Типът и броят на заключванията, придобити и освободени по време на изпълнение на заявката, могат да имат изненадващ ефект върху производителността (когато се използва ниво на изолация на заключване, като четене по подразбиране, заето), дори когато не се случва чакане или блокиране. В плановете за изпълнение няма информация, която да посочва обема на заключващата активност по време на изпълнение, което прави по-трудно да се забележи, когато прекомерното заключване причинява проблем с производителността.
За да изследвам някои по-малко известни поведения на заключване в SQL Server, ще използвам повторно заявките и примерните данни от последната ми публикация за изчисляване на медианите. В тази публикация споменах, че OFFSET групираното средно решение се нуждаеше от изричен PAGLOCK намек за заключване, за да избегнете лоша загуба от вложения курсор решение, така че нека започнем, като разгледаме подробно причините за това.
Групирано медианно решение OFFSET
Групираният среден тест използва повторно извадките от по-ранната статия на Арън Бертран. Скриптът по-долу пресъздава тази настройка от милиони редове, състояща се от десет хиляди записа за всеки от стоте въображаеми продавачи:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
SQL Server 2012 (и по-нови) OFFSET Решението, създадено от Peter Larsson, е както следва (без никакви заключващи намеци):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Важните части от плана след изпълнение са показани по-долу:

С всички необходими данни в паметта, тази заявка се изпълнява за 580 ms средно на моя лаптоп (работещ SQL Server 2014 Service Pack 1). Производителността на тази заявка може да бъде подобрена до 320 ms просто като добавите намек за заключване на детайлност на страницата към таблицата Продажби в подзаявката за прилагане:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Планът за изпълнение е непроменен (е, освен текста на заключващия намек в showplan XML, разбира се):
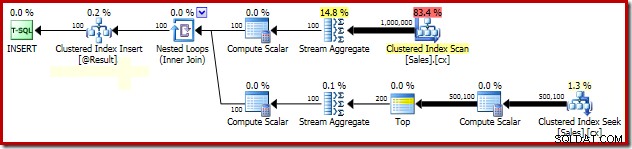
Групиран среден заключващ анализ
Обяснението за драматичното подобрение в производителността, дължащо се на PAGLOCK намекът е доста прост, поне първоначално.
Ако ръчно наблюдаваме дейността по заключване, докато тази заявка се изпълнява, виждаме, че без намек за детайлност на заключване на страницата, SQL Server придобива и освобождава над половин милион заключвания на ниво ред докато търси клъстерирания индекс. Няма блокиране за вина; простото придобиване и освобождаване на толкова много ключалки добавя значителни режийни разходи към изпълнението на тази заявка. Заявката за заключване на ниво страница намалява значително активността по заключване, което води до много подобрена производителност.
Проблемът с производителността на заключването на този конкретен план е ограничен до търсенето на клъстериран индекс в плана по-горе. Пълното сканиране на клъстерирания индекс (използван за изчисляване на броя на наличните редове за всеки продавач) използва автоматично заключване на ниво страница. Това е интересен момент. Подробното поведение на заключване на двигателя на SQL Server не е документирано в Books Online до голяма степен, но различни членове на екипа на SQL Server са направили няколко общи забележки през годините, включително факта, че неограничените сканирания обикновено започват от заснемане на страница заключвания, докато по-малките операции обикновено започват със заключване на редове.
Оптимизаторът на заявки прави известна информация на разположение на механизма за съхранение, включително оценки на мощността, вътрешни съвети за ниво на изолация и детайлност на заключване, които вътрешни оптимизации могат да бъдат безопасно приложени и т.н. Отново тези подробности не са документирани в Books Online. В крайна сметка механизмът за съхранение използва разнообразна информация, за да реши кои заключвания са необходими по време на изпълнение и при каква степен на детайлност трябва да бъдат взети.
Като странична бележка и като си припомним, че говорим за заявка, изпълняваща се при ниво на изолация на транзакцията по подразбиране за заключване на четене, имайте предвид, че заключванията на редове, взети без намек за детайлност, няма да ескалират до заключване на таблица в този случай. Това е така, защото нормалното поведение при четене е да се освободи предишното заключване непосредствено преди придобиването на следващото заключване, което означава, че във всеки конкретен момент ще бъде задържано само едно споделено заключване на ред (със свързаните с него по-високо ниво на споделено намерение). Тъй като броят на едновременно държаните заключвания на ред никога не достига прага, не се прави опит за ескалация на заключване.
Отместване на единична медиана решение
Тестът за ефективност за едно изчисление на медиана използва различен набор от примерни данни, отново възпроизведени от по-ранната статия на Аарон. Скриптът по-долу създава таблица с десет милиона реда псевдослучайни данни:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
OFFSET решението е:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Планът след изпълнение е:

Тази заявка се изпълнява за 910 ms средно на моята тестова машина. Производителността остава непроменена, ако PAGLOCK е добавен намек, но причината за това не е това, което може би си мислите...
Анализ на заключване на единична медиана
Може да очаквате механизма за съхранение да избере споделени заключване на ниво страница, поради клъстерното сканиране на индекс, обяснявайки защо PAGLOCK намек няма ефект. Всъщност наблюдението на заключванията, взети по време на изпълнение на тази заявка, разкрива, че не се вземат никакви споделени заключвания (S), в каквато и да е степен на детайлност . Единствените взети заключвания са споделено намерение (IS) на ниво обект и страница.
Обяснението за това поведение се състои от две части. Първото нещо, което трябва да забележите, е, че Clustered Index Scan е под оператор Top в плана за изпълнение. Това има важен ефект върху оценките за мощността, както е показано в плана за предварително изпълнение (приблизителен):

OFFSET и FETCH клаузите в заявката се позовават на израз и променлива, така че оптимизаторът на заявки отгатва броя на редовете, които ще са необходими по време на изпълнение. Стандартното предположение за Top е сто реда. Това е ужасно предположение, разбира се, но е достатъчно, за да убеди механизма за съхранение да заключи на детайлност на ред, вместо на ниво страница.
Ако деактивираме ефекта „цел на ред“ на оператора Top, използвайки документиран флаг за проследяване 4138, прогнозният брой редове при сканирането се променя на десет милиона (което все още е погрешно, но в другата посока). Това е достатъчно, за да промените решението за детайлност на заключване на механизма за съхранение, така че да се вземат споделени заключвания на ниво страница (забележете, не споделени по намерение заключвания):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Прогнозният план за изпълнение, произведен под флаг за проследяване 4138, е:

Връщайки се към основния пример, оценката за сто реда, дължаща се на отгатната цел на ред, означава, че механизмът за съхранение избира да заключи на ниво ред. Ние обаче наблюдаваме само споделени намерения (IS) заключвания на ниво таблица и страница. Тези ключалки от по-високо ниво биха били съвсем нормални, ако видим споделени (S) ключалки на ниво ред, така че къде отидоха?
Отговорът е, че механизмът за съхранение съдържа друга оптимизация, която може да пропусне споделените заключвания на ниво ред при определени обстоятелства. Когато се приложи тази оптимизация, заключванията със споделено намерение от по-високо ниво все още се придобиват.
За да обобщим, за заявката с единична медиана:
- Използването на променлива и израз в
OFFSETклауза означава, че оптимизаторът предполага мощност. - Ниската оценка означава, че механизмът за съхранение взема решение за стратегия за заключване на ниво ред.
- Вътрешна оптимизация означава, че S заключванията на ниво ред се пропускат по време на изпълнение, оставяйки само заключванията на IS на ниво страница и обект.
Единичната средна заявка би имала същия проблем с производителността при заключване на редове като групираната медиана (поради неточната оценка на оптимизатора на заявки), но тя беше запазена от отделна оптимизация на механизма за съхранение, което доведе до вземане само на споделени намерения за заключване на страници и таблици по време на изпълнение.
Преглед на групирания среден тест
Може би се чудите защо търсенето на клъстериран индекс в групирания среден тест не се възползва от същата оптимизация на механизма за съхранение, за да пропусне споделените заключване на ниво ред. Защо бяха използвани толкова много споделени заключване на редове, правейки PAGLOCK необходим ли е намек?
Краткият отговор е, че тази оптимизация не е налична за INSERT...SELECT запитвания. Ако изпълним SELECT самостоятелно (т.е. без записване на резултатите в таблица) и без PAGLOCK намек, оптимизацията за пропускане на заключване на ред е приложено:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Използват се само заключвания със споделено намерение (IS) на ниво таблица и страница и производителността се увеличава до същото ниво, както когато използваме PAGLOCK намек. Разбира се, няма да намерите това поведение в документацията и може да се промени по всяко време. Все пак е добре да сте наясно.
Освен това, в случай, че се чудите, флагът за проследяване 4138 няма ефект върху избора на детайлност на заключване на механизма за съхранение в този случай, тъй като прогнозният брой редове при търсене е твърде нисък (на итерация на прилагане) дори при деактивирана цел на реда.
Преди да направите заключения относно ефективността на заявка, не забравяйте да проверите броя и вида на заключванията, които тя приема по време на изпълнение. Въпреки че SQL Server обикновено избира „правилната“ детайлност, има моменти, когато може да обърка нещата, понякога с драматични ефекти върху производителността.