Общата стратегия, която двигателят на базата данни на SQL Server използва, за да поддържа индексиран изглед, синхронизиран с неговите базови таблици – което описах по-подробно в последната си публикация – е да извършва постепенна поддръжка на изгледа, когато възникне операция за промяна на данни спрямо една от таблиците, посочени в изгледа. Най-общо казано, идеята е да:
- Събирайте информация за промените в основната таблица
- Приложете проекциите, филтрите и съединенията, дефинирани в изгледа
- Агрегирайте промените за клъстериран ключ за индексиран изглед
- Решете дали всяка промяна трябва да доведе до вмъкване, актуализиране или изтриване спрямо изгледа
- Изчислете стойностите за промяна, добавяне или премахване в изгледа
- Прилагане на промените в изгледа
Или още по-кратко (макар и с риск от грубо опростяване):
- Изчислете ефектите на инкременталния изглед на оригиналните модификации на данните;
- Приложете тези промени към изгледа
Това обикновено е много по-ефективна стратегия от повторното изграждане на целия изглед след всяка основна промяна на данните (сигурната, но бавна опция), но тя разчита на логиката на постепенната актуализация, която е правилна за всяка възможна промяна на данните, спрямо всяка възможна дефиниция на индексиран изглед.
Както подсказва заглавието, тази статия се занимава с интересен случай, при който логиката на постепенната актуализация се разпада, което води до повреден индексиран изглед, който вече не съответства на основните данни. Преди да стигнем до самата грешка, трябва бързо да прегледаме скаларните и векторните агрегати.
Скаларни и векторни агрегати
В случай, че не сте запознати с термина, има два вида агрегати. Агрегат, който е свързан с клауза GROUP BY (дори ако групата по списък е празна), е известна като векторен агрегат . Агрегат без клауза GROUP BY е известен като скаларен агрегат .
Докато векторният агрегат гарантирано произвежда един изходен ред за всяка група, присъстваща в набора от данни, скаларните агрегати са малко по-различни. Скаларни агрегати винаги произведете един изходен ред, дори ако входният набор е празен.
Пример за векторен агрегат
Следният пример на AdventureWorks изчислява два векторни агрегата (сума и брой) върху празен входен набор:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Тези заявки произвеждат следния изход (без редове):

Резултатът е същият, ако заменим клаузата GROUP BY с празен набор (изисква SQL Server 2008 или по-нова версия):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Плановете за изпълнение и в двата случая са идентични. Това е планът за изпълнение на заявката за броене:
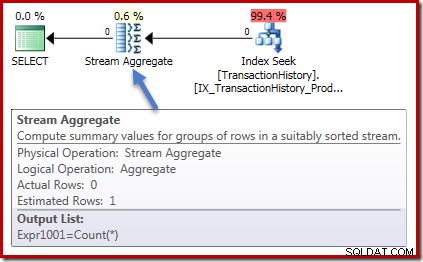
Нулеви редове се въвеждат в Stream Aggregate и нула редове се извеждат. Планът за изпълнение на сумата изглежда така:

Отново нула редове в агрегата и нула редове навън. Всички добри прости неща досега.
Скаларни агрегати
Сега вижте какво се случва, ако премахнем напълно клаузата GROUP BY от заявките:
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
Вместо празен резултат, агрегатът COUNT произвежда нула, а SUM връща NULL:
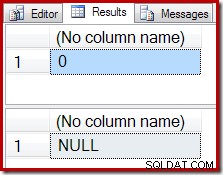
Планът за изпълнение на броене потвърждава, че нулевите входни редове произвеждат един ред изход от Stream Aggregate:
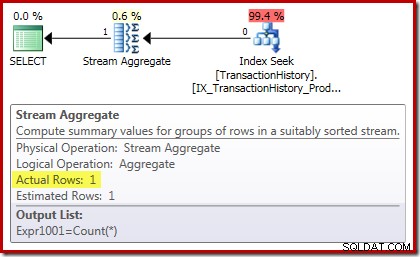
Планът за изпълнение на сумата е още по-интересен:
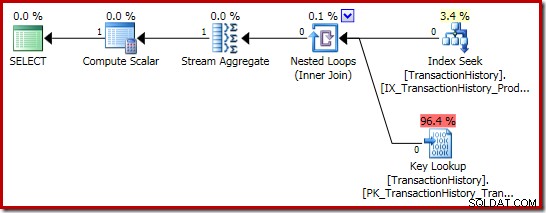
Свойствата на Stream Aggregate показват сборен брой, който се изчислява в допълнение към сумата, която поискахме:
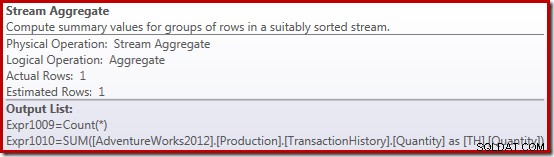
Новият оператор Compute Scalar се използва за връщане на NULL, ако броят на редовете, получени от Stream Aggregate, е нула, в противен случай той връща сбора от събраните данни:
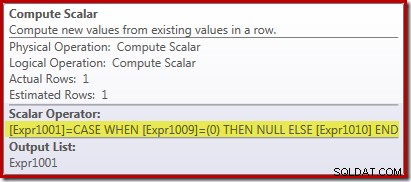
Всичко това може да изглежда малко странно, но ето как работи:
- Векторен агрегат от нулеви редове връща нула редове;
- Скаларен агрегат винаги произвежда точно един ред изход, дори и за празен вход;
- Скаларният брой на нулевите редове е нула; и
- Скаларната сума от нулеви редове е NULL (не нула).
Важният момент за нашите настоящи цели е, че скаларните агрегати винаги произвеждат един ред изходни данни, дори ако това означава създаване на такъв от нищо. Също така, скаларната сума от нулеви редове е NULL, а не нула.
Всички тези поведения са "правилни" между другото. Нещата са такива, каквито са, защото стандартът на SQL първоначално не дефинира поведението на скаларните агрегати, оставяйки го на реализацията. SQL Server запазва оригиналната си реализация поради причини за обратна съвместимост. Векторните агрегати винаги са имали добре дефинирано поведение.
Индексирани изгледи и векторно агрегиране
Сега помислете за прост индексиран изглед, включващ няколко (векторни) агрегати:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Следните заявки показват съдържанието на основната таблица, резултата от заявката за индексирания изглед и резултата от изпълнението на заявката за изглед в таблицата, която е в основата на изгледа:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Резултатите са:
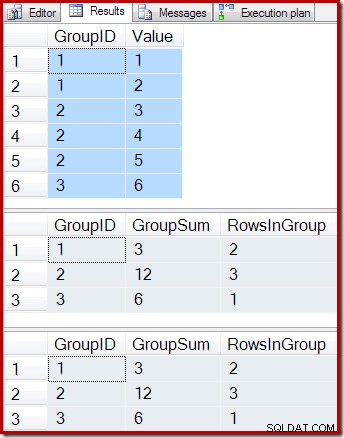
Както се очакваше, индексираният изглед и основната заявка връщат точно същите резултати. Резултатите ще продължат да остават синхронизирани след всякакви и всички възможни промени в основната таблица T1. За да си припомним как работи всичко това, разгледайте простия случай на добавяне на един нов ред към основната таблица:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Планът за изпълнение на това вмъкване съдържа цялата логика, необходима за поддържане на синхронизиран индексиран изглед:
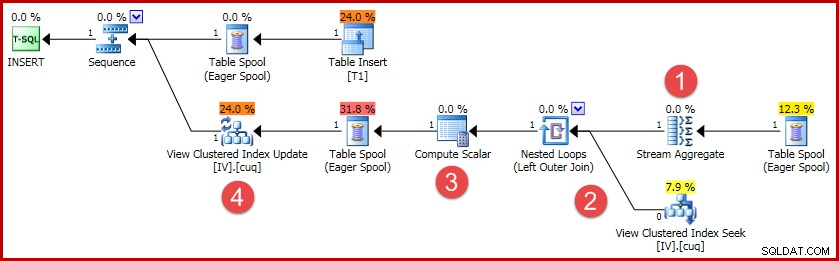
Основните дейности в плана са:
- Агрегатът на потока изчислява промените за индексиран ключ за изглед
- Външното присъединяване към изгледа свързва обобщението на промяната с реда на целевия изглед, ако има такъв
- Скаларът за изчисляване решава дали всяка промяна ще изисква вмъкване, актуализиране или изтриване спрямо изгледа и изчислява необходимите стойности.
- Операторът за актуализиране на изглед физически извършва всяка промяна на клъстерирания индекс на изгледа.
Има някои разлики в плана за различни операции за промяна спрямо основната таблица (например актуализации и изтривания), но общата идея зад поддържането на синхронизиране на изгледа остава същата:обобщете промените по ключ за изглед, намерете реда за изглед, ако съществува, след това изпълнете комбинация от операции за вмъкване, актуализиране и изтриване на индекса на изглед, ако е необходимо.
Без значение какви промени правите в основната таблица в този пример, индексираният изглед ще остане правилно синхронизиран – заявките NOEXPAND и EXPAND VIEWS по-горе винаги ще връщат един и същ набор от резултати. Така винаги трябва да работят нещата.
Индексирани изгледи и скаларно агрегиране
Сега опитайте този пример, където индексираният изглед използва скаларно агрегиране (без клауза GROUP BY в изгледа):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Това е напълно легален индексиран изглед; не се срещат грешки при създаването му. Има една улика, че може да правим нещо малко странно обаче:когато дойде време да материализираме изгледа чрез създаване на необходимия уникален клъстериран индекс, няма очевидна колона, която да изберем като ключ. Обикновено избираме колоните за групиране от клаузата GROUP BY на изгледа, разбира се.
Скриптът по-горе избира произволно колоната NumRows. Този избор не е важен. Чувствайте се свободни да създадете уникалния клъстериран индекс, както решите. Изгледът винаги ще съдържа точно един ред поради скаларните агрегати, така че няма шанс за нарушение на уникален ключ. В този смисъл изборът на ключ за индекс на изглед е излишен, но въпреки това е задължителен.
Използвайки повторно тестовите заявки от предишния пример, можем да видим, че индексираният изглед работи правилно:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
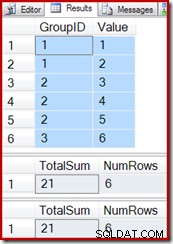
Вмъкването на нов ред в основната таблица (както направихме с векторния агрегатен индексиран изглед) също продължава да работи правилно:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Планът за изпълнение е подобен, но не съвсем идентичен:
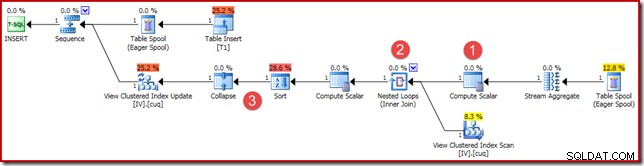
Основните разлики са:
- Този нов Compute Scalar е налице поради същите причини, както когато сравнихме резултатите от векторно и скаларно агрегиране по-рано:той гарантира, че се връща NULL сума (вместо нула), ако агрегатът работи с празен набор. Това е необходимото поведение за скаларен сбор без редове.
- Външното съединение, което се виждаше по-рано, е заменено с вътрешно съединение. Винаги ще има точно един ред в индексирания изглед (поради скаларното агрегиране), така че няма съмнение за необходимост от външно присъединяване, за да се тества дали даден ред на изглед съвпада или не. Единият ред, присъстващ в изгледа, винаги представлява целия набор от данни. Това вътрешно свързване няма предикат, така че технически е кръстосано съединение (към маса с гарантиран единичен ред).
- Операторите за сортиране и свиване присъстват по технически причини, разгледани в предишната ми статия за поддръжка на индексиран изглед. Те не засягат правилната работа на поддръжката на индексирания изглед тук.
Всъщност много различни видове операции за промяна на данни могат да бъдат извършени успешно срещу основната таблица T1 в този пример; ефектите ще бъдат правилно отразени в индексирания изглед. Следните операции за промяна на основната таблица могат да бъдат извършени, като индексираният изглед се поддържа правилен:
- Изтрийте съществуващите редове
- Актуализиране на съществуващите редове
- Вмъкване на нови редове
Това може да изглежда като изчерпателен списък, но не е.
Бъгът е разкрит
Проблемът е доста тънък и е свързан (както трябва да очаквате) с различното поведение на векторните и скаларните агрегати. Ключовите моменти са, че скаларен агрегат винаги ще произвежда изходен ред, дори ако не получава редове на входа си, а скаларната сума на празен набор е NULL, а не нула.
За да създадем проблем, всичко, което трябва да направим, е да вмъкнем или изтрием никакви редове в основната таблица.
Това твърдение не е толкова лудо, колкото изглежда на пръв поглед.
Въпросът е, че заявка за вмъкване или изтриване, която не засяга редове в основната таблица, все още ще актуализира изгледа, тъй като скаларният Stream Aggregate в частта за поддръжка на индексиран изглед на плана на заявката ще произведе изходен ред, дори когато е представен без вход. Скаларът за изчисляване, който следва Stream Aggregate, също ще генерира сума NULL, когато броят на редовете е нула.
Следният скрипт демонстрира грешката в действие:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
Резултатът от този скрипт е показан по-долу:
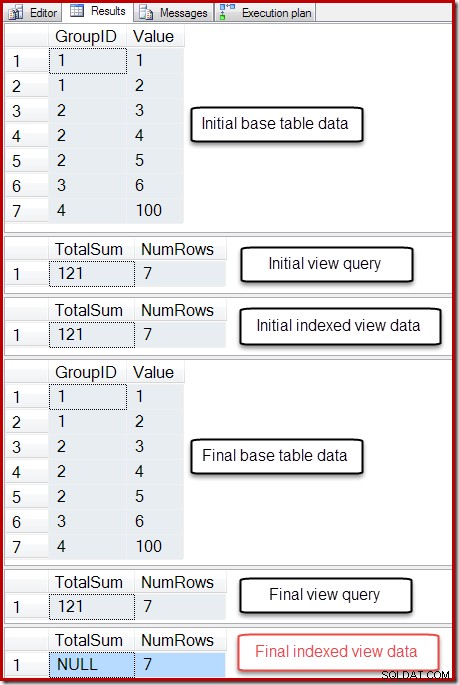
Крайното състояние на колоната Обща сума на индексирания изглед не съвпада с основната заявка за изглед или данните от основната таблица. Сумата NULL е повредила изгледа, което може да се потвърди чрез стартиране на DBCC CHECKTABLE (в индексирания изглед).
Планът за изпълнение, отговорен за корупцията, е показан по-долу:
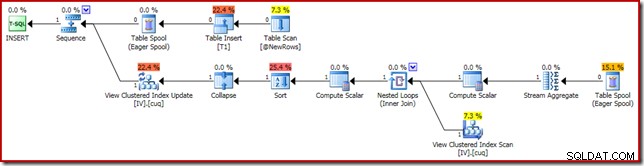
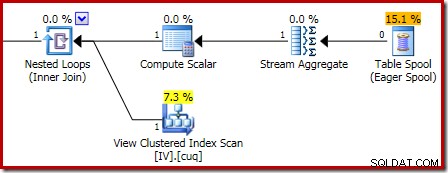
Увеличаването показва входа на нулевите редове в Stream Aggregate и изхода от един ред:
Ако искате да опитате скрипта за повреда по-горе с изтриване вместо вмъкване, ето един пример:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
Изтриването не засяга редове в основната таблица, но все пак променя колоната за сума на индексирания изглед на NULL.
Обобщаване на грешката
Вероятно можете да измислите произволен брой заявки за вмъкване и изтриване на основна таблица, които не засягат редове и причиняват повреда на този индексиран изглед. Същият основен проблем обаче се отнася за по-широк клас проблеми от просто вмъквания и изтривания, които не засягат редове в основната таблица.
Възможно е например да се произведе същата повреда чрез вмъкване, което прави добавяне на редове към основната таблица. Основната съставка е, че нито един добавен ред не трябва да отговаря на изискванията за изглед . Това ще доведе до празен вход към Stream Aggregate и до причиняващ корупция изход NULL ред от следния изчислителен скалар.
Един от начините да постигнете това е да включите клауза WHERE в изгледа, който отхвърля някои от редовете на основната таблица:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Като се има предвид новото ограничение за групови идентификатори, включени в изгледа, следното вмъкване ще добави редове към основната таблица, но все пак индексираният изглед ще повреди сумата NULL:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; Резултатът показва вече познатото повреждане на индекса:
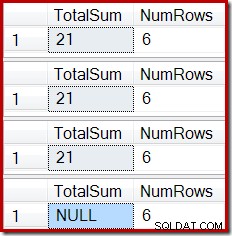
Подобен ефект може да се получи с помощта на изглед, който съдържа едно или повече вътрешни съединения. Докато редовете, добавени към основната таблица, се отхвърлят (например при неуспешно присъединяване), Stream Aggregate няма да получава редове, Compute Scalar ще генерира сума NULL и индексираният изглед вероятно ще се повреди.
Последни мисли
Този проблем не се появява при заявки за актуализиране (поне доколкото мога да преценя), но това изглежда е по-скоро случайно, отколкото дизайн – проблемният Stream Aggregate все още присъства в потенциално уязвимите планове за актуализиране, но Compute Scalar, който генерира сумата NULL не се добавя (или може би се оптимизира). Моля, уведомете ме, ако успеете да възпроизведете грешката чрез заявка за актуализиране.
Докато тази грешка не бъде коригирана (или може би скаларните агрегати станат забранени в индексираните изгледи), бъдете много внимателни при използването на агрегати в индексиран изглед без клауза GROUP BY.
Тази статия беше предизвикана от елемент на Connect, изпратен от Владимир Молдованенко, който беше любезен да остави коментар към моя стара публикация в блога (която се отнася до различна корупция в индексираните изгледи, причинена от изявлението MERGE). Владимир използва скаларни агрегати в индексиран изглед по основателни причини, така че не бързайте да прецените тази грешка като крайна ситуация, която никога няма да срещнете в производствена среда! Благодаря на Владимир, че ме предупреди за неговия елемент Connect.