Защо да изберете MySQL репликация?
Първо някои основни неща за технологията за репликация. MySQL репликацията не е сложна! Лесно е за внедряване, наблюдение и настройка, тъй като има различни ресурси, които можете да използвате – Google е един от тях. MySQL репликацията не съдържа много конфигурационни променливи за настройка. Логическите грешки на SQL_THREAD и IO_THREAD не са толкова трудни за разбиране и коригиране. MySQL репликацията е много популярна в днешно време и предлага прост начин за внедряване на база данни с висока достъпност. Мощни функции като GTID (глобален идентификатор на транзакция) вместо старомодна позиция на двоичен журнал или полусинхронна репликация без загуби, го правят по-стабилен.
Както видяхме в по-ранна публикация, мрежовата латентност е голямо предизвикателство при избора на решение с висока наличност. Използването на MySQL репликация предлага предимството да не е толкова чувствително към латентност. Той не прилага репликация, базирана на сертифициране, за разлика от Galera Cluster използва групова комуникация и техники за подреждане на транзакции за постигане на синхронна репликация. По този начин няма изискване всички възли да трябва да сертифицират набор за запис и няма нужда да чакате преди комит на другия подчинен или реплика.
Изборът на традиционната MySQL репликация с асинхронен първично-вторичен подход ви осигурява скорост, когато става въпрос за обработка на транзакции от вашия главен обект; не е необходимо да чака подчинените да синхронизират или да извършат транзакции. Настройката обикновено има първичен (главен) и един или повече вторични (подчинени). Следователно това е система без споделено нищо, при която всички сървъри имат пълно копие на данните по подразбиране. Разбира се, има и недостатъци. Целостта на данните може да бъде проблем, ако вашите подчинени устройства не успеят да се репликират поради грешки в SQL и I/O нишки или сривове. Като алтернатива, за да се справите с проблемите с целостта на данните, можете да изберете да приложите MySQL репликацията да бъде полусинхронна (или се нарича полусинхронна репликация без загуби в MySQL 5.7). Как работи това е, че главният трябва да изчака, докато реплика потвърди всички събития от транзакцията. Това означава, че трябва да завърши записите си в релейния дневник и да се флъшне на диска, преди да изпрати обратно на главния с ACK отговор. С активирана полусинхронна репликация, нишките или сесиите в главния трябва да изчакат потвърждение от реплика. След като получи ACK отговор от репликата, може да извърши транзакцията. Илюстрацията по-долу показва как MySQL се справя с полусинхронната репликация.
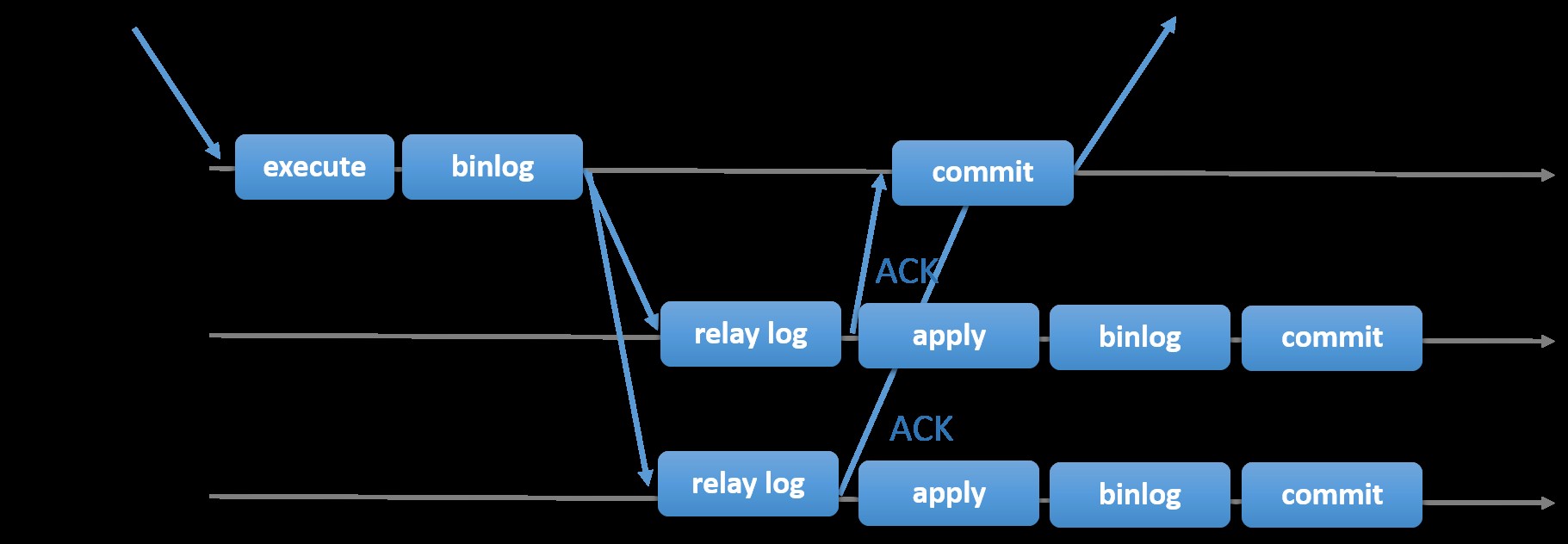 Изображение с любезното съдействие на MySQL Documentation
Изображение с любезното съдействие на MySQL Documentation С тази реализация всички ангажирани транзакции вече се репликират на поне един подчинен в случай на главен срив. Въпреки че полусинхронното не представлява само по себе си решение с висока достъпност, но е компонент за вашето решение. Най-добре е да знаете вашите нужди и съответно да настроите своята полусинхронизирана реализация. Следователно, ако загубата на данни е приемлива, можете вместо това да използвате традиционната асинхронна репликация.
Репликацията, базирана на GTID, е полезна за DBA, тъй като опростява задачата за извършване на отказ, особено когато подчинен е насочен към друг главен или нов главен. Това означава, че с обикновен MASTER_AUTO_POSITION=1 след задаване на правилните идентификационни данни за хост и репликация, той ще започне да се репликира от главния, без да е необходимо да се намират и указват правилните двоични регистрационни x &y позиции. Добавянето на поддръжка на паралелна репликация също засилва нишките за репликация, тъй като добавя скорост за обработка на събитията от регистрационния файл на релето.
По този начин MySQL репликацията е чудесен компонент за избор пред други HA решения, ако отговаря на вашите нужди.
Топологии за MySQL репликация
Внедряването на MySQL репликация в мултиоблачна среда с GCP (Google Cloud Platform) и AWS все още е същият подход, ако трябва да репликирате локално.
Има различни топологии, които можете да настроите и приложите.
Мастер с подчинена репликация (единична репликация)
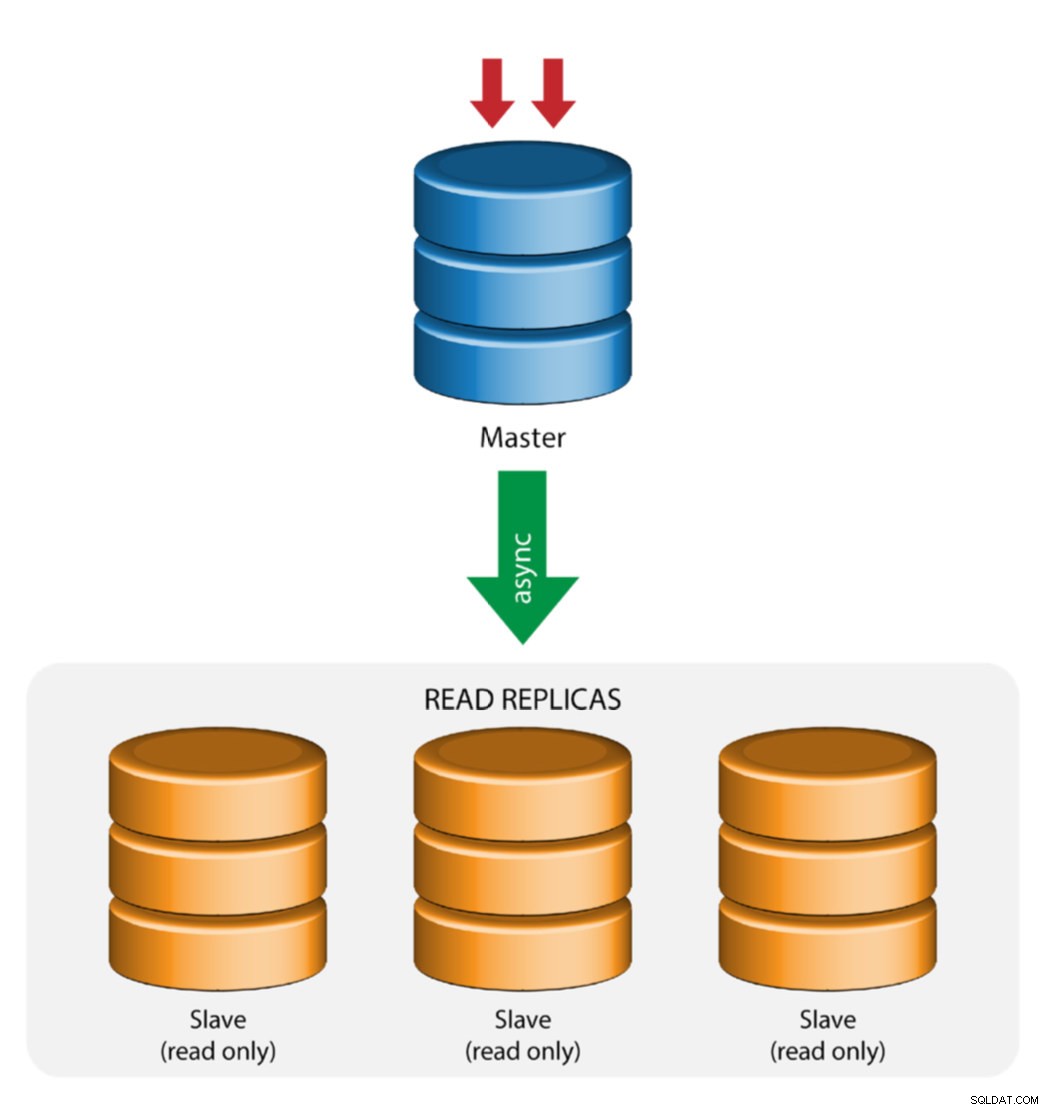
Това е най-простата топология за репликация на MySQL. Един главен получава записи, един или повече подчинени устройства се реплицират от същия главен чрез асинхронна или полусинхронна репликация. Ако определеният главен спада, най-актуалният подчинен трябва да бъде повишен като нов главен. Останалите подчинени подновяват репликацията от новия главен.
Мастер с реле подчинени (верижна репликация)
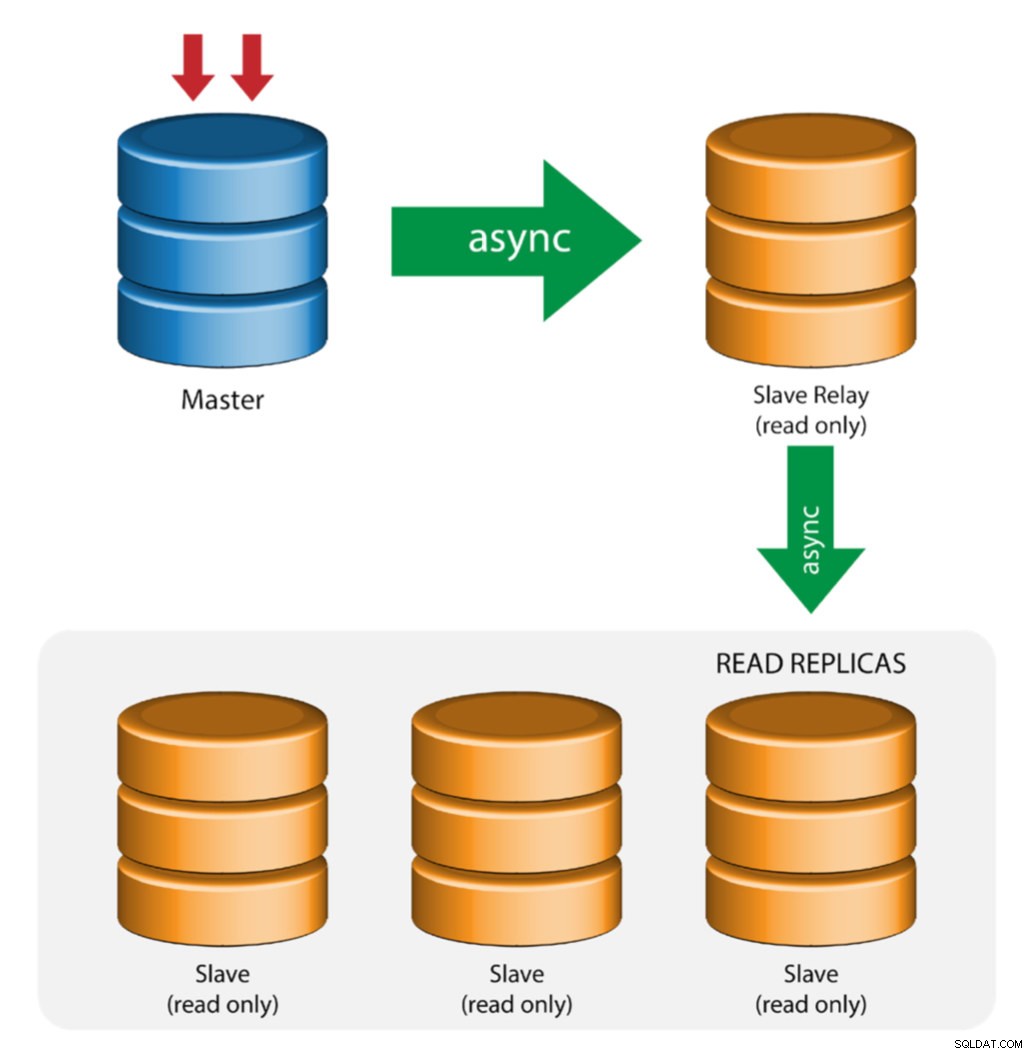
Тази настройка използва междинен главен, който да действа като реле към другите подчинени устройства във веригата за репликация. Когато има много подчинени устройства, свързани към главен, мрежовият интерфейс на главния може да се претовари. Тази топология позволява на прочетените реплики да изтеглят репликационния поток от релейния сървър, за да разтоварят главния сървър. На подчинения релейен сървър трябва да се активира двоичното регистриране и log_slave_updates, при което актуализациите, получени от подчинения сървър от главния сървър, се записват в собствения двоичен дневник на подчинения.
Използването на подчинено реле има своите проблеми:
- log_slave_updates има известно намаление на производителността.
- Закъснението при репликация на подчинения релейен сървър ще генерира забавяне на всички негови подчинени.
- Мошеннически транзакции на подчинения релей сървър ще заразят всички негови подчинени.
- Ако подчинен релейен сървър се повреди и вие не използвате GTID, всички негови подчинени престанат да се репликират и трябва да бъдат повторно инициализирани.
Основно устройство с активен главен код (кръгова репликация)
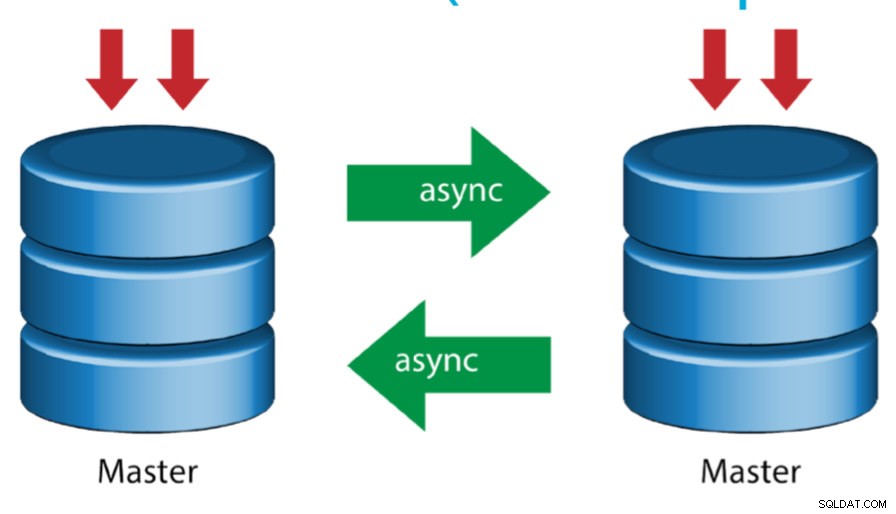
Известна също като топология на пръстена, тази настройка изисква два или повече MySQL сървъра, които действат като главен. Всички господари получават записи и генерират binlogs с няколко предупреждения:
- Трябва да зададете отместване на автоматично увеличение на всеки сървър, за да избегнете сблъсъци на първичен ключ.
- Няма разрешаване на конфликти.
- MySQL репликацията понастоящем не поддържа никакъв протокол за заключване между главен и подчинен, за да гарантира атомарността на разпределената актуализация в два различни сървъра.
- Общата практика е да се пише само до единия главен, а другият главен елемент действа като възел за гореща готовност. Все пак, ако имате подчинени устройства под това ниво, трябва ръчно да превключите към новия главен, ако определеният главен се повреди.
- ClusterControl поддържа тази топология (не препоръчваме множество записващи устройства в настройка за репликация). Вижте този предишен блог за това как да внедрите с ClusterControl.
Основно устройство с резервно копие (множествена репликация)
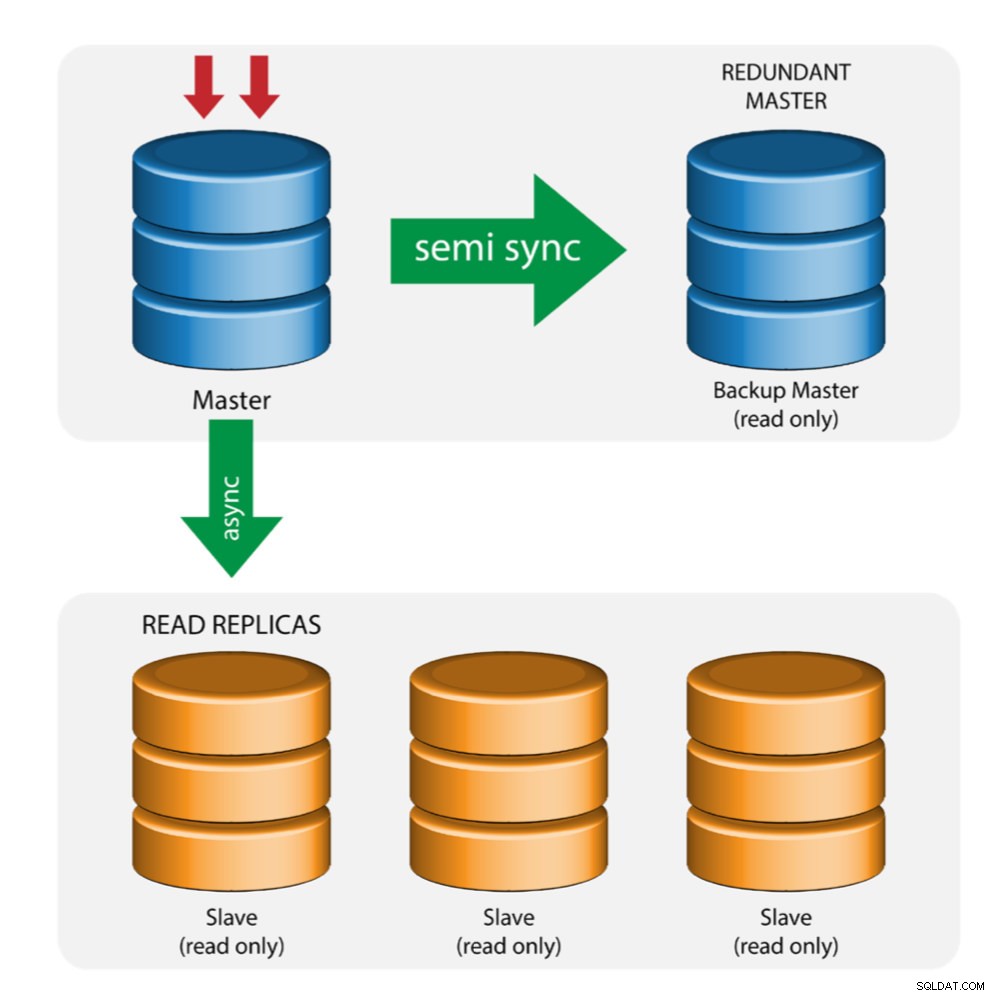
Главният прокарва промени към резервен главен и към един или повече подчинени устройства. Полусинхронна репликация се използва между главен и резервен главен. Главният изпраща актуализация на резервния главен код и изчаква с транзакция. Backup master получава актуализации, записва в своя регистрационен файл на релето и се флуира на диск. Архивният главен след това потвърждава получаването на транзакцията на главния и пристъпва към извършване на транзакция. Полусинхронизираната репликация оказва влияние върху производителността, но рискът от загуба на данни е сведен до минимум.
Тази топология работи добре при извършване на главен отказ при срив в случай, че главният се повреди. Главният резервен сървър действа като сървър в топъл режим на готовност, тъй като има най-голяма вероятност да разполага с актуални данни в сравнение с други подчинени устройства.
Много главни към един подчинен (репликация от множество източници)
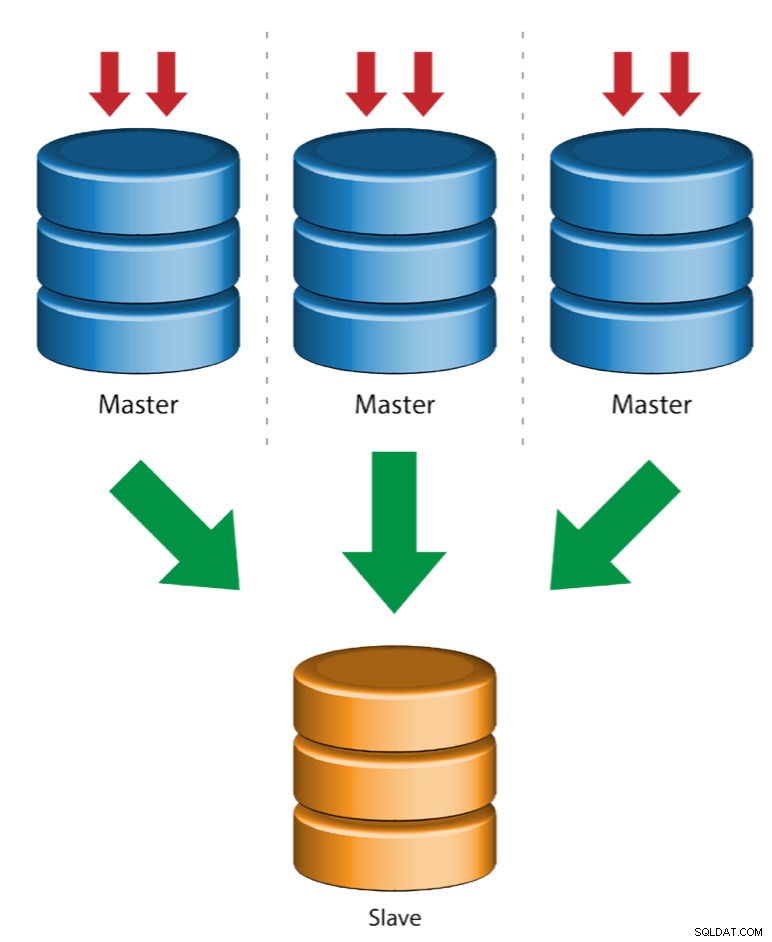
Репликацията от няколко източника позволява на подчинено устройство за репликация да получава транзакции от множество източници едновременно. Репликацията от множество източници може да се използва за архивиране на множество сървъри на един сървър, за сливане на части от таблици и консолидиране на данни от множество сървъри на един сървър.
MySQL и MariaDB имат различни реализации на репликация от няколко източника, където MariaDB трябва да има GTID с gtid-domain-id, конфигуриран за разграничаване на първоначалните транзакции, докато MySQL използва отделен канал за репликация за всеки главен, от който подчинената реплицира. В MySQL главните устройства в топология на репликация с множество източници могат да бъдат конфигурирани да използват репликация, базирана на глобален идентификатор на транзакции (GTID), или базирана на позиция на двоичен регистър репликация.
Повече за репликацията на MariaDB с множество източници можете да намерите в тази публикация в блога. За MySQL, моля, вижте документацията на MySQL.
Galera с ведомство за репликация (хибридна репликация)
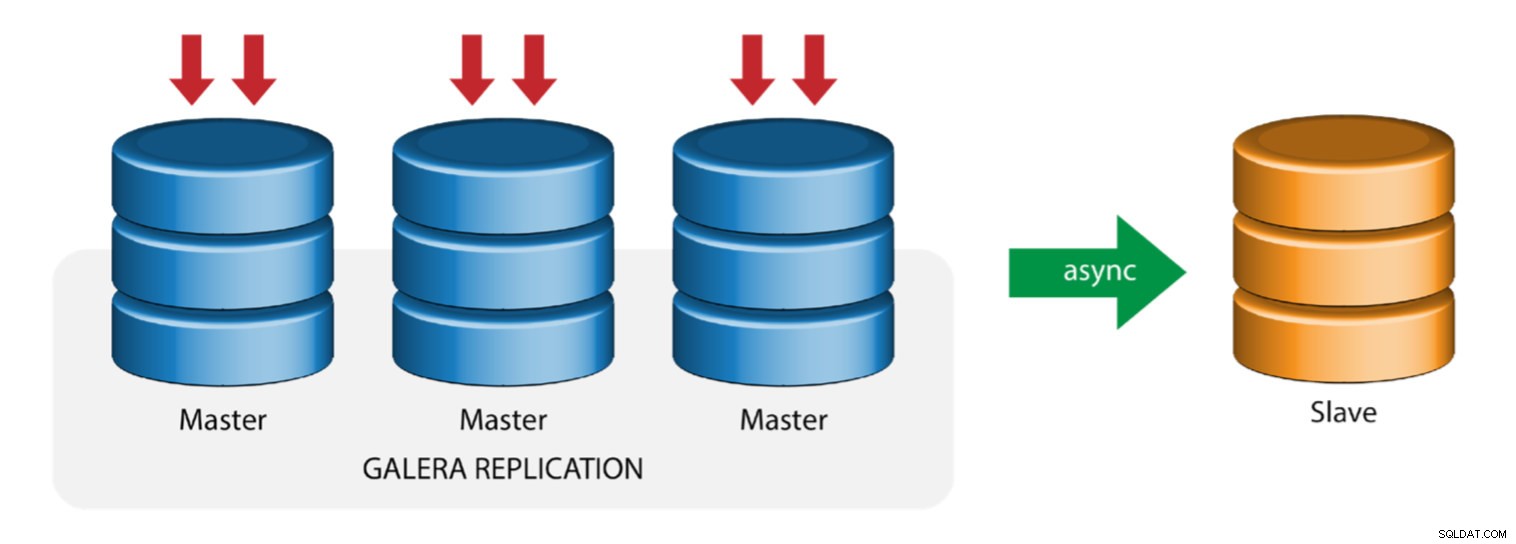
Хибридната репликация е комбинация от MySQL асинхронна репликация и практически синхронна репликация, предоставена от Galera. Разгръщането вече е опростено с внедряването на GTID в MySQL репликация, където настройката и извършването на главен отказ се превърна в лесен процес от страна на подчинените.
Производителността на клъстера на Galera е толкова бърза, колкото и най-бавния възел. Наличието на подчинено устройство за асинхронна репликация може да сведе до минимум въздействието върху клъстера, ако изпращате продължителни заявки за отчитане/OLAP тип към подчиненото устройство или ако изпълнявате тежки задачи, които изискват ключалки като mysqldump. Подчинения може също да служи като резервно копие на живо за аварийно възстановяване на място и извън него.
Хибридната репликация се поддържа от ClusterControl и можете да я разгърнете директно от потребителския интерфейс на ClusterControl. За повече информация как да направите това, моля, прочетете публикациите в блога – Хибридна репликация с MySQL 5.6 и Хибридна репликация с MariaDB 10.x.
Подготовка на GCP и AWS платформи
Проблемът в "реалния свят"
В този блог ще демонстрираме и използваме топологията „Множествена репликация“, при която екземпляри на две различни публични облачни платформи ще комуникират чрез MySQL репликация в различни региони и в различни зони на наличност. Този сценарий се основава на реален проблем, при който една организация иска да архитектира своята инфраструктура на множество облачни платформи за мащабируемост, резервиране, устойчивост/устойчивост на грешки. Подобни концепции биха били приложими за MongoDB или PostgreSQL.
Нека разгледаме американска организация с отвъдморски клон в Югоизточна Азия. Нашият трафик е висок в рамките на азиатския регион. Закъснението трябва да е ниско, когато се обслужва записване и четене, но в същото време базираният в САЩ регион може също да извлича записи, идващи от базирания в Азия трафик.
Потокът на облачната архитектура
В този раздел ще обсъдя архитектурния дизайн. Първо, ние искаме да предложим високо защитен слой, за който нашите възли Google Compute и AWS EC2 могат да комуникират, актуализират или инсталират пакети от интернет, защитени, високодостъпни в случай, че AZ (зоната на достъпност) изпадне, може да се репликира и общуват с друга облачна платформа през защитен слой. Вижте изображението по-долу за илюстрация:

Въз основа на илюстрацията по-горе, под платформата AWS всички възли работят в различни зони за наличност. Той има частна и публична подмрежа, за която всички изчислителни възли са в частна подмрежа. Следователно, той може да излезе извън интернет, за да изтегля и актуализира системните си пакети, когато е необходимо. Той има VPN шлюз, за който трябва да взаимодейства с GCP в този канал, заобикаляйки интернет, но чрез защитен и частен канал. Също като GCP, всички изчислителни възли са в различни зони на наличност, използвайте NAT Gateway за актуализиране на системните пакети, когато е необходимо, и използвайте VPN връзка за взаимодействие с AWS възлите, които се хостват в различен регион, т.е. Азиатско-тихоокеанския регион (Сингапур). От друга страна, базираният в САЩ регион се хоства под us-east1. За достъп до възлите, един възел в архитектурата служи като bastion-node, за който ще го използваме като хост за прескачане и ще инсталираме ClusterControl. Това ще бъде разгледано по-късно в този блог.
Настройване на GCP и AWS среди
Когато регистрирате първия си GCP акаунт, Google предоставя VPC (виртуален частен облак) акаунт по подразбиране. Следователно е най-добре да създадете отделен VPC от стандартния и да го персонализирате според нуждите си.
Нашата цел тук е да поставим изчислителните възли в частни подмрежи или възлите няма да бъдат настроени с публичен IPv4. Следователно и двата обществени облака трябва да могат да разговарят помежду си. AWS и GCP изчислителните възли работят с различни CIDR, както беше споменато по-горе. Следователно, ето следните CIDR:
Изчислителни възли на AWS: 172.21.0.0/16
GCP изчислителни възли: 10.142.0.0/20
В тази настройка на AWS разпределихме три подмрежи, които нямат интернет шлюз, а NAT шлюз; и една подмрежа, която има интернет шлюз. Всяка от тези подмрежи се хоства поотделно в различни зони за наличност (AZ).
ap-southeast-1a =172.21.1.0/24
ap-southeast-1b =172.21.8.0/24
ap-southeast-1c =172.21.24.0/24
Докато е в GCP, се използва подмрежата по подразбиране, създадена във VPC под us-east1, която е 10.142.0.0/20 CIDR. Следователно, това са стъпките, които можете да следвате, за да настроите своята мулти-публична облачна платформа.
-
За това упражнение създадох VPC в us-east1 регион със следната подмрежа 10.142.0.0/20. Вижте по-долу:

-
Резервирайте статичен IP. Това е IP адресът, който ще настроим като клиентски шлюз в AWS
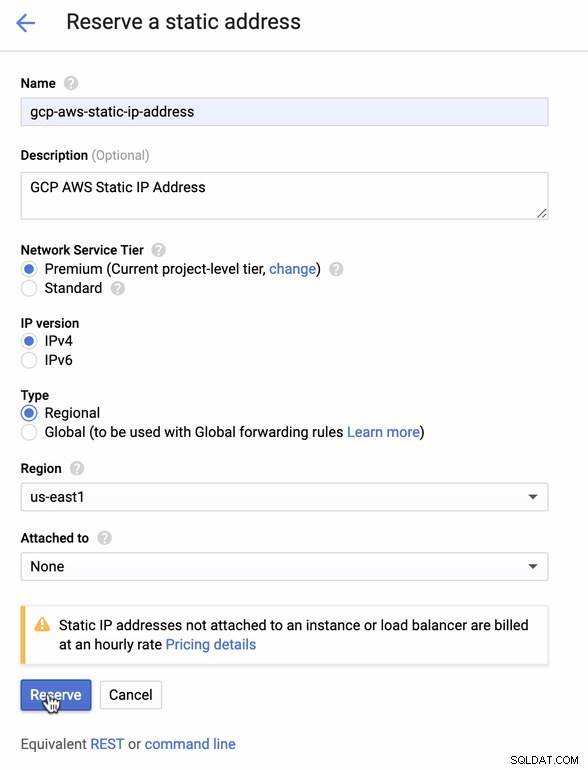
-
Тъй като имаме създадени подмрежи (предоставени като subnet-us-east1 ), отидете на GCP -> VPC Network -> VPC Networks и изберете създадения от вас VPC и отидете на Правилата на защитната стена . В този раздел добавете правилата, като посочите вашето влизане и излизане. По принцип това са входящите/изходящите правила в AWS или вашата защитна стена за входящи и изходящи връзки. В тази настройка отворих всички TCP протоколи от диапазона CIDR, зададен в моя AWS и GCP VPC, за да го направя по-опростен за целите на този блог. Следователно това не е оптималният начин за сигурност. Вижте изображението по-долу:
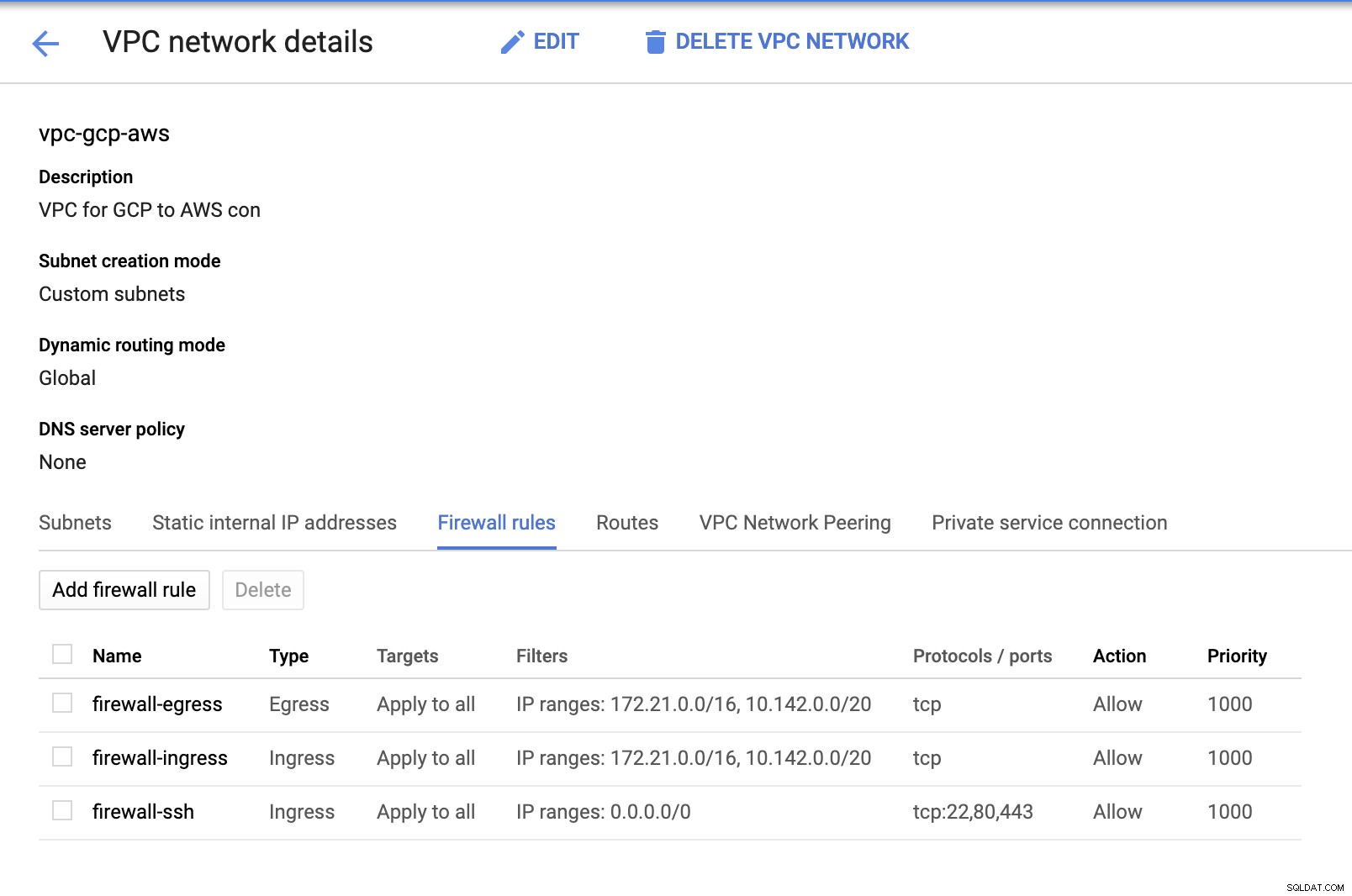
Firewall-ssh тук ще се използва за разрешаване на ssh, HTTP и HTTPS входящи връзки.
-
Сега превключете към AWS и създайте VPC. За този блог използвах CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
-
Създайте подмрежите, за които трябва да ги зададете във всяка AZ (зона на достъпност); и поне резервирайте една подмрежа за публична подмрежа, която ще обработва NAT Gateway, а останалите са за EC2 възли.

-
След това създайте своята таблица с маршрути и се уверете, че "Дестинация" и "Цели" са зададени правилно. За този блог създадох 2 маршрутни таблици. Един, който ще обработва 3 AZ, които моите изчислителни възли ще бъдат присвоени индивидуално и ще бъде назначен без интернет шлюз, тъй като няма да има публичен IP. Тогава другият ще се справи с NAT Gateway и ще има интернет Gateway, който ще бъде в публичната подмрежа. Вижте изображението по-долу:

и както споменахме, моята примерна дестинация за частен маршрут, която обработва 3 подмрежи, показва, че има цел на NAT шлюз плюс цел на виртуален шлюз, която ще спомена по-късно във входящите стъпки.

-
След това създайте „Интернет шлюз“ и го присвоете на VPC, който е бил създаден преди това в секцията AWS VPC. Този интернет шлюз трябва да бъде зададен само като местоназначение към публичната подмрежа, тъй като това ще бъде услугата, която трябва да се свърже с интернет. Очевидно името означава услуга за интернет шлюз.
-
След това създайте "NAT Gateway". Когато създавате "NAT Gateway", уверете се, че сте присвоили своя NAT към публична подмрежа. NAT Gateway е вашият канал за достъп до интернет от вашата частна подмрежа или EC2 възли, които нямат назначен публичен IPv4. След това създайте или задайте EIP (Еластичен IP), тъй като в AWS само изчислителни възли, на които е назначен публичен IPv4, могат да се свързват директно с интернет.
-
Сега под VPC -> Сигурност -> Групи за сигурност (SG) , създаденият от вас VPC ще има SG по подразбиране. За тази настройка създадох „Входящи правила“ с източници, присвоени за всеки CIDR, т.е. 10.142.0.0/20 в GCP и 172.21.0.0/16 в AWS. Вижте по-долу:

За „Изходящи правила“ можете да оставите това както е, тъй като присвояването на правила на „Входящи правила“ е двустранно, което означава, че ще се отваря и за „Изходящи правила“. Обърнете внимание, че това не е оптималният начин за настройка на вашата група за сигурност; но за да улесня тази настройка, направих и по-широк обхват от портове и източник. Също така, протоколът е специфичен само за TCP връзки, тъй като няма да се занимаваме с UDP за този блог.
Освен това можете да оставите VPC -> Сигурност -> Мрежови ACLs недокоснат, стига да не ОТКАЗВА никакви tcp връзки от CIDR, посочен във вашия източник. -
След това ще настроим VPN конфигурацията, която ще се хоства под платформата AWS. Под VPC -> Клиентски шлюзове , създайте шлюза, като използвате статичния IP адрес, който беше създаден по-рано в предишната стъпка. Разгледайте изображението по-долу:
-
След това създайте виртуален частен шлюз и го прикачете към текущия VPC, който създадохме преди това в предишната стъпка. Вижте изображението по-долу:

-
Сега създайте VPN връзка, която ще се използва за връзката от сайт до сайт между AWS и GCP. Когато създавате VPN връзка, уверете се, че сте избрали правилния виртуален частен шлюз и клиентския шлюз, които създадохме в предишните стъпки. Вижте изображението по-долу:
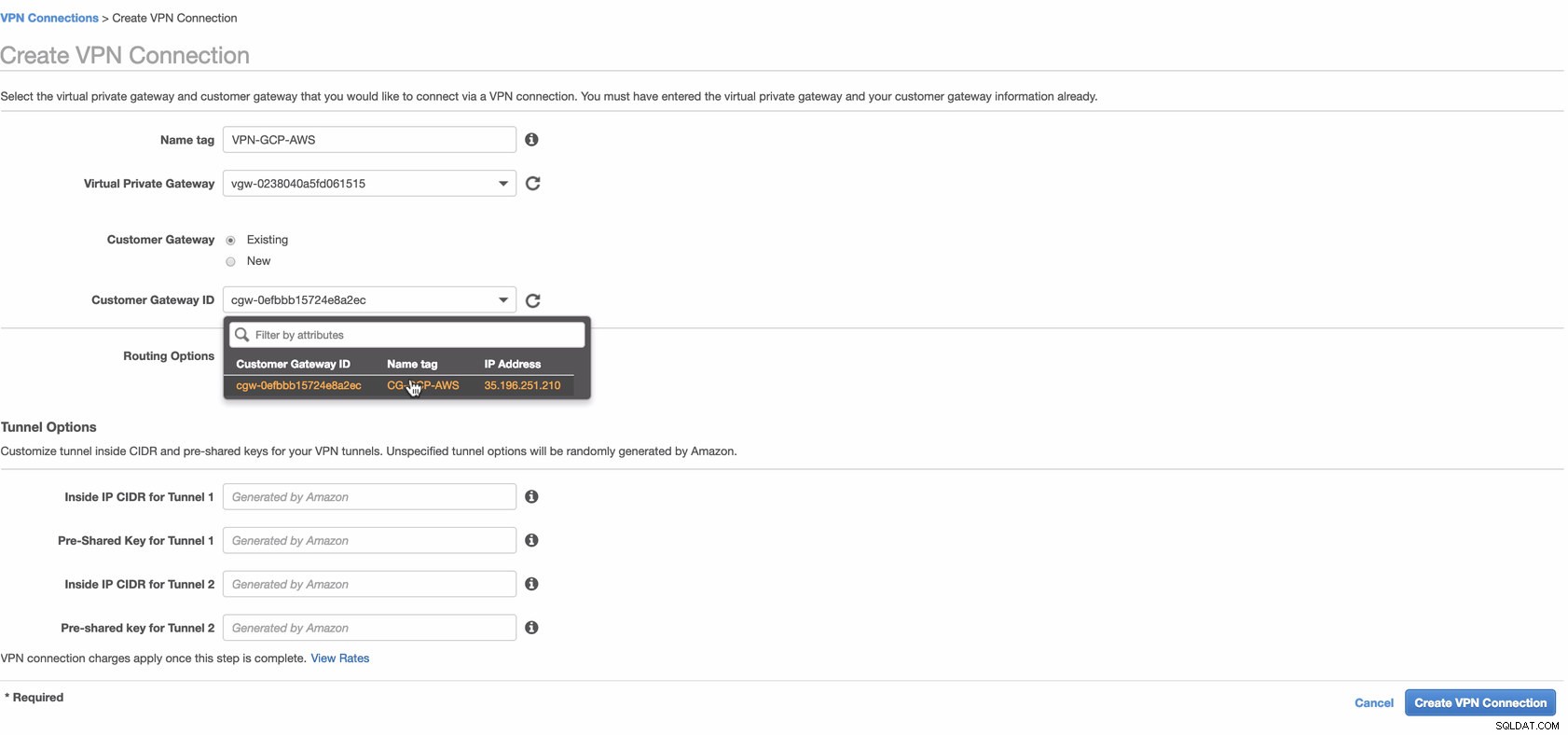
Това може да отнеме известно време, докато AWS създава вашата VPN връзка. Когато вашата VPN връзка е осигурена, може да се чудите защо в раздела Тунел (след като изберете вашата VPN връзка) ще се покаже, че Външният IP адрес Долу е. Това е нормално, тъй като все още няма установена връзка от клиента. Разгледайте примерното изображение по-долу:

След като VPN връзката е готова, изберете вашата създадена VPN връзка и изтеглете конфигурацията. Той съдържа вашите идентификационни данни, необходими за следните стъпки за създаване на VPN връзка от сайт до сайт с клиента.
Забележка: В случай, че сте настроили своя VPN, където IPSEC Е ГО ноСъстояние е НАДОЛУ точно като изображението по-долу

това вероятно се дължи на грешни стойности, зададени на специфични параметри, докато настройвате вашата BGP сесия или облачен рутер. Вижте го тук за отстраняване на неизправности във вашата VPN.
-
Тъй като имаме готова VPN връзка, хоствана в AWS, нека създадем VPN връзка в GCP. Сега нека се върнем към GCP и да настроим клиентската връзка там. В GCP отидете на GCP -> Хибридна свързаност -> VPN . Уверете се, че избирате правилния регион, който е в този блог, ние използваме us-east1 . След това изберете статичния IP адрес, създаден в предишните стъпки. Вижте изображението по-долу:
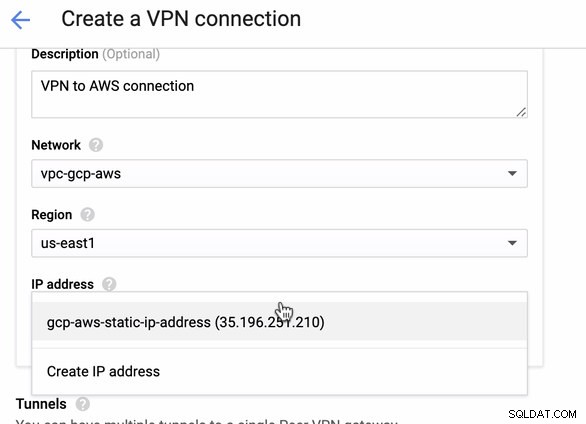
След това в Тунелите раздел, това е мястото, където ще трябва да настроите въз основа на изтеглените идентификационни данни от AWS VPN връзка, която сте създали по-рано. Предлагам да разгледате това полезно ръководство от Google. Например, един от тунелите, които се настройват, е показан на изображението по-долу:
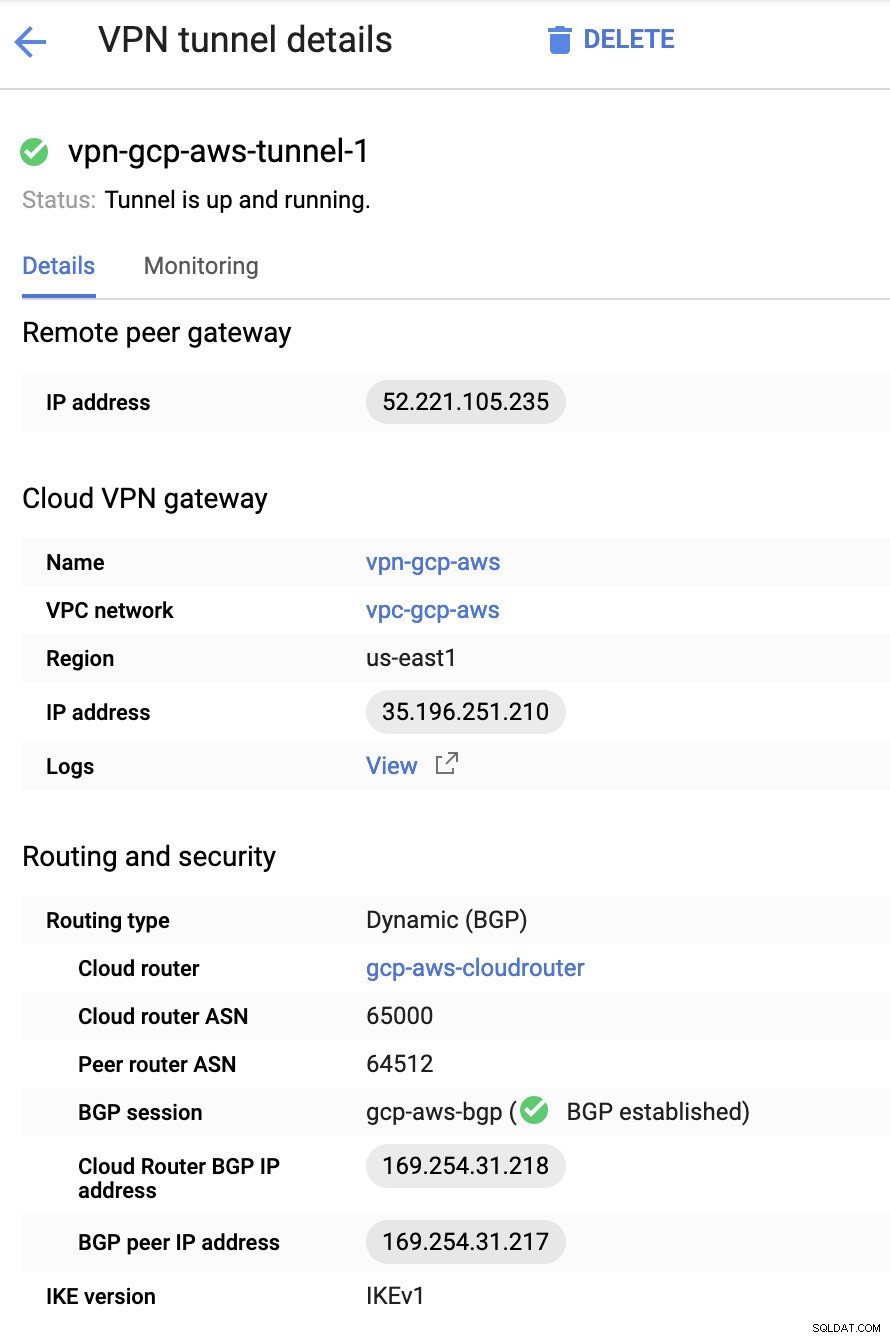
По принцип най-важните неща тук са следните:
- Remote Peer Gateway:IP адрес – Това е IP адресът на VPN сървъра, посочен под Подробности за тунела -> Външен IP адрес . Това не трябва да се бърка със статичния IP, който създадохме под GCP. Това е Cloud VPN шлюз -> IP адрес все пак.
- Облачен рутер ASN – По подразбиране AWS използва 65000. Но вероятно ще получите тази информация от изтегления конфигурационен файл.
- ASN на равностойния рутер – Това е ASN за виртуален частен шлюз който се намира в изтегления конфигурационен файл.
- BGP IP адрес на облачния рутер – това е Customer Gateway намерен в изтегления конфигурационен файл.
- BGP peer IP адрес – това е виртуалния частен шлюз намерен в изтегления конфигурационен файл.
-
Разгледайте примерния конфигурационен файл, който имам по-долу:
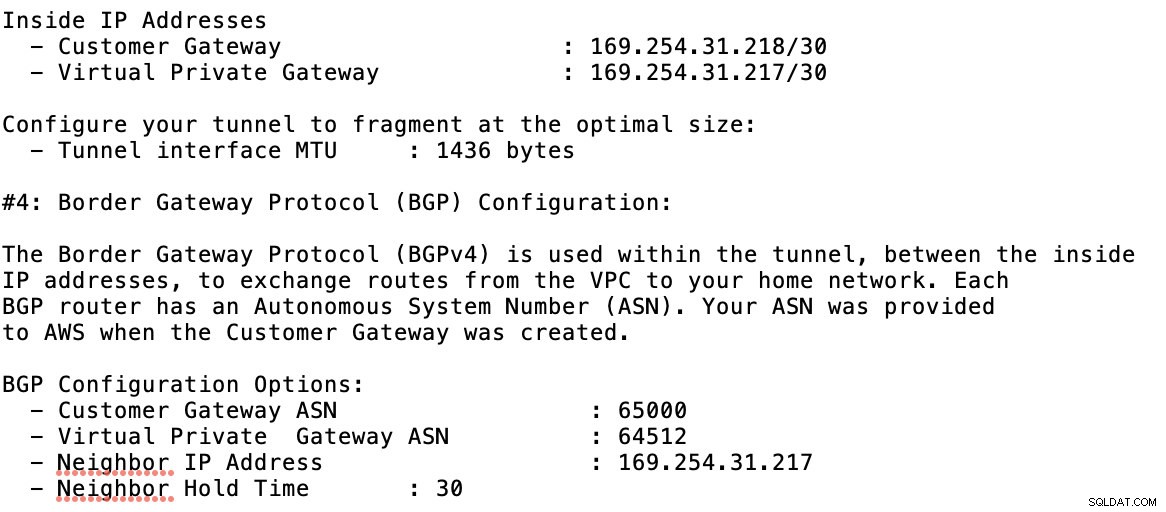
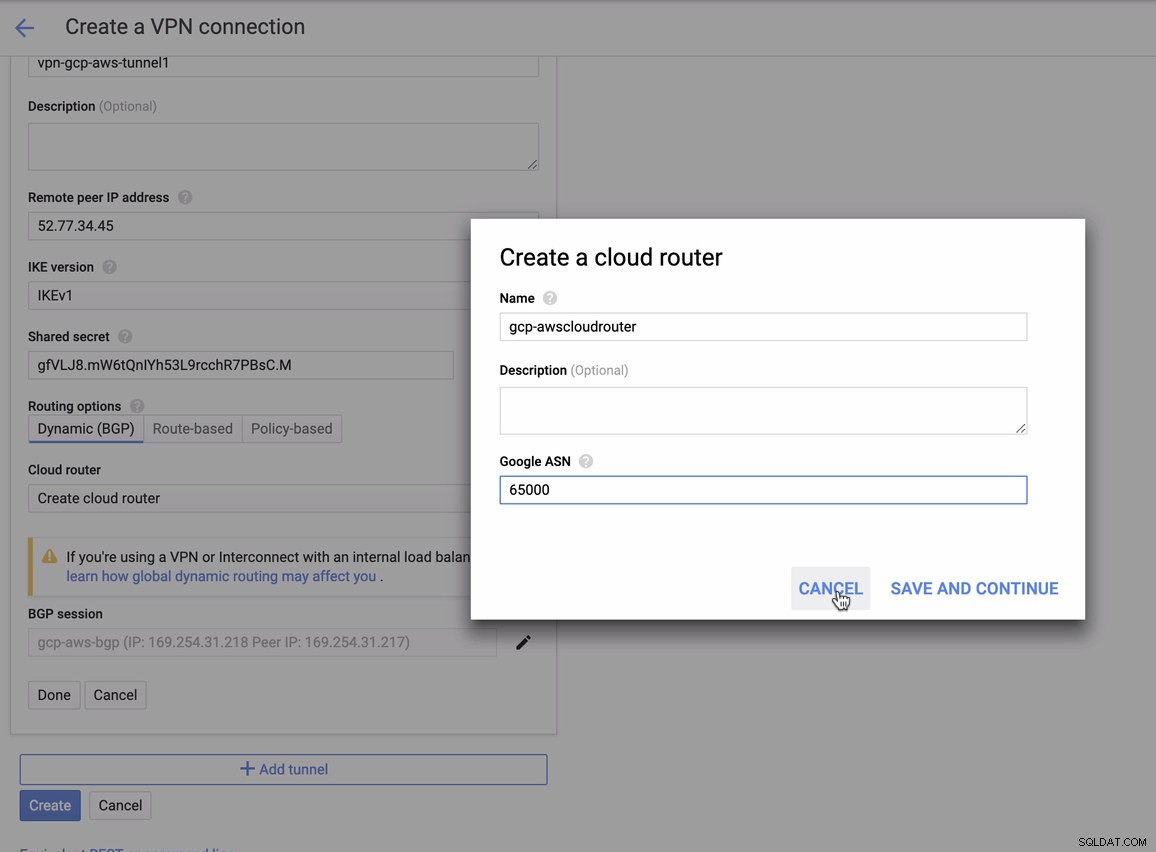
за което трябва да съпоставите това по време на добавяне на вашия тунел под GCP -> Хибридна свързаност -> VPN настройка на свързаността. Вижте изображението по-долу, за което създадох облачен рутер и BGP сесия по време на създаването на примерен тунел:
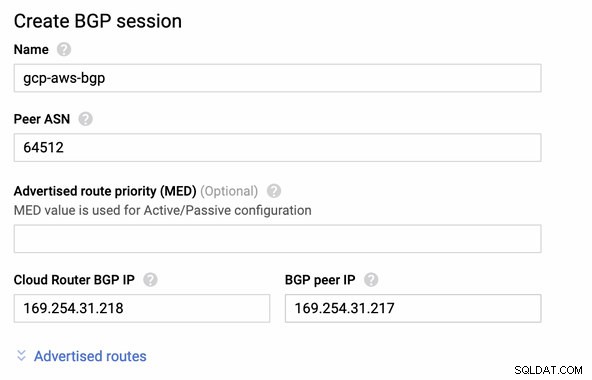
След това BGP сесия като,

Забележка: Изтегленият конфигурационен файл съдържа IPSec конфигурационен тунел, за който AWS също съдържа два (2) VPN сървъра, готови за вашата връзка. Трябва да настроите и двете, така че да имате висока налична настройка. След като се настрои правилно за двата тунела, AWS VPN връзката под раздела Тунели ще покаже, че и двата Външен IP адрес са нагоре. Вижте изображението по-долу:

-
И накрая, тъй като създадохме интернет шлюз и NAT шлюз, попълнете правилно публичните и частните подмрежи с правилна дестинация и Цел както е забелязано на екранната снимка от предишни стъпки. Това може да се настрои, като отидете на Услуги -> Мрежа и доставка на съдържание -> VPC -> Таблици с маршрути и изберете създадените маршрутни таблици, споменати от предишните стъпки. Вижте изображението по-долу:
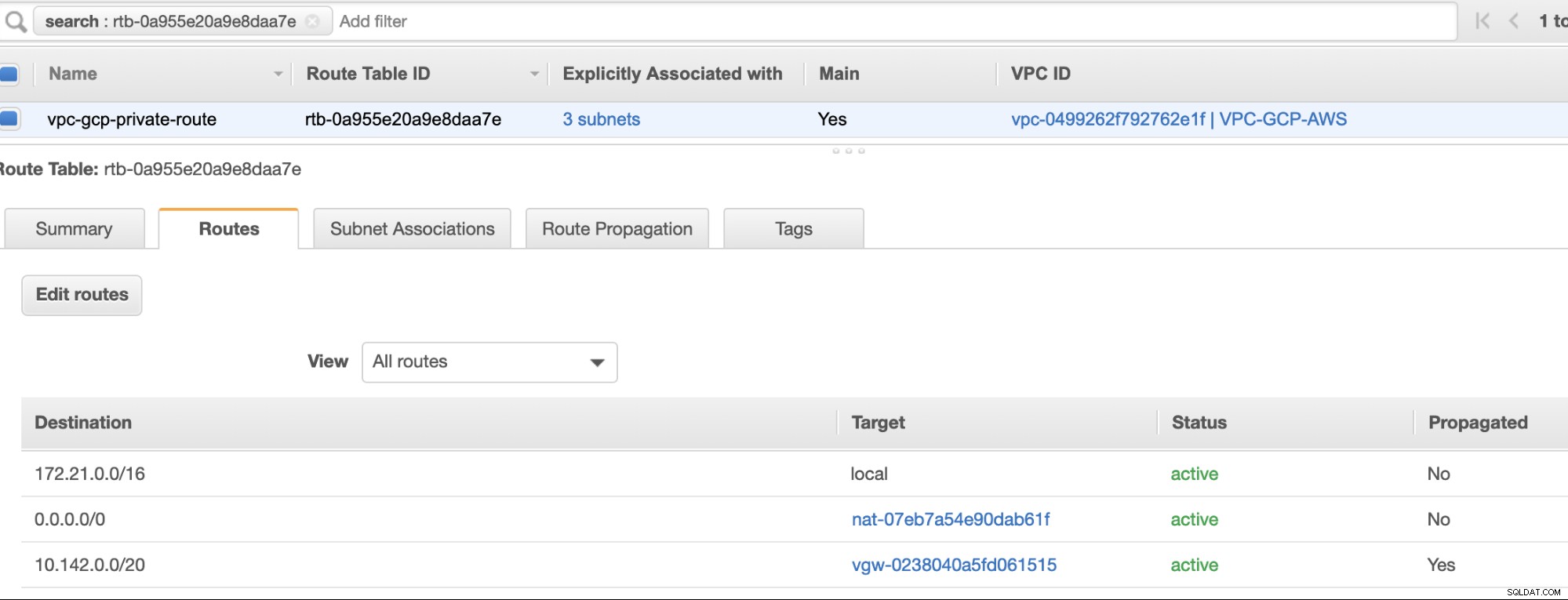
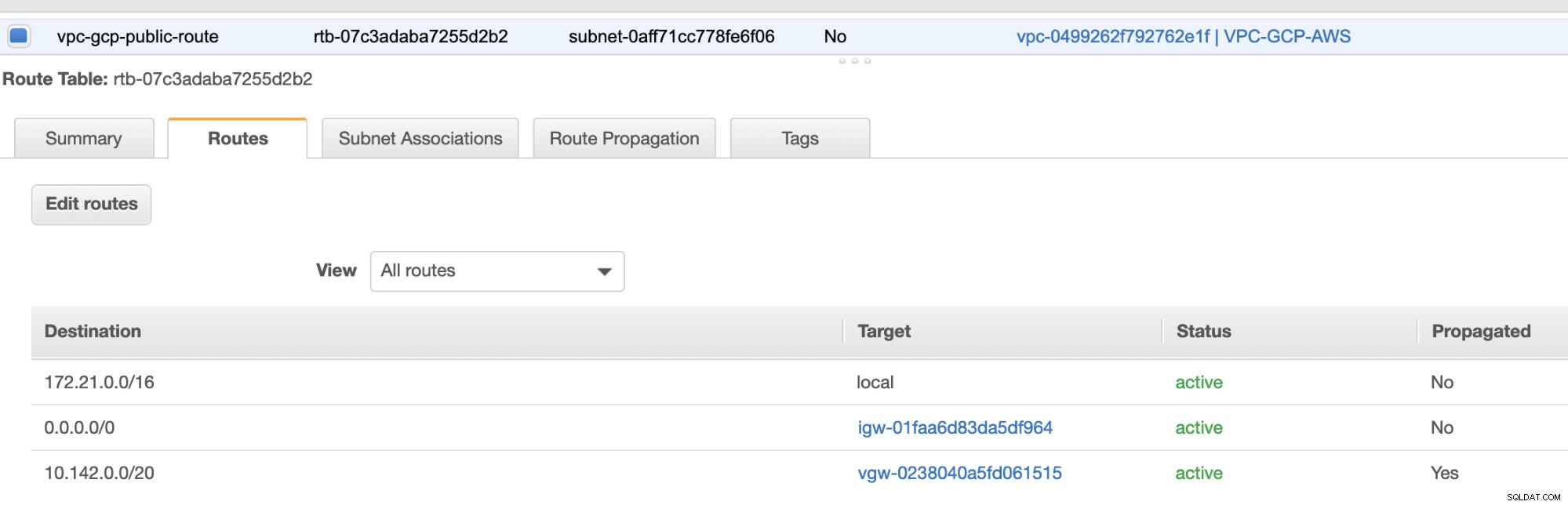
Както забелязахте, igw-01faa6d83da5df964 е интернет шлюзът, който създадохме и се използва от обществения маршрут. Докато частната таблица с маршрути има дестинация и цел, зададени на nat-07eb7a54e90dab61f и двете имат Дестинация задайте на 0.0.0.0/0, тъй като ще позволява от различни IPv4 връзки. Също така не забравяйте да зададете Разпространение на маршрут правилно за виртуалния шлюз, както се вижда на екранната снимка, която има цел vgw-0238040a5fd061515 . Просто щракнете върху Разпространение на маршрута и го задайте на Да, точно както на екранната снимка по-долу:
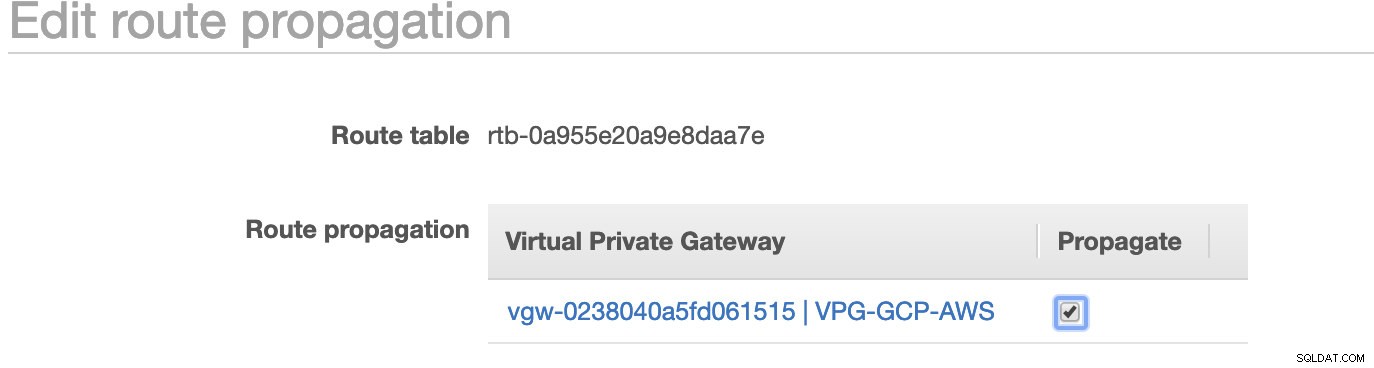
Това е много важно, за да може връзката от външните GCP връзки да се насочва към таблиците с маршрути в AWS и да не е необходима допълнителна ръчна работа. В противен случай вашият GCP не може да установи връзка с AWS.
Сега, когато нашата VPN е готова, ще продължим да настройваме частните си възли, включително хоста на бастиона.
Настройване на възлите на Compute Engine
Настройката на възлите Compute Engine/EC2 ще бъде бърза и лесна, тъй като имаме всички настройки на място. Няма да навлизам в тези подробности, но разгледайте екранните снимки по-долу, тъй като обясняват настройката.
AWS EC2 възли :

GCP изчислителни възли :
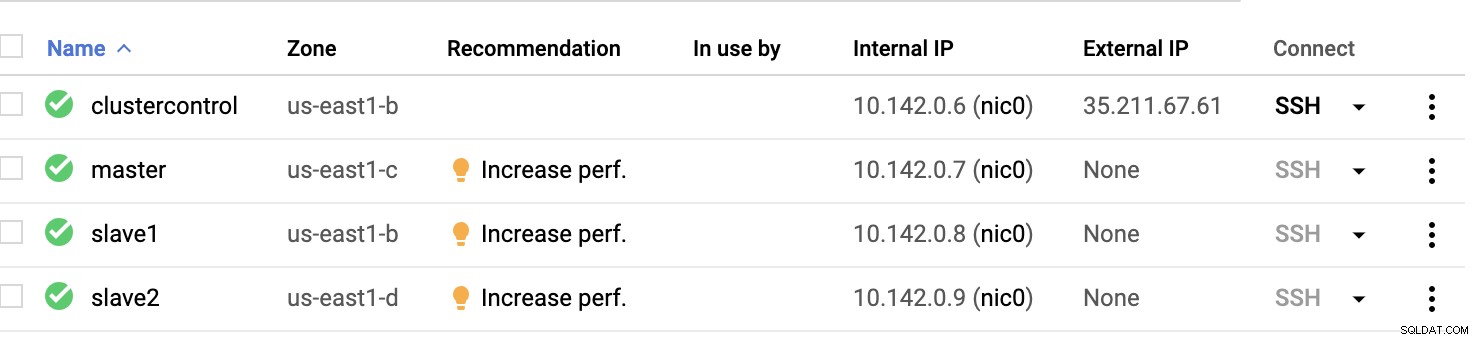
По принцип на тази настройка. Хост clustercontrol ще бъде bastion или jump host и за който ще бъде инсталиран ClusterControl. Очевидно всички възли тук не са достъпни в интернет. Не им е назначен външен IPv4 и възлите комуникират чрез много защитен канал, използвайки VPN.
И накрая, всички тези възли от AWS до GCP са настроени с един единен потребител на системата с sudo достъп, който е необходим в следващия раздел. Вижте как ClusterControl може да улесни живота ви, когато сте в мултиоблак и много региони.
ClusterControl на помощ!!!
Работата с множество възли и на различни публични облачни платформи, както и в различен „регион“ може да бъде „наистина болезнена и обезсърчаваща“ задача. Как го наблюдавате ефективно? ClusterControl действа не само като вашия швейцарски нож, но и като вашия виртуален DBA. Сега нека видим как ClusterControl може да улесни живота ви.
Създаване на клъстер с множество репликации с помощта на ClusterControl
Сега нека се опитаме да създадем MariaDB главен-подчинен клъстер за репликация, следвайки топологията „Множество репликации“.
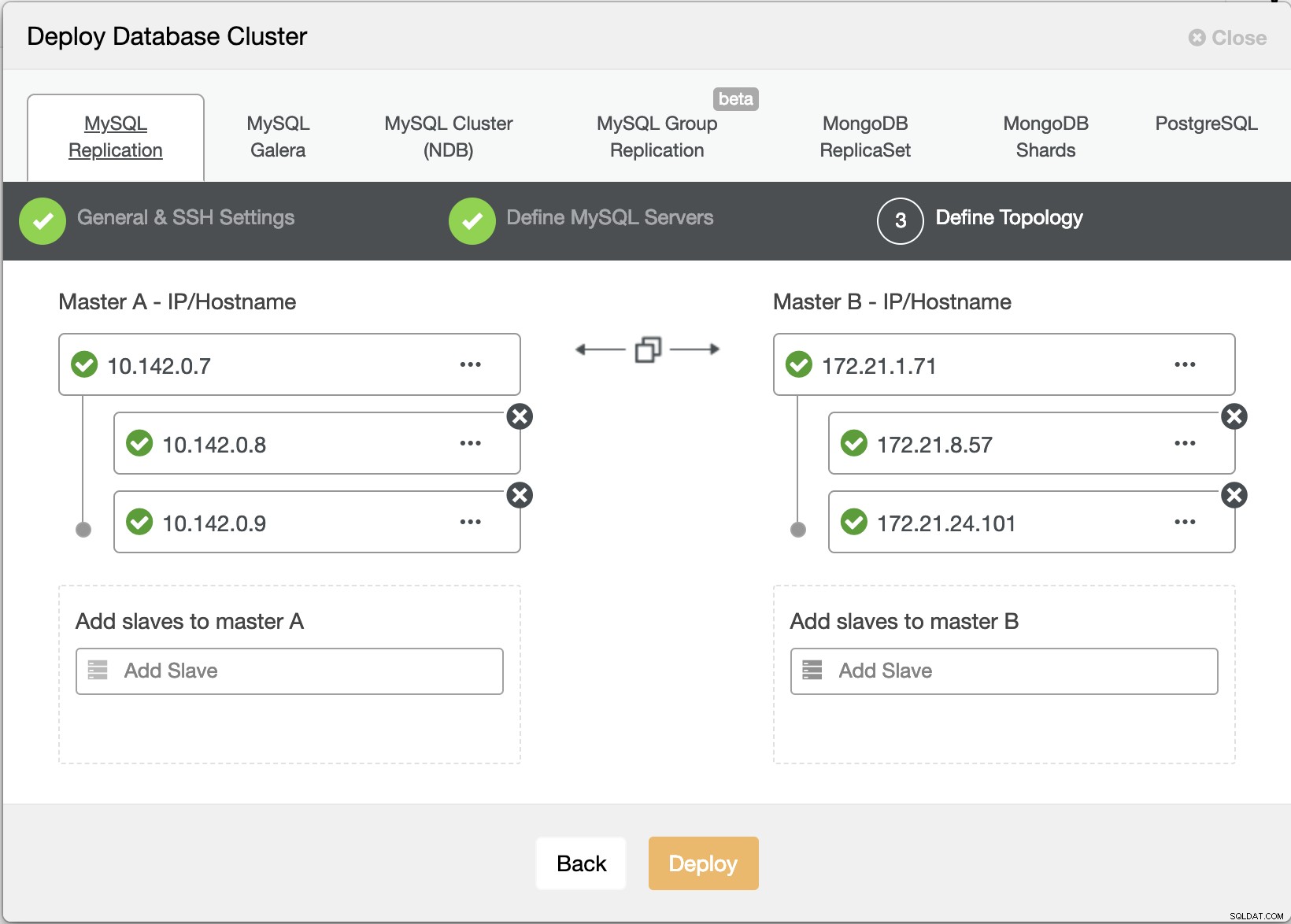 Съветник за внедряване на ClusterControl
Съветник за внедряване на ClusterControl Натиснете Разгръщане бутонът ще инсталира пакети и съответно ще настрои възлите. Следователно, логичен поглед върху това как би изглеждала топологията:
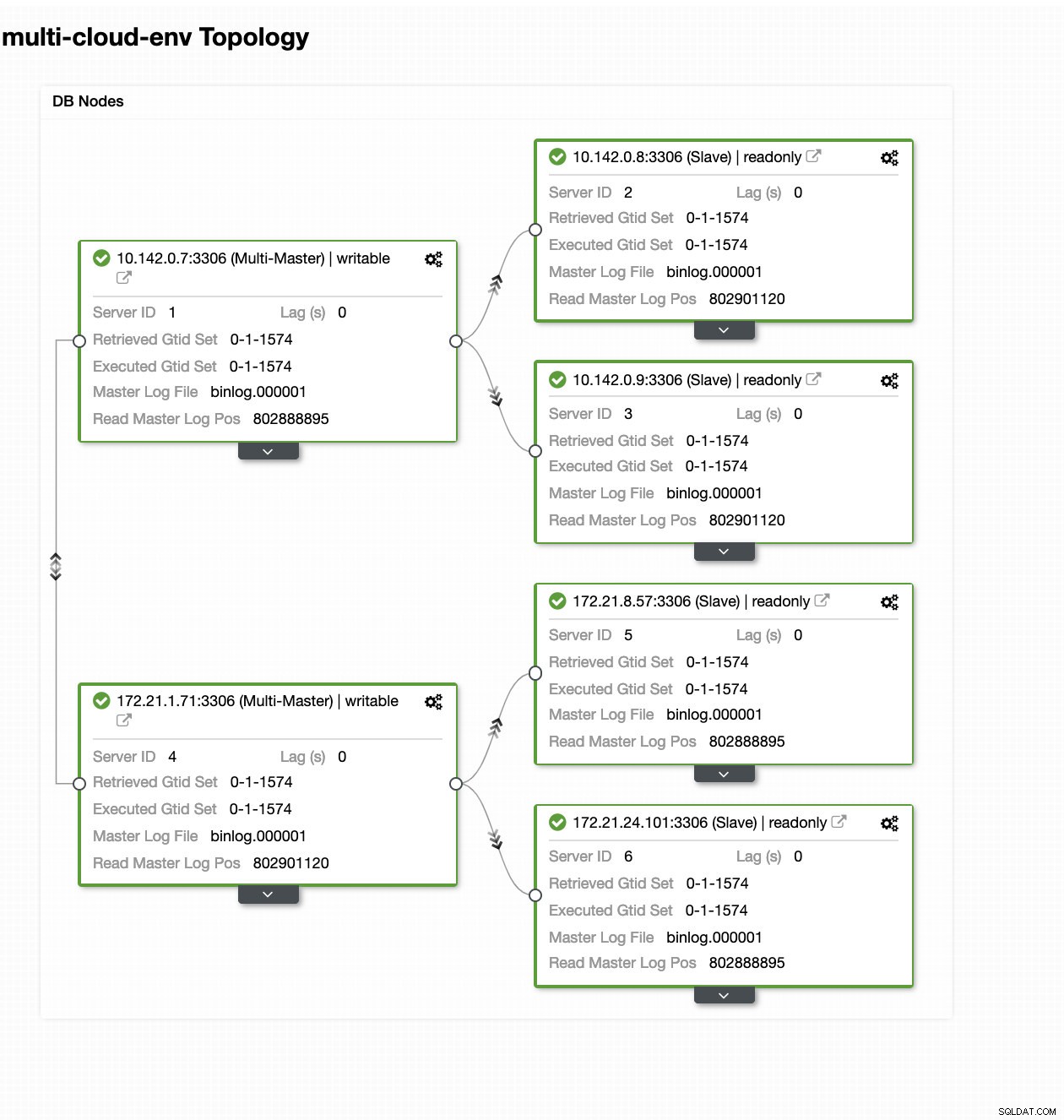 ClusterControl – изглед на топология
ClusterControl – изглед на топология IP адресите на обхвата на възлите 172.21.0.0/16 се репликират от своя главен сървър, работещ на GCP.
Сега, какво ще кажете да се опитаме да заредим някои записи на главния? Всички проблеми със свързаността или латентността могат да генерират забавяне на подчинените, ще можете да забележите това с ClusterControl. Вижте екранната снимка по-долу:
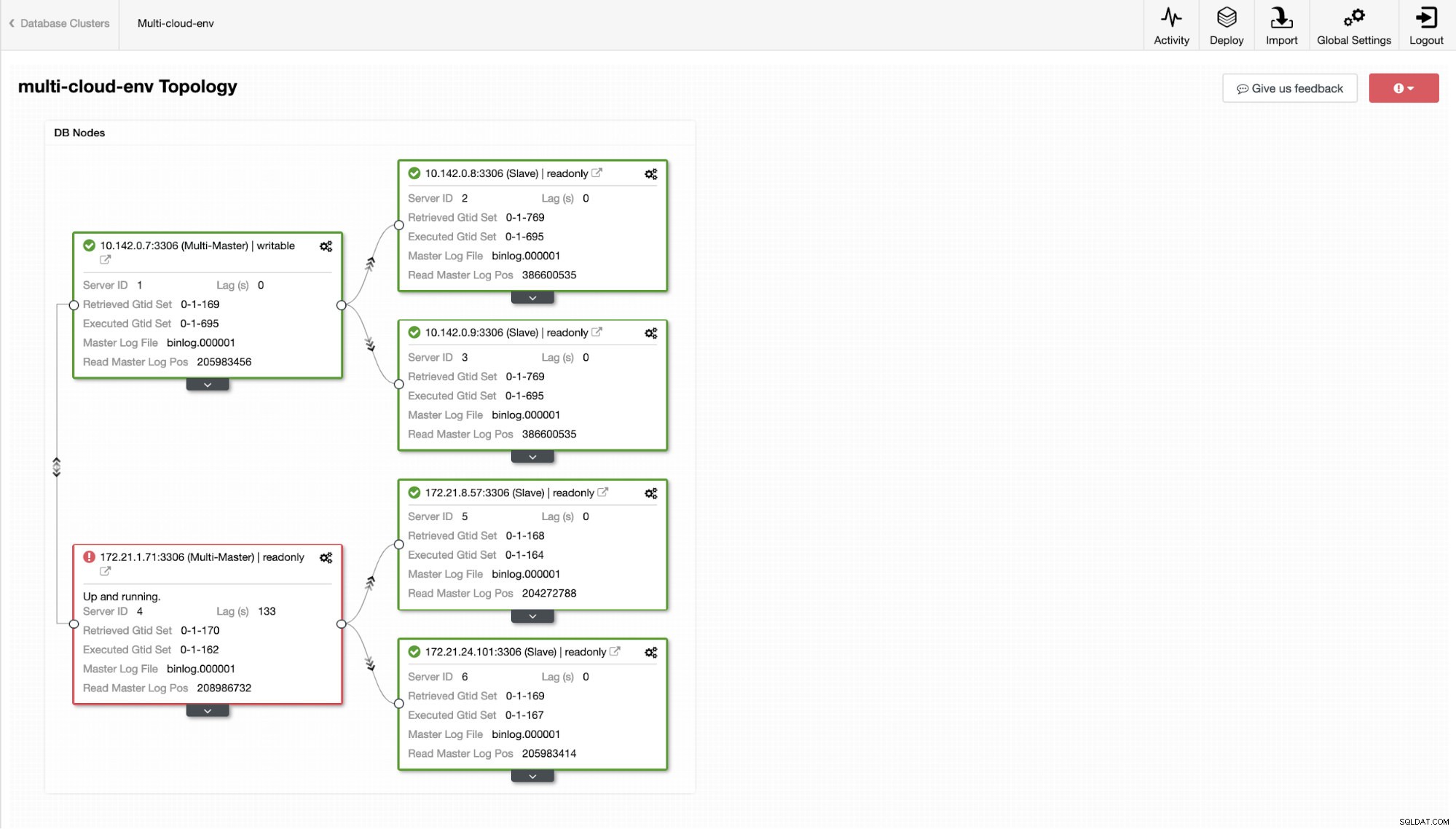
и както виждате в горния десен ъгъл на екранната снимка, той става червен, тъй като показва, че са открити проблеми. Следователно се изпраща аларма, докато този проблем е открит. Вижте по-долу:
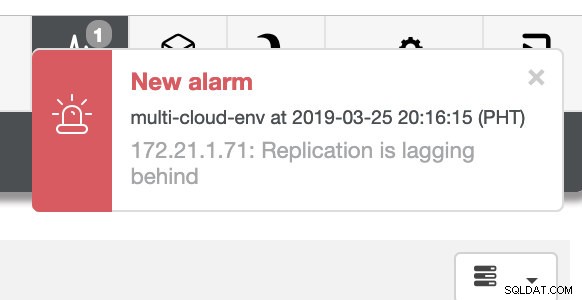
Трябва да се задълбочим в това. За фино наблюдение сме активирали агенти в екземплярите на базата данни. Нека да разгледаме таблото за управление.
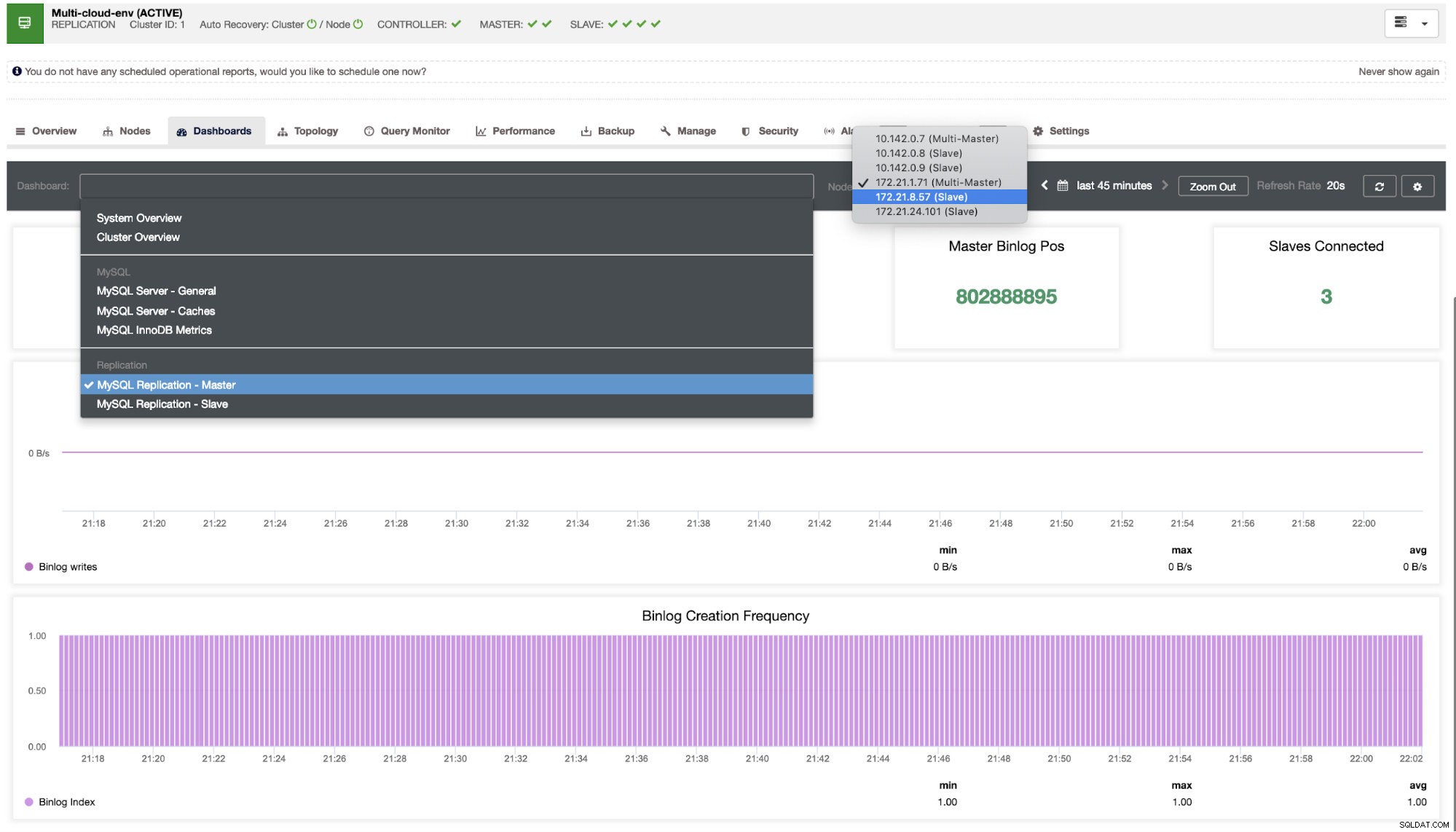
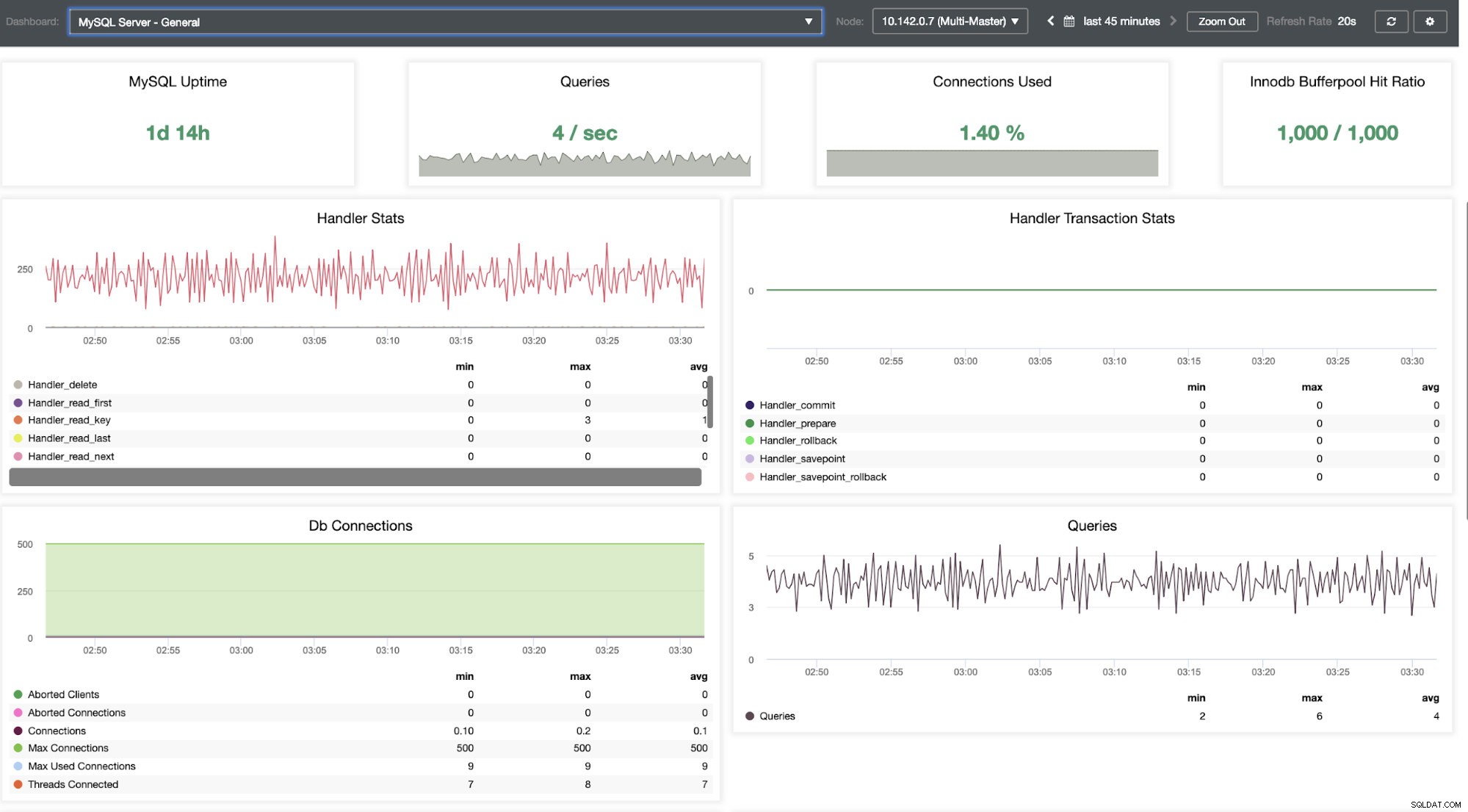
Той предлага супер гладко изживяване по отношение на наблюдението на вашите възли.
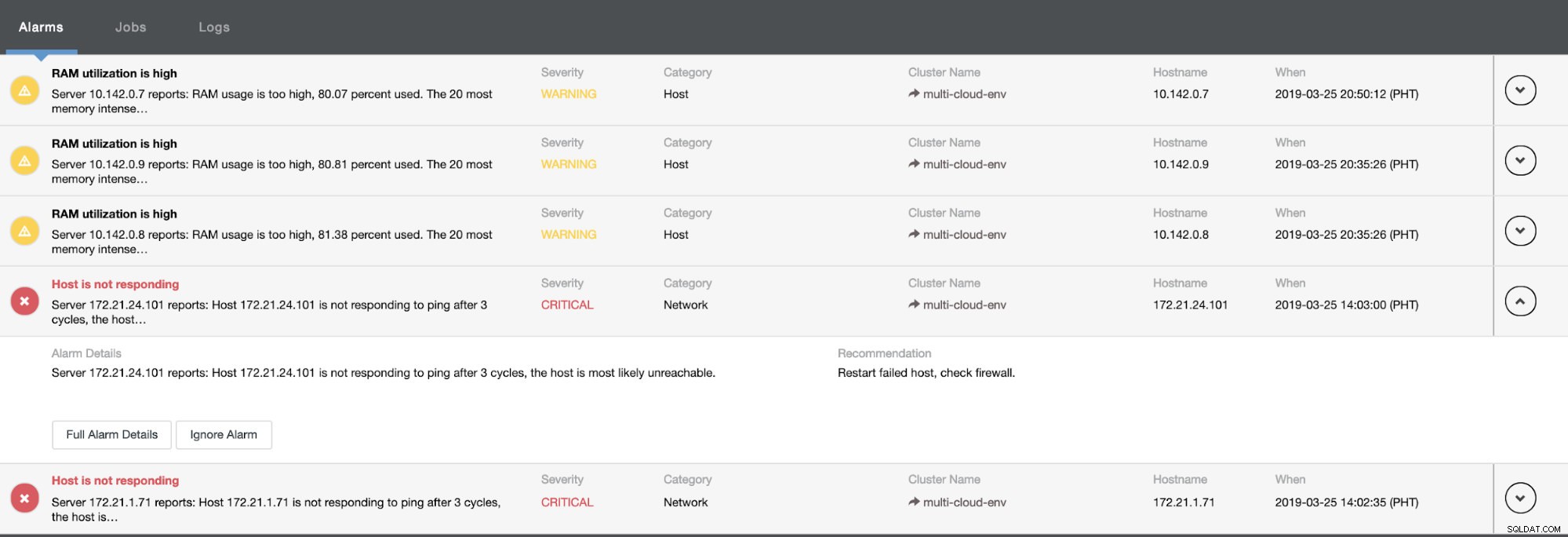
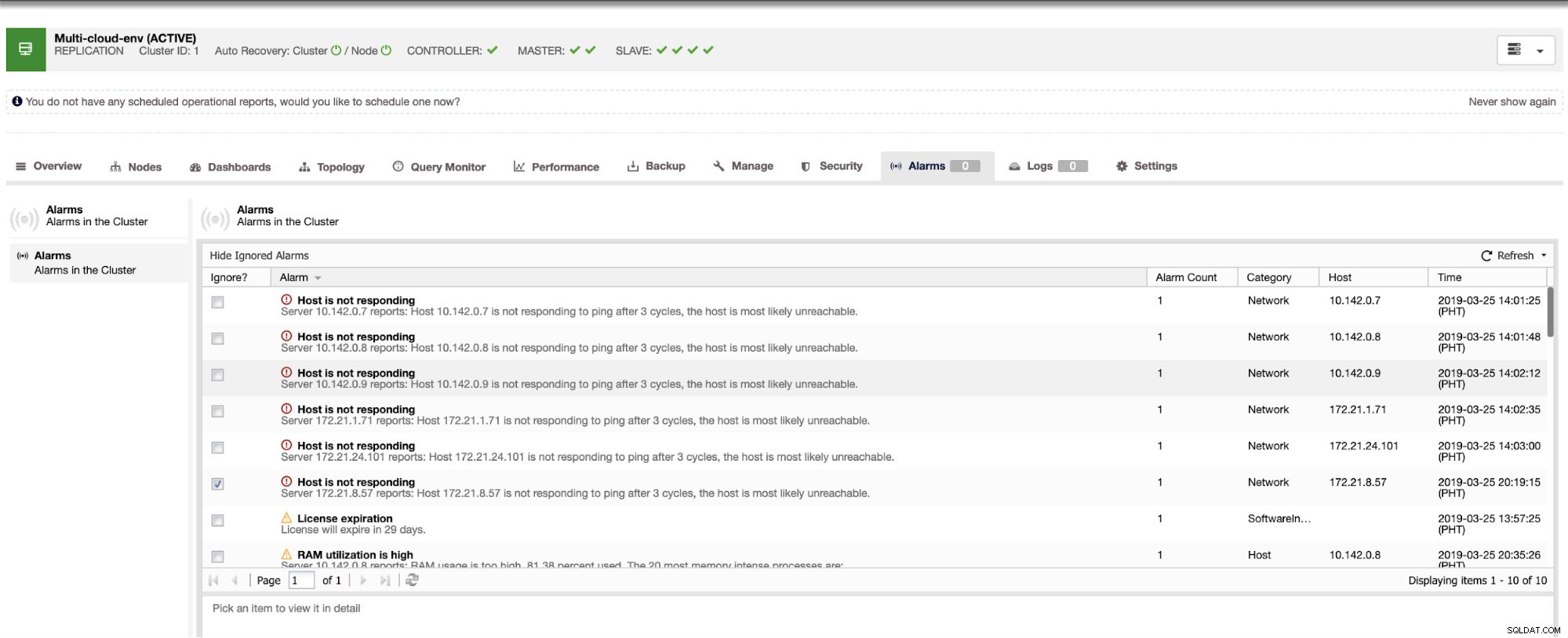
Това ни казва, че използването е високо или хостът не отговаря. Въпреки че това беше само пинг неуспешен отговор, можете да игнорирате предупреждението, за да ви попречи да го бомбардирате. Следователно, можете да го „пренебрегнете“, ако е необходимо, като отидете на Cluster -> Alarms в ClusterControl. Вижте по-долу:
Управление на неуспехи и извършване на отказ
Да кажем, че главният възел us-east1 се е провалил или изисква основен ремонт поради надстройка на системата или хардуера. Да кажем, че това е топологията в момента (вижте изображението по-долу):
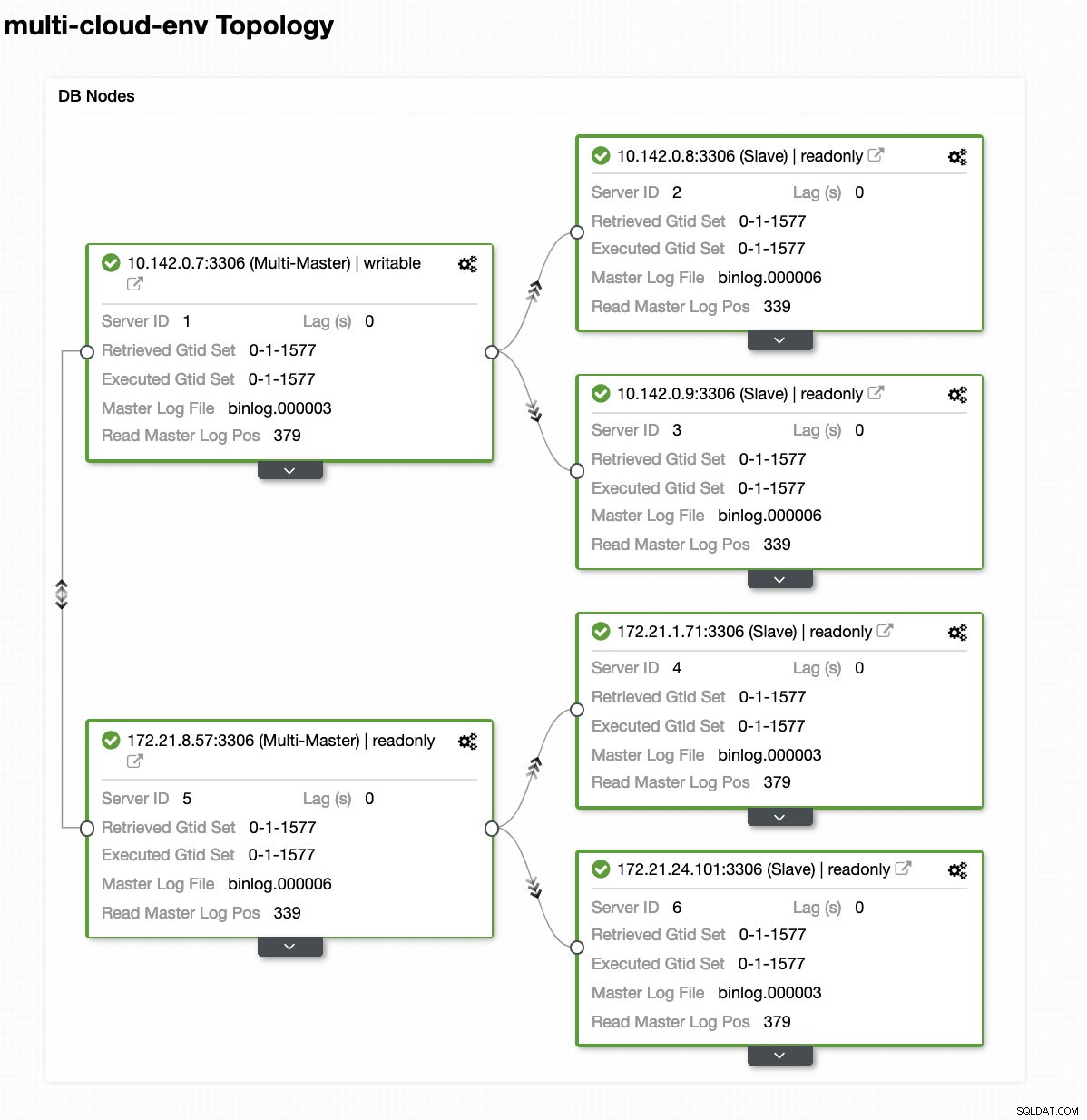
Нека се опитаме да изключим хост 10.142.0.7, който е главният под региона us-east1. Вижте екранните снимки по-долу как ClusterControl реагира на това:
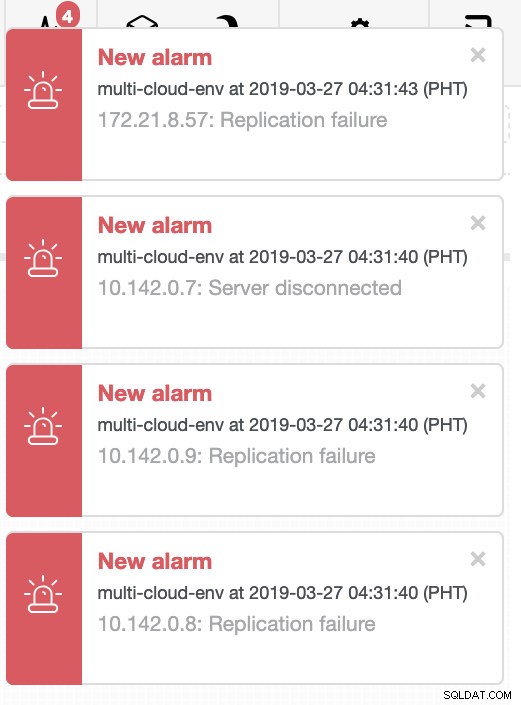
ClusterControl изпраща аларми, след като открие аномалии в клъстера. След това се опитва да извърши отказ на нов главен елемент, като избере правилния кандидат (вижте изображението по-долу):

След това оставя настрана неуспешния главен код, който вече е изваден от клъстера (вижте изображението по-долу):
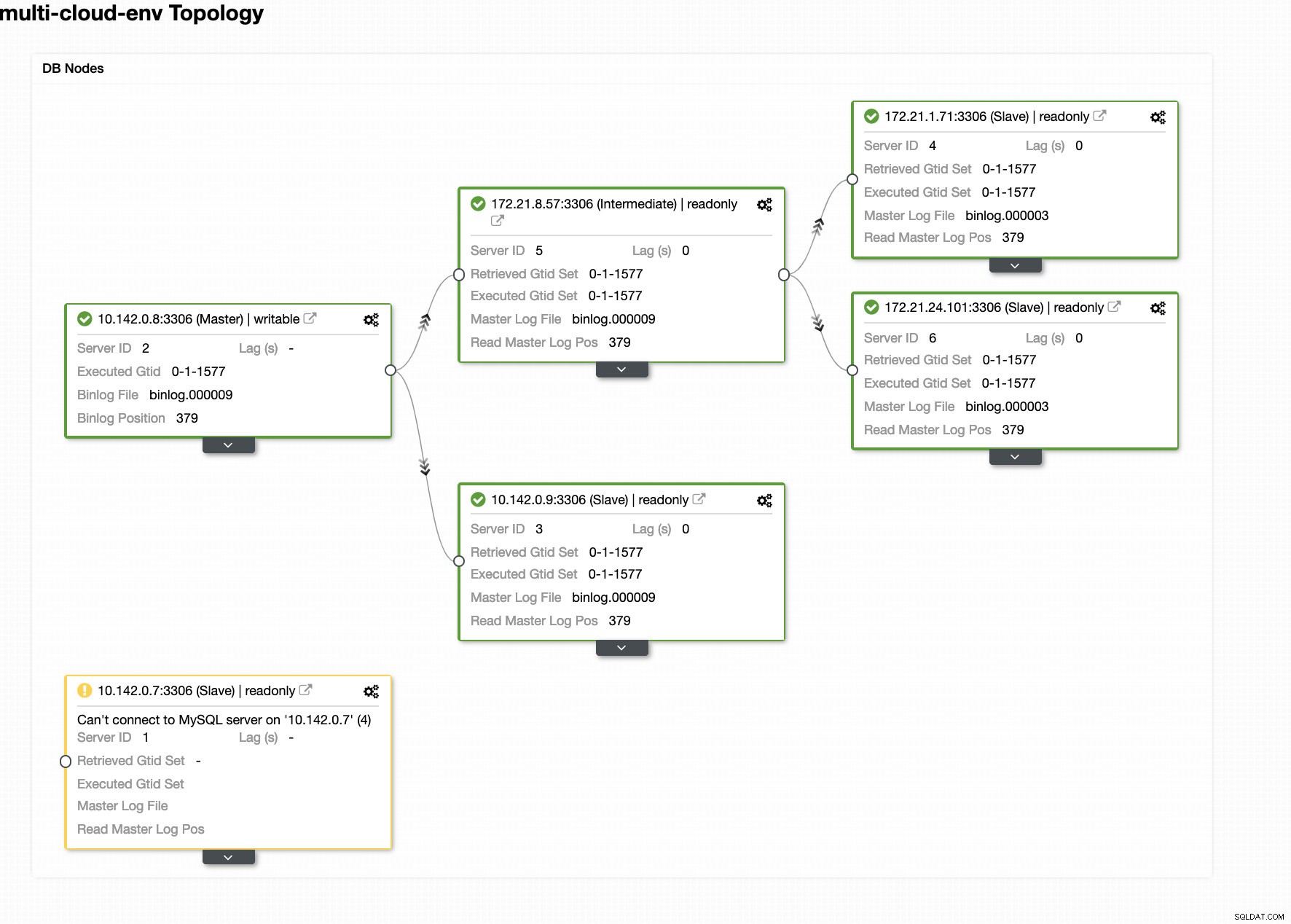
Това е само един поглед върху това, което ClusterControl може да направи, има и други страхотни функции като архивиране, наблюдение на заявки, внедряване/управление на балансьори на натоварване и много други!
Заключение
Управлението на вашата настройка на MySQL репликация в мултиоблак може да бъде трудно. Трябва да се полагат много грижи, за да се осигури нашата настройка, така че се надяваме, че този блог дава идея как да дефинирате подмрежи и да защитите възлите на базата данни. След сигурността има редица неща за управление и тук ClusterControl може да бъде много полезен.
Опитайте го сега и ни уведомете как върви. Можете да се свържете с нас тук по всяко време.



