълнява за 3250 мс, след като избегнатото разливане е премахнато (с цената на малко увеличаване на предоставената памет).
Планът след изпълнение (действителният) е почти същият като плана за предварително изпълнение:

Всички оценки са точно правилни, с изключение на изхода на Window Spool, който е отклонен с 2 реда. Информацията за IO на статистиката е точно същата като преди премахването на сортирането, както бихте очаквали:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
За да обобщим накратко, единствената очевидна разлика между този нов план и непосредствено предишния е, че сортирането (с приблизителен принос на разходите от почти 80%) е премахнато.
Тогава може да е изненада да научите, че новата заявка – без сортирането – се изпълнява за 5000 мс . Това е много по-лошо от 3250ms със сортирането и почти толкова дълго, колкото 5700ms оригиналната заявка за присъединяване на цикъл. Решението за номериране на двойни редове все още е много напред с 2950 ms.
Обяснение
Обяснението е донякъде езотерично и се отнася до начина, по който се обработват ключалките за най-новата заявка. Можем да покажем този ефект по няколко начина, но най-простият вероятно е да разгледаме статистиката за изчакване и заключване с помощта на DMV:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Когато клъстерираният индекс не е уникален и има сортиране в плана, няма значителни изчаквания, само няколко PAGEIOLATCH_UP изчаквания и очакваните SOS_SCHEDULER_YIELDs.
Когато клъстерираният индекс е уникален и сортирането е премахнато, изчакванията са:
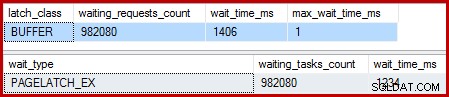
Там има 982 080 ексклузивни ключалки за страници, с време за изчакване, което обяснява почти цялото допълнително време за изпълнение. За да подчертаем, това е почти едно изчакване на фиксатор на актуализиран ред! Може да очакваме фиксатор за всяка промяна на ред, но не и фиксатор изчакайте , особено когато тестовата заявка е единствената дейност в екземпляра. Чаканията на резето са кратки, но има ужасно много.
Мързеливи ключалки
След изпълнението на заявката с прикачен дебъгер и анализатор, обяснението е както следва.
Clustered Index Scan използва мързеливи ключалки – оптимизация, която означава, че ключалките се освобождават само когато друга нишка изисква достъп до страницата. Обикновено ключалките се освобождават веднага след четене или писане. Мързеливите ключалки оптимизират случая, когато сканирането на цяла страница иначе би придобило и освободило едно и също заключване на страница за всеки ред. Когато се използва мързеливо заключване без спор, се взема само едно заключване за цялата страница.
Проблемът е, че конвейерният характер на плана за изпълнение (без блокиращи оператори) означава, че четенията се припокриват с записванията. Когато Clustered Index Update се опита да получи EX ключалка, за да промени ред, тя почти винаги ще установи, че страницата вече е заключена SH (мързеливото заключване, взето от Clustered Index Scan). Тази ситуация води до изчакване.
Като част от подготовката за изчакване и превключването към следващия изпълним елемент в планировчика, кодът внимава да освободи всички мързеливи ключалки. Освобождаването на мързеливия ключалка сигнализира за първия отговарящ на условията сервитьор, който се оказва самият той. И така, имаме странната ситуация, при която нишка се блокира, освобождава мързеливото си ключалка, след което си сигнализира, че отново може да се изпълнява. Нишката се подема отново и продължава, но само след като всичко това пропиляно спиране и превключване, сигнализиране и възобновяване на работата е извършено. Както казах преди, чакането е кратко, но има много.
Доколкото знам, тази странна последователност от събития е по замисъл и по добри вътрешни причини. Въпреки това, няма как да се измъкнем от факта, че има доста драматичен ефект върху представянето тук. Ще направя някои запитвания за това и ще актуализирам статията, ако има публично изявление, което да направя. Междувременно прекомерното изчакване на самозаключване може да е нещо, за което трябва да внимавате с конвейерни заявки за актуализиране, въпреки че не е ясно какво трябва да се направи по въпроса от гледна точка на автора на заявката.
Това означава ли, че подходът за двойно номериране на редове е най-доброто, което можем да направим за тази заявка? Не съвсем.
4. Ръчна защита за Хелоуин
Тази последна опция може да звучи и да изглежда малко налудничаво. Общата идея е да напишете цялата информация, необходима за извършване на промените в променлива на таблица, след което да извършите актуализацията като отделна стъпка.
За да няма по-добро описание, наричам това „ръчен HP“ подход, тъй като концептуално е подобен на записването на цялата информация за промените в Eager Table Spool (както се вижда в първата заявка), преди да задвижите актуализацията от тази спула.
Както и да е, кодът е както следва:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Този код умишлено използва таблична променлива за да се избегнат разходите за автоматично създадени статистически данни, които би довело до използването на временна таблица. Това е добре тук, защото знам формата на плана, която искам, и тя не зависи от оценките на разходите или статистическата информация.
Единственият недостатък на променливата на таблицата (без флаг за проследяване) е, че оптимизаторът обикновено оценява един ред и избира вложени цикли за актуализацията. За да предотвратя това, използвах подсказка за присъединяване за сливане. Отново, това се дължи на познаването точно на формата на плана, която трябва да се постигне.
Планът след изпълнение за вмъкването на променлива в таблицата изглежда точно по същия начин като заявката, която е имала проблем с ключалката, чака:

Предимството на този план е, че не променя същата таблица, от която чете. Не се изисква защита за Хелоуин и няма шанс за смущения в ключалката. Освен това има значителни вътрешни оптимизации за tempdb обекти (заключване и регистриране) и се прилагат други нормални оптимизации за групово зареждане. Не забравяйте, че груповите оптимизации са налични само за вмъквания, а не за актуализации или изтривания.
Планът след изпълнение за изявлението за актуализиране е:
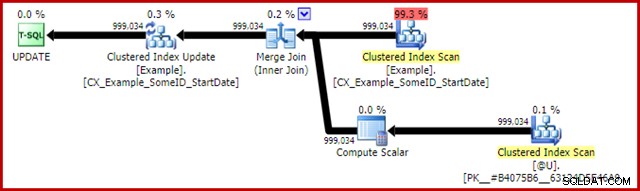
Merge Join тук е ефективният тип един към много. По-важното е, че този план отговаря на изискванията за специална оптимизация, което означава, че сканирането на клъстериран индекс и актуализацията на клъстерирания индекс споделят един и същ набор от редове. Важната последица е, че Актуализацията вече не трябва да намира реда за актуализиране – той вече е позициониран правилно от четенето. Това спестява ужасно много логически четения (и други дейности) при актуализацията.
В нормалните планове за изпълнение няма нищо, което да показва къде се прилага тази оптимизация на споделен набор от редове, но активирането на недокументиран флаг за проследяване 8666 разкрива допълнителни свойства на Update and Scan, които показват, че споделянето на набор от редове се използва, и че се предприемат стъпки, за да се гарантира, че актуализацията е безопасна от проблема за Хелоуин.
Статистическият изход за IO за двете заявки е както следва:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
И двете четения на таблицата с примери включват едно сканиране и едно логическо четене на страница (вижте простата заявка за преброяване на редове по-рано). Таблицата #B9C034B8 е името на вътрешния tempdb обект, поддържащ променливата на таблицата. Общият логически показания за двете заявки е 3 * 2353 =7 059. Работната маса е вътрешното хранилище в паметта, използвано от Window Spool.
Типичното време за изпълнение на тази заявка е 2300 мс . И накрая, имаме нещо, което превъзхожда заявката за двойно номериране на редове (2950 мс), колкото и малко вероятно да изглежда.
Последни мисли
Може да има дори по-добри начини да напишете тази актуализация, които работят дори по-добре от „ръчното решение на HP“ по-горе. Резултатите от производителността може дори да са различни за вашия хардуер и конфигурация на SQL Server, но нито едно от тях не е основната точка на тази статия. Това не означава, че не се интересувам да виждам по-добри заявки или сравнения на производителността – аз съм.
Въпросът е, че в SQL Server се случва много повече, отколкото е изложено в плановете за изпълнение. Надяваме се, че някои от детайлите, обсъдени в тази доста дълга статия, ще бъдат интересни или дори полезни за някои хора.
Добре е да имате очаквания за производителност и да знаете какви форми и свойства на плана обикновено са полезни. Този вид опит и знания ще ви послужат добре за 99% или повече от заявките, които някога ще бъдете помолени да настроите. Понякога обаче е добре да опитате нещо малко странно или необичайно, само за да видите какво се случва и да потвърдите тези очаквания.