По-рано писах за свойството Actual Rows Read. Той ви казва колко реда всъщност се четат от индексно търсене, така че да можете да видите колко селективен е предикатът за търсене в сравнение със селективността на предиката за търсене плюс остатъчен предикат, комбинирани.
Но нека да разгледаме какво всъщност се случва в оператора Seek. Защото не съм убеден, че „Действително прочетени редове“ е непременно точно описание на случващото се.
Искам да разгледам пример, който заявява адреси на конкретни типове адреси за клиент, но принципът тук лесно би се приложил към много други ситуации, ако формата на вашата заявка пасва, като например търсене на атрибути в таблица с двойки ключ-стойност, например.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Знам, че не съм ви показал нищо за метаданните – ще се върна към това след минута. Нека помислим за тази заявка и какъв вид индекс бихме искали да имаме за нея.
Първо, ние знаем точно CustomerID. Съвпадение на равенство като това обикновено го прави отличен кандидат за първата колона в индекс. Ако имахме индекс в тази колона, бихме могли да се потопим направо в адресите на този клиент – така че бих казал, че това е безопасно предположение.
Следващото нещо, което трябва да вземете предвид, е този филтър на AddressTypeID. Добавянето на втора колона към ключовете на нашия индекс е напълно разумно, така че нека го направим. Нашият индекс вече е включен (CustomerID, AddressTypeID). И нека ВКЛЮЧИМ Пълен адрес, така че да не се налага да правим никакви справки, за да завършим картината.
И мисля, че сме готови. Би трябвало да можем спокойно да приемем, че идеалният индекс за тази заявка е:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Потенциално бихме могли да го декларираме като уникален индекс – ще разгледаме ефекта от това по-късно.
Така че нека създадем таблица (използвам tempdb, защото нямам нужда от нея, за да продължи извън тази публикация в блога) и да тестваме това.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Не ме интересуват ограниченията на външния ключ или какви други колони може да има. Интересувам се само от моя идеален индекс. Така че създайте и това, ако още не сте го направили.
Планът ми изглежда доста перфектен.
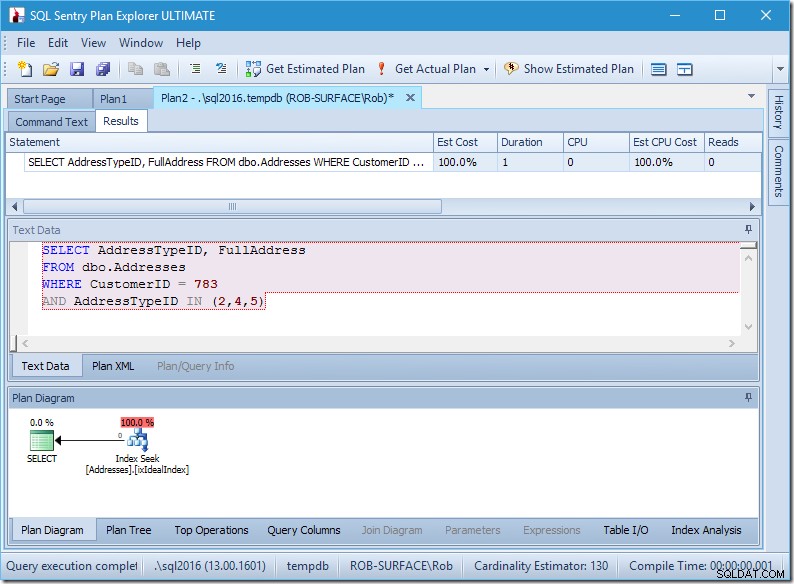
Имам търсене на индекс и това е всичко.
Разбира се, няма данни, така че няма четене, няма процесор и също работи доста бързо. Само ако всички заявки могат да бъдат настроени, както и това.
Нека видим какво се случва малко по-отблизо, като разгледаме свойствата на Seek.
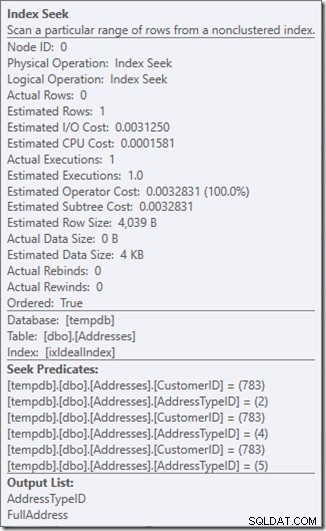
Можем да видим предикатите за търсене. Има шест. Три за CustomerID и три за AddressTypeID. Това, което всъщност имаме тук, са три набора предикати за търсене, които показват три операции за търсене в рамките на единичния оператор Търсене. Първото търсене търси Клиент 783 и AddressType 2. Второто търси 783 и 4, а последното 783 и 5. Нашият оператор Търсене се появи веднъж, но в него имаше три търсения.
Дори нямаме данни, но можем да видим как ще се използва нашият индекс.
Нека добавим някои фиктивни данни, за да можем да разгледаме част от въздействието на това. Ще поставя адреси за типове от 1 до 6. Всеки клиент (над 2000, въз основа на размера на master..spt_values ) ще има адрес от тип 1. Може би това е основният адрес. Оставям 80% да имат адрес тип 2, 60% тип 3 и така нататък, до 20% за тип 5. Ред 783 ще получи адреси от тип 1, 2, 3 и 4, но не и 5. Предпочитам да използвам произволни стойности, но искам да се уверя, че сме на една и съща страница за примерите.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Сега нека разгледаме нашата заявка с данни. Излизат два реда. Както преди, но сега виждаме двата реда, излизащи от оператора Seek, и виждаме шест четения (в горния десен ъгъл).
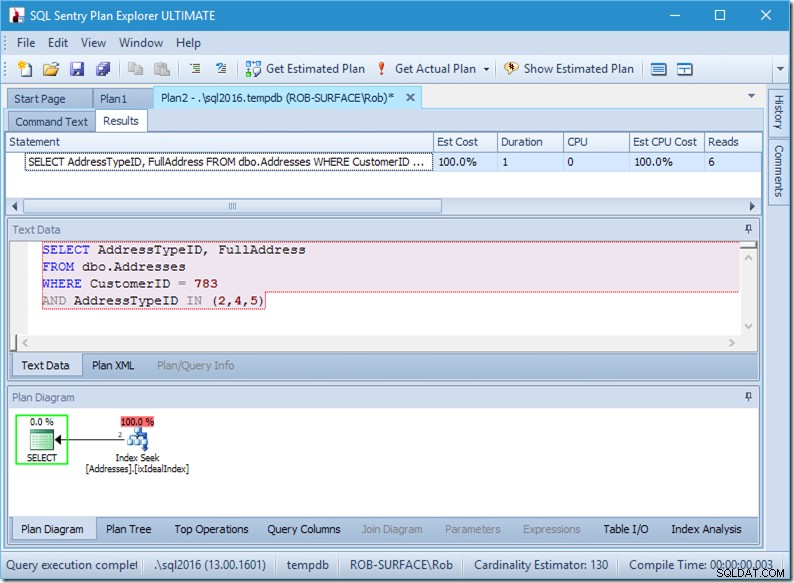
Шест четения има смисъл за мен. Имаме малка таблица и индексът се побира само на две нива. Правим три търсения (в рамките на един единствен оператор), така че машината чете основната страница, открива коя страница да отиде надолу и я чете, и прави това три пъти.
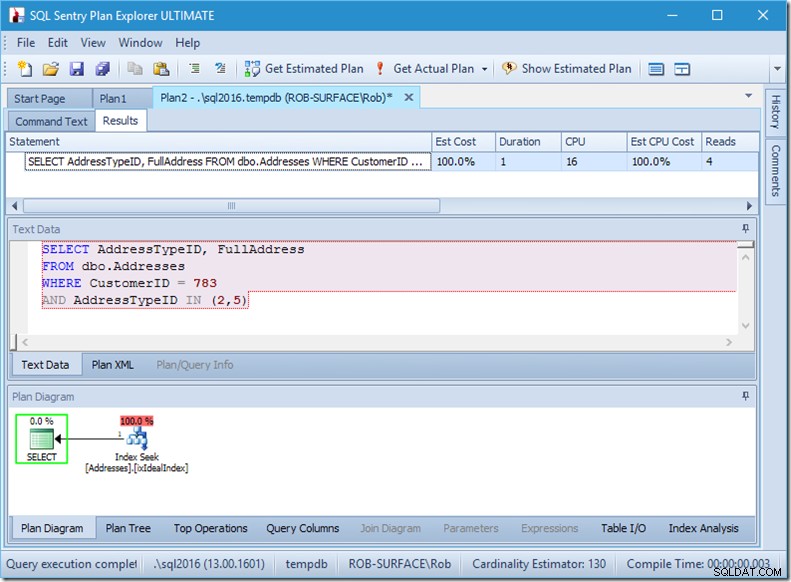
Ако просто търсим два AddressTypeID, ще видим само 4 четения (и в този случай се извежда един ред). Отлично.
И ако търсихме 8 типа адреси, щяхме да видим 16.
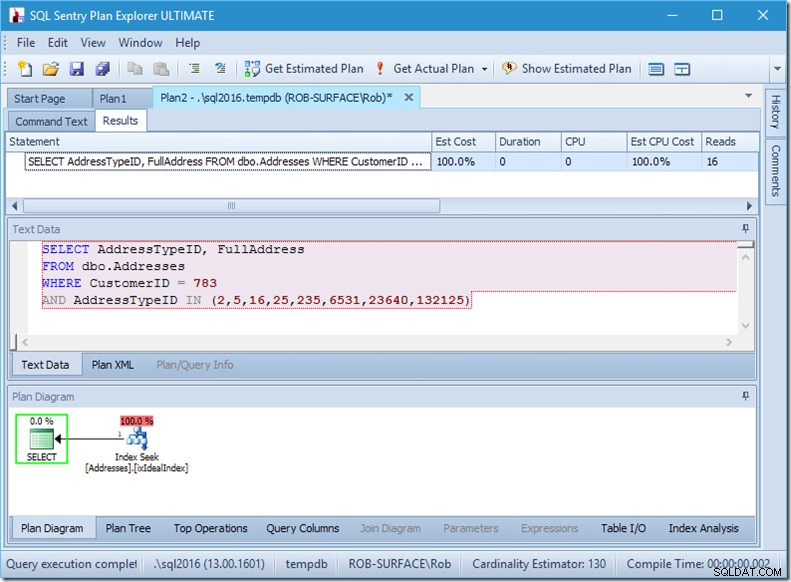
И все пак всеки от тях показва, че прочетените действителни редове съвпадат точно с действителните редове. Никаква неефективност!
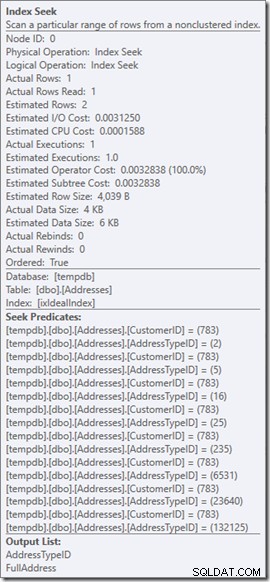
Нека се върнем към първоначалната си заявка, търсейки типове адреси 2, 4 и 5 (което връща 2 реда) и да помислим какво се случва в търсенето.
Предполагам, че системата за запитвания вече е свършила работата, за да разбере, че търсенето в индекс е правилната операция и че има под ръка номера на страницата на корена на индекса.
В този момент той зарежда тази страница в паметта, ако все още не е там. Това е първото четене, което се отчита при изпълнението на търсенето. След това намира номера на страницата за реда, който търси, и чете тази страница. Това е второто четене.
Но често пренебрегваме този бит „намира номера на страницата“.
С помощта на DBCC IND(2, N'dbo.Address', 2); (първият 2 е идентификаторът на базата данни, защото използвам tempdb; вторият 2 е индексният идентификатор на ixIdealIndex ), мога да открия, че 712 във файл 1 е страницата с най-високо ниво на индекс. На екранната снимка по-долу виждам, че страница 668 е IndexLevel 0, което е основната страница.

Така че сега мога да използвам DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); за да видите съдържанието на страница 712. На моята машина се връщат 84 реда и мога да кажа, че CustomerID 783 ще бъде на страница 1004 от файл 5.
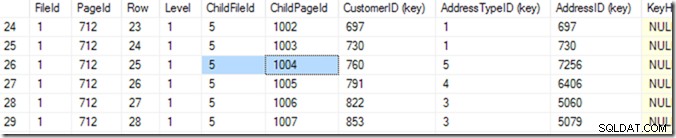
Но знам това, като превъртя списъка си, докато не видя този, който искам. Започнах с превъртане малко надолу и след това се върнах нагоре, докато не намерих реда, който исках. Компютърът нарича това двоично търсене и е малко по-точно от мен. Той търси реда, където комбинацията (CustomerID, AddressTypeID) е по-малка от тази, която търся, като следващата страница е по-голяма или същата като нея. Казвам „същото“, защото може да има две, които съвпадат, разпределени на две страници. Той знае, че има 84 реда (от 0 до 83) данни в тази страница (чете това в заглавката на страницата), така че ще започне с проверка на ред 41. От там той знае в коя половина да търси и (в този пример), той ще прочете ред 20. Още няколко четения (което прави 6 или 7 общо)* и знае, че ред 25 (моля, вижте колоната, наречена „Row“ за тази стойност, а не номера на реда, предоставен от SSMS ) е твърде малък, но ред 26 е твърде голям – така че 25 е отговорът!
*При двоично търсене търсенето може да бъде малко по-бързо, ако има късмет, когато раздели блока на две, ако няма среден слот и в зависимост от това дали средният слот може да бъде елиминиран или не.
Сега може да отиде на страница 1004 във файл 5. Нека използваме DBCC PAGE на тази.
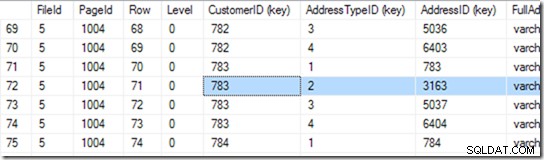
Този ми дава 94 реда. Той прави друго двоично търсене, за да намери началото на диапазона, който търси. Трябва да прегледа 6 или 7 реда, за да намери това.
„Начало на диапазона?“ Чувам те да питаш. Но ние търсим адрес тип 2 на клиент 783.
Така е, но не сме декларирали този индекс за уникален. Така че може да има две. Ако е уникален, търсенето може да извърши еднократно търсене и може да се натъкне на него по време на двоичното търсене, но в този случай трябва да завърши двоичното търсене, за да намери първия ред в диапазона. В този случай това е ред 71.
Но ние не спираме до тук. Сега трябва да видим дали наистина има втори! Така че чете и ред 72 и открива, че двойката CustomerID+AddressTypeiD наистина е твърде голяма и търсенето й е завършено.
И това се случва три пъти. Третият път не намира ред за клиент 783 и адрес тип 5, но не знае това предварително и все пак трябва да завърши търсенето.
Така че редовете, които всъщност се четат в тези три търсения (за да се намерят два реда за извеждане), са много повече от върнатото число. Има около 7 на ниво индекс 1 и още около 7 на ниво лист, само за да се намери началото на диапазона. След това чете реда, който ни интересува, и след това реда след това. Това ми звучи повече като 16 и го прави три пъти, като прави около 48 реда.
Но действителното четене на редове не е за броя на действително прочетените редове, а за броя на редовете, върнати от предиката за търсене, които се тестват спрямо остатъчния предикат. И при това само 2-та реда се намират от 3-те търсения.
Може би си мислите в този момент, че тук има известна доза неефективност. Второто търсене също щеше да прочете страница 712, да провери същите 6 или 7 реда там и след това да прочете страница 1004 и да я преследва... както и третото търсене.
Така че може би би било по-добре да получите това с едно търсене, като прочетете страница 712 и страница 1004 само по веднъж. В крайна сметка, ако правех това с хартиена система, щях да направя търсене да намеря клиент 783 и след това да сканирам всичките им типове адреси. Защото знам, че клиентът не е склонен да има много адреси. Това е предимство, което имам пред двигателя на базата данни. Машината на базата данни знае чрез своите статистически данни, че търсенето ще бъде най-добро, но не знае, че търсенето трябва да се спусне само с едно ниво, когато може да каже, че има това, което изглежда като идеалния индекс.
Ако променя заявката си, за да взема набор от типове адреси, от 2 до 5, тогава получавам почти желаното от мен поведение:
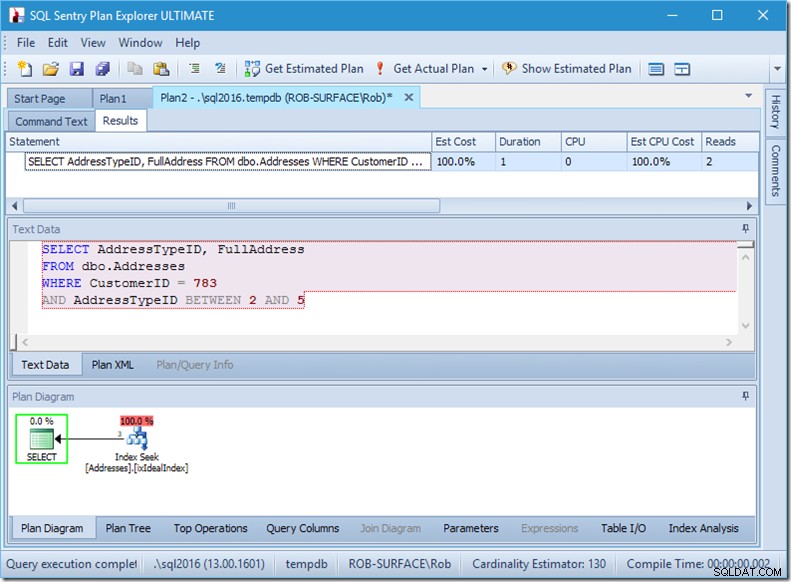
Вижте – показанията са до 2 и знам кои страници са…
...но резултатите ми са грешни. Защото искам само типове адреси 2, 4 и 5, а не 3. Трябва да му кажа да няма 3, но трябва да внимавам как правя това. Вижте следващите два примера.
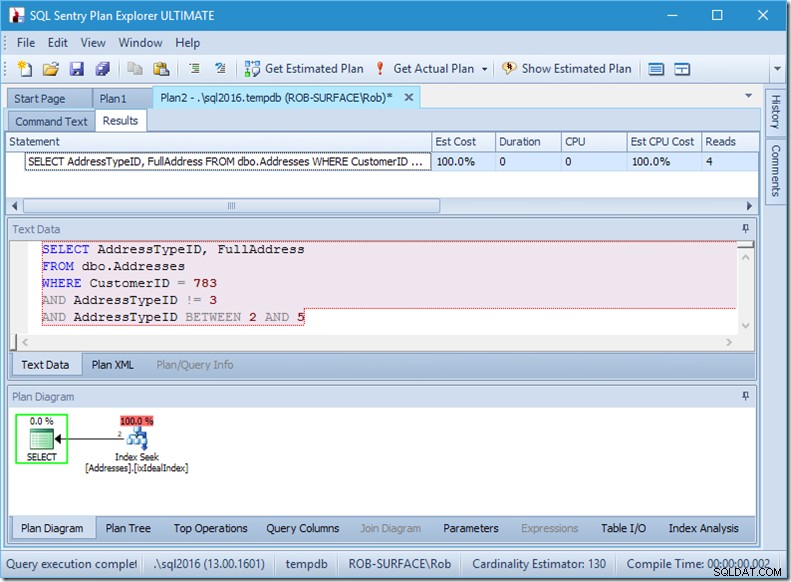
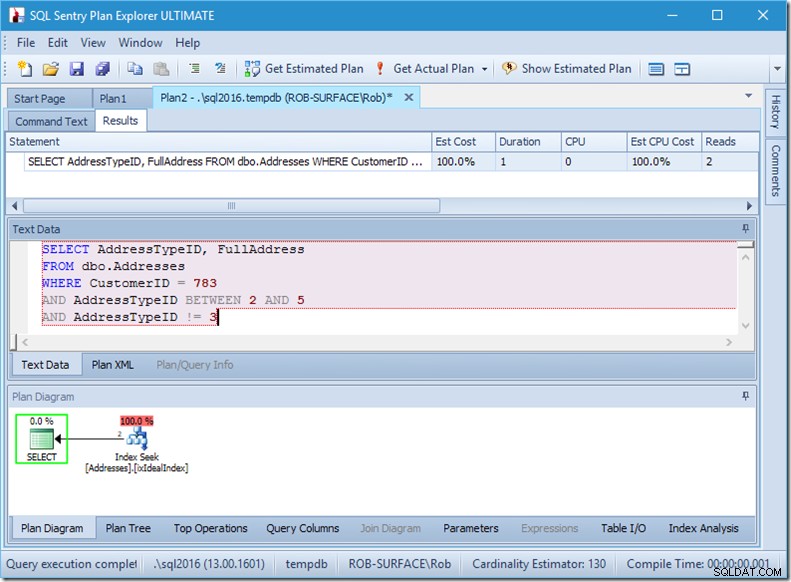
Мога да ви уверя, че редът на предикатите няма значение, но тук очевидно има значение. Ако поставим „не 3“ първо, той прави две търсения (4 четения), но ако поставим „не 3“ на второ място, той прави едно търсене (2 четения).
Проблемът е, че AddressTypeID !=3 се преобразува в (AddressTypeID> 3 ИЛИ AddressTypeID <3), което след това се разглежда като два много полезни предиката за търсене.
И затова предпочитам да използвам предикат, който не може да се саргира, за да му кажа, че искам само типове адреси 2, 4 и 5. И мога да направя това, като променя AddressTypeID по някакъв начин, като добавяне на нула към него.
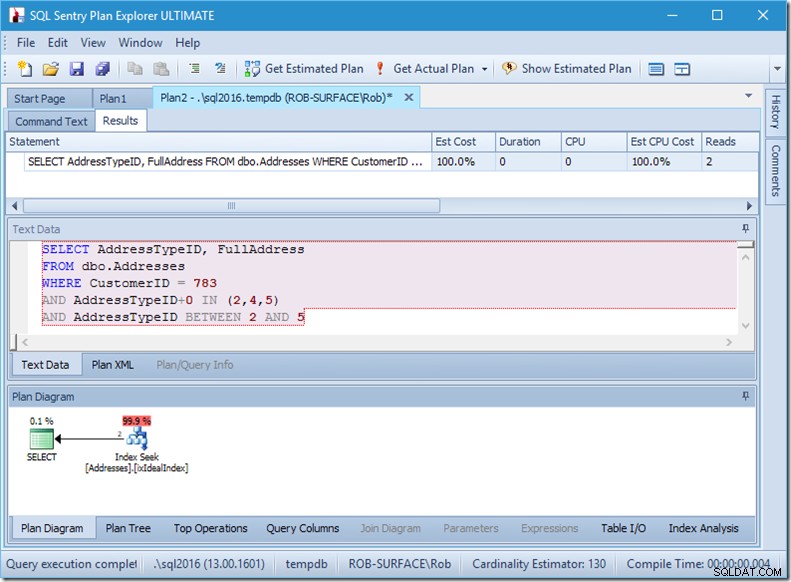
Сега имам хубаво и тесен обхват сканиране в рамките на едно търсене и все още се уверявам, че заявката ми връща само редовете, които искам.
О, но това свойство Actual Rows Read? Това вече е по-високо от свойството Actual Rows, защото предикатът за търсене намира адрес тип 3, който остатъчният предикат отхвърля.
Замених три перфектни търсения за едно несъвършено търсене, което коригирам с остатъчен предикат.
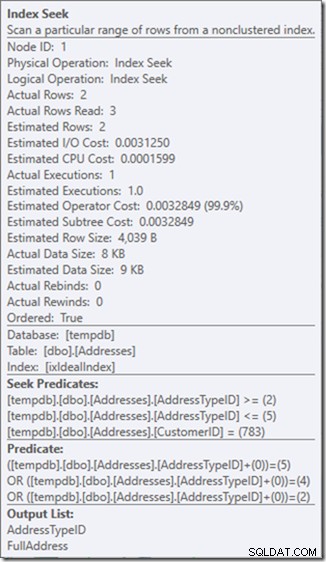
И за мен понякога това е цена, която си струва да платя, като ми дадете план за заявка, от който съм много по-доволен. Не е значително по-евтино, въпреки че има само една трета от показанията (защото винаги ще има само две физически четения), но когато си помисля за работата, която върши, се чувствам много по-удобен с това, което го питам да направите по този начин.