Въведение
- Има някои специфични правила, които трябва да се спазват, докато създавате обектите на базата данни. За да се подобри производителността на база данни, на таблица трябва да се присвои първичен ключ, клъстерирани и неклъстерирани индекси и ограничения. Въпреки че следваме всички тези правила, дублиращи се редове все още може да се появят в таблица.
- Винаги е добра практика да се използват ключовете на базата данни. Използването на ключовете на базата данни ще намали шансовете за получаване на дублирани записи в таблица. Но ако дублиращи се записи вече присъстват в таблица, има специфични начини, които се използват за премахване на тези дублиращи се записи.
Начини за премахване на дублиращи се редове
- Използване на DELETE JOIN изявление за премахване на дублиращи се редове
Инструкцията DELETE JOIN е предоставена в MySQL, която помага за премахване на дублиращи се редове от таблица.
Помислете за база данни с име "studentdb". Ще създадем таблица студент в нея.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
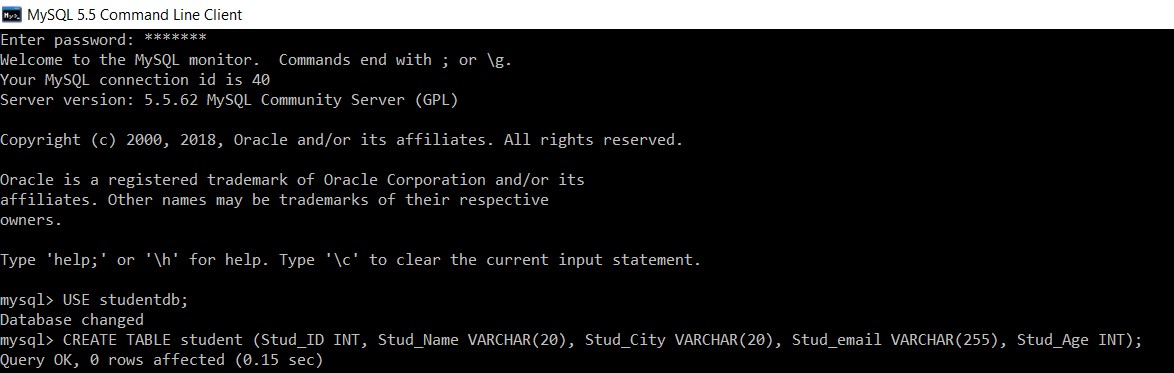
Успешно създадохме таблица „student“ в базата данни „studentdb“.
Сега ще напишем следните заявки, за да вмъкнем данни в таблицата на учениците.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
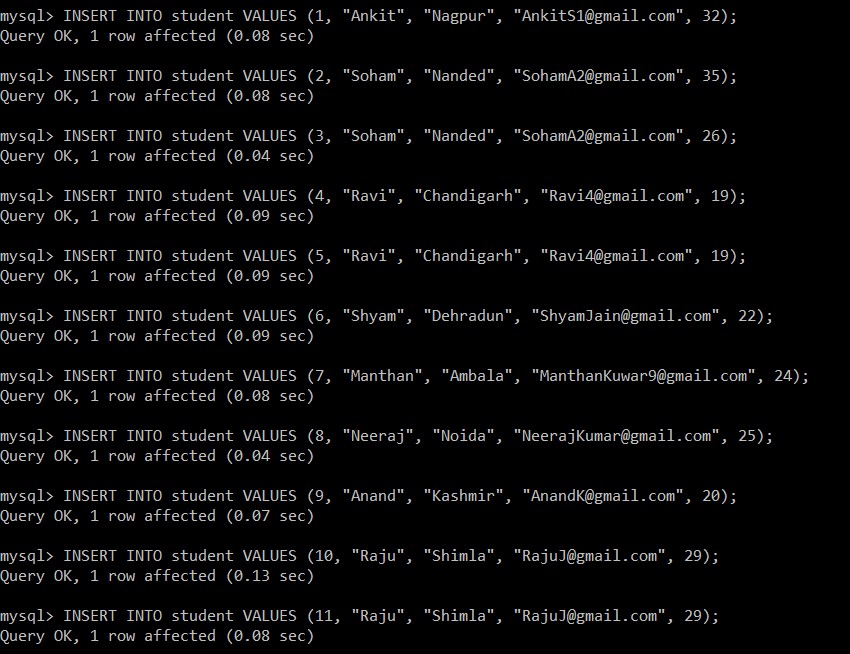
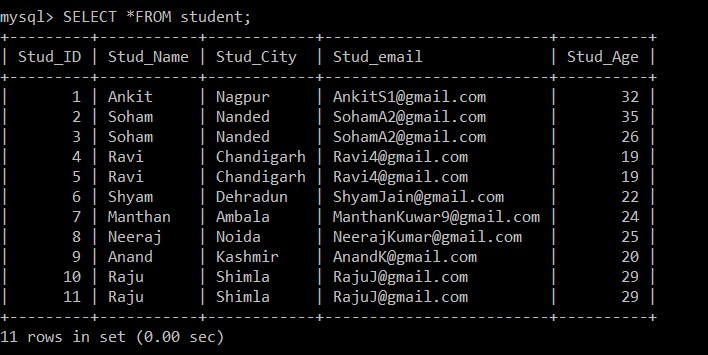
Сега ще извлечем всички записи от таблицата на учениците. Ще разгледаме тази таблица и база данни за всички следващи примери.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Пример 1:
Напишете заявка за изтриване на дублиращи се редове от таблицата на учениците с помощта на DELETE JOIN изявление.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Използвахме заявката DELETE с INNER JOIN. За да приложим INNER JOIN в една таблица, създадохме два екземпляра s1 и s2. След това, с помощта на клаузата WHERE, проверихме две условия, за да открием дублиращите се редове в таблицата на учениците. Ако идентификационният номер на имейл в два различни записа е един и същ и студентският идентификатор е различен, той ще бъде третиран като дублиран запис според условието WHERE.
Изход:
Query OK, 3 rows affected (0.20 sec)Резултатите от горната заявка показват, че в таблицата на учениците има три дублиращи се записа.

Ще използваме заявката SELECT, за да намерим дублиращите се записи, които са били изтрити.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
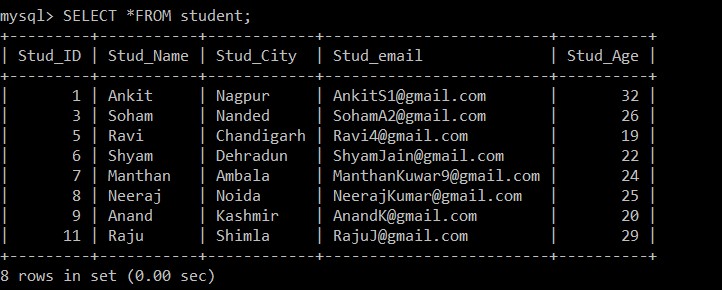
Сега има само 8 записа, които присъстват в таблицата на учениците, тъй като трите дублиращи се записа се изтриват от текущо избраната таблица. Според следното условие:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Ако имейл идентификаторите на всеки два записа са еднакви, тогава тъй като знакът по-малко от се използва между студентския идентификатор, ще се съхранява само записът с по-големи идентификационни номера на служителите, а другият дублиран запис ще бъде изтрит между двата записа.
Пример 2:
Напишете заявка за изтриване на дублиращи се редове от таблицата на учениците, като използвате оператора delete join, като същевременно запазите дублирания запис с по-малък идентификатор на служител и изтриете другия.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Използвахме заявката DELETE с INNER JOIN. За да приложим INNER JOIN в една таблица, създадохме два екземпляра s1 и s2. След това, с помощта на клаузата WHERE, проверихме две условия, за да открием дублиращите се редове в таблицата на учениците. Ако идентификационният номер на имейл, присъстващ в два различни записа, е един и същ и идентификационният номер на ученика е различен, той ще бъде третиран като дублиран запис според условието WHERE.
Изход:
Query OK, 3 rows affected (0.09 sec)Резултатите от горната заявка показват, че в таблицата на учениците има три дублиращи се записа.

Ще използваме заявката SELECT, за да намерим дублиращите се записи, които са били изтрити.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
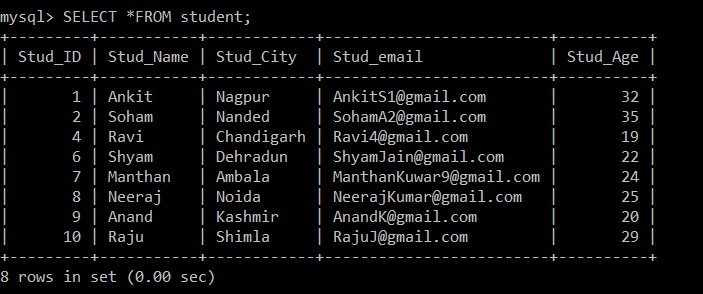
Сега има само 8 записа, които присъстват в таблицата на учениците, тъй като трите дублиращи се записа се изтриват от текущо избраната таблица. Според следното условие:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Ако имейл идентификаторите на всеки два записа са еднакви, тъй като знакът по-голям от се използва между студентския идентификатор, ще се съхранява само записът с по-малкия идентификатор на служител, а другият дублиран запис ще бъде изтрит между двата записа.
- Използване на междинна таблица за премахване на дублиращи се редове
Следните стъпки трябва да се следват, докато премахвате дублиращите се редове с помощта на междинна таблица.
- Трябва да се създаде нова таблица, която ще бъде същата като действителната таблица.
- Добавете отделни редове от действителната таблица към новосъздадената таблица.
- Изхвърлете действителната таблица и преименувайте новата таблица със същото име като действителната таблица.
Пример:
Напишете заявка за изтриване на дублираните записи от таблицата на учениците, като използвате междинна таблица.
Стъпка 1:
Първо, ще създадем междинна таблица, която ще бъде същата като таблицата на служителите.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Тук „служител“ е оригиналната таблица, а „temp_student“ е междинната таблица.
Стъпка 2:
Сега ще извлечем само уникалните записи от таблицата на студентите и ще вмъкнем всички извлечени записи в таблицата temp_student.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Тук, преди да вмъкнете отделните записи от студентската таблица в temp_student, всички дублиращи се записи се филтрират от Stud_email. След това само записите с уникален имейл идентификатор са били вмъкнати в temp_student.
Стъпка 3:
След това ще премахнем таблицата на студентите и ще преименуваме таблицата temp_student на таблицата на студентите.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
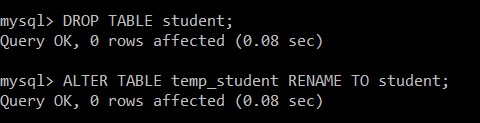
Таблицата на студентите е премахната успешно и temp_student се преименува на таблицата на студентите, която съдържа само уникалните записи.
След това трябва да проверим дали таблицата на учениците вече съдържа само уникалните записи. За да проверим това, използвахме заявката SELECT, за да видим данните, съдържащи се в таблицата на учениците.
mysql> SELECT *FROM student;Изход:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
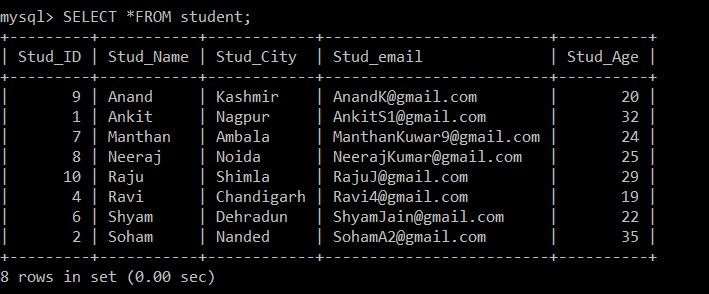
Сега има само 8 записа, които присъстват в таблицата на учениците, тъй като трите дублиращи се записа се изтриват от текущо избраната таблица. В стъпка 2, докато се извличат отделните записи от оригиналната таблица и се вмъкват в междинна таблица, в Stud_email беше използвана клауза GROUP BY, така че всички записи бяха вмъкнати въз основа на имейл идентификаторите на учениците. Тук само записът с по-нисък идентификационен номер на служител се съхранява сред дублиращите се записи по подразбиране, а другият се изтрива.