От време на време виждам някой да изразява изискване да създаде произволно число за ключ. Обикновено това е за създаване на някакъв тип сурогатен идентификатор на клиента или потребителски идентификатор, който е уникален номер в определен диапазон, но не се издава последователно и следователно е много по-малко предполагаем от IDENTITY стойност.
NEWID() решава проблема с отгатването, но намаляването на производителността обикновено е пречка, особено когато са групирани:много по-широки ключове от цели числа и разделяне на страници поради непоследователни стойности. NEWSEQUENTIALID() решава проблема с разделянето на страници, но все още е много широк ключ и въвежда отново проблема, че можете да отгатнете следващата стойност (или наскоро издадени стойности) с известно ниво на точност.
В резултат на това те искат техника за генериране на произволен и уникално цяло число. Генерирането на произволно число самостоятелно не е трудно, като се използват методи като RAND() или CHECKSUM(NEWID()) . Проблемът идва, когато трябва да откриете сблъсъци. Нека да разгледаме набързо един типичен подход, като приемем, че искаме стойности на CustomerID между 1 и 1 000 000:
DECLARE @rc INT =0, @CustomerID INT =ABS(КОНТРОЛНА СУМА(НОВИД())) % 1000000 + 1; -- или ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1; -- или CONVERT(INT, RAND() * 1000000) + 1; ДОКАТО @rc =0BEGIN, АКО НЕ СЪЩЕСТВУВА (ИЗБЕРЕТЕ 1 ОТ dbo.Customers КЪДЕТО CustomerID =@CustomerID) ЗАПОЧНЕТЕ ВМЪКВАНЕ НА dbo.Customers(CustomerID) SELECT @CustomerID SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(КОНТРОЛНА СУМА(НОВИД())) % 1000000 + 1, @rc =0; КРАЙ.
Тъй като таблицата става по-голяма, не само проверката за дубликати става по-скъпа, но и шансовете ви за генериране на дубликат се увеличават. Така че този подход може да изглежда да работи добре, когато масата е малка, но подозирам, че с времето трябва да боли все повече и повече.
Различен подход
Аз съм голям фен на помощните маси; Пиша публично за календарни таблици и таблици с числа от десетилетие и ги използвам много по-дълго. И това е случай, в който мисля, че предварително попълнената таблица може да бъде много полезна. Защо да разчитате на генериране на произволни числа по време на изпълнение и справяне с потенциални дубликати, когато можете да попълните всички тези стойности предварително и знаете – със 100% сигурност, ако защитавате таблиците си от неоторизиран DML – че следващата избрана от вас стойност никога не е била използван преди?
CREATE TABLE dbo.RandomNumbers1( RowID INT, Value INT, --UNIQUE, PRIMARY KEY (RowID, Value));;WITH x AS ( SELECT TOP (1000000) s1.[object_id] FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id])INSERT dbo.RandomNumbers(RowID, Value)ROW_NUMBER(ROW_SELECT r(object_id) ) НАД (ПОРЪЧКА ПО [обект_идентификатор]), n =ROW_NUMBER() НАД (ПОРЪЧКА ПО NEWID())ОТ xORDER BY r;
Създаването на тази популация отне 9 секунди (във VM на лаптоп) и заема около 17 MB на диска. Данните в таблицата изглеждат така:
(Ако се притеснявахме как се попълват числата, бихме могли да добавим уникално ограничение към колоната Стойност, което ще направи таблицата 30 MB. Ако приложихме компресия на страница, тя щеше да бъде съответно 11 MB или 25 MB. )
Създадох друго копие на таблицата и го попълних със същите стойности, за да мога да тествам два различни метода за извличане на следващата стойност:
CREATE TABLE dbo.RandomNumbers2( RowID INT, Value INT, -- УНИКАЛЕН ПЪРВИЧЕН КЛЮЧ (RowID, Value)); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Сега, всеки път, когато искаме ново произволно число, можем просто да извадим едно от купчината съществуващи числа и да го изтрием. Това ни предпазва от безпокойство за дубликати и ни позволява да изтегляме числа – с помощта на клъстериран индекс – които всъщност вече са в произволен ред. (Строго погледнато, не е нужно да изтриваме числата, както ги използваме; бихме могли да добавим колона, за да посочим дали дадена стойност е била използвана – това би улеснило възстановяването и повторното използване на тази стойност, в случай че клиент по-късно бъде изтрит или нещо се обърка извън тази транзакция, но преди да бъдат напълно създадени.)
DECLARE @holding TABLE(CustomerID INT); DELETE TOP (1) dbo.RandomNumbers1OUTPUT deleted.Value INTO @holding; INSERT dbo.Customers(CustomerID, ...други колони...) SELECT CustomerID, ...други параметри... FROM @holding;
Използвах променлива на таблица, за да задържа междинния изход, тъй като има различни ограничения с композируемия DML, които могат да направят невъзможно вмъкването в таблицата на клиентите директно от DELETE (например наличието на външни ключове). Все пак, признавайки, че това не винаги ще бъде възможно, аз също исках да тествам този метод:
DELETE TOP (1) dbo.RandomNumbers2 ИЗХОД е изтрит.Стойност, ...други параметри... INTO dbo.Customers(CustomerID, ...други колони...);
Имайте предвид, че нито едно от тези решения наистина не гарантира произволен ред, особено ако таблицата с произволни числа има други индекси (като уникален индекс в колоната Стойност). Няма начин да се дефинира поръчка за DELETE използвайки TOP; от документацията:
Така че, ако искате да гарантирате произволно подреждане, вместо това можете да направите нещо подобно:
DECLARE @holding TABLE(CustomerID INT);;С x AS ( SELECT TOP (1) Value FROM dbo.RandomNumbers2 ORDER BY RowID)DELETE x OUTPUT deleted.Value INTO @holding; INSERT dbo.Customers(CustomerID, ...други колони...) SELECT CustomerID, ...други параметри... FROM @holding;
Друго съображение тук е, че за тези тестове таблиците Customers имат клъстериран първичен ключ в колоната CustomerID; това със сигурност ще доведе до разделяне на страници, докато вмъквате произволни стойности. В реалния свят, ако имахте това изискване, вероятно щяхте да се класирате в друга колона.
Имайте предвид, че тук също съм пропуснал транзакциите и обработката на грешки, но те също трябва да бъдат съображения за производствения код.
Тестване на производителността
За да направя някои реалистични сравнения на производителността, създадох пет съхранени процедури, представящи следните сценарии (скорост на тестване, разпределение и честота на сблъсък на различните произволни методи, както и скоростта на използване на предварително дефинирана таблица с произволни числа):
- Генериране по време на изпълнение с помощта на
CHECKSUM(NEWID()) - Генериране по време на изпълнение с помощта на
CRYPT_GEN_RANDOM() - Генериране по време на изпълнение с помощта на
RAND() - Таблица с предварително дефинирани числа с променлива на таблица
- Таблица с предварително дефинирани числа с директно вмъкване
Те използват таблица за регистриране за проследяване на продължителността и броя на сблъсъците:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.CustomerLog( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, колизии INT, продължителност INT -- микросекунди);
Кодът за процедурите следва (щракнете, за да покажете/скриете):
/* Време на изпълнение с помощта на CHECKSUM(NEWID()) */ СЪЗДАВАНЕ НА ПРОЦЕДУРА [dbo].[AddCustomer_Runtime_Checksum]КАКТО ЗАСТАНЕТЕ NOCOUNT ON; ДЕКЛАРИРАНЕ @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(КОНТРОЛНА СУМА(НОВИД())) % 1000000 + 1, @collisions INT =0, @rc INT =0; ДОКАТО @rc =0 ЗАПОЧНЕТЕ, АКО НЕ СЪЩЕСТВУВА (ИЗБЕРЕТЕ 1 ОТ dbo.Customers_Runtime_Checksum, КЪДЕТО ИД на клиента =@CustomerID) ЗАПОЧНЕТЕ ВМЪКВАНЕ НА dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(КОНТРОЛНА СУМА(НОВИД())) % 1000000 + 1, @сблъсъци +=1, @rc =0; END END SELECT @duration =DATEDIFF(МИКРОСЕКУНДА, @начало, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, колизии, продължителност) SELECT 1, @collisions, @duration;ENDGO /* време на изпълнение с помощта на CRYPT_GEN_RANDOM() */ СЪЗДАВАНЕ НА ПРОЦЕДУРА [dbo].[AddCustomer_Runtime_CryptGen]КАКТО ЗАСТАНЕТЕ NOCOUNT ON; ДЕКЛАРИРАНЕ @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @сблъсъци INT =0, @rc INT =0; ДОКАТО @rc =0 ЗАПОЧНЕТЕ, АКО НЕ СЪЩЕСТВУВА (ИЗБЕРЕТЕ 1 ОТ dbo.Customers_Runtime_CryptGen КЪДЕТО CustomerID =@CustomerID) ЗАПОЧНЕТЕ ВМЕСТЕТЕ dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @сблъсъци +=1, @rc =0; END END SELECT @duration =DATEDIFF(МИКРОСЕКУНДА, @начало, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, сблъсъци, продължителност) SELECT 2, @collisions, @duration;ENDGO /* време на изпълнение с помощта на RAND() */ СЪЗДАВАНЕ НА ПРОЦЕДУРА [dbo].[AddCustomer_Runtime_Rand]КАКТО ЗАСТАНЕТЕ NOCOUNT ON; ДЕКЛАРИРАНЕ @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =CONVERT(INT, RAND() * 1000000) + 1, @сблъсъци INT =0, @rc INT =0; ДОКАТО @rc =0 ЗАПОЧНЕТЕ, АКО НЕ СЪЩЕСТВУВА ( ИЗБЕРЕТЕ 1 ОТ dbo.Customers_Runtime_Rand, КЪДЕ ИД на клиента =@CustomerID ) ЗАПОЧНЕТЕ ВЪВЕТЕ dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =CONVERT(INT, RAND() * 1000000) + 1, @сблъсъци +=1, @rc =0; END END SELECT @duration =DATEDIFF(МИКРОСЕКУНДА, @начало, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, сблъсъци, продължителност) SELECT 3, @collisions, @duration;ENDGO /* предварително дефиниран с помощта на променлива на таблица */ СЪЗДАВАНЕ НА ПРОЦЕДУРА [dbo].[AddCustomer_Predefined_TableVariable]ASBEGIN SET NOCOUNT ON; ДЕКЛАРИРАНЕ @start DATETIME2(7) =SYSDATETIME(), @duration INT; ДЕКЛАРИРАНЕ @придържане TABLE(CustomerID INT); DELETE TOP (1) dbo.RandomNumbers1 OUTPUT deleted.Value INTO @holding; INSERT dbo.Customers_Predefined_TableVariable(CustomerID) SELECT CustomerID FROM @holding; ИЗБЕРЕТЕ @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;ENDGO /* предварително дефинирано с помощта на директно вмъкване */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]ASBEGIN SET NOCOUNT ON; ДЕКЛАРИРАНЕ @start DATETIME2(7) =SYSDATETIME(), @duration INT; DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct; ИЗБЕРЕТЕ @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;ENDGO
И за да тествам това, бих стартирал всяка съхранена процедура 1 000 000 пъти:
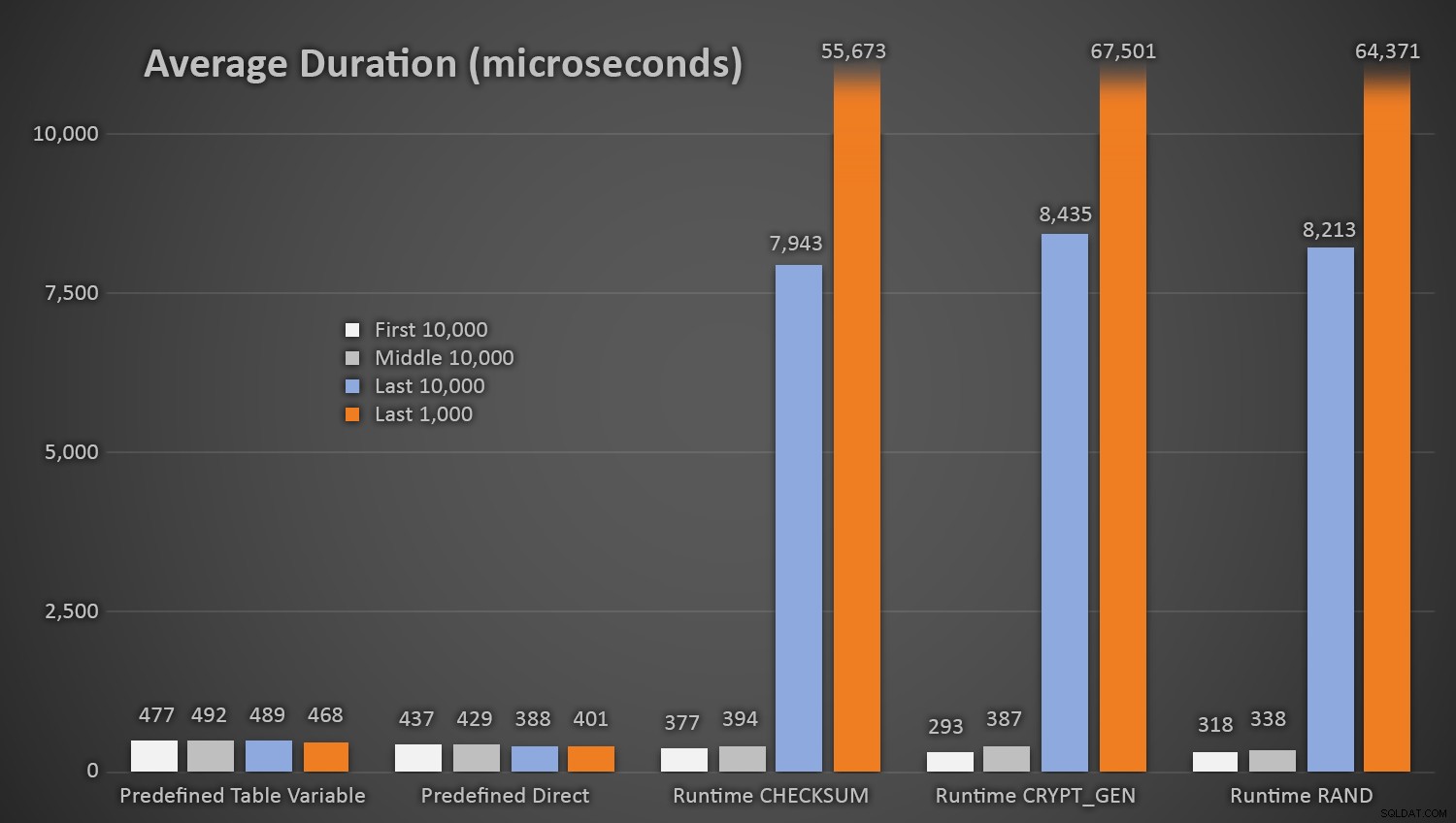
EXEC dbo.AddCustomer_Runtime_Checksum;EXEC dbo.AddCustomer_Runtime_CryptGen;EXEC dbo.AddCustomer_Runtime_Rand;EXEC dbo.AddCustomer_Predefined_TableVariable;EXEC dbo.AddCustomer_Runtime_CryptGen;EXEC dbo.AddCustomer_Runtime_Rand;EXEC dbo.AddCustomer_Predefined_TableVariable;EXEC dbo.Add00000000000000000000000Не е изненадващо, че методите, използващи предварително дефинираната таблица от произволни числа, отнеха малко повече време *в началото на теста*, тъй като трябваше да извършват както четене, така и записване на I/O всеки път. Имайки предвид, че тези числа са в микросекунди , ето средната продължителност за всяка процедура на различни интервали по пътя (средно за първите 10 000 екзекуции, средните 10 000 екзекуции, последните 10 000 екзекуции и последните 1000 екзекуции):
Средна продължителност (в микросекунди) на произволно генериране при използване на различни подходиТова работи добре за всички методи, когато има няколко реда в таблицата с клиенти, но тъй като таблицата става все по-голяма и по-голяма, разходите за проверка на новото произволно число спрямо съществуващите данни с помощта на методите за изпълнение се увеличават значително, както поради увеличеното I /O, а също и защото броят на сблъсъците се увеличава (принуждава ви да опитате и опитате отново). Сравнете средната продължителност, когато е в следните диапазони на броя на сблъсъците (и не забравяйте, че този модел засяга само методите по време на изпълнение):
Средна продължителност (в микросекунди) по време на различни диапазони на сблъсъциИска ми се да има прост начин за графика на продължителността спрямо броя на сблъсъците. Ще ви оставя с този лакомство:при последните три вмъквания, следните методи за изпълнение трябваше да извършат толкова много опити, преди най-накрая да се натъкнат на последния уникален идентификационен номер, който търсеха, и това е колко време отне:
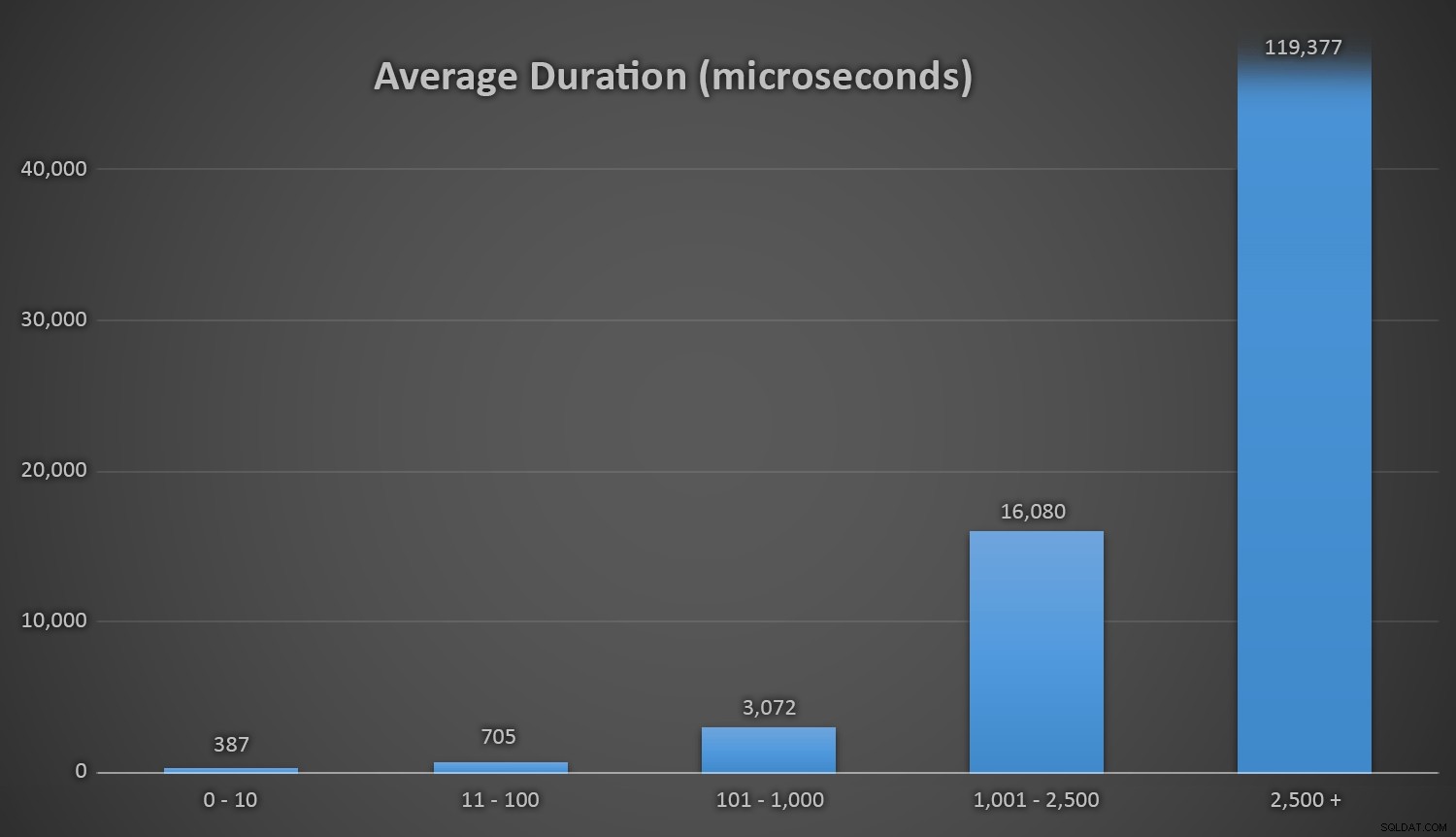
| Брой сблъсъци | Продължителност (микросекунди) | ||
|---|---|---|---|
| КОНТРОЛНА СУМА(НОВИД()) | от 3-ти до последен ред | 63 545 | 639 358 |
| 2-ри до последен ред | 164 807 | 1 605 695 | |
| Последен ред | 30 630 | 296 207 | |
| CRYPT_GEN_RANDOM() | от 3-ти до последен ред | 219 766 | 2 229 166 |
| 2-ри до последен ред | 255 463 | 2 681 468 | |
| Последен ред | 136 342 | 1 434 725 | |
| RAND() | от 3-ти до последен ред | 129 764 | 1 215 994 |
| 2-ри до последен ред | 220 195 | 2 088 992 | |
| Последен ред | 440 765 | 4 161 925 | |
Прекомерна продължителност и сблъсъци близо до края на реда
Интересно е да се отбележи, че последният ред не винаги е този, който дава най-голям брой сблъсъци, така че това може да започне да бъде истински проблем много преди да сте изразходили 999 000+ стойности.
Друго съображение
Може да помислите за настройване на някакъв вид предупреждение или известие, когато таблицата RandomNumbers започне да пада под определен брой редове (в този момент можете да попълните отново таблицата с нов набор от 1 000 001 – 2 000 000, например). Ще трябва да направите нещо подобно, ако генерирате произволни числа в движение – ако поддържате това в диапазон от 1 – 1 000 000, тогава ще трябва да промените кода, за да генерирате числа от различен диапазон, след като използвах всички тези стойности.
Ако използвате метода на произволно число по време на изпълнение, тогава можете да избегнете тази ситуация, като постоянно променяте размера на пула, от който извличате произволно число (което също трябва да се стабилизира и драстично да намали броя на сблъсъците). Например вместо:
ДЕКЛАРИРАНЕ @CustomerID INT =ABS(КОНТРОЛНА СУМА(НОВИД())) % 1000000 + 1;
Можете да базирате пула на броя на редовете, които вече са в таблицата:
DECLARE @total INT =1000000 + ISNULL( (ИЗБЕРЕТЕ SUM(row_count) FROM sys.dm_db_partition_stats WHERE [object_id] =OBJECT_ID('dbo.Customers') И index_id =1),0);
Сега единственото ви истинско притеснение е, когато се приближите до горната граница за INT …
Забележка:Наскоро написах и съвет за това на MSSQLTips.com.