Проста дефиниция на медианата е:
Медианата е средната стойност в сортиран списък с числаЗа да уточним това малко, можем да намерим медианата на списък с числа, като използваме следната процедура:
- Сортирайте числата (във възходящ или низходящ ред, няма значение кои).
- Средното число (по позиция) в сортирания списък е медианата.
- Ако има две „равно средни“ числа, медианата е средната стойност на двете средни стойности.
Aaron Bertrand преди това е тествал няколко начина за изчисляване на медианата в SQL Server:
- Кой е най-бързият начин за изчисляване на медианата?
- Най-добри подходи за групирана медиана
Роб Фарли наскоро добави друг подход, насочен към инсталации преди 2012 г.:
- Медиани преди SQL 2012
Тази статия представя нов метод, използващ динамичен курсор.
Методът OFFSET-FETCH от 2012 г.
Ще започнем с разглеждане на най-ефективното изпълнение, създадено от Питър Ларсон. Той използва SQL Server 2012 OFFSET разширение към ORDER BY клауза за ефективно намиране на един или два средни реда, необходими за изчисляване на медианата.
ИЗМЕСТВАНЕ Единична медиана
Първата статия на Аарон тества изчисляването на една медиана върху таблица от десет милиона редове:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Решението на Питър Ларсон с помощта на OFFSET разширението е:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Кодът по-горе твърдо кодира резултата от преброяването на редовете в таблицата. Всички тествани методи за изчисляване на медианата се нуждаят от този брой, за да се изчислят средните номера на редовете, така че това е постоянна цена. Оставянето на операцията за броене на редове извън времето избягва един възможен източник на вариации.
Планът за изпълнение на OFFSET решението е показано по-долу:

Операторът Top бързо прескача ненужните редове, като предава само един или два реда, необходими за изчисляване на медианата на Stream Aggregate. Когато се изпълнява с топъл кеш и изключено събиране на планове за изпълнение, тази заявка се изпълнява за 910 ms средно на моя лаптоп. Това е машина с процесор Intel i7 740QM, работещ на 1,73 GHz с деактивирано Turbo (за последователност).
ОТМЕСТВА Групирана медиана
Втората статия на Аарон тества ефективността на изчисляване на медиана за група, като се използва таблица за продажби от милион реда с десет хиляди вписвания за всеки от сто продавачи:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Отново, най-ефективното решение използва OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Важната част от плана за изпълнение е показана по-долу:

Най-горният ред на плана е свързан с намирането на броя на груповите редове за всеки продавач. Долният ред използва същите елементи на плана, които се виждат за едногруповото медианно решение, за да се изчисли медианата за всеки търговец. Когато се изпълнява с топъл кеш и изключени планове за изпълнение, тази заявка се изпълнява за 320 ms средно на моя лаптоп.
Използване на динамичен курсор
Може да изглежда лудо дори да се мисли за използване на курсор за изчисляване на медианата. Transact SQL курсорите имат (предимно заслужена) репутация на бавни и неефективни. Също така често се смята, че динамичните курсори са най-лошият тип курсор. Тези точки са валидни при някои обстоятелства, но не винаги.
Transact SQL курсорите са ограничени до обработка на един ред в даден момент, така че те наистина могат да бъдат бавни, ако много редове трябва да бъдат извлечени и обработени. Това обаче не е така за медианното изчисление:всичко, което трябва да направим, е да намерим и извлечем една или две средни стойности ефективно . Динамичният курсор е много подходящ за тази задача, както ще видим.
Единичен среден динамичен курсор
Решението за динамичен курсор за едно изчисление на медиана се състои от следните стъпки:
- Създайте динамичен курсор с възможност за превъртане върху подредения списък с елементи.
- Изчислете позицията на първия среден ред.
- Преместете курсора, като използвате
FETCH RELATIVE. - Решете дали е необходим втори ред за изчисляване на медианата.
- Ако не, върнете незабавно единичната средна стойност.
- В противен случай извлечете втората стойност с помощта на
FETCH NEXT. - Изчислете средната стойност на двете стойности и върнете.
Забележете колко точно този списък отразява простата процедура за намиране на медианата, дадена в началото на тази статия. Пълна реализация на Transact SQL код е показана по-долу:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
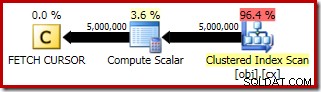
Планът за изпълнение на FETCH RELATIVE операторът показва динамичния курсор, който ефективно се препозиционира към първия ред, необходим за изчислението на медиана:
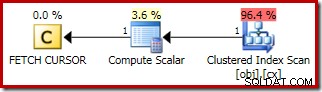
Планът за FETCH NEXT (изисква се само ако има втори среден ред, както в тези тестове) е извличане на един ред от запазената позиция на курсора:
Предимствата от използването на динамичен курсор тук са:
- Избягва преминаването на целия набор (четенето спира след намиране на средните редове); и
- В tempdb не се прави временно копие на данните , както би било за статичен курсор или курсор с набор от клавиши.
Обърнете внимание, че не можем да посочим FAST_FORWARD курсора тук (оставяйки избора на статичен или динамичен план на оптимизатора), защото курсорът трябва да може да се превърта, за да поддържа FETCH RELATIVE . Dynamic е оптималният избор тук така или иначе.
Когато се изпълнява с топъл кеш и изключено събиране на планове за изпълнение, тази заявка се изпълнява за 930 ms средно на моята тестова машина. Това е малко по-бавно от 910 ms за OFFSET решение, но динамичният курсор е значително по-бърз от другите методи, тествани от Аарон и Роб, и не изисква SQL Server 2012 (или по-нова версия).
Тук няма да повтарям тестването на другите методи преди 2012 г., но като пример за размера на разликата в производителността, следното решение за номериране на редове отнема 1550 ms средно (70% по-бавно):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Групиран среден динамичен тест на курсора
Лесно е да се разшири решението за единичен среден динамичен курсор, за да се изчислят групирани медиани. За последователност ще използвам вложени курсори (да, наистина):
- Отворете статичен курсор върху продавачите и броя на редовете.
- Изчислете медианата за всеки човек, като използвате нов динамичен курсор всеки път.
- Запазвайте всеки резултат в променлива на таблица, докато вървим.
Кодът е показан по-долу:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Външният курсор е умишлено статичен, тъй като всички редове в този набор ще бъдат докоснати (също не е наличен динамичен курсор поради операцията за групиране в основната заявка). Този път няма нищо особено ново или интересно да се види в плановете за изпълнение.
Интересното е изпълнението. Въпреки многократното създаване и освобождаване на вътрешния динамичен курсор, това решение се представя много добре върху набора от тестови данни. С изключен топъл кеш и планове за изпълнение, скриптът на курсора завършва за 330 ms средно на моята тестова машина. Това отново е малко по-бавно от 320 ms записано от OFFSET групирана медиана, но с голяма разлика надминава другите стандартни решения, изброени в статиите на Аарон и Роб.
Отново, като пример за разликата в производителността спрямо другите методи извън 2012 г., следното решение за номериране на редове работи за 485 ms средно на моя тестов стенд (50% по-лошо):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Резюме на резултатите
В единичния среден тест динамичният курсор работи за 930 ms срещу 910 ms за OFFSET метод.
В групирания среден тест вложеният курсор работи за 330 ms срещу 320 ms за OFFSET .
И в двата случая методът на курсора беше значително по-бърз от другия не-OFFSET методи. Ако трябва да изчислите единична или групирана медиана за екземпляр отпреди 2012 г., динамичен курсор или вложен курсор наистина може да бъде оптималният избор.
Ефективност на хладния кеш
Някои от вас може да се чудят за производителността на студения кеш. Изпълнявайте следното преди всеки тест:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Това са резултатите за единичния среден тест:
OFFSET метод:940 ms
Динамичен курсор:955 ms
За групираната медиана:
OFFSET метод:380 ms
Вложени курсори:385 ms
Последни мисли
Решенията за динамичен курсор наистина са значително по-бързи от не-OFFSET методи както за единични, така и за групирани медиани, поне с тези примерни набори от данни. Умишлено избрах да използвам повторно тестовите данни на Аарон, така че наборите от данни да не бяха умишлено изкривени към динамичния курсор. Има може да бъдат други разпределения на данни, за които динамичният курсор не е добра опция. Въпреки това показва, че все още има моменти, когато курсорът може да бъде бързо и ефективно решение на правилния вид проблем. Дори динамични и вложени курсори.
Читателите с орлови очи може да са забелязали PAGLOCK намек в OFFSET групиран среден тест. Това е необходимо за най-добра производителност, поради причини, които ще разгледам в следващата си статия. Без него решението от 2012 г. всъщност губи от вложения курсор с прилична разлика (590 мс срещу 330 мс ).