Сега нашата общност за анализ на големи данни започна да използва Apache Spark с пълна сила за обработка на големи данни. Обработката може да се използва за ad hoc заявки, предварително изградени заявки, обработка на графики, машинно обучение и дори за поточно предаване на данни.
Следователно разбирането на Spark Job Submission е много важно за общността. Разширете до това с удоволствие да споделя с вас знанията от стъпките, включени в изпращането на задание в Apache Spark.
По принцип има две стъпки,

Подаване на работа
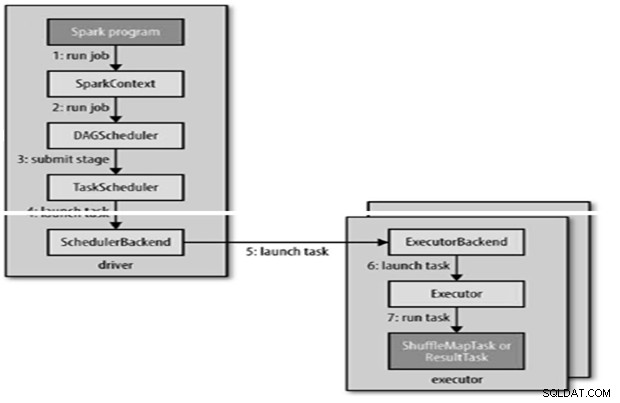
Заданието Spark се изпраща автоматично, когато се извършват действия като count () върху RDD.
Вътрешно runJob() се извиква в SparkContext и след това се извиква към планировчика, който се изпълнява като част от деривъра.
Планировчикът се състои от 2 части – DAG Scheduler и Task Scheduler.
DAG Construction
Има два вида DAG конструкции,

- Simple Spark задание е такова, което не се нуждае от разбъркване и поради това има само един етап, съставен от задачи с резултати, като задача само за карта в MapReduce
- Сложното задание на Spark включва групиращи операции и изисква един или повече етапа на разбъркване.
- DAG планировщикът на Spark превръща заданието в два етапа.
- DAG планировчикът е отговорен за разделянето на етап на задачи за подаване на планировчика на задачи.
- На всяка задача се дава предпочитание за разположение от планировчика на DAG, за да позволи на планировчика на задачи да се възползва от локалността на данните.
- Етапите за деца се изпращат само след като родителите им завършат успешно.
Планиране на задачи
- Инструментът за планиране на задачи ще изпрати набор от задачи; той използва своя списък с изпълнители, които се изпълняват за приложението, и изгражда съпоставяне на задачите с изпълнители, което взема предвид предпочитанията за разположение.
- Планировчикът на задачи присвоява на изпълнители, които имат свободни ядра, като на всяка задача се разпределя едно ядро по подразбиране. Може да се промени чрез параметър spark.task.cpus.
- Spark използва Akka, която е базирана на актьори платформа за изграждане на силно мащабируеми разпределени приложения, управлявани от събития.
- Spark не използва Hadoop RPC за отдалечени обаждания.
Изпълнение на задача
Изпълнителят изпълнява задача, както следва,
- Той гарантира, че зависимостите на JAR и файла за задачата са актуални.
- Десериализира кода на задачата.
- Кодът на задачата се изпълнява.
- Task връща резултати на драйвера, който се сглобява в краен резултат, който се връща на потребителя.
Справка
- Окончателното ръководство на Hadoop
- Общност с отворен код за анализи и големи данни
Тази статия първоначално се появи тук. Препубликувано с разрешение. Изпратете жалбите си за авторски права тук.