Преди да преминем през проблема с производителността на препратените записи и да го разрешим, трябва да прегледаме структурата на таблиците на SQL Server.
Преглед на структурата на таблицата
В SQL Server основната единица за съхранение на данни са 8-KB страници . Всяка страница започва с 96-байтова заглавка, която съхранява системната информация за тази страница. След това редовете на таблицата ще се съхраняват на страниците с данни последователно след заглавката. В края на страницата таблицата за отместване на редове, която съдържа по един запис за всеки ред, ще бъде съхранена срещу последователността на редовете в страницата. Този запис за отместване на ред показва колко далеч се намира първият байт от този ред от началото на страницата.
SQL Server ни предоставя два типа таблици въз основа на структурата на тази таблица. Групирани таблицата съхранява и сортира данните в страниците с данни въз основа на предварително дефинираните стойности на колона или колони за ключов клъстерен индекс. В допълнение, страниците с данни в клъстерираната таблица се сортират и свързват заедно в свързан списък въз основа на ключовите стойности на клъстерирания индекс. В-дървото структурата на клъстерирания индекс осигурява бърз метод за достъп до данни, базиран на ключовите стойности на клъстерния индекс. Ако се вмъкне нов ред или се актуализира съществуваща ключова стойност в клъстерираната таблица, SQL Server ще съхрани новата стойност в правилната логическа позиция, която отговаря на размера на вмъкнатия ред, без да нарушава критериите за подреждане. Ако вмъкнатата или актуализирана стойност е по-голяма от наличното пространство на страницата с данни, страницата ще бъде разделена на две страници, за да пасне на новата стойност.
Вторият тип таблици са Heap таблица, в която данните не са сортирани в страниците с данни в никакъв ред и страниците не са свързани заедно, тъй като в тази таблица няма дефиниран клъстерен индекс, за да се наложат каквито и да е критерии за сортиране. Проследяването на страниците, които не са сортирани по никакви критерии за подреждане или свързани помежду си в таблицата на купчината, не е лесна мисия. За да опрости процеса на проследяване на разпределението на страниците в таблицата на heap, SQL Server използва Карта за разпределение на индекси (IAM), единствената логическа връзка между страниците с данни в таблицата на heap, чрез запазване на запис за всяка страница с данни в таблицата или индекса в таблицата IAM. За да извлече каквито и да е данни от таблицата на heap, SQL Server Engine сканира IAM, за да намери екстент, който образува 8 страници, които съхраняват исканите данни.
Проблем с препратените записи
Ако нов ред се вмъкне в таблицата на heap, SQL Server Engine ще сканира Свободно пространство на страници (PFS) за проследяване на състоянието на разпределение и използването на пространството на всяка страница с данни, за да се намери първото налично местоположение в страниците с данни, което отговаря на размера на вмъкнатия ред. След това редът ще бъде добавен към избраната страница. Ако вмъкнатата стойност е по-голяма от наличното пространство в страниците с данни, към тази таблица ще бъде добавена нова страница, за да може да се вмъкне новата стойност.
От друга страна, ако съществуващите данни в таблицата на heap бъдат променени, например, актуализирахме низ с променлива дължина с по-голям размер на данните и текущото пространство не отговаря на новите данни, данните ще бъдат преместени в различен физически местоположение и Препратен запис ще бъдат вмъкнати в таблицата на купчината в оригиналното местоположение на данни, за да посочи новото местоположение на тези данни и да опрости местоположението на данните за проследяване. Новото местоположение на данни съдържа също указател, който сочи към указателя за препращане, за да го поддържа актуализиран в случай на преместване на данните от новото местоположение и да предотврати дългата верига от указатели за препращане или да го изтрие. Това може да доведе и до премахване на записа за препращане.
Въпреки че методът за пренасочване на пренасочени записи намалява необходимостта от операции за възстановяване на таблицата с интензивни ресурси и неклъстерирани индекси за актуализиране на адресите на данните всеки път, когато местоположението на данните се промени, той също така удвоява броя на четенията, необходими за извличане на данните. SQL Server първо ще посети старото местоположение, където ще намери препратения запис, който го пренасочва към новото местоположение на данни. След това той ще прочете исканите данни, извършвайки операцията за четене два пъти. В допълнение, проблемът с пренасочените записи води до промяна на последователно прочетените данни в произволно четене на данни, което влияе отрицателно върху ефективността на операцията за извличане на данни с течение на времето.
Нека създадем следния хийп ForwardRecordDemo таблица с помощта на оператора CREATE TABLE T-SQL по-долу:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
След това попълнете тази таблица с 3K записи за тестови цели, като използвате оператора INSERT INTO T-SQL по-долу:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Идентифициране на проблема с препратените записи
Информацията за типа на таблицата и броя на страниците, използвани при съхраняване на данните от таблицата, както и процента на фрагментация на индекса и броя на препратените записи за конкретна таблица може да се види чрез запитване на sys.dm_db_index_physical_stats функция за динамично управление на системата и чрез преминаване към ПОДРОБНО режим, за да върнете броя на препращащите записи. За да направите това, използвайте T-SQL скрипта по-долу:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Както можете да видите от резултата от заявката, предишната таблица е хеп таблицата, в която няма създаден клъстериран индекс за сортиране на данните в страниците и свързване на страниците помежду си. Вмъкнатите в таблицата 3K реда са присвоени на 15 страници с данни, без препратени записи и нулев процент на фрагментация, както е показано в резултата по-долу:

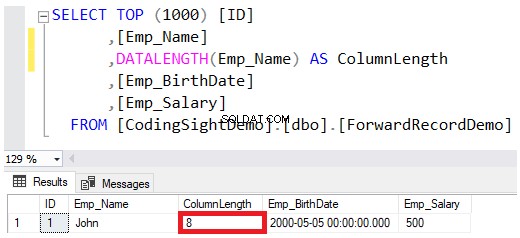
Когато дефинирате типа данни на колона като VARCHAR или NVARCHAR, стойността, посочена в дефиницията на типа данни, е максималният разрешен размер за този низ, без да се резервира напълно тази сума, докато се записват стойностите в страниците с данни. Например, Джон името на служител, вмъкнато в тази таблица, ще запази само 8 байта от максималните 100 байта за тази колона, като се има предвид, че запазването на низа NVARCHAR ще удвои байтовете, необходими за колоната VARCHAR, както е показано в DATALENGTH функция резултат по-долу:
Ако искате да актуализирате стойността на колоната Emp_Name, за да включите пълното име на служителя на John, използвайте оператора UPDATE по-долу:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
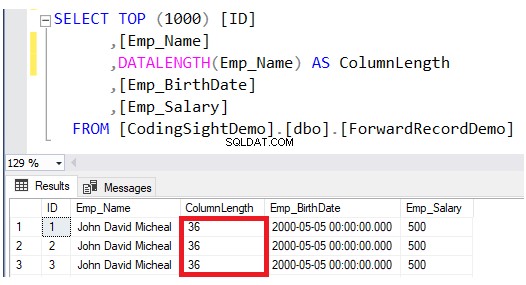
Проверете дължината на актуализираната колона с помощта на DATALENGTH функция. Ще видите, че дължината на колоната Emp_Name в актуализираните редове е разширена с 28 байта за всяка колона, което е около 3,5 допълнителни страници с данни към тази таблица, както е показано в резултата по-долу:
След това проверете броя на препратените записи след операцията за актуализиране, като потърсите функцията за динамично управление на системата sys.dm_db_index_physical_stats. За да направите това, използвайте T-SQL скрипта по-долу:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Както можете да видите, актуализирането на колоната Emp_Name на 1K записи с по-големи стойности на низове, без добавяне на нов запис, ще присвои допълнителните 5 страници към тази таблица, а не 3,5 страници, както се очакваше преди. Това ще се случи поради генериране на 484 препратени записи, за да сочат към новите местоположения на преместените данни. Това може да доведе до това, че таблицата е 33% фрагментиран, както е показано ясно по-долу:

Отново, ако успеете да актуализирате стойността на колоната Emp_Name, за да включите пълното име на служителя на Zaid, използвайте оператора UPDATE по-долу:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
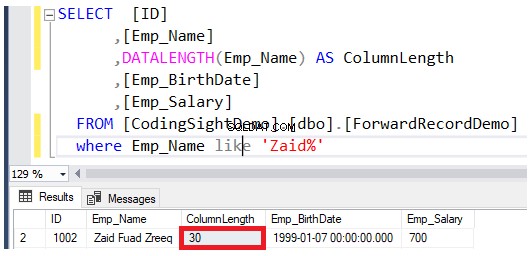
Проверете дължината на актуализираната колона с помощта на DATALENGTH функция. Ще видите, че дължината на колоната Emp_Name в актуализираните редове е разширена с 22 байта за всяка колона, което е около 2,7 допълнителни страници с данни, добавени към тази таблица, както е показано в резултата по-долу:
Проверете броя на препратените записи след извършване на операцията за актуализиране. Можете да направите това, като потърсите функцията за динамично управление на системата sys.dm_db_index_physical_stats, като използвате същия T-SQL скрипт по-долу:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Резултатът ще ви покаже, че актуализирането на колоната Emp_Name в другите 1K записи с по-големи стойности на низове без вмъкване на нов ред ще присвои още 4 страници към тази таблица, а не 2,7 страници, както се очаква. Това ще се случи поради генериране на допълнителни 417 препратени записи с цел посочване на новите местоположения на преместените данни и запазване на същите 33% процент на фрагментация, както е показано по-долу:

Отстраняване на проблема с препратените записи
Най-простият начин да коригирате проблема с препратените записи е да оцените максималната дължина на низа, който ще бъде съхранен в колоната, и да го присвоите с помощта на фиксираната дължина тип данни за тази колона, вместо да използвате типа данни с променлива дължина. Оптималният постоянен начин за отстраняване на проблема с препратените записи е добавянето на Клъстериран индекс на тази маса. По този начин таблицата ще бъде напълно преобразувана в клъстерирана таблица, която се сортира въз основа на ключовите стойности на клъстериран индекс. Той ще контролира реда на съществуващите данни, нововмъкнатите и актуализирани данни, които не отговарят на текущото налично пространство на страницата с данни, както е описано по-рано във въведението на тази статия.
Ако добавянето на клъстериран индекс към тази таблица не е опция за специфични изисквания, като например таблиците за етапи или ETL таблиците, можете временно да преодолеете проблема с пренасочените записи, като наблюдавате препратените записи и изграждате повторно таблицата на heap, за да я премахнете, това ще също така актуализира всички не-клъстерни индекси в тази таблица на heap. Функционалността за повторно изграждане на таблицата на heap е въведена в SQL Server 2008, като се използва ALTER TABLE...REBUILD T-SQL команда.
За да видите влиянието на производителността на препратените записи върху заявките за извличане на данни, нека изпълним заявката SELECT, която извършва търсене въз основа на стойностите на колоната Emp_Name. Въпреки това, преди да изпълните заявката, активирайте статистиката TIME и IO:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
В резултат на това ще видите, че 925 логически операции за четене се извършват за извличане на исканите данни в рамките на 84ms както е показано по-долу:

За да изградите отново таблицата на heap, за да премахнете всички препратени записи, използвайте командата ALTER TABLE…REBUILD:
ALTER TABLE ForwardRecordDemo REBUILD;
Изпълнете отново същия оператор SELECT:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Статистиката за TIME и IO ще ви покаже, че само 21 логически операции за четене в сравнение с 925 логически операции за четене с включени препратени записи се извършват за извличане на исканите данни в рамките на 79 мс :

За да проверите броя на препратените записи след възстановяване на таблицата на heap, изпълнете функцията за динамично управление на системата sys.dm_db_index_physical_stats, използвайте същия T-SQL скрипт по-долу:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Ще видите, че само 21 страници, с предходните 3 страниците, използвани за препратените записи, се присвояват на тази таблица за съхраняване на данните, което е подобно на приблизителния резултат, който сме получили по време на операциите за вмъкване и актуализиране на данни (15+3,5+2,7). След възстановяване на таблицата на кучината всички препратени записи се премахват сега. В резултат на това имаме таблица без фрагментация:

Проблемът с препратените записи е важен проблем с производителността, който администраторите на базата данни трябва да имат предвид, когато планират поддръжка на маса маса. Предишните резултати са извлечени от нашата тестова таблица, която съдържа само 3K записи. Можете да си представите броя на страниците, които ще бъдат пропилени от препратените записи и влошаването на I/O производителността поради четене на голям брой препратени записи при четене от огромни таблици!
Препратки:
- Ръководство за архитектура на страници и екстенти
- dm_db_index_physical_stats (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- Познаването на „Препратени записи“ може да помогне за диагностицирането на трудно откриваеми проблеми с производителността