В тази статия ще обясня как да преместите таблица от основната файлова група към вторичната файлова група. Първо, нека разберем какво представляват файл с данни, файлова група и тип файлови групи.
Файлове и файлови групи от база данни
Когато SQL Server е инсталиран на който и да е сървър, той създава първичен файл с данни и регистрационен файл за съхранение на данни. Първичният файл с данни съхранява данни и обекти от база данни като таблици, индекс, съхранени процедури и т.н. Регистрационните файлове съхраняват информация, необходима за възстановяване на транзакции. Файловете с данни могат да бъдат обединени във файлови групи.
SQL Server има три типа файлове
- Основен файл :Създава се при инсталиране на SQL сървър и съдържа метаданните и информацията на базата данни. Потребителски данни, обекти могат да се съхраняват в първичните файлове с данни. Основният файл има разширението .mdf.
- Вторичен файл :Вторичните файлове са дефинирани от потребителя. Те съхраняват потребителски данни, обекти, създадени от потребител. Те имат разширението .ndf.
- Регистрационен файл на транзакциите s:T-Log файловете регистрират всички извършени транзакции за възстановяване на базата данни. Разширението на регистрационния файл в .ldf.
Както споменах по-горе, файловете с данни могат да бъдат групирани във файлова група. Докато SQL Server се инсталира, той създава основната файлова група, която има основен файл с данни. Вторичните файлови групи са дефинирани от потребителя. Те имат вторични файлове с данни. Когато създаваме нова база данни, можем да създадем вторични файлове с данни и файлови групи. Добавянето на файлове с вторични данни помага за подобряване на производителността. Той може да бъде създаден на различни дискови устройства или отделни дискови дялове, което намалява латентността на изчакване на IO и четене-запис.
Препоръчително е да съхранявате таблици и индекси в отделни файлови групи. Освен това поддържането на големи таблици в отделни файлове подобрява производителността.
Има три типа файлови групи:
- Файлова група от редове :Файлова група на ред, известна още като Основна файлова група, съдържа основен файл с данни. SQL обект, данни, системни таблици се разпределят към основната файлова група.
- Оптимизирана за памет файлова група :Оптимизирана за памет файлова група съдържа оптимизирани за паметта таблици и данни. За да активираме OLTP в паметта, трябва да създадем файлова група, оптимизирана за паметта.
- Файлов поток :Файлова група с файлов поток съдържа данни от файлов поток като изображения, документи, изпълними файлове и т.н. Основната файлова група не може да съдържа данни за файлов поток, трябва да създадем файлова група FileStream. Той съдържа данните от FileStream.
Настройка на демонстрация
В тази демонстрация създадох „DemoDatabase“ на екземпляра на SQL Server 2017. В базата данни бяха създадени разделите „Записи“ и „Данни на пациента“. Първичният ключ „PK_CIDX_Records_ID“ беше създаден в таблицата „Records“, а клъстерният индекс „CIDX_PatientData_ID“ беше създаден в таблицата „PatientData“. В тази демонстрация ще преместя таблиците „Records“ и „PatientData“ от първичната файлова група към вторичната файлова група.
За това трябва да направим следното:
- Създайте вторична файлова група.
- Добавете файлове с данни към вторичната файлова група.
- Преместете таблицата във вторичната файлова група, като преместите клъстерирания индекс с ограничението на първичния ключ.
- Преместете таблиците във вторичната файлова група, като преместите клъстерирания индекс без първичния ключ.
Създаване на вторична файлова група
Вторична файлова група може да бъде създадена с помощта на T-SQL ИЛИ с помощта на съветника за добавяне на файл от SQL Server Management Studio. За да добавите файлова група с помощта на SSMS, отворете SSMS и изберете база данни, където трябва да се създаде файлова група. Щракнете с десния бутон върху базата данни, изберете „Свойства ”>> изберете „Файлови групи ” и щракнете върху „Добавяне на файлова група ” както е показано на следното изображение:
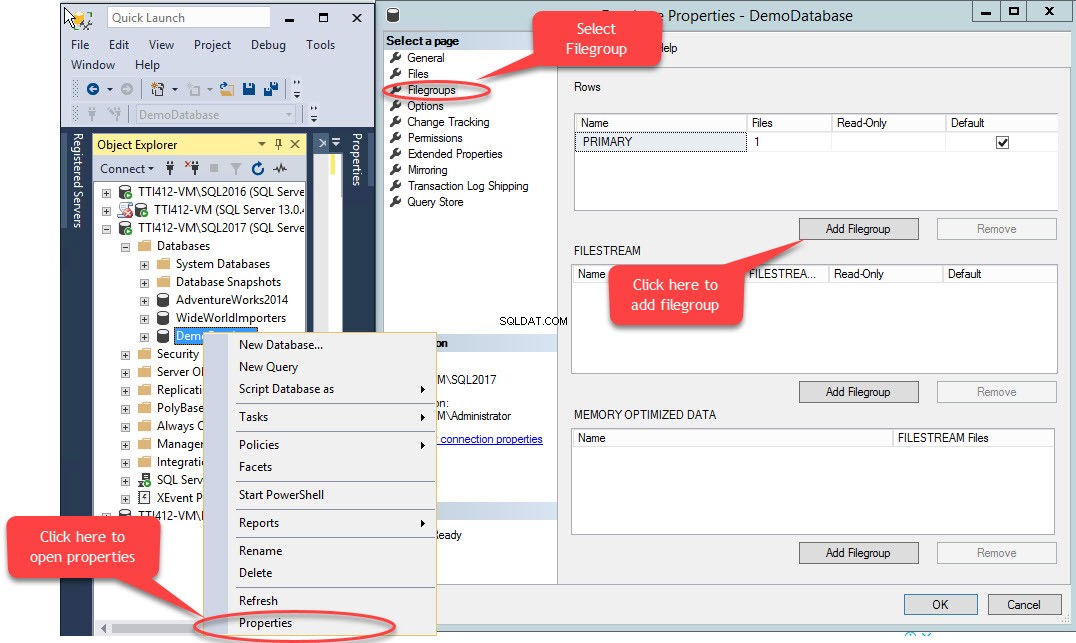
Когато щракнем върху „Добавяне на файлова група ” ще бъде добавен ред в „Редове ” решетка. В „Редове ” мрежа, посочете подходящо име на файлова група в „Име " колона. Файловата група не е нито само за четене, нито по подразбиране; следователно, запазете Само за четене и По подразбиране квадратчетата за отметка са изчистени за нова файлова група. Вижте следното изображение:
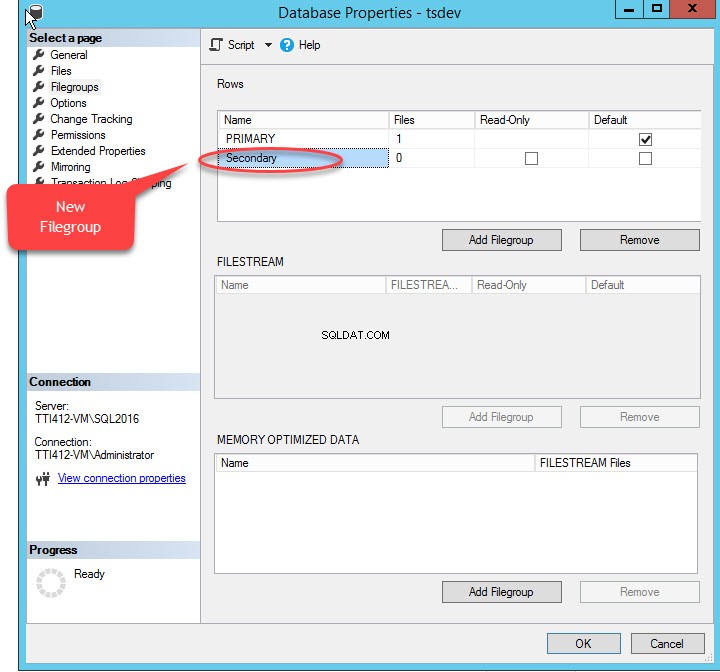
Щракнете върху OK, за да затворите диалоговия прозорец.
За да създадете файлова група с помощта на T-SQL скрипт, изпълнете следния скрипт.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Добавяне на файлове към файлова група
За да добавите файлове във файлова група, отворете свойствата на базата данни, изберете „файлове“ и щракнете върху „Добавяне“. Както е показано на следното изображение:
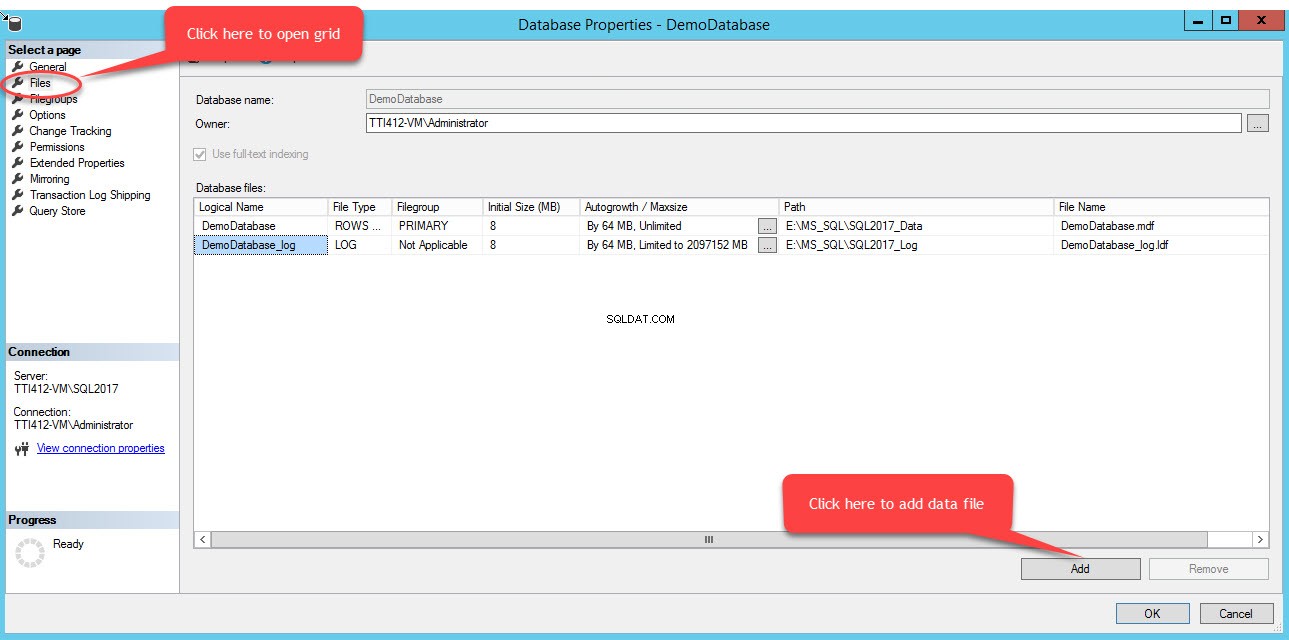
Ще бъде добавен празен ред в Файловете на базата данни изглед на мрежа. В изгледа на мрежата посочете подходящо логическо име в Логическо име колона, изберете Данни за редове отТип файл падащо меню, изберете вторичен от Файловата група падащото поле, задайте първоначалния размер на файла в Начален размер колони, задайте параметър за автоматичен растеж и максимален размер в Автоматичен растеж/Максимален размер колона, посочете физическото местоположение на вторичния файл с данни в Пътят колона и посочете подходящо име на файл в Име на файл колона. Вижте следното изображение:
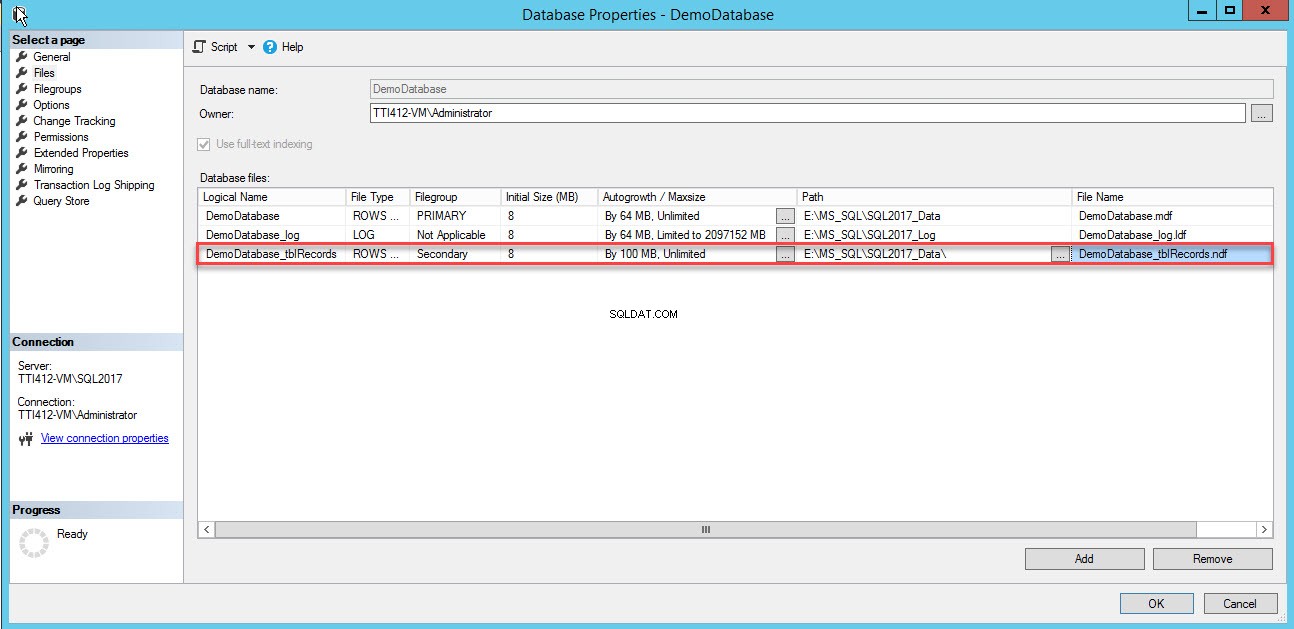
Използвайте следния T-SQL скрипт, за да създадете вторичен файл с данни.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
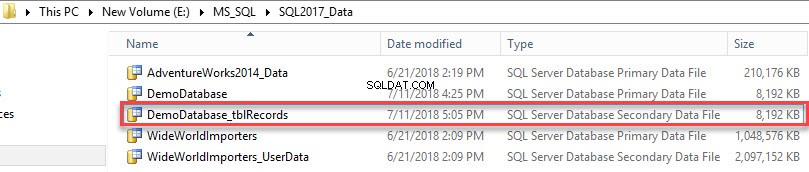
Вторичният файл с данни е създаден. Вижте следното изображение:
За да видите списък с файлови групи, създадени в базата данни, изпълнете следната заявка.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
По-долу е изход от заявката.

Прехвърляне на съществуваща таблица от първична файлова група към вторична файлова група
Можем да преместим съществуваща таблица в друга файлова група, като преместим клъстерирания индекс в друга файлова група. Както знаем, листовият възел на клъстерирания индекс има действителни данни; следователно преместването на клъстериран индекс може да премести цялата таблица в друга файлова група. Преместването на индекса има ограничение:ако индексът е първичен ключ или уникално ограничение, не можете да премествате индекс с помощта на SQL Server Management Studio. За да преместим тези индекси, трябва да използваме създаване на индекс изявление и с DROP_Existing=ON опция.
Преместване на клъстериран индекс с ограничение на първичния ключ.
Първичният ключ налага уникални стойности, следователно създава уникален клъстериран индекс. Ключовата колона е PRN. За да го създадете във вторичната файлова група, задайте DROP_EXISTING=ON опция и файловата група трябва да е вторична. Изпълнете следния скрипт.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
След като командата е изпълнена успешно, проверете дали индексът е създаден във вторичната файлова група. За това щракнете с десния бутон върху Съхранение опция в Свойства на индекса диалогов прозорец. За да отворите свойствата на индекса, разгънете DemoDatabase база данни>> разгънете Таблици>> разгънете Индекси . Щракнете с десния бутон върху PK_CIDX_Records_ID , както е показано на следното изображение:
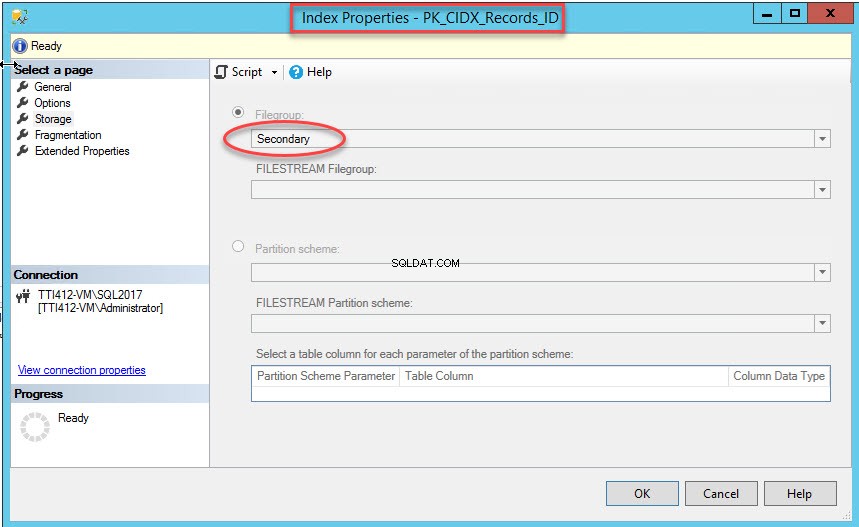
Както споменах, след като клъстерираният индекс се премести във вторична файлова група, таблицата ще бъде преместена във вторичната файлова група. За да го потвърдите, щракнете с десния бутон върху Съхранение опция вСвойства на таблицата диалогов прозорец. За да отворите свойствата на индекса, разгънете DemoDatabase база данни>> разгънете Таблица s>> щракнете с десния бутон върху Записи, и изберете хранилище както е показано на следното изображение:
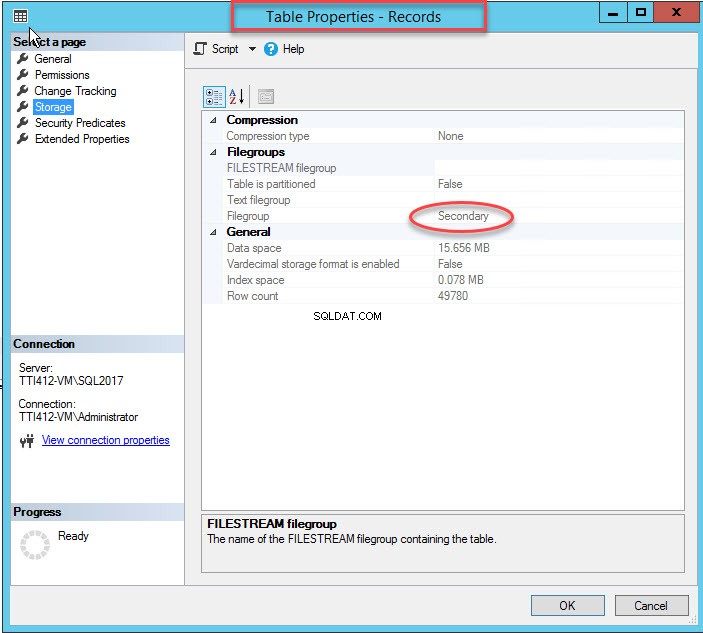
Преместване на клъстериран индекс без първичен ключ
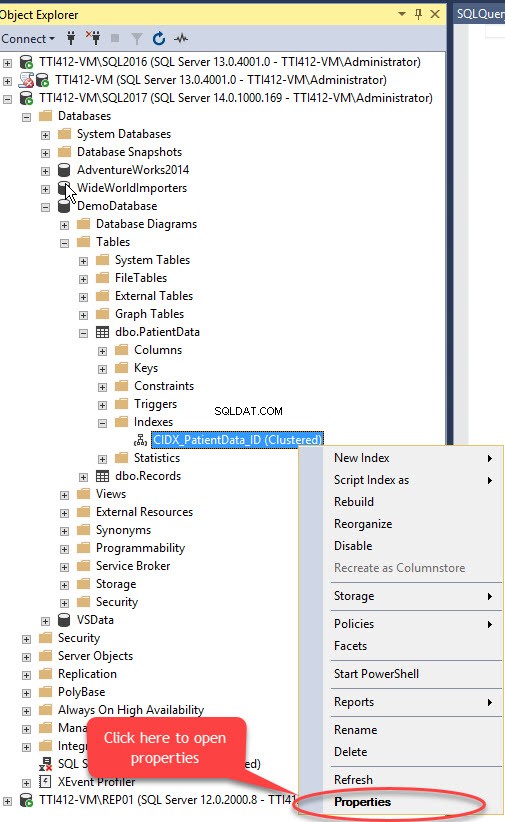
Можем да преместваме клъстериран индекс без първичен ключ, използвайки SQL Server Management Studio. За да направите това, разгънете DemoDatabase база данни>> разгънете Таблици>> разгънете Индекс s>> щракнете с десния бутон върху CIDX_PatientData_ID индекс и изберете Свойства както е показано на следното изображение:
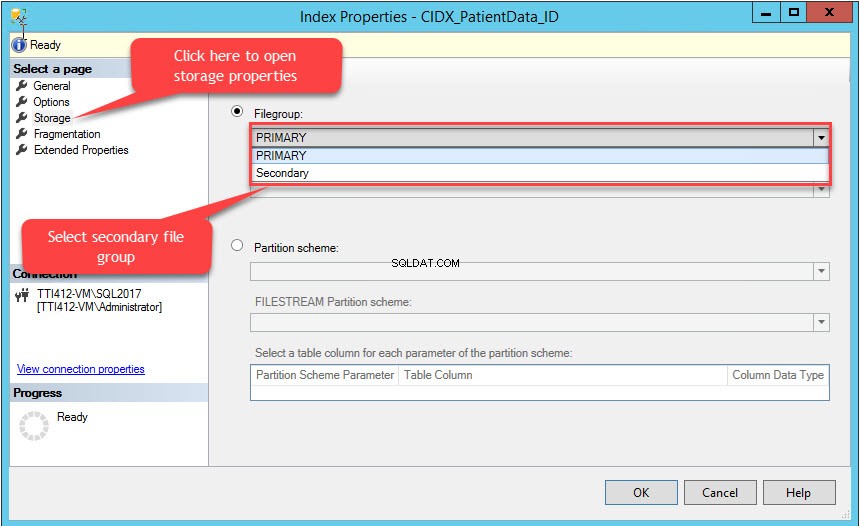
Свойства на индекса диалогов прозорец се отваря. В диалоговия прозорец изберете Съхранение и в прозореца за съхранение щракнете върху Файлова група падащото меню, изберете Вторично файлова група и щракнете върху OK както е показано на следното изображение:
Промяната на индексната файлова група ще създаде отново целия индекс. След като индексът бъде създаден отново, отворете Свойства на таблицата и изберете хранилище.
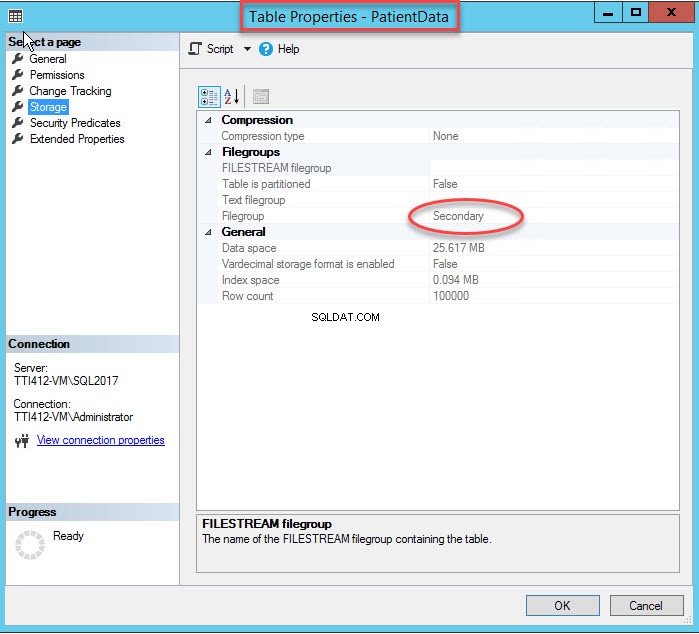
Както можете да видите на изображението по-горе, заедно с преместването на CIDX_PatientData_ID клъстериран индекс към вторичната файлова група,PatientData таблицата също се премества в Вторично файлова група.
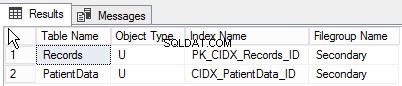
Като изпълните следната заявка, можете да намерите списъка с обекти, създадени в различна файлова група:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go По-долу е изходът от заявката:
Резюме
В тази статия обясних
-
- Основи на файловете с данни и файловите групи.
- Как да създадете вторична файлова група и да добавите вторичен файл с данни в нея.
- Преместете таблицата във вторична файлова група, като преместите:
- Първичен ключ.
- Клъстериран индекс.