В предишната публикация в блога разгледахме основите на мащабирането – какво е то, какви са видовете, какво трябва да имаме, ако искаме да мащабираме. Тази публикация в блога ще се фокусира върху предизвикателствата и начините, по които можем да разширим.
Предизвикателство за намаляване на мащаба
Мащабирането на бази данни не е най-лесната задача по множество причини. Нека се съсредоточим малко върху предизвикателствата, свързани с мащабирането на вашата инфраструктура на база данни.
Услуга за състояние
Можем да различим два различни типа услуги:без състояние и без състояние. Услугите без гражданство са тези, които не разчитат на какъвто и да е вид съществуващи данни. Можете просто да продължите, да стартирате такава услуга и тя за щастие просто ще работи. Не е нужно да се притеснявате за състоянието на данните или услугата. Ако е включен, той ще работи правилно и можете лесно да разпределите трафика между множество екземпляри на услугата, само като добавите още клонинги или копия на съществуващи VM, контейнери или подобни. Пример за такава услуга може да бъде уеб приложение - разгърнато от репо, с правилно конфигуриран уеб сървър, такава услуга просто ще стартира и ще работи правилно.
Проблемът с базите данни е, че базата данни е всичко друго, но не и без състояние. Данните трябва да бъдат вмъкнати в базата данни, те трябва да бъдат обработени и запазени. Образът на базата данни не е нищо повече от няколко пакета, инсталирани върху образа на ОС и без данни и правилна конфигурация е доста безполезен. Това увеличава сложността на мащабирането на базата данни. За услуги без състояние е просто да ги разположите и да конфигурирате някои балансиращи устройства за включване на нови екземпляри в работното натоварване. За бази данни, разгръщащи базата данни, екземплярът е само отправната точка. По-надолу по лентата е управление на данни - трябва да прехвърлите данните от съществуващата си инстанция на базата данни в новата. Това може да бъде значителна част от проблема и времето, необходимо на новите инстанции да започнат да обработват трафика. Само след като данните бъдат прехвърлени, можем да настроим новите възли да станат част от съществуващата топология на репликация - данните трябва да се актуализират върху тях в реално време, въз основа на трафика, който достига до други възли.
Време, необходимо за увеличаване на мащаба
Фактът, че базите данни са услуги с поддържане на състоянието, е пряка причина за второто предизвикателство, пред което сме изправени, когато искаме да мащабираме инфраструктурата на базата данни. Услуги без гражданство - просто ги стартирате и това е всичко. Това е доста бърз процес. За бази данни трябва да прехвърлите данните. Колко време ще отнеме, зависи от множество фактори. Колко голям е наборът от данни? Колко бързо е съхранението? Колко бърза е мрежата? Какви са другите стъпки, необходими за осигуряване на новия възел с новите данни? Данните компресирани/декомпресирани ли са или криптирани/декриптирани в процеса? В реалния свят може да отнеме от минути до няколко часа, за да предоставите данните на нов възел. Това сериозно ограничава случаите, в които можете да разширите средата на вашата база данни. Внезапни, временни скокове на натоварване? Не всъщност, може да са изчезнали отдавна, преди да можете да стартирате допълнителни възли на базата данни. Внезапно и постоянно увеличаване на натоварването? Да, ще бъде възможно да се справите с това чрез добавяне на още възли, но може да отнеме дори часове, за да ги изведете и да им позволите да поемат трафика от съществуващите възли на базата данни.
Допълнително натоварване, причинено от процеса на увеличаване на мащаба
Много е важно да имате предвид, че времето, необходимо за увеличаване на мащаба, е само едната страна на проблема. Другата страна е натоварването, причинено от процеса на мащабиране. Както споменахме по-рано, трябва да прехвърлите целия набор от данни към новодобавени възли. Това не е нещо, което можете да пренебрегнете, в края на краищата може да отнеме часове дълъг процес на четене на данните от диска, изпращането им по мрежата и съхраняването им на ново място. Ако донорът, възелът, от който четете данните, е претоварен, трябва да помислите как ще се държи, ако бъде принуден да извършва допълнителна тежка I/O активност? Ще може ли вашият клъстер да поеме допълнително натоварване, ако вече е под силен натиск и е разпръснат слабо? Отговорът може да не е лесен за получаване, тъй като натоварването на възлите може да бъде под различни форми. Натоварването, свързано с процесора, ще бъде най-добрият сценарий, тъй като I/O активността трябва да е ниска и допълнителните дискови операции ще бъдат управляеми. Натоварването, свързано с I/O, от друга страна, може да забави значително преноса на данни, което сериозно повлияе на способността на клъстера да се мащабира.
Мащабиране на запис
Процесът на мащабиране, който споменахме по-рано, до голяма степен е ограничен до четения за мащабиране. От първостепенно значение е да се разбере, че мащабирането на записите е съвсем различна история. Можете да мащабирате показанията, като просто добавите повече възли и разпределите показанията в повече бекенд възли. Писанията не са толкова лесни за мащабиране. Като за начало, не можете да мащабирате записите просто така. Всеки възел, който съдържа целия набор от данни, очевидно е необходим да обработва всички записи, извършени някъде в клъстера, защото само чрез прилагане на всички модификации към набора от данни той може да поддържа последователност. Така че, като се замислите, без значение как проектирате своя клъстер и каква технология използвате, всеки член на клъстера трябва да изпълни всяко записване. Независимо дали е реплика, репликираща всички записи от неговия главен или възел в клъстер с множество глави като Galera или InnoDB Cluster, изпълнявайки всички промени в набора от данни, извършени на всички други възли на клъстера, резултатът е същият. Записванията не се мащабират просто чрез добавяне на още възли към клъстера.
Как можем да увеличим мащаба на базата данни?
И така, ние знаем пред какви предизвикателства сме изправени. Какви са опциите, които имаме? Как можем да мащабираме базата данни?
Чрез добавяне на реплики
Първо и най-важно, ще мащабираме просто чрез добавяне на още възли. Разбира се, това ще отнеме време и разбира се, това не е процес, който можете да очаквате да се случи веднага. Разбира се, няма да можете да мащабирате записи по този начин. От друга страна, най-типичният проблем, с който ще се сблъскате, е натоварването на процесора, причинено от SELECT заявки и, както обсъдихме, четенията могат просто да бъдат мащабирани чрез просто добавяне на още възли към клъстера. Повече възли за четене означава, че натоварването на всеки един от тях ще бъде намалено. Когато сте в началото на вашето пътуване в жизнения цикъл на вашето приложение, просто приемете, че това е, с което ще се занимавате. Натоварване на процесора, а не ефективни заявки. Малко вероятно е да се наложи да мащабирате записите до много по-нататък в жизнения цикъл, когато приложението ви вече е узряло и трябва да се справите с броя на клиентите.
Чрез разделяне
Добавянето на възли няма да реши проблема с записването, това установихме. Това, което трябва да направите, е разделяне - разделяне на набора от данни в клъстера. В този случай всеки възел съдържа само част от данните, а не всичко. Това ни позволява най-накрая да започнем да мащабираме записите. Да кажем, че имаме четири възела, всеки от които съдържа половината от набора от данни.
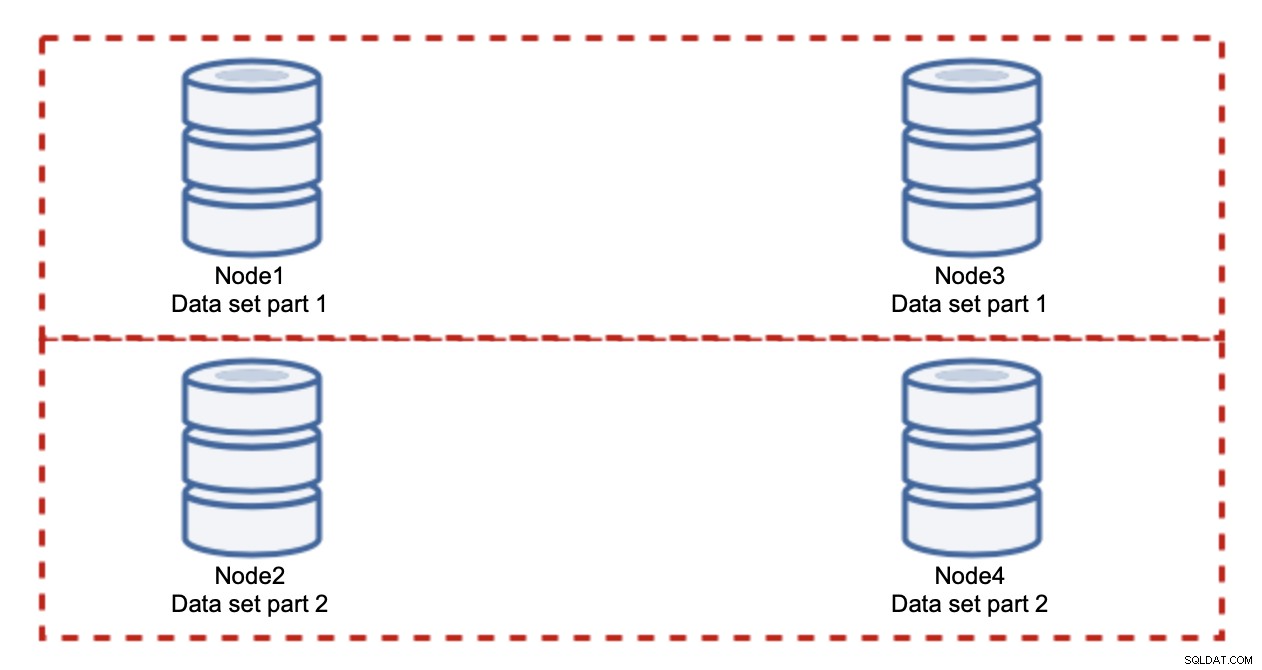
Както виждате, идеята е проста. Ако записът е свързан с част 1 от набора от данни, той ще бъде изпълнен на node1 и node3. Ако е свързан с част 2 от набора от данни, той ще бъде изпълнен на node2 и node4. Можете да мислите за възлите на базата данни като дискове в RAID. Тук имаме пример за RAID10, два чифта огледала, за излишък. В реално изпълнение може да е по-сложно, може да имате повече от една реплика на данните за подобрена висока наличност. Същността е, че ако приемем напълно справедливо разделяне на данните, половината от записванията ще ударят node1 и node3, а другата половина възли 2 и 4. Ако искате да разделите натоварването още повече, можете да въведете третата двойка възли:
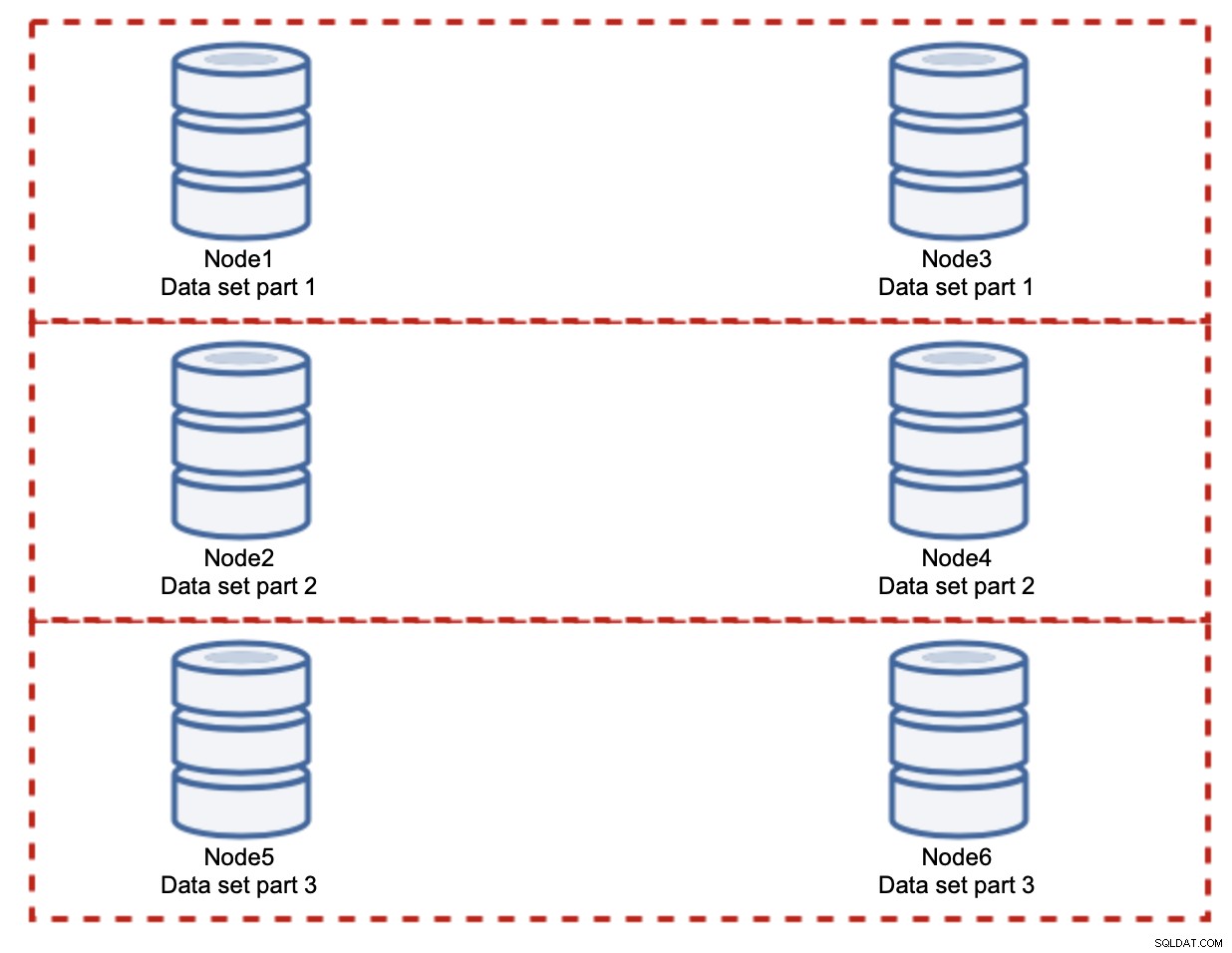
В този случай, отново, ако приемем напълно справедливо разделяне, всяка двойка ще носи отговорност за 33% от всички записвания в клъстера.
Това до голяма степен обобщава идеята за разделяне. В нашия пример, като добавим още фрагменти, можем да намалим активността по запис на възлите на базата данни до 33% от първоначалното I/O натоварване. Както можете да си представите, това не е без недостатъци.
Как ще разбера в кой шард се намират данните ми? Подробностите са извън обхвата на това извикване, но накратко, можете или да внедрите някаква функция в дадена колона (модуло или хеш в колоната „id“) или можете да изградите отделна база данни, където ще съхранявате подробностите за това как се разпространяват данните.
Надяваме се, че сте намерили тази кратка серия от блогове за информативна и че сте разбрали по-добре различните предизвикателства, пред които сме изправени, когато искаме да разширим средата на базата данни. Ако имате някакви коментари или предложения по тази тема, моля не се колебайте да коментирате под тази публикация и да споделите своя опит



