В предишните си статии обясних как да създадете и конфигурирате функцията FILESTREAM в екземпляр на SQL сървър. Освен това демонстрирах как да създам таблица, която има колона FILESTREAM и гореща за вмъкване и изтриване на данните от нея.
В тази статия ще обясня как да архивирам и възстановя базата данни с активиран FILESTREAM. Освен това ще демонстрирам как да възстановя файловата група FILESTREAM, без да правя база данни офлайн.
Както обясних в предишните си статии, когато активираме FILESTREAM на екземпляр на SQL Server, трябва да създадем FILESTREAM контейнер, който има файловата група FILESTREAM. Когато архивираме базата данни с активиран FILESTREAM, архивирането на файловата група FILESTREAM ще бъде включено в набора за архивиране. Когато възстановим базата данни, SQL Server ще възстанови базата данни и контейнера FILESTREAM и файловете в нея.
Когато архивираме база данни с активиран FILESTREAM, тя ще:
- Архивирайте всички налични файлове с данни на базата данни.
- Архивирайте файловата група FILESTREAM и файловете в нея.
- Резервно копие на T-Log.
SQL Server дава гъвкавостта да се прави резервно копие само на контейнера FILESTREAM. Ако файловете в контейнера FILESTREAM се повредят, не е необходимо да възстановяваме цялата база данни. Можем да възстановим само файловата група FILESTREAM.
В тази демонстрация ще:
- Обяснете как да направите пълно архивиране на базата данни на FS и да архивирате само контейнера FILESTREAM.
- Обяснете как да възстановите базата данни с активиран FILESTREAM.
- Как да възстановите контейнера FILESTREAM онлайн и офлайн. Забележка:Изданието SQL Server Enterprise и изданието за разработчици поддържа ОНЛАЙН възстановяване.
Настройка на демонстрация:
В тази демонстрация ще използвам:
- База данни :SQL Server 2017
- Софтуер :Студио за управление на SQL Server.
Архивиране на база данни с активиран FILESTREAM
За да демонстрирам процеса на архивиране, създадох база данни с активиран FILESTREAM с име FileStream_Demo . Той има таблица FILESTREAM с име Document_Content .
Пълно архивиране на базата данни
Архивирането на база данни с активиран FILESTREAM е лесен процес. За да генерирате пълно архивиране на него, изпълнете следния T-SQL скрипт.
РЕзервно копие на БАЗА ДАННИ [FileStream_Demo] НА ДИСК =N'E:\Backups\FileStream_Demo.bak' С NOFORMAT, NOINIT, NAME =N'FileStream_Demo-Full Database Backup', SKIP, NOREWIND1, NOSTAUN =>Следва архивният дневник, генериран чрез изпълнение на горната команда за архивиране:
/*Започнете архивиране на DataFile*/Обработени 568 страници за база данни „FileStream_Demo“, файл „FileStream_Demo“ във файл 1./*Започнете архивиране на контейнера FILESTREAM*/ 10 процента обработени. 20 процента обработени. 30 процента обработени. 40 процента обработени. 50 процента обработени. 60 процента обработени. 70 процента обработени. 80 процента обработени. 90 процента обработени. Обработени 111106 страници за база данни 'FileStream_Demo', файл 'Dummy-Documents ' във файл 1./*Започнете архивиране на контейнера FILESTREAM*/ Обработени 4 страници за база данни „FileStream_Demo“, файл „FileStream_Demo_log“ във файл 1,100 процента обработен. BACKUP DATABASE успешно обработи 111677 страници за 18,410 секунди (47,391 MB/sec).Както споменах в началото на статията, първо, SQL сървърът прави резервно копие на първичния файл с данни, след това на вторичните файлове с данни и накрая, регистрационните файлове за транзакции. Както можете да видите в архивния дневник, първо, резервното копие на SQL сървъра Основен файл с данни, след това файловата група FILESTREAM и свързаните с нея данни и накрая регистрационни файлове на транзакциите.
Архивиране на контейнер FILESTREAM
Както споменах в началото на статията, можем също да генерираме резервно копие на контейнера FILESTREAM. За да създадете резервно копие на контейнера FILESTREAM, изпълнете следния T-SQL скрипт.
BACKUP DATABASE [FileStream_Demo] FILEGROUP =N'Dummy-Documents' TO DISK =N'E:\Backups\FS_Container.bak' С NOFORMAT, NOINIT, NAME =N'FileStream_Demo-Full Database, NOREWINDSKIP, NOUNLOAD, STATS =10GOВъзстановяване на база данни с активиран FILESTREAM
Когато възстановим базата данни FILESTREAM, SQL възстановява контейнера FileStream заедно с всички файлове в контейнера FILESTREAM.
За да възстановите базата данни, изпълнете следните задачи:
- В SSMS щракнете с десния бутон върху базата данни и изберете Възстановяване на база данни .
- В диалоговия прозорец Възстановяване изберете Устройство и щракнете върху Преглед . Ще се отвори друг диалогов прозорец. В диалоговия прозорец щракнете върху Добавяне .
- В Намерете архивен файл диалогов прозорец, придвижете се през структурата на директорията, щракнете върху подходящо архивно копие и щракнете върху OK .
- След като информацията за архивиране се зареди в Набори за архивиране за възстановяване изглед на мрежа, щракнете върху OK за да започнете да възстановявате процеса.
Като алтернатива можете да възстановите база данни, като изпълните следната команда:
ИЗПОЛЗВАЙТЕ [master]ВЪЗСТАНОВЯВАНЕ НА БАЗА ДАННИ [FileStream_Demo] ОТ ДИСК =N'E:\Backups\FileStream_Demo.bak' С ФАЙЛ =1, НЕЗАРАЗЯВАНЕ, СТАТИСТИКА =5GOСценарий за възстановяване на база данни с активиран FILESTREAM
Файловата група FILESTREAM възстановява процес като процеса на възстановяване на файлови групи.
За да генерирате сценария за възстановяване, създайте база данни с активиран FILESTREAM с име FileStream-Demo . Базата данни има таблица FILESTREAM с име Document_Content . Поставете някои произволни данни и файлове в Document_Content таблица.
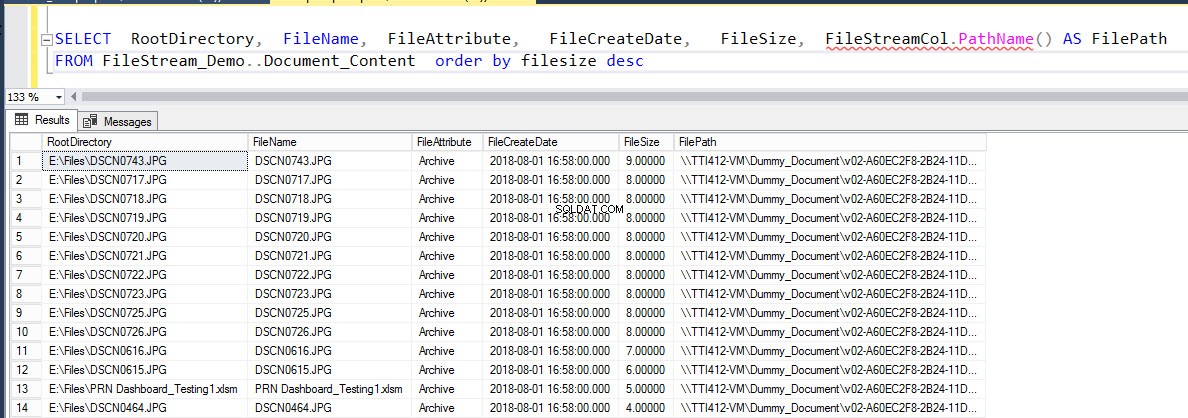
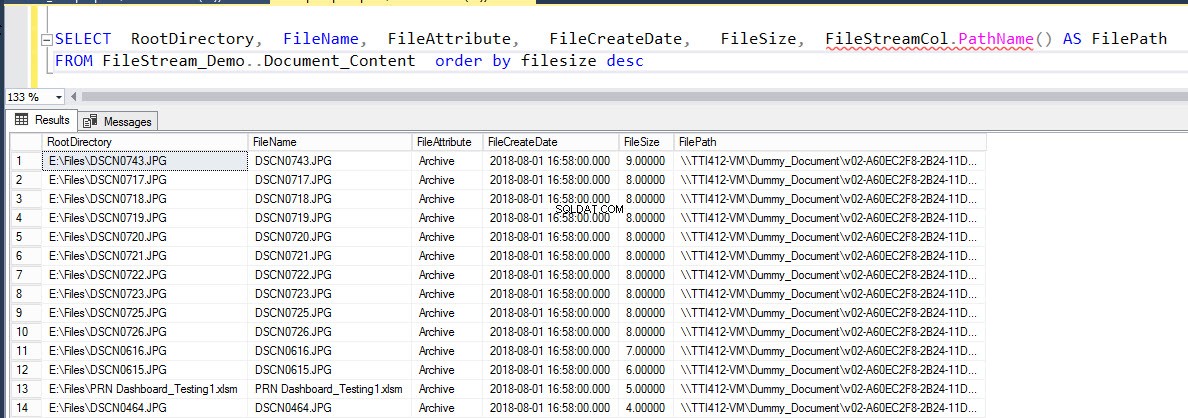
Изпълнете следната заявка, за да попълните подробности за файловете, вмъкнати в таблицата.
ИЗБЕРЕТЕ RootDirectory, FileName, FileAttribute, FileCreateDate, FileSize, FileStreamCol.PathName() КАТО FilePath FROM Document_Content подредете по опис на размера на файлаРезултатът е както следва:
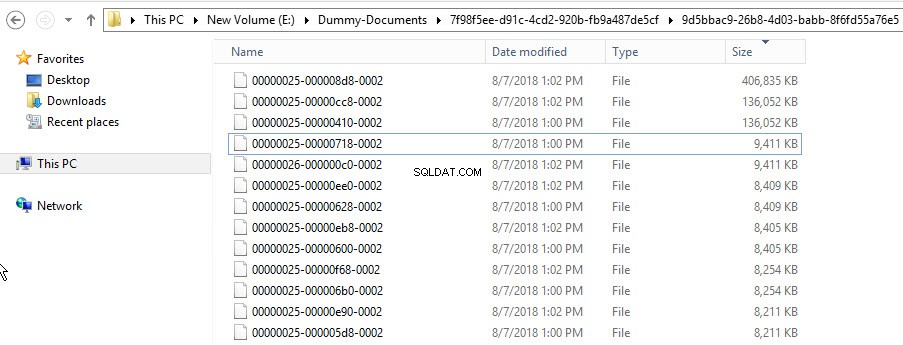
Следва екранна снимка на контейнера FILESTREAM:
Първо, генерирайте пълен архив на базата данни. За това изпълнете следната команда.
РЕзервно копие на БАЗА ДАННИ [FileStream_Demo] НА ДИСК =N'E:\Backups\Full_FileStream_Demo_20180810.bak' С NOFORMAT, NOINIT,NAME =N'FileStream_Demo-Full Database Backup'Второ, генерирайте резервно копие FILEGROUP на файловата група FILESTREAM с име Dummy-Document като изпълните следната команда:
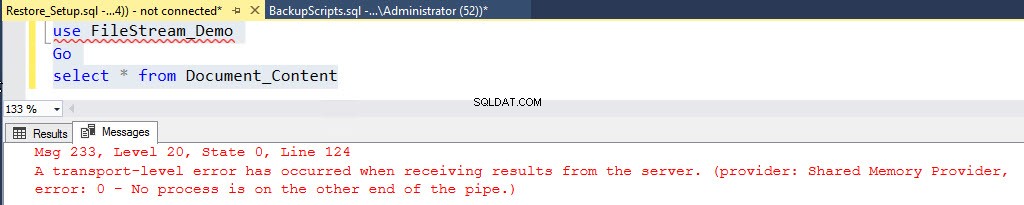
РЕЗЕРВНА БАЗА ДАННИ [FileStream_Demo] FILEGROUP =N'Dummy-Documents' КЪМ ДИСКА =N'E:\Backups\FileStream_Filegroup_Demo.bak' С NOFORMAT, NOINIT, NAME =N'FileStream_Demo-Full' Backup'За да генерирате повреда на FILESTREAM, изтрийте някои файлове от контейнера FILESTREAM. След като тези файлове бъдат изтрити, опитайте да извлечете данни от „Document_Content“, като изпълните следната команда:
Използвайте FileStream_DemoGoselect * от Document_ContentЩе получите следната грешка:
Съобщение 233, ниво 20, състояние 0, ред 122 Възникна грешка на транспортно ниво при получаване на резултати от сървъра. (доставчик:Доставчик на споделена памет, грешка:0 - Няма процес от другия край на тръбата.)Вижте следната екранна снимка:
Сега трябва да възстановим контейнера FILESTREAM, за да коригираме тази грешка. Генерирахме пълно архивиране и архивиране на Dummy-document файлова група.
Можем да възстановим целия контейнер FILESTREAM, като възстановим файловата група FILESTREAM. Ще покажа:
- Офлайн възстановяване на файлова група FILESTREAM.
- Онлайн възстановяване на файлова група FILESTREAM.
Офлайн възстановяване на файлова група на контейнера FILESTREAM
Тъй като бях изтрил файлове от контейнера FILESTREAM, не е необходимо да възстановяваме цялата база данни. Следователно вместо да възстановяваме цялата база данни, ще възстановим единствената файлова група. За да направите това, първо генерирайте резервно копие на Tail-Log, за да уловите промените в данните, които не са били архивирани. Архивирането на Tail-log трябва да бъде направено с помощта на опцията NORECOVERY, за да приведе базата данни в състояние на възстановяване и това дава възможност за прилагане на резервни копия върху базата данни. За да направите това, изпълнете следната заявка:
резервно копие на дневника [FileStream_Demo] на диск ='E:\Backups\FileStream_Filegroup_Demo_Log_1.trn' С NORECOVERYСлед като резервното копие на Tail-log бъде генерирано, базата данни ще бъде в режим на възстановяване. Сега можем да приложим архивирането на FILEGROUP върху база данни с опцията NORECOVERY. За целта изпълнете следната команда:
използвайте mastergoRESTORE DATABASE [FileStream_Demo] FILE='Dummy-Documents' FROM DISK =N'E:\Backups\FileStream_Filegroup_Demo.bak' С NORECOVERY,REPLACE;Сега приложете архивирането на Tail-log с опцията RECOVERY. За целта изпълнете следната команда:
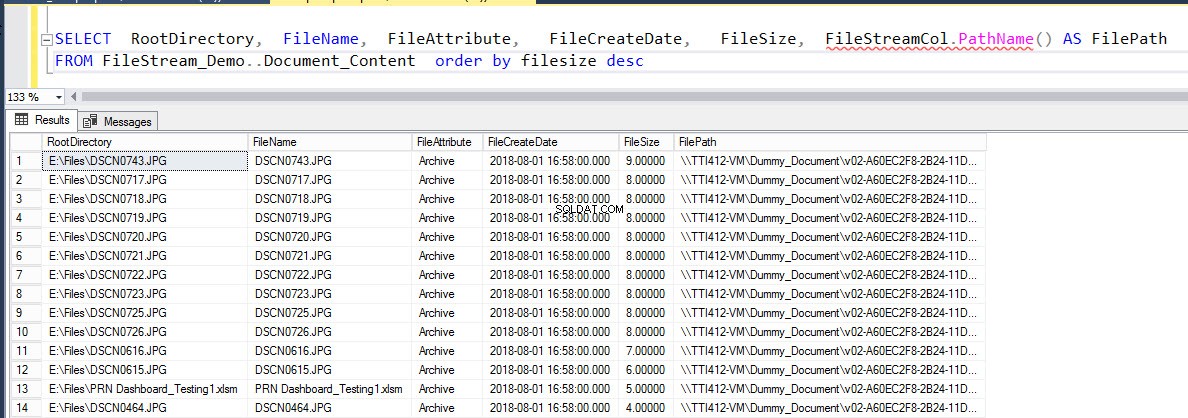
ВЪЗСТАНОВЯВАНЕ НА ДНИ [FileStream_Demo] ОТ ДИСКА =N'E:\Backups\FileStream_Filegroup_Demo_Log_1.trn'След като резервното копие се възстанови, базата данни ще бъде онлайн и всички файлове ще бъдат възстановени в контейнера FILESTREAM. За да го потвърдите, изпълнете следната команда:
ИЗБЕРЕТЕ RootDirectory, FileName, FileAttribute, FileCreateDate, FileSize, FileStreamCol.PathName() КАТО FilePath FROM Document_Content подредете по опис на размера на файлаРезултатът от горната заявка е както следва:
Онлайн възстановяване на файлова група FILESTREAM
Използвайки корпоративното издание на SQL сървър, можем да възстановим архива, когато базата данни е онлайн. Например, ако файл F1 от вторичната файлова група FG-1 е повреден, тогава можем да възстановим файл F1, докато базата данни остава онлайн. Последователността на възстановяване на офлайн и онлайн възстановяване е една и съща.
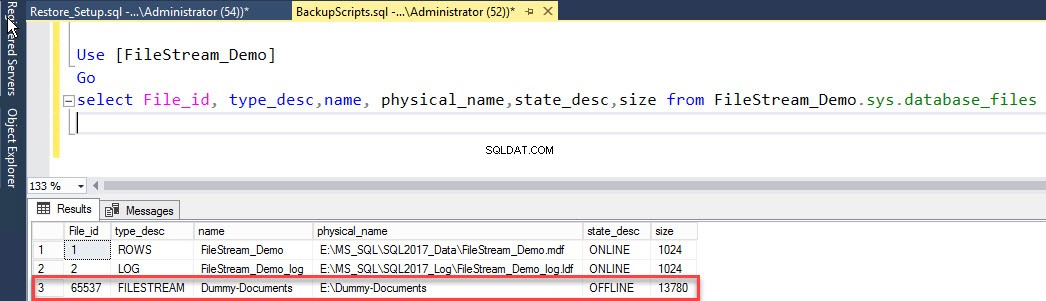
Както бе споменато по-горе, за да извършите онлайн възстановяване на файловата група FILESTREAM, направете Dummy-Document файл с данни офлайн. За това изпълнете следната команда.
използвайте mastergoAlter база данни [FileStream_Demo] ПРОМЕНЯНЕ НА ФАЙЛ (NAME='Dummy-Documents',OFFLINE)За да проверите състоянието на файла, изпълнете следната заявка:
Използвайте [FileStream_Demo]Goselect File_id, type_desc,name,physical_name,state_desc,size от FileStream_Demo.sys.database_filesРезултатът е както следва:
Вече направихме резервно копие на Dummy-document файлова група. Следователно, след като файлът с данни е офлайн, възстановете архива на FILEGROUP в база данни с опцията NORECOVERY. За целта изпълнете следната команда:
използвайте mastergoRESTORE DATABASE [FileStream_Demo] FILE='Dummy-Documents' ОТ ДИСКА =N'E:\Backups\FileStream_Filegroup_Demo.bak' С NORECOVERY, ЗАМЕНЕТЕ;Сега направете архивно копие на лог на базата данни, за да се уверите, че точката, в която файлът с данни е излязъл офлайн, е уловен. За целта изпълнете следната команда:
резервно копие на дневника [FileStream_Demo] на диск ='E:\Backups\FileStream_Filegroup_Demo_Log1.trn'Изпълнете следната команда, за да възстановите последното архивно копие на T-Log.
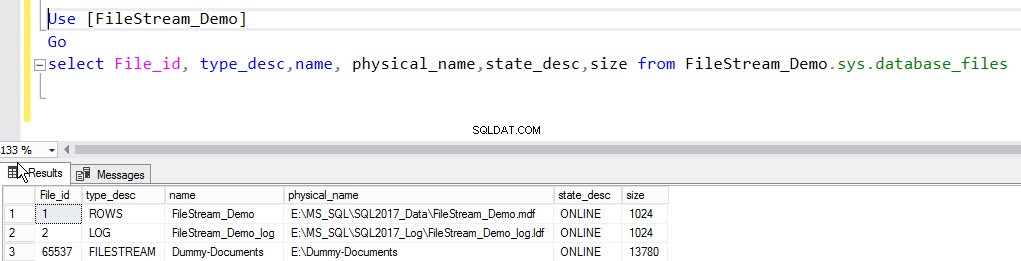
използвайте mastergoRESTORE LOG [FileStream_Demo] ОТ ДИСКА =N'E:\Backups\FileStream_Filegroup_Demo_Log1.trn'След като архивът на журнала се възстанови, всички файлове в контейнера FILESTREAM ще бъдат възстановени и файловата група ще бъде онлайн. За да потвърдите това, изпълнете следната заявка:
Използвайте [FileStream_Demo]Goselect File_id, type_desc,name,physical_name,state_desc,size от FileStream_Demo.sys.database_filesРезултатът е както следва:
След като архивът бъде възстановен, базата данни ще бъде онлайн и всички файлове ще бъдат възстановени в контейнера FILESTREAM. За да го потвърдите, изпълнете следната команда:
ИЗБЕРЕТЕ RootDirectory, FileName, FileAttribute, FileCreateDate, FileSize, FileStreamCol.PathName() КАТО FilePath FROM Document_Content подредете по опис на размера на файлаРезултатът е както следва:
Резюме
В тази статия обясних:
- Как да направите резервно копие и да възстановите базата данни с активиран FILESTREAM и файловата група FILESTREAM.
- Как да възстановим файловата група FILESTREAM онлайн и офлайн.