Премахването и предотвратяването на фрагментация на индекси отдавна са част от нормалните операции по поддръжка на база данни, не само в SQL Server, но и в много платформи. Фрагментацията на индекса влияе върху производителността по много причини и повечето хора говорят за ефектите от произволни малки блокове I/O, които могат да се случат физически на дисково базирано хранилище, като нещо, което трябва да се избягва. Общата загриженост относно фрагментацията на индекса е, че тя влияе върху производителността на сканирането чрез ограничаване на размера на входно-изходните операции за четене напред. Въз основа на това ограничено разбиране на проблемите, които фрагментацията на индекса причинява, някои хора са започнали да разпространяват идеята, че фрагментацията на индекса няма значение с устройствата за съхранение на твърдо състояние (SSD) и че можете просто да игнорирате фрагментацията на индекса в бъдеще.
Това обаче не е така поради редица причини. Тази статия ще обясни и демонстрира една от тези причини:фрагментацията на индекса може да повлияе неблагоприятно на избора на план за изпълнение за заявки. Това се случва, защото фрагментирането на индекс обикновено води до индекс, който има повече страници (тези допълнителни страници идват от разделяне на страници операции, както е описано в тази публикация на този сайт), и така използването на този индекс се счита за по-висока цена от оптимизатора на заявки на SQL Server.
Нека разгледаме пример.
Първото нещо, което трябва да направим, е да изградим подходяща тестова база данни и набор от данни, които да използваме за изследване как фрагментацията на индекса може да повлияе на избора на план за заявка в SQL Server. Следният скрипт ще създаде база данни с две таблици с идентични данни, едната силно фрагментирана и една минимално фрагментирана.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO След като възстановим индекса, можем да разгледаме нивата на фрагментация със следната заявка:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Резултати:

Тук можем да видим, че нашата GuidHighFragmentation таблицата е 99% фрагментирана и използва 31% повече пространство на страницата от GuidLowFragmentation таблица в базата данни, въпреки че имат същите 7 000 000 реда данни. Ако изпълним основна заявка за агрегиране спрямо всяка от таблиците и сравним плановете за изпълнение на инсталация по подразбиране (с опции за конфигурация и стойности по подразбиране) на SQL Server с помощта на SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


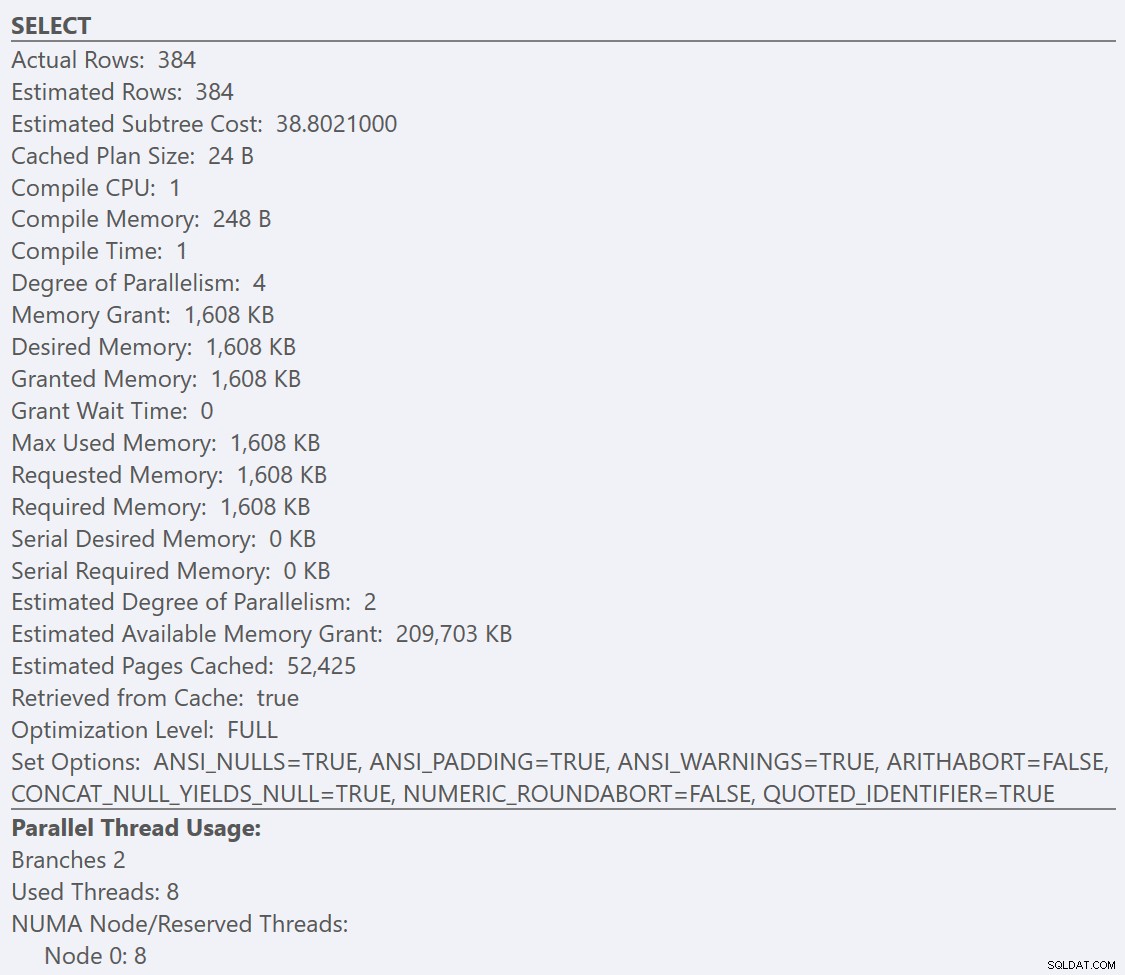

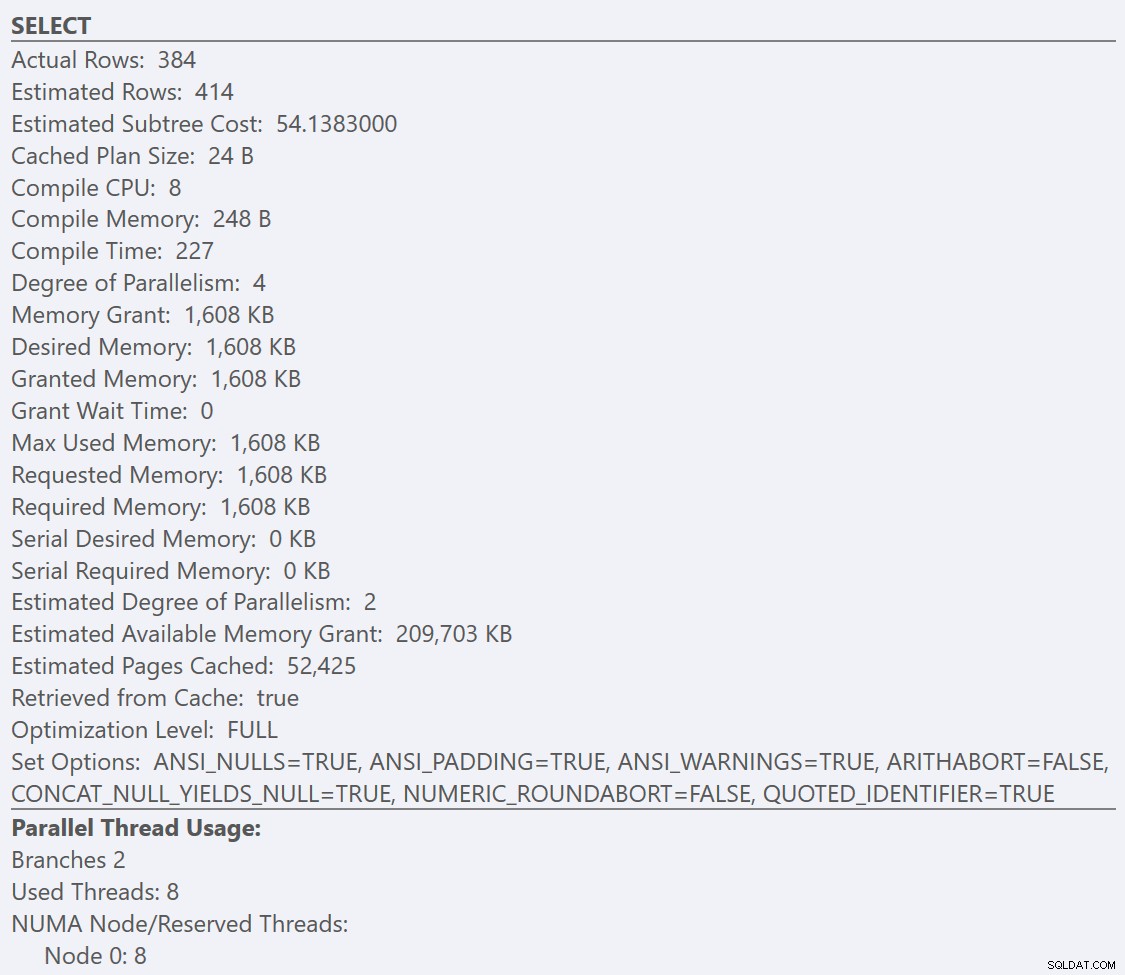
Ако погледнем подсказките от SELECT оператор за всеки план, планът за GuidLowFragmentation таблицата има цена на заявка от 38,80 (третият ред надолу от горната част на подсказката) срещу цена на заявка от 54,14 за плана за плана GuidHighFragmentation.
При конфигурация по подразбиране за SQL Server и двете от тези заявки в крайна сметка генерират план за паралелно изпълнение, тъй като приблизителната цена на заявката е по-висока от стойността на опцията по подразбиране „праг на разходите за паралелизъм“ на sp_configure от 5. Това е така, защото оптимизаторът на заявки първо произвежда сериен план (който може да бъде изпълнен само от една нишка), когато компилирате плана за заявка. Ако прогнозната цена на този сериен план надвишава конфигурираната стойност на „прага на разходите за паралелизъм“, вместо това се генерира и кешира паралелен план.
Но какво ще стане, ако опцията sp_configure „праг на разходите за паралелизъм“ не е зададена по подразбиране от 5 и е по-висока? Най-добрата практика (и правилна) е да увеличите тази опция от ниската стойност по подразбиране от 5 до някъде от 25 до 50 (или дори много по-висока), за да предотвратите малките заявки от допълнителни разходи за паралелно преминаване.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
След като следвате указанията за най-добри практики и увеличите „прага на разходите за паралелизъм“ до 50, повторното изпълнение на заявките води до същия план за изпълнение за GuidHighFragmentation таблица, но GuidLowFragmentation серийната цена на заявката, 44,68, сега е под стойността на „прага на разходите за паралелизъм“ (не забравяйте, че нейната прогнозна паралелна цена беше 38,80), така че получаваме план за серийно изпълнение:
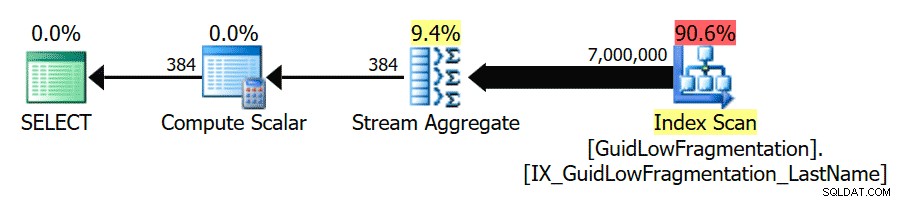
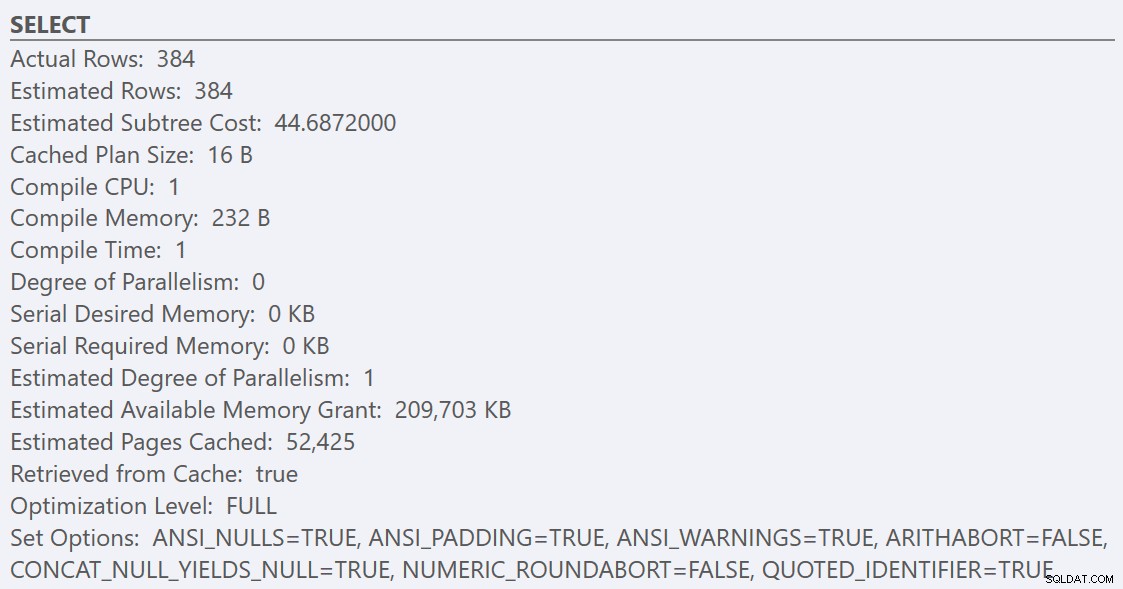
Допълнителното пространство на страницата в GuidHighFragmentation клъстерираният индекс поддържа цената над настройката на най-добрата практика за „праг на разходите за паралелизъм“ и води до паралелен план.
Сега си представете, че това е система, при която сте следвали насоките за най-добри практики и първоначално сте конфигурирали „праг на разходите за паралелизъм“ на стойност 50. След това по-късно сте следвали погрешния съвет просто да игнорирате напълно фрагментацията на индекса.
Вместо това да е основна заявка, тя е по-сложна, но ако също се изпълнява много често във вашата система и в резултат на фрагментацията на индекса, броят на страниците прехвърля разходите към паралелен план, той ще използва повече процесор и в резултат на това повлияе на цялостната производителност на работното натоварване.
Какво правиш? Увеличавате ли „прага на разходите за паралелизъм“, така че заявката да поддържа сериен план за изпълнение? Намеквате ли заявката с OPTION(MAXDOP 1) и просто я принуждавате към сериен план за изпълнение?
Имайте предвид, че фрагментацията на индекса вероятно не засяга само една таблица във вашата база данни, сега, когато я игнорирате изцяло; вероятно е много клъстерирани и неклъстерирани индекси да са фрагментирани и да имат по-висок от необходимия брой страници, така че разходите за много I/O операции се увеличават в резултат на широко разпространеното фрагментиране на индекса, което води до потенциално много неефективни заявки планове.
Резюме
Не можете просто да игнорирате фрагментацията на индекса изцяло, както някои може да искат да вярвате. Наред с други недостатъци от това, натрупаните разходи за изпълнение на заявка ще ви настигнат с промени в плана на заявките, тъй като оптимизаторът на заявки е базиран на разходите оптимизатор и затова правилно смята тези фрагментирани индекси за по-скъпи за използване.
Заявките и сценариите тук очевидно са измислени, но сме виждали промени в плана за изпълнение, причинени от фрагментация в реалния живот на клиентски системи.
Трябва да се уверите, че се справяте с фрагментирането на индекси за онези индекси, където фрагментацията причинява проблеми с производителността на работното натоварване, независимо какъв хардуер използвате.