Въпреки че идват с много ограничения и някои важни предупреждения за внедряване, индексираните изгледи все още са много мощна функция на SQL Server, когато се използват правилно при правилните обстоятелства. Една често срещана употреба е предоставянето на предварително обобщен изглед на основните данни, като дава възможност на потребителите да правят заявки за резултатите директно, без да поемат разходи за обработка на основните обединения, филтри и агрегати всеки път, когато се изпълнява заявка.
Въпреки че новите функции на Enterprise Edition като колонно съхранение и обработка в пакетен режим са трансформирали характеристиките на производителността на много големи заявки от този тип, все още няма по-бърз начин да получите резултат от това да избегнете напълно цялата основна обработка, без значение колко е ефективна тази обработка може да е станало.
Преди индексираните изгледи (и техните по-ограничени братовчеди, изчислени колони) да бъдат добавени към продукта, специалистите по бази данни понякога написват сложен код с множество задействания, за да представят резултатите от важна заявка в реална таблица. Известно е, че този вид споразумение е трудно да се постигне правилно при всякакви обстоятелства, особено когато едновременните промени в основните данни са чести.
Функцията за индексирани изгледи прави всичко това много по-лесно, когато се прилага разумно и правилно. Машината на базата данни се грижи за всичко необходимо, за да гарантира, че данните, прочетени от индексиран изглед, съвпадат с основната заявка и данните от таблицата по всяко време.
Постепенна поддръжка
SQL Server поддържа индексираните данни за изглед синхронизирани с основната заявка, като автоматично актуализира индексите на изгледа по подходящ начин, когато данните се променят в базовите таблици. Разходите за тази дейност по поддръжката се поемат от процеса на промяна на базовите данни. Допълнителните операции, необходими за поддържане на индексите на изгледа, се добавят безшумно към плана за изпълнение за оригиналната операция за вмъкване, актуализиране, изтриване или сливане. На заден план SQL Server също така се грижи за по-фини проблеми, свързани с изолирането на транзакциите, например осигуряване на коректна обработка на транзакции, изпълнявани под моментна снимка или изолация за четене, ангажирана моментна снимка.
Създаването на допълнителни операции на план за изпълнение, необходими за правилното поддържане на индексите на изгледа, не е тривиален въпрос, както всеки, който е опитал реализация на "обобщена таблица, поддържана от код за задействане", ще знае. Сложността на задачата е една от причините индексираните изгледи да имат толкова много ограничения. Ограничаването на поддържаната повърхност до вътрешни съединения, проекции, селекции (филтри) и агрегатите SUM и COUNT_BIG намалява значително сложността на внедряването.
Индексираните изгледи се поддържат постепенно . Това означава, че процесорът на заявки определя нетния ефект от промените в основната таблица върху изгледа и прилага само онези промени, необходими за актуализиране на изгледа. В прости случаи той може да изчисли необходимите делти само от промените в основната таблица и данните, съхранявани в момента в изгледа. Когато дефиницията на изглед съдържа обединения, частта за поддръжка на индексирания изглед от плана за изпълнение също ще трябва да има достъп до обединените таблици, но това обикновено може да се извърши ефективно, като се имат предвид подходящи индекси на базовата таблица.
За да опрости допълнително внедряването, SQL Server винаги използва една и съща основна форма на план (като отправна точка) за прилагане на операции по поддръжка на индексиран изглед. Нормалните средства, предоставени от оптимизатора на заявки, се използват за опростяване и оптимизиране на стандартната форма за поддръжка, както е подходящо. Сега ще се обърнем към пример, за да помогнем за обединяването на тези понятия.
Пример 1 – Вмъкване на един ред
Да предположим, че имаме следната проста таблица и индексиран изглед:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); След като този скрипт се изпълни, данните в примерната таблица изглеждат така:

И индексираният изглед съдържа:

Най-простият пример за план за поддръжка на индексиран изглед за тази настройка се случва, когато добавим един ред към основната таблица:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); Планът за изпълнение на тази вложка е показан по-долу:
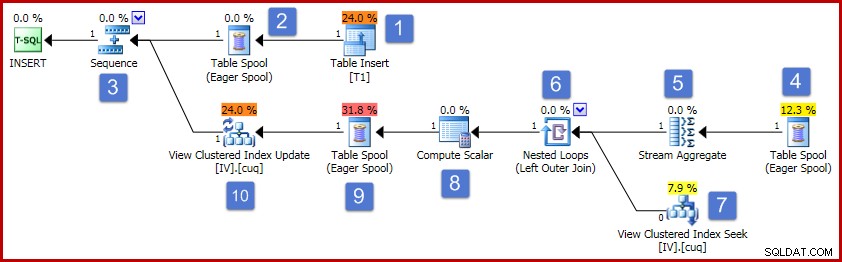
След числата в диаграмата, работата на този план за изпълнение протича по следния начин:
- Операторът вмъкване на таблица добавя новия ред към основната таблица. Това е единственият план оператор, свързан с вмъкването на основната таблица; всички останали оператори се грижат за поддържането на индексирания изглед.
- Eager Table Spool запазва вмъкнатите данни за ред във временно съхранение.
- Операторът последователност гарантира, че горният клон на плана работи до завършване, преди да бъде активиран следващият клон в последователността. В този специален случай (вмъкване на един ред) би било валидно да премахнете последователността (и макарите на позиции 2 и 4), директно свързвайки входа на Stream Aggregate с изхода на Table Insert. Тази възможна оптимизация не е приложена, така че последователността и спуловете остават.
- Тази Eager Table Spool е свързана с макарата на позиция 2 (тя има свойство за първичен идентификатор на възел, което предоставя тази връзка изрично). Шпулата възпроизвежда редове (един ред в настоящия случай) от същото временно хранилище, записано от първичната макара. Както бе споменато по-горе, макарите и позициите 2 и 4 са ненужни и се отличават просто защото съществуват в общия шаблон за поддръжка на индексиран изглед.
- Агрегатът на потока изчислява сумата от данните в колоната „Стойност“ във вмъкнатия набор и отчита броя на редовете, присъстващи на група ключове за изглед. Резултатът е инкременталните данни, необходими за поддържане на синхронизиране на изгледа с основните данни. Забележете, Stream Aggregate няма елемент Group By, тъй като оптимизаторът на заявки знае, че се обработва само една стойност. Въпреки това, оптимизаторът не прилага подобна логика, за да замени агрегатите с прогнози (сумата от една стойност е само самата стойност и броят винаги ще бъде един за вмъкване на един ред). Изчисляването на агрегатите за сума и брой за един ред данни не е скъпа операция, така че тази пропусната оптимизация не е много за притеснение.
- Обединението свързва всяка изчислена постепенна промяна със съществуващ ключ в индексирания изглед. Обединяването е външно, защото нововмъкнатите данни може да не съответстват на съществуващи данни в изгледа.
- Този оператор намира реда, който трябва да бъде променен в изгледа.
- Изчислителният скалар има две важни отговорности. Първо, той определя дали всяка постепенна промяна ще засегне съществуващ ред в изгледа или ще трябва да се създаде нов ред. Той прави това, като проверява дали външното съединение е произвело нула от страната на изгледа на съединението. Нашата примерна вложка е за група 3, която в момента не съществува в изгледа, така че ще бъде създаден нов ред. Втората функция на Compute Scalar е да изчислява нови стойности за колоните на изгледа. Ако към изгледа трябва да се добави нов ред, това е просто резултат от инкременталната сума от Stream Aggregate. Ако трябва да се актуализира съществуващ ред в изгледа, новата стойност е съществуващата стойност в реда на изгледа плюс инкременталната сума от агрегата на потока.
- Тази Eager Table Spool е за защита за Хелоуин. Изисква се за коректност, когато операция за вмъкване засяга таблица, която също е посочена от страната за достъп до данни на заявката. Технически не е необходимо, ако операцията по поддръжка на един ред доведе до актуализация на съществуващ ред за изглед, но така или иначе остава в плана.
- Окончателният оператор в плана е обозначен като оператор за актуализиране, но той ще извърши или вмъкване, или актуализиране за всеки ред, който получава, в зависимост от стойността на колоната „код на действие“, добавена от скалара за изчисляване на възел 8 По-общо казано, този оператор за актуализиране може да вмъква, актуализира и изтрива.
Там има доста подробности, така че да обобщим:
- Агрегираните групи данни се променят от уникалния клъстериран ключ на изгледа. Той изчислява нетния ефект от промените в основната таблица за всяка колона на ключ.
- Външното свързване свързва постепенните промени за всеки ключ със съществуващите редове в изгледа.
- Изчислителният скалар изчислява дали към изгледа трябва да се добави нов ред или да се актуализира съществуващ ред. Той изчислява крайните стойности на колоната за операцията вмъкване или актуализиране на изглед.
- Операторът за актуализиране на изглед вмъква нов ред или актуализира съществуващ, както е указано от кода за действие.
Пример 2 – Многоредово вмъкване
Вярвате или не, планът за изпълнение на вмъкване на базова таблица с един ред, обсъден по-горе, беше предмет на редица опростявания. Въпреки че някои възможни допълнителни оптимизации бяха пропуснати (както беше отбелязано), оптимизаторът на заявки все пак успя да премахне някои операции от общия шаблон за поддръжка на индексиран изглед и да намали сложността на други.
Няколко от тези оптимизации бяха разрешени, защото вмъквахме само един ред, но други бяха разрешени, защото оптимизаторът можеше да види буквалните стойности, които се добавят към основната таблица. Например, оптимизаторът може да види, че вмъкнатата стойност на групата ще предаде предиката в клаузата WHERE на изгледа.
Ако сега вмъкнем два реда, със стойностите "скрити" в локални променливи, получаваме малко по-сложен план:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
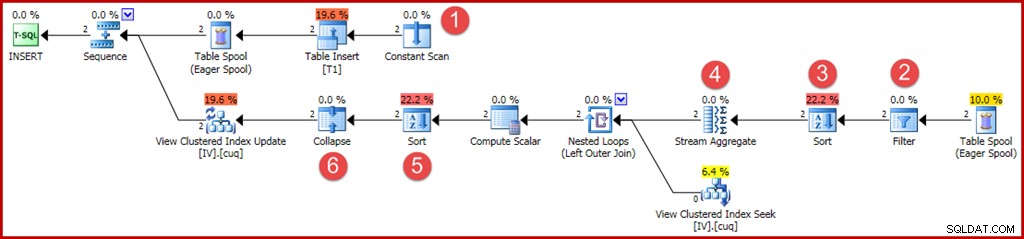
Новите или променените оператори са анотирани както преди:
- Постоянното сканиране предоставя стойностите за вмъкване. Преди това оптимизация за едноредови вмъквания позволяваше този оператор да бъде пропуснат.
- Сега се изисква изричен оператор за филтриране, за да се провери дали групите, вмъкнати в основната таблица, съответстват на клаузата WHERE в изгледа. Както се случва, и двата нови реда ще преминат теста, но оптимизаторът не може да види стойностите в променливите, за да знае това предварително. Освен това не би било безопасно да се кешира план, който е пропуснал този филтър, тъй като бъдещо повторно използване на плана може да има различни стойности в променливите.
- Сега се изисква сортиране, за да се гарантира, че редовете пристигат в агрегата на потока в групов ред. Сортирането беше премахнато преди това, защото е безсмислено да сортирате един ред.
- Агрегатът на потока вече има свойство „групиране по“, което съответства на уникалния клъстериран ключ на изгледа.
- Това сортиране е необходимо за представяне на редове в ключ за изглед, ред на код за действие, който е необходим за правилната работа на оператора за свиване. Сортирането е напълно блокиращ оператор, така че вече няма нужда от Eager Table Spool за защита на Хелоуин.
- Новият оператор за свиване комбинира съседно вмъкване и изтриване на същата ключова стойност в една операция за актуализиране. Този оператор всъщност не е задължителен в този случай, тъй като не могат да се генерират кодове за действие за изтриване (само вмъквания и актуализации). Изглежда, че това е пропуск или може би нещо останало от съображения за безопасност. Автоматично генерираните части от план за заявка за актуализиране могат да станат изключително сложни, така че е трудно да се знае със сигурност.
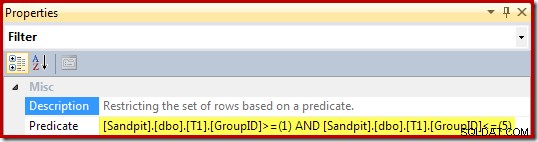
Свойствата на филтъра (извлечени от клаузата WHERE на изгледа) са:
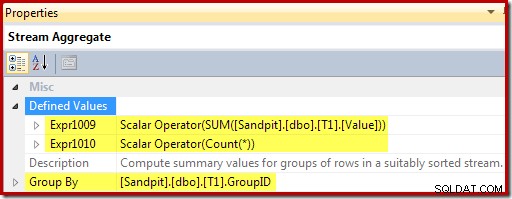
Stream Aggregate групира по ключа за изглед и изчислява сбора и брой агрегати за група:
Скаларът за изчисляване идентифицира действието, което трябва да се извърши на ред (вмъкване или актуализиране в този случай) и изчислява стойността за вмъкване или актуализиране в изгледа:
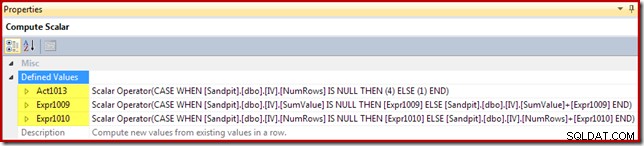
На кода за действие се дава етикет на израз [Act1xxx]. Валидни стойности са 1 за актуализация, 3 за изтриване и 4 за вмъкване. Този израз за действие води до вмъкване (код 4), ако не е намерен съвпадащ ред в изгледа (т.е. външното присъединяване върна нула за колоната NumRows). Ако е намерен съвпадащ ред, кодът за действие е 1 (актуализация).
Имайте предвид, че NumRows е името, дадено на необходимата колона COUNT_BIG(*) в изгледа. В план, който може да доведе до изтриване от изгледа, изчислителният скалар ще открие кога тази стойност ще стане нула (няма редове за текущата група) и ще генерира код за действие за изтриване (3).
Останалите изрази поддържат сбора и брой агрегати в изгледа. Забележете обаче, че етикетите на изразите [Expr1009] и [Expr1010] не са нови; те се отнасят до етикетите, създадени от Stream Aggregate. Логиката е ясна:ако не е намерен съвпадащ ред, новата стойност за вмъкване е само стойността, изчислена в агрегата. Ако е намерен съвпадащ ред в изгледа, актуализираната стойност е текущата стойност в реда плюс приращението, изчислено от агрегата.
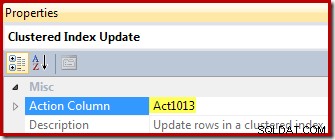
И накрая, операторът за актуализиране на изглед (показан като актуализация на клъстериран индекс в SSMS) показва препратката към колоната за действие ([Act1013], дефинирана от Compute Scalar):
Пример 3 – Актуализация на няколко реда
Досега разглеждахме само вложки към основната маса. Плановете за изпълнение за изтриване са много сходни, само с няколко малки разлики в подробните изчисления. Следващият пример следователно преминава към разглеждане на плана за поддръжка за актуализация на основната таблица:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Както и преди, тази заявка използва променливи, за да скрие литералните стойности от оптимизатора, предотвратявайки прилагането на някои опростявания. Също така внимавайте да актуализирате две отделни групи, предотвратявайки оптимизации, които могат да бъдат приложени, когато оптимизаторът знае, че само една група (един ред от индексирания изглед) ще бъде засегната. Анотираният план за изпълнение на заявката за актуализиране е по-долу:
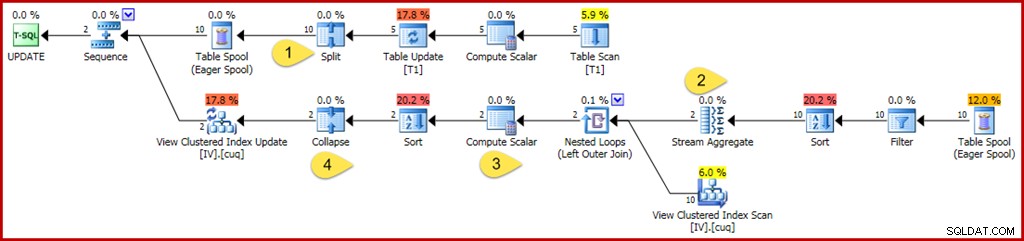
Промените и интересните места са:
- Новият оператор Split превръща всяка актуализация на ред на основна таблица в отделна операция за изтриване и вмъкване. Всеки ред за актуализиране се разделя на два отделни реда, удвоявайки броя на редовете след тази точка в плана. Разделянето е част от модела за разделяне-сортиране-свиване, необходим за защита срещу неправилни преходни грешки при нарушаване на уникален ключ.
- Агрегатът на потока е променен, за да отчита входящите редове, които могат да посочат или изтриване, или вмъкване (поради разделянето и се определя от колона с код за действие в реда). Вмъкнат ред допринася за първоначалната стойност в сумарни агрегати; знакът се обръща за изтриване на редове за действие. По същия начин, агрегираният брой редове тук отчита вмъкване на редове като +1 и изтриване на редове като –1.
- Изчислителната скаларна логика също е променена, за да отрази, че нетният ефект от промените на група може да изисква евентуално действие за вмъкване, актуализиране или изтриване спрямо материализирания изглед. Всъщност не е възможно тази конкретна заявка за актуализиране да доведе до вмъкване или изтриване на ред срещу този изглед, но логиката, необходима за извеждане на това, е извън текущите способности за разсъждение на оптимизатора. Малко по-различна заявка за актуализиране или дефиниция на изглед наистина може да доведе до смесица от действия за вмъкване, изтриване и актуализиране на изглед.
- Операторът за свиване е подчертан единствено заради ролята му в споменатия по-горе модел на разделяне на сортиране и свиване. Имайте предвид, че той свива само изтривания и вмъквания на един и същ ключ; несравними изтривания и вмъквания след свиването са напълно възможни (и съвсем обичайни).
Както и преди, ключовите свойства на оператора, които трябва да разгледате, за да разберете работата по поддръжката на индексирания изглед, са филтърът, агрегатът на потока, външното присъединяване и скаларата за изчисляване.
Пример 4 – Многоредова актуализация с присъединявания
За да завършим прегледа на плановете за поддръжка на индексиран изглед, ще ни е необходим нов примерен изглед, който свързва няколко таблици заедно и включва проекция в списъка за избор:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); За да се гарантира коректност, едно от изискванията за индексиран изглед е, че агрегатът на сумата не може да работи с израз, който може да се оцени като нула. Дефиницията на изглед по-горе използва ISNULL, за да отговори на това изискване. Примерна заявка за актуализиране, която произвежда доста изчерпателен компонент на плана за поддръжка на индекса, е показан по-долу, заедно с плана за изпълнение, който произвежда:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
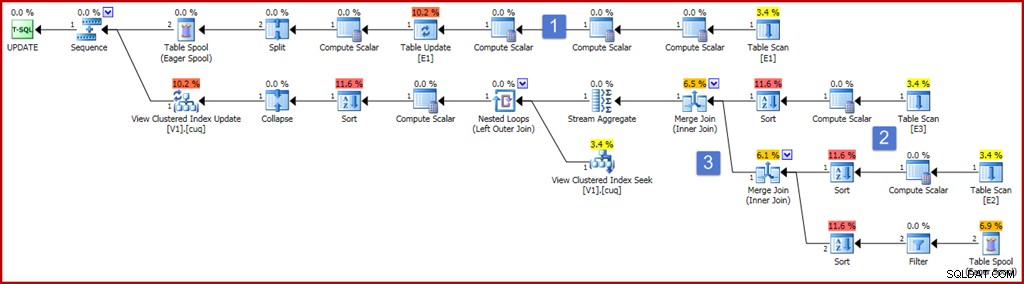
Сега планът изглежда доста голям и сложен, но повечето от елементите са точно такива, каквито вече видяхме. Основните разлики са:
- Горният клон на плана включва редица допълнителни оператори за скаларно изчисление. Те биха могли да бъдат по-компактно подредени, но по същество те присъстват, за да улавят стойностите преди актуализиране на колоните, които не се групират. Скаларът за изчисляване вляво от актуализацията на таблицата улавя стойността след актуализацията на колона "a", с приложена проекция ISNULL.
- Новите скалари за изчисляване в тази област на плана изчисляват стойността, произведена от израза ISNULL за всяка таблица източник. Като цяло, проекциите върху съединените таблици в изгледа ще бъдат представени от Compute Scalars тук. Сортовете в тази област на плана присъстват само защото оптимизаторът е избрал стратегия за обединяване с обединяване по причини на разходите (не забравяйте, че сливането изисква сортиран вход по ключ за присъединяване).
- Двата оператора за свързване са нови и просто имплементират обединяванията в дефиницията на изгледа. Тези обединения винаги се появяват преди Stream Aggregate, който изчислява нарастващия ефект от промените върху изгледа. Имайте предвид, че промяната в основна таблица може да доведе до това, че ред, който е отговарял на критериите за присъединяване, вече не се присъединява и обратно. Всички тези потенциални сложности се обработват правилно (като се имат предвид ограниченията на индексирания изглед) от Stream Aggregate, създавайки обобщение на промените на ключ за изглед след извършване на обединяването.
Последни мисли
Този последен план представлява почти пълния шаблон за поддържане на индексиран изглед, въпреки че добавянето на неклъстерирани индекси към изгледа би добавило и допълнителни оператори, извлечени от изхода на оператора за актуализиране на изгледа. Освен допълнителното разделяне (и комбинация за сортиране и свиване, ако неклъстерираният индекс на изгледа е уникален), няма нищо особено специално в тази възможност. Добавянето на изходна клауза към заявката на основната таблица също може да доведе до някои интересни допълнителни оператори, но отново те не са специфични за поддръжката на индексиран изглед сами по себе си.
За да обобщим цялостната стратегия:
- Промените в базовата таблица се прилагат както обикновено; могат да бъдат уловени стойности преди актуализиране.
- Може да се използва оператор разделяне за трансформиране на актуализации в двойки изтриване/вмъкване.
- Нетърпелива макара запазва информацията за промяна на основната таблица във временно съхранение.
- Всички таблици в изгледа са достъпни, с изключение на актуализираната основна таблица (която се чете от пулта).
- Проекциите в изгледа са представени от изчислителни скалари.
- Филтрите в изгледа се прилагат. Филтрите могат да бъдат вкарани в сканирания или търсения като остатъци.
- Съединяванията, посочени в изгледа, се извършват.
- Агрегатът изчислява нетните допълнителни промени, групирани по ключ за клъстериран изглед.
- Наборът за постепенна промяна е външен присъединен към изгледа.
- Скаларът за изчисляване изчислява код за действие (вмъкване/актуализиране/изтриване спрямо изгледа) за всяка промяна и изчислява действителните стойности, които трябва да бъдат вмъкнати или актуализирани. Изчислителната логика се основава на изхода на агрегата и резултата от външното присъединяване към изгледа.
- Промените се сортират по реда на ключ за изглед и код за действие и се свиват до актуализации според случая.
- Накрая постепенните промени се прилагат към самия изглед.
Както видяхме, нормалният набор от инструменти, налични за оптимизатора на заявки, все още се прилага към автоматично генерираните части на плана, което означава, че една или повече от стъпките по-горе могат да бъдат опростени, трансформирани или премахнати изцяло. Въпреки това основната форма и действие на плана остават непокътнати.
Ако сте следвали заедно с примерите за код, можете да използвате следния скрипт за почистване:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;