Има две допълващи се умения, които са много полезни при настройката на заявки. Едната е способността да се четат и тълкуват планове за изпълнение. Второто е да знаете малко за това как работи оптимизаторът на заявки, за да преведе SQL текст в план за изпълнение. Обединяването на двете неща може да ни помогне да открием моменти, когато очакваната оптимизация не е приложена, което води до план за изпълнение, който не е толкова ефективен, колкото би могъл да бъде. Липсата на документация за това кои точно оптимизации може да приложи SQL Server (и при какви обстоятелства) означава, че много от това се свежда до опит обаче.
Пример
Примерната заявка за тази статия се основава на въпрос, зададен от MVP на SQL Server Фабиано Аморим преди няколко месеца, въз основа на проблем от реалния свят, с който се е сблъскал. Схемата и тестовата заявка по-долу са опростяване на реалната ситуация, но запазва всички важни характеристики.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Тест 1 – 10 000 реда, SQL Server 2005+
Конкретните данни от таблицата не са от значение за тези тестове. Следните заявки просто зареждат 10 000 реда от таблица с числа във всяка от трите тестови таблици:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
С заредените данни планът за изпълнение, създаден за тестовата заявка, е:
SELECT MAX(c1) FROM dbo.V1;
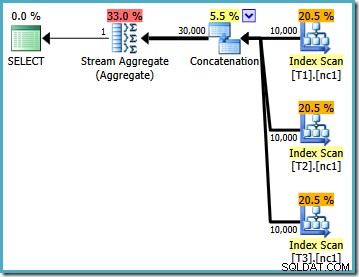
Този план за изпълнение е доста директно изпълнение на логическата SQL заявка (след като референтният изглед V1 е разширен). Оптимизаторът вижда заявката след разширяване на изгледа, почти сякаш заявката е била написана изцяло:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
Сравнявайки разширения текст с плана за изпълнение, директността на реализацията на оптимизатора на заявки е ясна. Има индексно сканиране за всяко четене на базовите таблици, оператор за конкатенация за прилагане на UNION ALL , и Stream Aggregate за крайния MAX съвкупност.
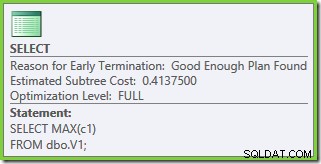
Свойствата на плана за изпълнение показват, че е стартирана оптимизация на базата на разходи (нивото на оптимизация е FULL ), но че е прекратено рано, защото е намерен „достатъчно добър“ план. Прогнозната цена на избрания план е 0,1016240 магически модули за оптимизиране.
Тест 2 – 50 000 реда, SQL Server 2008 и 2008 R2
Изпълнете следния скрипт, за да нулирате тестовата среда да работи с 50 000 реда:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
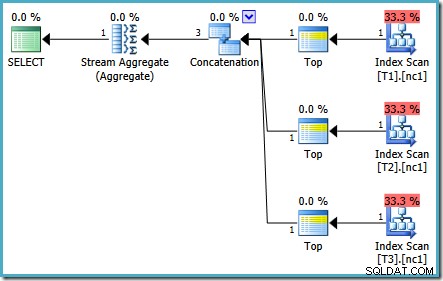
Планът за изпълнение на този тест зависи от версията на SQL Server, която използвате. В SQL Server 2008 и 2008 R2 получаваме следния план:
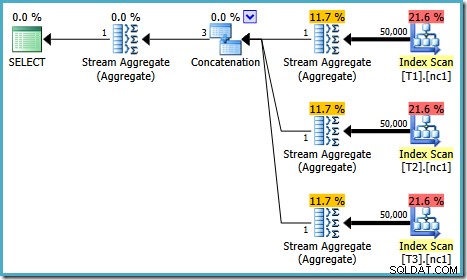
Свойствата на плана показват, че оптимизацията, базирана на разходите, все още е приключила по-рано поради същата причина, както преди. Прогнозната цена е по-висока от преди на 0,41375 единици, но това се очаква поради по-високата мощност на базовите таблици.
Тест 3 – 50 000 реда, SQL Server 2005 и 2012
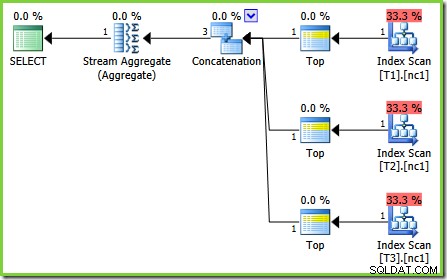
Същата заявка, изпълнена през 2005 или 2012 г., произвежда различен план за изпълнение:
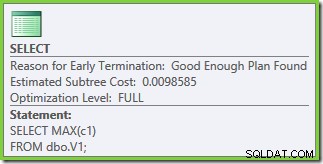
Оптимизацията отново приключи рано, но прогнозната цена на плана за 50 000 реда на основна таблица е до 0,0098585 (от 0,41375 на SQL Server 2008 и 2008 R2).
Обяснение
Както може би знаете, оптимизаторът на заявки на SQL Server разделя усилията за оптимизация на няколко етапа, като по-късните етапи добавят повече техники за оптимизация и позволяват повече време. Етапите на оптимизация са:
- Тривиален план
- Оптимизация на базата на разходи
- Обработка на транзакции (търсене 0)
- Бърз план (търсене 1)
- Бърз план с активиран паралелизъм
- Пълна оптимизация (търсене 2)
Нито един от тестовете, извършени тук, не отговаря на изискванията за тривиален план, тъй като агрегатът и съюзите имат множество възможности за изпълнение, което изисква решение, основано на разходите.
Обработка на транзакции
Етапът на обработка на транзакции (TP) изисква заявката да съдържа поне три препратки към таблици, в противен случай оптимизацията, базирана на разходите, пропуска този етап и преминава директно към бърз план. Етапът TP е насочен към евтините навигационни заявки, типични за OLTP работните натоварвания. Той изпробва ограничен брой техники за оптимизация и е ограничен до намиране на планове с вложени връзки (освен ако не е необходимо хеш присъединяване за генериране на валиден план).
В някои отношения е изненадващо, че тестовата заявка отговаря на изискванията за етап, насочен към намиране на OLTP планове. Въпреки че заявката съдържа необходимите три препратки към таблици, тя не съдържа никакви присъединявания. Изискването за три таблици е просто евристика, така че няма да се затруднявам.
Кои етапи на оптимизатора бяха изпълнени?
Има редица методи, като документираният е за сравняване на съдържанието на sys.dm_exec_query_optimizer_info преди и след компилацията. Това е добре, но записва информация за целия екземпляр, така че трябва да внимавате, че вашата е единствената компилация на заявка, която се случва между моментните снимки.
Недокументирана (но сравнително добре позната) алтернатива, която работи на всички поддържани в момента версии на SQL Server, е да активирате флагове за проследяване 8675 и 3604, докато компилирате заявката.
Тест 1
Този тест произвежда флаг за проследяване 8675, подобен на следния:

Прогнозната цена от 0,101624 след етапа TP е достатъчно ниска, че оптимизаторът да не търси по-евтини планове. Простият план, който в крайна сметка получаваме, е доста разумен предвид относително ниската мощност на базовите таблици, дори и да не е наистина оптимален.
Тест 2
С 50 000 реда във всяка основна таблица, флагът за проследяване разкрива различна информация:

Този път прогнозната цена след етапа TP е 0,428735 (повече редове =по-висока цена). Това е достатъчно, за да насърчи оптимизатора в етапа на бърз план. С повече налични техники за оптимизация, този етап намира план с цена от 0,41375 . Това не представлява голямо подобрение спрямо плана за тест 1, но е по-ниско от прага на разходите по подразбиране за паралелизъм и не е достатъчно, за да влезете в пълна оптимизация, така че отново оптимизацията приключва по-рано.
Тест 3
За изпълнението на SQL Server 2005 и 2012 изходният флаг за проследяване е:

Има малки разлики в броя на задачите, изпълнявани между версиите, но важната разлика е, че на SQL Server 2005 и 2012, етапът на бърз план намира план, струващ само 0,0098543 единици. Това е планът, който съдържа Топ оператори вместо трите Stream Aggregate под оператора Concatenation, който се вижда в плановете за SQL Server 2008 и 2008 R2.
Бъгове и недокументирани поправки
SQL Server 2008 и 2008 R2 съдържат грешка в регресията (в сравнение с 2005 г.), която беше коригирана под флаг за проследяване 4199, но не е документирана, доколкото мога да преценя. Има документация за TF 4199, която изброява поправките, предоставени под отделни флагове за проследяване, преди да бъдат обхванати от 4199, но както се казва в тази статия от базата знания:
Този един флаг за проследяване може да се използва за активиране на всички корекции, направени преди това за процесора на заявки под много флагове за проследяване. Освен това, всички бъдещи корекции на процесора на заявки ще бъдат контролирани с помощта на този флаг за проследяване.
Грешката в този случай е една от онези „бъдещи корекции на процесора на заявки“. Конкретно правило за оптимизиране, ScalarGbAggToTop , не се прилага към новите агрегати, виждани в плана за тест 2. С активиран флаг за проследяване 4199 на подходящи компилации на SQL Server 2008 и 2008 R2, грешката е коригирана и се получава оптималният план от тест 3:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Заключение
След като знаете, че оптимизаторът може да трансформира скаларен MIN или MAX обобщете до TOP (1) на подреден поток, планът, показан в тест 2, изглежда странен. Скаларните агрегати над индексно сканиране (което може да осигури ред, ако бъде поискано да го направи) се открояват като пропусната оптимизация, която обикновено се прилага.
Това е идеята, която посочих във въведението:след като усетите какви неща може да направи оптимизаторът, той може да ви помогне да разпознаете случаите, когато нещо се е объркало.
Отговорът не винаги ще бъде да активирате флаг за проследяване 4199, тъй като може да срещнете проблеми, които все още не са отстранени. Може също да не искате другите корекции на QP, обхванати от флага за проследяване, да се прилагат в конкретен случай – корекциите на оптимизатора не винаги правят нещата по-добри. Ако го направиха, нямаше да има нужда да се защитава срещу злополучни регресии на плана с помощта на този флаг.
Решението в други случаи може да бъде да се формулира SQL заявката, използвайки различен синтаксис, да се разбие заявката на по-удобни за оптимизатор парчета или нещо съвсем друго. Какъвто и да се окаже отговорът, все пак си струва да знаете малко за вътрешните елементи на оптимизатора, за да можете да разпознаете, че е имало проблем на първо място :)