Миналата година публикувах съвет, наречен Подобряване на ефективността на SQL Server чрез превключване към ВМЕСТО тригери.
Основната причина, поради която съм склонен да предпочитам спусък ВМЕСТО, особено в случаите, когато очаквам много нарушения на бизнес логиката, е, че изглежда интуитивно, че би било по-евтино да се предотврати действието като цяло, отколкото да се продължи и да се извърши (и регистрирайте го!), само за да използвате тригер AFTER, за да изтриете редовете в нарушение (или да върнете назад цялата операция). Резултатите, показани в този съвет, показаха, че това всъщност е така – и подозирам, че ще бъдат още по-изразени с повече неклъстерни индекси, засегнати от операцията.
Това обаче беше на бавен диск и на ранен CTP на SQL Server 2014. При подготовката на слайд за нова презентация, която ще направя тази година за тригери, открих, че в по-нова версия на SQL Server 2014 – в комбинация с актуализиран хардуер – беше малко по-трудно да се демонстрира същата делта в производителността между тригер AFTER и INSTEAD OF. Затова се заех да открия защо, въпреки че веднага знаех, че това ще бъде повече работа, отколкото съм правил за един слайд.
Едно нещо, което искам да спомена е, че тригерите могат да използват tempdb по различни начини и това може да обясни някои от тези разлики. Тригер AFTER използва хранилището на версиите за вмъкнатите и изтрити псевдо-таблици, докато тригер INSTEAD OF прави копие на тези данни във вътрешна работна таблица. Разликата е фина, но си струва да се отбележи.
Променливите
Ще тествам различни сценарии, включително:
- Три различни задействания:
- Задействане AFTER, което изтрива конкретни редове, които не успяват
- Задействане AFTER, което отменя цялата транзакция, ако някой ред е неуспешен
- Задействане ВМЕСТО, което вмъква само редовете, които преминават
- Различни модели за възстановяване и настройки за изолиране на моментни снимки:
- ПЪЛНО с активирана МОМЕНТАЛНА СНИМКА
- ПЪЛЕН с деактивирана МОМЕНТАЛНА СНИМКА
- Просто с активирана МОМЕНТАЛНА СНИМКА
- ПРОСТО с деактивирана МОМЕНТАЛНА СНИМКА
- Различни оформления на дискове*:
- Данни на SSD, влезте в HDD със 7200 RPM
- Данни на SSD, влезте в SSD
- Данни на 7200 RPM HDD, влезте в SSD
- Данни на 7200 RPM HDD, влезте в HDD със 7200 RPM
- Различна честота на отказ:
- 10%, 25% и 50% процент на неуспех в:
- Единична партидна вложка от 20 000 реда
- 10 партиди от 2000 реда
- 100 партиди от 200 реда
- 1000 партиди от 20 реда
- 20 000 единични вложки
*
tempdbе единичен файл с данни на бавен диск със 7200 RPM. Това е умишлено и има за цел да засили всички тесни места, причинени от различните употреби наtempdb. Планирам да преразгледам този тест в някакъв момент, когатоtempdbе на по-бърз SSD. - 10%, 25% и 50% процент на неуспех в:
Добре, TL; DR Вече!
Ако просто искате да знаете резултатите, пропуснете надолу. Всичко по средата е само фон и обяснение как настроих и проведох тестовете. Не съм съкрушен, че не всеки ще се интересува от всички тънкости.
Сценарият
За този конкретен набор от тестове сценарият в реалния живот е този, при който потребителят избира екранно име, а задействането е предназначено да улавя случаи, когато избраното име нарушава някои правила. Например, това не може да бъде някаква вариация на "ninny-muggins" (със сигурност можете да използвате въображението си тук).
Създадох таблица с 20 000 уникални потребителски имена:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
След това създадох таблица, която ще бъде източникът за моите "палави имена", с които да проверя. В този случай това е просто ninny-muggins-00001 чрез ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Създадох тези таблици в model база данни, така че всеки път, когато създавам база данни, тя ще съществува локално и планирам да създам много бази данни, за да тествам матрицата на сценариите, изброена по-горе (вместо просто да променя настройките на базата данни, да изчистя регистрационния файл и т.н.). Моля, имайте предвид, че ако създавате обекти в модел за целите на тестване, уверете се, че сте изтрили тези обекти, когато сте готови.
Като настрана, ще оставя умишлено ключови нарушения и обработка на други грешки от това, като правя наивното предположение, че избраното име се проверява за уникалност много преди да се направи опит за вмъкване, но в рамките на същата транзакция (точно като Проверка срещу палавата таблица с имена можеше да бъде направена предварително).
За да подкрепя това, създадох и следните три почти идентични таблици в model , за целите на тестовата изолация:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
И следните три задействания, по едно за всяка таблица:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Вероятно бихте искали да обмислите допълнителна обработка, за да уведомите потребителя, че изборът му е отменен или игнориран – но това също е пропуснато за простота.
Тестовата настройка
Създадох примерни данни, представящи трите процента на отказ, които исках да тествам, като промених 10 процента на 25 и след това 50 и добавих и тези таблици към model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Всяка таблица има 20 000 реда, с различен микс от имена, които ще преминат и се провалят, а колоната с номера на редовете улеснява разделянето на данните на различни размери на партиди за различни тестове, но с повтарящи се проценти на отказ за всички тестове.
Разбира се, имаме нужда от място, където да уловим резултатите. Избрах да използвам отделна база данни за това, като стартирам всеки тест няколко пъти, просто заснемайки продължителността.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Попълних dbo.Tests таблица със следния скрипт, така че да мога да изпълня различни части, за да настроя четирите бази данни да съответстват на текущите параметри на теста. Имайте предвид, че D:\ е SSD, докато G:\ е диск със 7200 RPM:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) След това беше лесно да стартирате всички тестове няколко пъти:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
В моята система това отне близо 6 часа, така че бъдете готови да оставите това да работи без прекъсване. Също така се уверете, че нямате отворени активни връзки или прозорци за заявка спрямо model база данни, в противен случай може да получите тази грешка, когато скриптът се опита да създаде база данни:
Не можа да се получи изключително заключване на база данни „модел“. Опитайте отново операцията по-късно.
Резултати
Има много точки от данни, които да разгледате (и всички заявки, използвани за извличане на данните, са посочени в приложението). Имайте предвид, че всяка средна продължителност, посочена тук, е над 10 теста и вмъква общо 100 000 реда в таблицата на местоназначението.
Графика 1 – Общи агрегати
Първата графика показва общите агрегати (средна продължителност) за различните променливи в изолация (така че *всички* тестове, използващи тригер AFTER, който изтрива, *всички* тестове, използващ тригер AFTER, който се връща назад и т.н.).
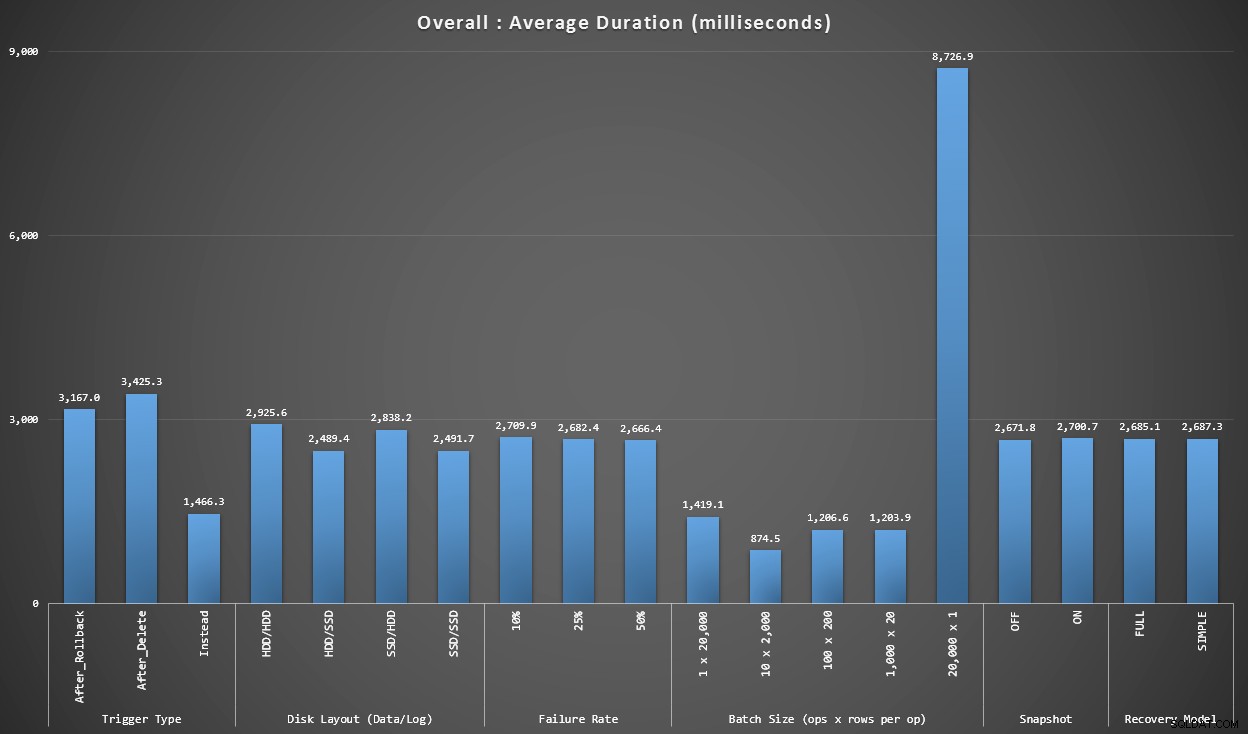
Средна продължителност, в милисекунди, за всяка променлива в изолация
Веднага ни изскачат няколко неща:
- Задействането INSTEAD OF тук е два пъти по-бързо от двете задействания AFTER.
- Наличието на регистрационния файл на транзакциите на SSD направи малко разлика. Местоположението на файла с данни е много по-малко.
- Партията от 20 000 единични вложки беше 7-8 пъти по-бавна от която и да е друга партидна дистрибуция.
- Вмъкването на единична партида от 20 000 реда беше по-бавно от което и да е от разпределенията, които не са единични.
- Процентът на откази, изолирането на моментна снимка и моделът за възстановяване имаха малко или изобщо влияние върху производителността.
Графика 2 – Най-добрите 10 като цяло
Тази графика показва най-бързите 10 резултата, когато се вземе предвид всяка променлива. Всичко това са ВМЕСТО тригери, при които най-големият процент от редовете се провалят (50%). Изненадващо, най-бързият (макар и не много) имаше както данни, така и вход на един и същ твърд диск (не SSD). Тук има смесица от оформления на дискове и модели за възстановяване, но всичките 10 имат активирана изолация на моментни снимки, а първите 7 резултата включват партида 10 x 2000 реда.
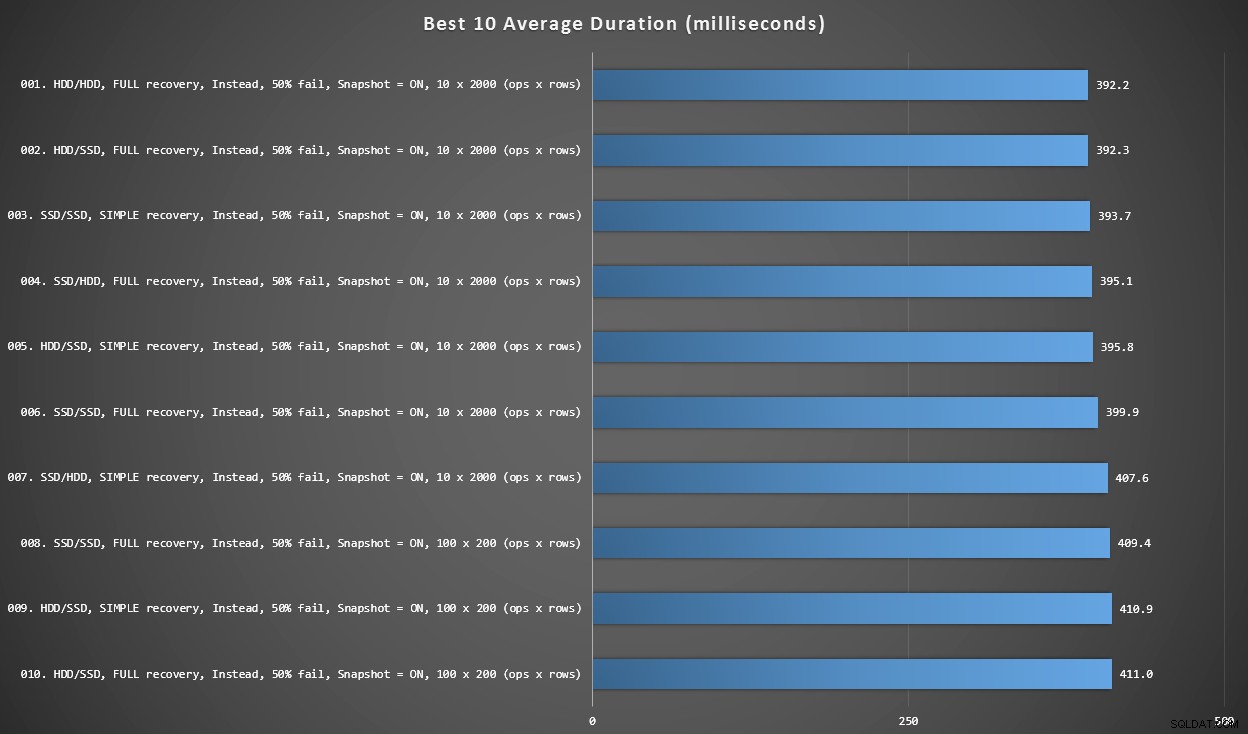
Най-добрите 10 продължителност, в милисекунди, като се има предвид всяка променлива
Най-бързият тригер AFTER – вариант ROLLBACK с 10% процент на отказ в партидата от 100 x 200 реда – дойде на позиция #144 (806 ms).
Графика 3 – Най-лошите 10 като цяло
Тази графика показва най-бавните 10 резултата, когато се вземе предвид всяка променлива; всички са AFTER варианти, всички включват 20 000 singleton вмъквания и всички имат данни и влизат на един и същ бавен HDD.
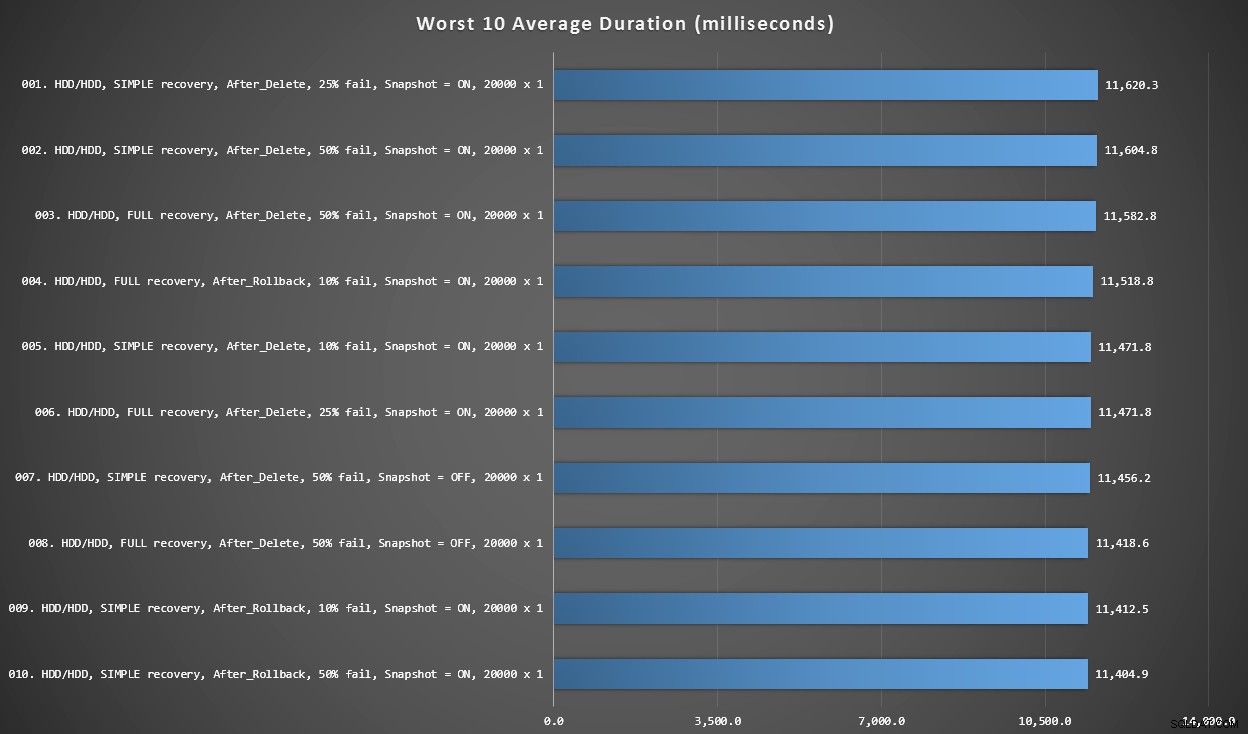
Най-лошите 10 продължителност, в милисекунди, като се има предвид всяка променлива
Най-бавният тест ВМЕСТО беше в позиция #97, при 5 680 ms – тест с 20 000 сингълтон, където 10% не успяха. Интересно е също да се отбележи, че нито един тригер AFTER, използващ партидата от 20 000 единични вмъквания, се е представил по-добре – всъщност 96-ият най-лош резултат беше тест AFTER (изтриване), който дойде при 10 219 ms – почти двойно повече от следващия най-бавен резултат.
Графика 4 – Тип на регистрационния диск, единични вложки
Графиките по-горе ни дават груба представа за най-големите болезнени точки, но те или са твърде увеличени, или не са увеличени достатъчно. Тази графика се филтрира до данни въз основа на реалността:в повечето случаи този тип операция ще бъде еднократно вмъкване. Мислех, че ще го разбия по честота на откази и типа диск, на който е регистрационният файл, но погледнете само редовете, където партидата се състои от 20 000 отделни вмъквания.
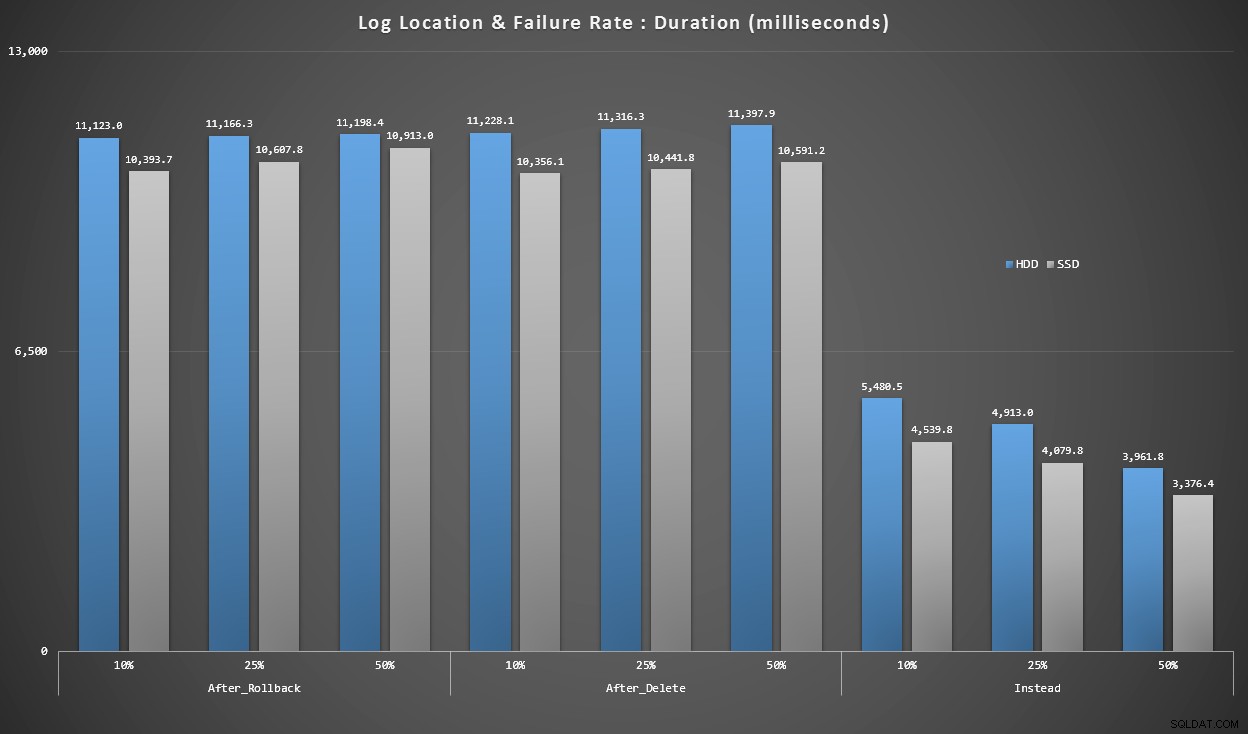
Продължителност, в милисекунди, групирана по честота на отказ и местоположение на регистрационния файл, за 20 000 отделни вложки
Тук виждаме, че всички задействания AFTER са средно в диапазона от 10-11 секунди (в зависимост от местоположението на регистрационния файл), докато всички задействания INSTEAD OF са доста под 6-те секунди.
Заключение
Засега ми се струва ясно, че спусъкът INSTEAD OF е печеливш в повечето случаи – в някои случаи повече от други (например, когато процентът на отказ се увеличава). Други фактори, като модел за възстановяване, изглежда имат много по-малко влияние върху цялостната производителност.
Ако имате други идеи за това как да разбиете данните или искате копие на данните, за да извършите собствено нарязване и нарязване на кубчета, моля, уведомете ме. Ако искате помощ при настройването на тази среда, така че да можете да провеждате свои собствени тестове, аз също мога да помогна с това.
Въпреки че този тест показва, че ВМЕСТО тригерите определено си струва да се обмислят, това не е цялата история. Буквално съединих тези тригери, използвайки логиката, която смятах, че има най-голям смисъл за всеки сценарий, но кодът за задействане – като всеки T-SQL израз – може да бъде настроен за оптимални планове. В последваща публикация ще разгледам потенциална оптимизация, която може да направи задействането AFTER по-конкурентоспособно.
Приложение
Заявки, използвани за секцията Резултати:
Графика 1 – Общи агрегати
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Графика 2 и 3 – Най-добри и най-лоши 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Графика 4 – Тип на регистрационния диск, единични вложки
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;