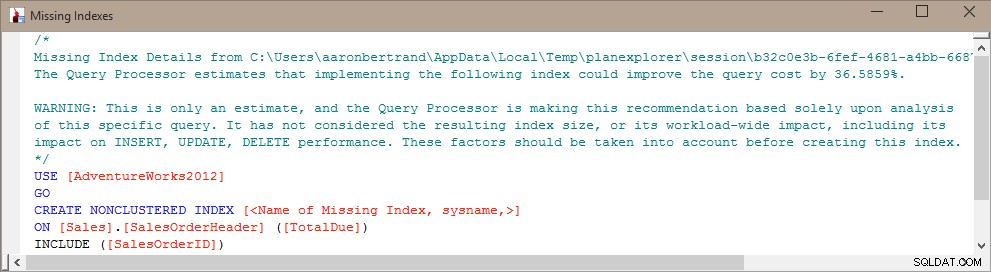
Кевин Клайн (@kekline) и аз наскоро проведохме уебинар за настройка на заявки (всъщност един от поредица) и едно от нещата, които се появиха, е тенденцията на хората да създават всеки липсващ индекс, който SQL Server им казва, че ще бъде добро нещо™ . Те могат да научат за тези липсващи индекси от Database Engine Tuning Advisor (DTA), липсващите индекси DMV или план за изпълнение, показан в Management Studio или Plan Explorer (всички от които просто предават информация от точно едно и също място):
Проблемът с простото създаване на този индекс на сляпо е, че SQL Server е решил, че е полезен за конкретна заявка (или шепа заявки), но напълно и едностранно игнорира останалата част от работното натоварване. Както всички знаем, индексите не са „безплатни“ – вие плащате за индекси както в необработено съхранение, така и за поддръжка, необходима за DML операции. Няма смисъл при натоварено с писане работно натоварване да добавите индекс, който помага да се направи една заявка малко по-ефективна, особено ако тази заявка не се изпълнява често. В тези случаи може да е много важно да разберете цялостното си работно натоварване и да постигнете добър баланс между това да направите заявките си ефективни и да не плащате твърде много за това по отношение на поддръжката на индекса.
Така че една идея, която имах, беше да „смеся“ информация от липсващите индексни DMV, статистиката за използване на индекса DMV и информацията за плановете за заявки, за да определя какъв тип баланс съществува в момента и как добавянето на индекса може да се справи като цяло.
Липсващи индекси
Първо, можем да разгледаме липсващите индекси, които SQL Server предлага в момента:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Това показва таблицата(ите) и колоната(ите), които биха били полезни в даден индекс, колко компилации/търсени/сканирания биха били използвани и кога се е случило последното подобно събитие за всеки потенциален индекс. Можете също да включите колони като s.avg_total_user_cost и s.avg_user_impact ако искате да използвате тези цифри за приоритизиране.
Планирайте операции
След това нека да разгледаме операциите, използвани във всички планове, които сме кеширали спрямо обектите, идентифицирани от нашите липсващи индекси.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Приятел от dba.SE, Микаел Ериксон, предложи следните две заявки, които в по-голяма система ще се представят много по-добре от XML/UNION заявката, която събрах по-горе, така че можете първо да експериментирате с тях. Неговият финален коментар беше, че той „не е изненадващо разбрал, че по-малко XML е добро нещо за производителност. :)“ Наистина.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Сега в #planops таблица имате куп стойности за plan_handle за да можете да отидете и да проучите всеки един от индивидуалните планове в игра срещу обектите, които са идентифицирани като липсващи някакъв полезен индекс. В момента няма да го използваме за това, но можете лесно да направите кръстосана препратка към това с:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Сега можете да щракнете върху всеки от изходните планове, за да видите какво правят в момента срещу вашите обекти. Имайте предвид, че някои от плановете ще се повтарят, тъй като планът може да има множество оператори, които препращат към различни индекси в една и съща таблица.
Статистика за използване на индекс
След това, нека да разгледаме статистиката за използване на индекса, за да можем да видим колко действителна активност се изпълнява в момента срещу нашите таблици кандидати (и по-специално актуализации).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Не се притеснявайте, ако много малко или никакви планове в кеша показват актуализации за конкретен индекс, въпреки че статистическите данни за използването на индекса показват, че тези индекси са актуализирани. Това просто означава, че плановете за актуализация в момента не са в кеша, което може да е по различни причини – например може да е много тежко четене и те са остарели, или всички те са единични- използвайте и optimize for ad hoc workloads е активирана.
Обединяване на всичко
Следната заявка ще ви покаже, за всеки предложен липсващ индекс, броя на четенията, които индексът може да е помогнал, броя на записванията и четенията, които в момента са били уловени спрямо съществуващите индекси, съотношението между тях, броя на плановете, свързани с този обект и общият брой използване се брои за тези планове:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Ако вашето съотношение на запис:четене към тези индекси вече е> 1 (или> 10!), мисля, че това дава причина за пауза, преди сляпо да създаде индекс, който може само да увеличи това съотношение. Броят на potential_read_ops показано обаче може да компенсира това, когато числото стане по-голямо. Ако potential_read_ops числото е много малко, вероятно искате да игнорирате препоръката изцяло, преди дори да си направите труда да проучите другите показатели – така че можете да добавите WHERE клауза за филтриране на някои от тези препоръки.
Няколко бележки:
- Това са операции четене и запис, а не индивидуално измерени четения и записвания на 8K страници.
- Съотношението и сравненията са до голяма степен образователни; много добре може да се окаже, че 10 000 000 операции на запис да повлияят на един ред, докато 10 операции за четене биха могли да имат значително по-голямо въздействие. Това е само груба насока и предполага, че операциите за четене и запис са претеглени приблизително еднакво.
- Можете също да използвате леки вариации на някои от тези заявки, за да разберете – извън липсващите индекси, които SQL Server препоръчва – колко от текущите ви индекси са разточителни. Има много идеи за това онлайн, включително тази публикация от Пол Рандал (@PaulRandal).
Надявам се, че това дава някои идеи за придобиване на повече представа за поведението на вашата система, преди да решите да добавите индекс, който някой инструмент ви каза да създадете. Бих могъл да създам това като една масивна заявка, но мисля, че отделните части ще ви дадат някои заешки дупки, които да проучите, ако желаете.
Други бележки
Може също да искате да разширите това, за да обхванете текущите показатели за размер, ширината на таблицата и броя на текущите редове (както и всякакви прогнози за бъдещ растеж); това може да ви даде добра представа колко място ще заеме един нов индекс, което може да бъде проблем в зависимост от вашата среда. Може да разгледам това в бъдеща публикация.
Разбира се, трябва да имате предвид, че тези показатели са полезни само дотолкова, доколкото времето на работа диктува. DMV се изчистват след рестартиране (а понякога и в други, по-малко разрушителни сценарии), така че ако смятате, че тази информация ще бъде полезна за по-дълъг период от време, правенето на периодични моментни снимки може да е нещо, което искате да обмислите.