Отговорът, разбира се, ще бъде "зависи", но въз основа на тестване на този край...
Ако приемем
- 1 милион продукта
productима клъстериран индекс наproduct_id- Повечето (ако не всички) продукти имат съответната информация в
product_codeтаблица - Идеални индекси, налични в
product_codeи за двете заявки.
PIVOT версията в идеалния случай се нуждае от индекс product_code(product_id, type) INCLUDE (code) докато JOIN версията в идеалния случай се нуждае от индекс product_code(type,product_id) INCLUDE (code)
Ако те са налице, давам плановете по-долу
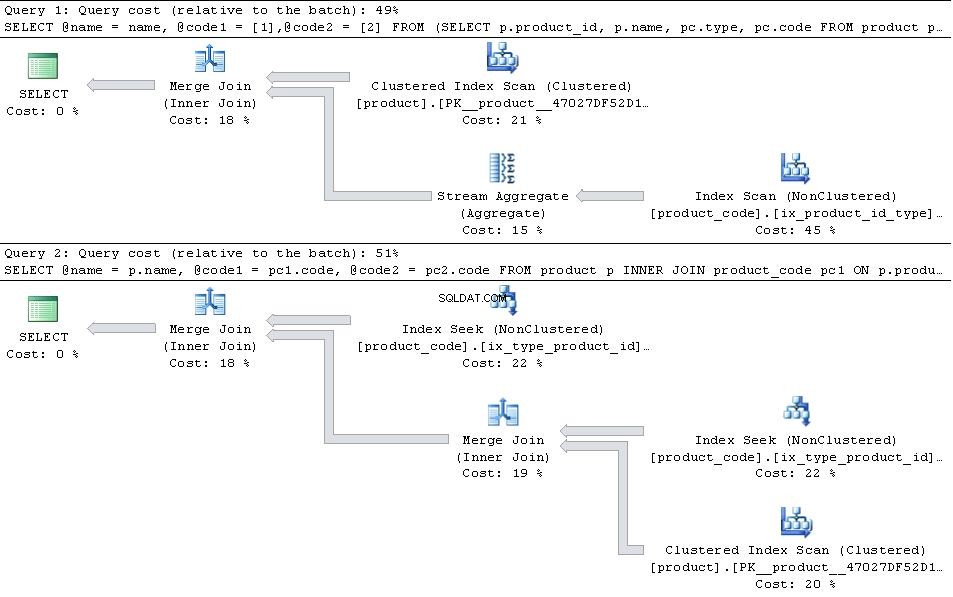
след това JOIN версията е по-ефективна.
В случай, че type 1 и type 2 са единствените types в таблицата, след това PIVOT версията има леко предимство по отношение на броя на четенията, тъй като не е нужно да търси в product_code два пъти, но това е повече от надвишено от допълнителните режийни разходи на оператора за агрегиране на поток
ОБОРОТ
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
Присъединете се
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Ако има допълнителен type записи, различни от 1 и 2 JOIN версията ще увеличи предимството си, тъй като просто прави обединения за сливане в съответните секции на type,product_id индекс, докато PIVOT планът използва product_id, type и така ще трябва да сканира допълнителния type редове, които се смесват с 1 и 2 редове.