Миналата година представих решение за симулиране на четими вторични елементи на Availability Group, без да инвестирам в Enterprise Edition. Не за да спирам хората да купуват Enterprise Edition, тъй като има много предимства извън AG, но още повече за тези, които нямат шанс някога да имат Enterprise Edition на първо място:
- Четиви второстепенни елементи на бюджет
Опитвам се да бъда безмилостен защитник на клиента на Standard Edition; почти е шега, че със сигурност – предвид броя на функциите, които получава във всяка нова версия – това издание като цяло е на път за оттегляне. На частни срещи с Microsoft настоявах функциите също да бъдат включени в Standard Edition, особено с функции, които са много по-полезни за малкия бизнес от тези с неограничен хардуерен бюджет.
Клиентите на Enterprise Edition се радват на предимствата за управление и производителност, предлагани от разделянето на таблици, но тази функция не е налична в Standard Edition. Наскоро ми хрумна една идея, че има начин да се постигнат поне някои от предимствата на разделянето на всяко издание и то не включва разделени изгледи. Това не означава, че разделените изгледи не са жизнеспособна опция, която си струва да се обмисли; те са описани добре от други, включително Даниел Хътмахър (Разделени изгледи над разделянето на таблици) и Кимбърли Трип (Разделени таблици срещу Разделени изгледи – защо те изобщо са все още?). Идеята ми е малко по-лесна за изпълнение.
Вашият нов герой:филтрирани индекси
Сега, знам, тази функция за някои е четирибуквена дума; преди да продължите по-нататък, трябва да сте щастливи с филтрираните индекси или поне да сте наясно с техните ограничения. Малко четиво, за да ви дам справедлив баланс, преди да се опитам да ви продам за тях:
- Говоря за няколко недостатъка в Как филтрираните индекси биха могли да бъдат по-мощна функция и посочвам много елементи на Connect, за които да гласувате;
- Пол Уайт (@SQL_Kiwi) говори за проблеми с настройката в Ограничения на оптимизатора с филтрирани индекси, а също и за Неочакван страничен ефект от добавянето на филтриран индекс; и,
- Jes Borland (@grrl_geek) ни казва какво можете (и не можете) да правите с филтрирани индекси.
Прочетете всички тези? И все още ли си тук? Страхотно.
TL;DR на това е, че можете да използвате филтрирани индекси, за да запазите всичките си „горещи данни“ в отделна физическа структура и дори на отделен основен хардуер (може да имате налично бързо SSD или PCIe устройство, но може да „ t дръжте цялата маса).
Бърз пример
Има много случаи на използване, при които част от данните се запитват много по-често от останалите – помислете за магазин за търговия на дребно, който управлява поръчки, пекарна, която планира доставки на сватбени торти, или футболен стадион, който измерва данни за посещаемостта и концесиите. В тези случаи по-голямата част или цялата ежедневна дейност по заявки е свързана с „текущи“ данни.
Нека бъдем прости; ще създадем база данни с много тясна таблица с поръчки:
СЪЗДАЙТЕ БАЗА ДАННИ PoorManPartition;GO ИЗПОЛЗВАЙТЕ PoorManPartition;GO ИЗПОЛЗВАЙТЕ ТАБЛИЦА dbo.Orders( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8.2) --, .други колони...);
Сега да приемем, че имате достатъчно място в бързото си хранилище, за да запазите един месец данни (с много място за отчитане на сезонността и бъдещия растеж). Можем да добавим нова файлова група и да поставим файл с данни на бързото устройство.
ПРОМЕНЯ БАЗА ДАННИ PoorManPartition ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА HotData;ОТИВЯВАНЕ НА БАЗА ДАННИ PoorManPartition ДОБАВЯНЕ НА ФАЙЛ ( Име =N'HotData', FileName =N'Z:\folder\HotData.mdf', Размер =100MB, FileGrowth TO; FILEGROUP)Da =FILEGROUP
Сега, нека създадем филтриран индекс в нашата файлова група HotData, където филтърът включва всичко от началото на ноември 2015 г., а общите колони, участващи в базирани на време заявки, са в списъка с ключ или включва:
СЪЗДАДЕТЕ ИНДЕКС FilteredIndex В dbo.Orders(OrderDate) ВКЛЮЧЕТЕ(OrderTotal) КЪДЕТО OrderDate>='20151101' И OrderDate <'20151201' ON HotData;
Можем да вмъкнем няколко реда и да проверим плана за изпълнение, за да сме сигурни, че обхванатите заявки всъщност могат да използват индекса:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(Ners'dbo).; /* Резултати:index_id rows -------- ---- 1 3 2 2*/ SELECT OrderID, OrderDate, OrderTotal ОТ dbo.Orders WHERE OrderDate>='20151102' И OrderDate <'20151106';
Полученият план за изпълнение, разбира се, използва филтрирания индекс (въпреки че предикатът на филтъра в заявката не съвпада точно с дефиницията на индекса):
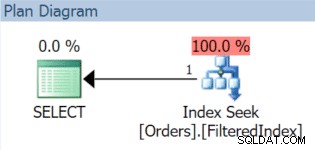
Сега настъпва 1 декември и е време да разменим данните си за ноември и да ги заменим с декември. Можем просто да създадем отново филтрирания индекс с нов предикат на филтъра и да използваме DROP_EXISTING опция:
СЪЗДАДЕТЕ ИНДЕКС FilteredIndex В dbo.Orders(OrderDate) ВКЛЮЧЕТЕ(OrderTotal) КЪДЕТО OrderDate>='20151201' И OrderDate <'20160101' С (DROP_EXISTING =ON) ON HotData;
Сега можем да добавим още няколко реда, да проверим статистиката на дяла и да изпълним предишната ни заявка и нова, за да проверим използваните индекси:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');GO SELECT index_id, rows FROM sys.partitions WHERE object_id =OBJECT_ID(N'dbo.Orders'); /* Резултати:index_id rows -------- ---- 1 5 2 2*/ SELECT OrderID, OrderDate, OrderTotal ОТ dbo.Orders WHERE OrderDate>='20151102' И OrderDate <'20151106'; ИЗБЕРЕТЕ OrderID, OrderDate, OrderTotal ОТ dbo.Orders WHERE OrderDate>='20151202' И OrderDate <'20151204';
В този случай получаваме клъстерно сканиране на индекс със заявката за ноември:
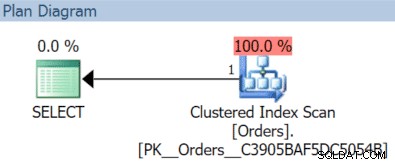
(Но това би било различно, ако имахме отделен, нефилтриран индекс с OrderDate като ключ.)
И няма да го показвам отново, но със заявката за декември получаваме същото филтрирано търсене на индекс, както преди.
Можете също така да поддържате множество индекси, един за текущия месец, един за предходния месец и т.н., и можете просто да ги управлявате отделно (на 1 декември просто махнете индекса от октомври и оставите ноември сам, например) . Можете също така да поддържате множество индекси за по-кратки или по-дълги периоди от време (текуща и предишна седмица, текущо и предишно тримесечие) и т.н. Решението е доста гъвкаво.
Поради ограниченията на филтрираните индекси, няма да се опитвам да налагам това като перфектно решение, нито като пълна замяна на разделянето на таблици или разделените изгледи. Превключването на дял, например, е операция с метаданни, докато повторното създаване на индекс с DROP_EXISTING може да има много записвания (и тъй като не сте на Enterprise Edition, не може да се изпълнява онлайн). Може също да откриете, че разделените изгледи са по-голяма за вашата скорост – има повече работа около поддържането на отделни физически таблици и ограниченията, които правят разделения изглед възможен, но печалбата по отношение на производителността на заявката може да е по-добра в някои случаи.
Автоматизация
Актът на повторно създаване на индекса може да бъде автоматизиран доста лесно, като се използва проста работа, която прави нещо подобно веднъж месечно (или какъвто и да е размерът на вашия "горещ" прозорец):
DECLARE @sql NVARCHAR(MAX), @dt ДАТА =DATEADD(ДЕН, 1-ДЕН(GETDATE()), GETDATE()); SET @sql =N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) КЪДЕ OrderDate>=''' + CONVERT(CHAR(8), @dt, 112) + N''' С (DROP_EXISTING =ON ) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
Можете също така да създавате множество индекси месеци предварително, подобно на създаване на бъдещи дялове предварително – в края на краищата, бъдещите индекси няма да заемат никакво място, докато няма данни, свързани с техните предикати. И можете просто да махнете индексите, които сегментират по-старите данни, които сега искате да станат студени.
Ретроспективно
След като завърших тази статия, разбира се, попаднах на друга публикация на Кимбърли Трип, която трябва да прочетете, преди да продължите с нещо, което препоръчвам тук (и което бях чел, преди да започна):
- Какво ще кажете за филтрирани индекси вместо разделяне?
Поради множество причини Кимбърли е много повече за разделените изгледи за реализиране на нещо подобно на разделянето в Standard Edition; обаче, за определени сценарии, използването на филтрирани индекси все още ме интригува достатъчно, за да продължа с експериментите си. Една от областите, в които филтрираните индекси могат да бъдат полезни, е, когато вашите „горещи“ данни имат множество критерии – не само нарязани по дата, но и по други атрибути (може би искате бързи заявки към всички поръчки от този месец, които са за конкретно ниво на клиент или над определена сума в долари).
Напред...
В бъдеща публикация ще играя с тази концепция на система от по-висок клас, с известен обем и натоварване в реалния свят. Искам да открия разликите в производителността между това решение, нефилтриран покриващ индекс, разделен изглед и разделена таблица. Вътре във виртуална машина на лаптоп с налични само SSD дискове вероятно няма да доведат до реалистични или честни тестове в мащаб.



