В предишната си публикация говорих за начини за генериране на последователност от последователни числа от 1 до 1000. Сега бих искал да говоря за следващите нива на мащаб:генериране на набори от 50 000 и 1 000 000 числа.
Генериране на набор от 50 000 числа
Когато започнах тази серия, бях искрено любопитен как различните подходи ще се мащабират до по-големи набори от числа. В ниския край бях малко уплашен да открия, че любимият ми подход – използвайки sys.all_objects – не беше най-ефективният метод. Но как биха се мащабирали тези различни техники до 50 000 реда?
Таблица с числа
Тъй като вече сме създали таблица с числа с 1 000 000 реда, тази заявка остава практически идентична:
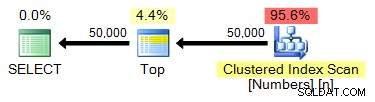
ИЗБЕРЕТЕ ТОП (50000) n ОТ dbo.Числа ПОРЪЧАЙТЕ ПО n;
План:
spt_values
Тъй като в spt_values има само ~2500 реда , трябва да бъдем малко по-креативни, ако искаме да го използваме като източник на нашия генератор на набори. Един от начините за симулиране на по-голяма таблица е CROSS JOIN то срещу себе си. Ако направихме това необработено, щяхме да получим ~2500 реда на квадрат (над 6 милиона). Необходими са само 50 000 реда, имаме нужда от около 224 реда на квадрат. Така че можем да направим това:
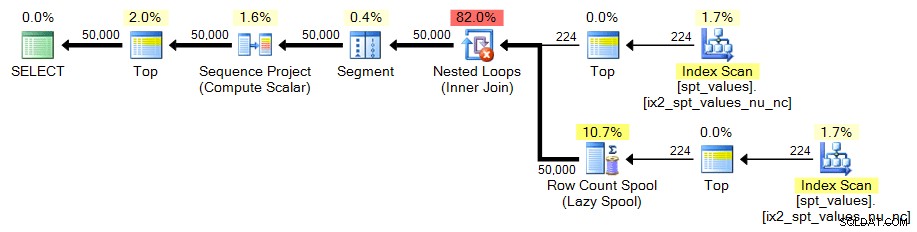
;WITH x AS ( SELECT TOP (224) number FROM [master]..spt_values)SELECT TOP (50000) n =ROW_NUMBER() НАД (ПОРЪЧКА ПО x.number) FROM x CROSS JOIN x AS yORDER BY n;
Имайте предвид, че това е еквивалентно, но по-сбито от този вариант:
ИЗБЕРЕТЕ ВЪРХА (50000) n =ROW_NUMBER() НАД (ПОРЪЧКА ПО x.число) ОТ (ИЗБЕРЕТЕ ВЪРХА (224) номер ОТ [главен]..spt_values) КАТО xCROSS JOIN(ИЗБЕРЕТЕ ВЪРХ (224) номер ОТ [главен ]..spt_values) КАТО yORDER BY n;
И в двата случая планът изглежда така:
sys.all_objects
Като spt_values , sys.all_objects не удовлетворява напълно нашето изискване за 50 000 реда сам по себе си, така че ще трябва да извършим подобно CROSS JOIN .
;;С x AS ( ИЗБЕРЕТЕ ВЪРХА (224) [object_id] ОТ sys.all_objects)ИЗБЕРЕТЕ ВЪРХА (50000) n =ROW_NUMBER() НАД (ПОРЪЧКА ПО x.[object_id]) ОТ x КРЪСТО ПРИСЪЕДИНЯВАНЕ x КАТО y ПОРЪЧКА BY n;
План:

Натрупани CTEs
Трябва само да направим малка корекция на нашите подредени CTE, за да получим точно 50 000 реда:
;С e1(n) AS( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) , -- 10e2(n) AS (ИЗБЕРЕТЕ 1 ОТ e1 КРЪСТО ПРИСЪЕДИНЯВАНЕ e1 AS b), -- 10*10e3(n) AS (ИЗБЕРЕТЕ 1 ОТ e2 КРЪСТО ПРИЕДИНЯВАНЕ e2 AS b), -- 100*100e4(n) AS (ИЗБЕРЕТЕ 1 ОТ e3 КРЪСТО ПРИСЪЕДИНЯВАНЕ (ИЗБЕРЕТЕ ТОП 5 n ОТ e1) КАТО b) -- 5*10000 SELECT n =ROW_NUMBER() НАД (ПОРЪЧАЙТЕ ПО n) ОТ e4 ПОРЪЧАЙТЕ ПО n;
План:

Рекурсивни CTEs
Необходима е още по-малко съществена промяна, за да се извадят 50 000 реда от нашия рекурсивен CTE:променете WHERE клауза на 50 000 и променете MAXRECURSION опция на нула.
;С n(n) КАТО( ИЗБЕРЕТЕ 1 ОБЪЕД ВСИЧКИ ИЗБЕРЕТЕ n+1 ОТ n КЪДЕ n <50000)ИЗБЕРЕТЕ n ОТ n ПОРЪЧАЙТЕ ПО nOPTION (МАКС.РЕКУРСИЯ 0);
План:
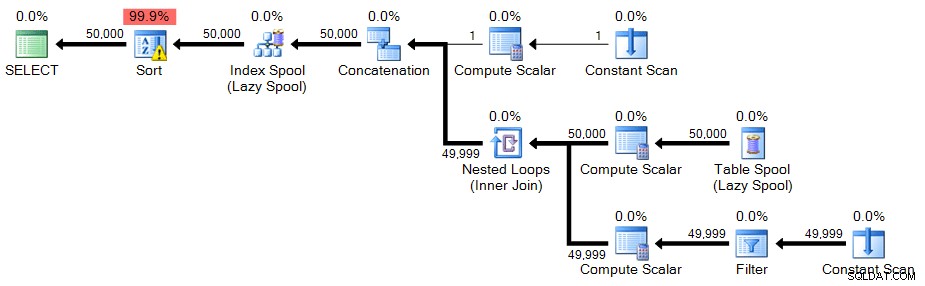
В този случай има икона за предупреждение върху сортирането – както се оказва, в моята система сортирането трябва да се разлее в tempdb. Може да не видите разлив на системата си, но това трябва да е предупреждение за ресурсите, необходими за тази техника.
Ефективност
Както при последния набор от тестове, ние ще сравним всяка техника, включително таблицата Numbers със студен и топъл кеш, както и компресиран и некомпресиран:
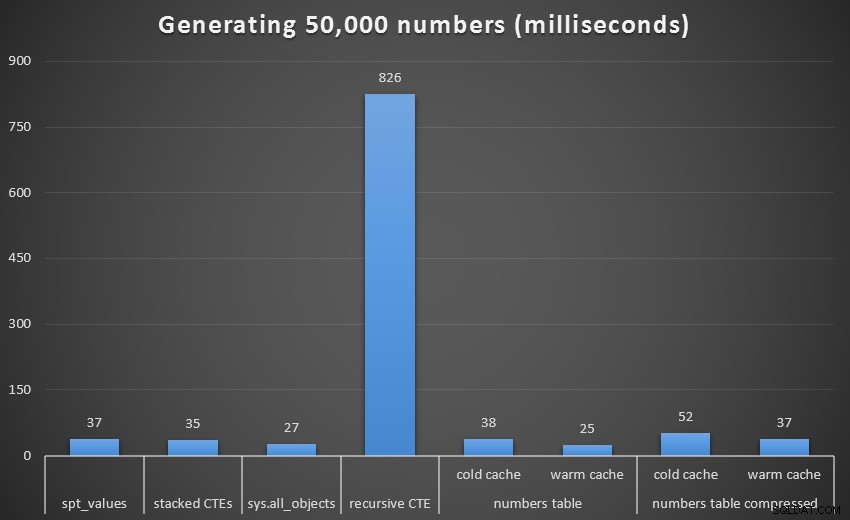
Време на изпълнение, в милисекунди, за генериране на 50 000 последователни числа
За да получите по-добра визуализация, нека премахнем рекурсивния CTE, който беше пълно куче в този тест и който изкривява резултатите:
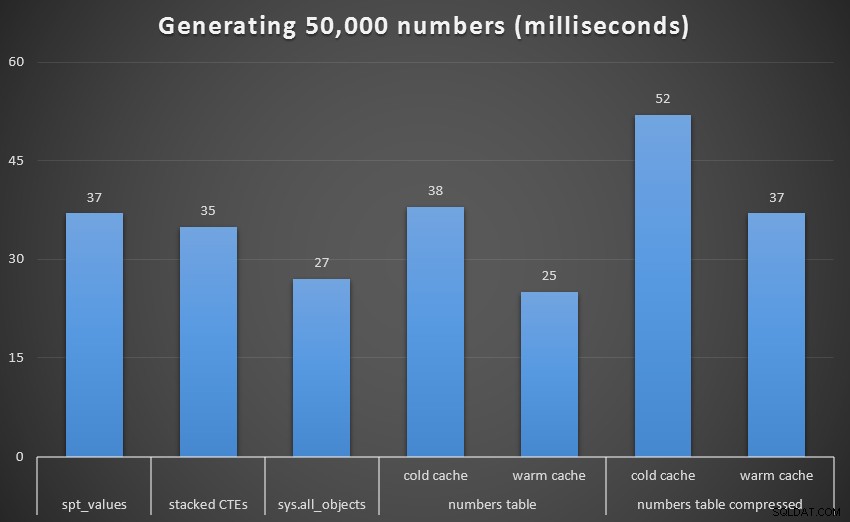
Време на изпълнение, в милисекунди, за генериране на 50 000 последователни числа (с изключение на рекурсивни CTE)
При 1000 реда разликата между компресирано и некомпресирано беше незначителна, тъй като заявката трябваше да прочете само 8 и 9 страници съответно. При 50 000 реда разликата се разширява малко:74 страници срещу 113. Въпреки това, общите разходи за декомпресиране на данните изглежда надвишават спестяванията при I/O. Така че, при 50 000 реда, таблицата с некомпресирани числа изглежда е най-ефективният метод за извличане на непрекъснат набор – въпреки че, разбира се, предимството е незначително.
Генериране на набор от 1 000 000 числа
Въпреки че не мога да си представя много случаи на употреба, при които ще ви трябва толкова голям последователен набор от числа, исках да го включа за пълнота и тъй като направих някои интересни наблюдения в този мащаб.
Таблица с числа
Тук няма изненади, нашето запитване е:
ИЗБЕРЕТЕ ТОП 1000000 n ОТ dbo.Числа ПОРЪЧАЙТЕ ПО n;
TOP не е строго необходимо, но това е само защото знаем, че нашата таблица с числа и желаният ни изход имат еднакъв брой редове. Планът все още е доста подобен на предишните тестове:
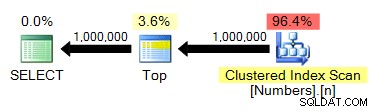
spt_values
За да получите CROSS JOIN което дава 1 000 000 реда, трябва да вземем 1 000 реда на квадрат:
;WITH x AS ( SELECT TOP (1000) number FROM [master]..spt_values)SELECT n =ROW_NUMBER() НАД (ПОРЪЧКА ПО x.number) ОТ x КРЪСТО ПРИСЪЕДИНИ x AS y ORDER BY n;;>
План:
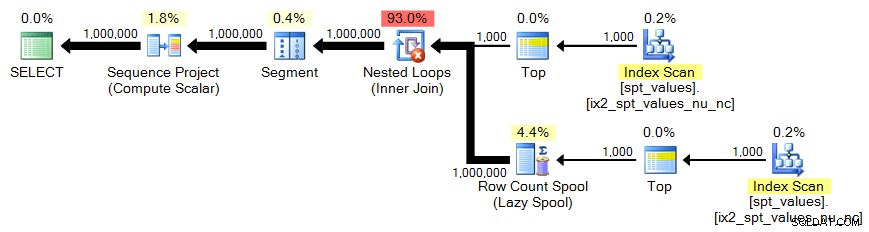
sys.all_objects
Отново се нуждаем от кръстосаното произведение на 1000 реда:
;С x КАТО ( ИЗБЕРЕТЕ ТОП (1000) [object_id] ОТ sys.all_objects)ИЗБЕРЕТЕ n =ROW_NUMBER() НАД (ПОРЪЧАЙТЕ ПО x.[object_id]) ОТ x КРЪСТО ПРИСЪЕДИНЕТЕ x КАТО y ПОРЪЧАЙТЕ ПО n;План:
Натрупани CTEs
За подредената CTE, ние просто се нуждаем от малко по-различна комбинация от
CROSS JOINs, за да стигнете до 1 000 000 реда:;С e1(n) AS( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) , -- 10e2(n) AS (ИЗБЕРЕТЕ 1 ОТ e1 КРЪСТО ПРИСЪЕДИНЯВАНЕ e1 AS b), -- 10*10e3(n) AS (ИЗБЕРЕТЕ 1 ОТ e1 КРЪСТО ПРИЕДИНЯВАНЕ e2 AS b), -- 10*100e4(n) AS (ИЗБЕРЕТЕ 1 ОТ e3 КРЪСТО ПРИСЪЕДИНЕТЕ e3 AS b) -- 1000*1000 SELECT n =ROW_NUMBER() НАД (ПОРЪЧАЙТЕ ПО n) ОТ e4 ПОРЪЧАЙТЕ ПО n;План:
При този размер на реда можете да видите, че подреденото CTE решение върви успоредно. Затова пуснах и версия с
MAXDOP 1за да получите подобна форма на план като преди и да видите дали паралелизмът наистина помага:
Рекурсивен CTE
Рекурсивният CTE отново има само малка промяна; само
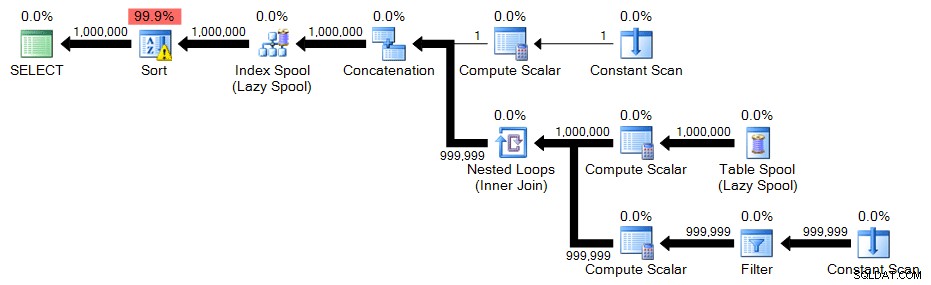
WHEREклаузата трябва да се промени:;С n(n) КАТО( ИЗБЕРЕТЕ 1 ОБЪЕДИНЕНИЕ ВСИЧКИ ИЗБЕРЕТЕ n+1 ОТ n, КЪДЕ n <1000000) ИЗБЕРЕТЕ n ОТ n ПОРЪЧАЙТЕ ПО nOPTION (МАКС. РЕКУРСИЯ 0);План:
Ефективност
Още веднъж виждаме, че производителността на рекурсивния CTE е ужасна:
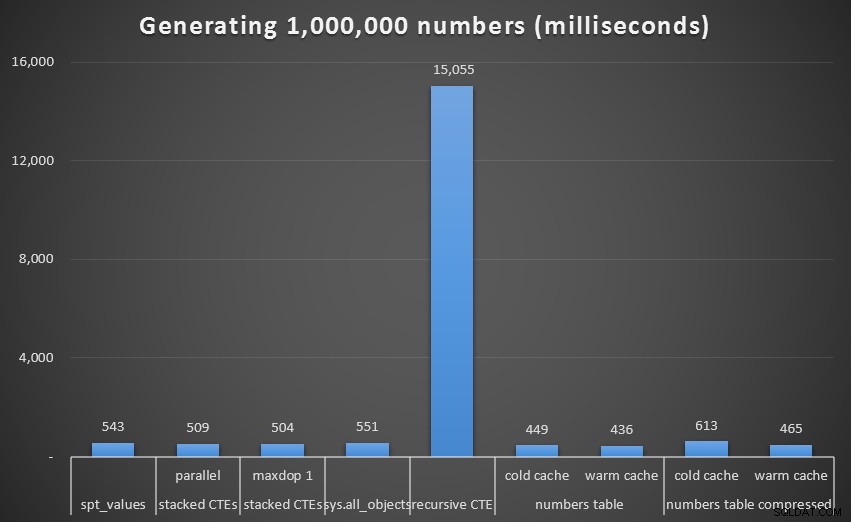
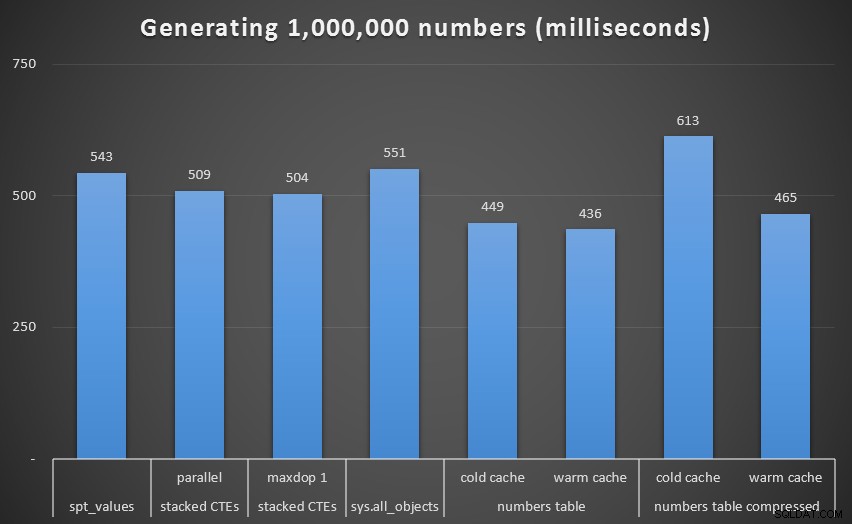
Време на изпълнение, в милисекунди, за генериране на 1 000 000 последователни числаПремахването на този отклонение от графиката получаваме по-добра представа за производителността:
Време на изпълнение, в милисекунди, за генериране на 1 000 000 последователни повтарящи се числа (напр. CTE)Въпреки че отново виждаме некомпресираната таблица с числа (поне с топъл кеш) като победител, разликата дори при този мащаб не е чак толкова забележителна.
Продължава...
След като проучихме задълбочено няколко подхода за генериране на поредица от числа, ще преминем към датите. В последната публикация от тази поредица ще преминем през изграждането на период от време като набор, включително използването на календарна таблица и няколко случая на използване, когато това може да бъде полезно.
[ Част 1 | Част 2 | Част 3 ]
Допълнение:Брой на редовете
Може да не се опитвате да генерирате точен брой редове; вместо това може да искате просто лесен начин за генериране на много редове. Следва списък от комбинации от изгледи на каталог, които ще ви осигурят различен брой редове, ако просто
SELECTбезWHEREклауза. Обърнете внимание, че тези числа ще зависят от това дали сте на RTM или сервизен пакет (тъй като някои системни обекти се добавят или променят), както и дали имате празна база данни.



| Източник | Брой редове | ||
|---|---|---|---|
| SQL Server 2008 R2 | SQL Server 2012 | SQL Server 2014 | |
| master..spt_values | 2508 | 2515 | 2519 |
| master..spt_values CROSS JOIN master..spt_values | 6 290 064 | 6,325,225 | 6 345 361 |
| sys.all_objects | 1990 | 2089 | 2165 |
| sys.all_columns | 5157 | 7276 | 8 560 |
| sys.all_objects КРЪСТНО ПРИСЪЕДИНЕНИЕ към sys.all_objects | 3 960 100 | 4 363 921 | 4 687 225 |
| sys.all_objects КРЪСТО ПРИЕДИНЯВАНЕ към sys.all_columns | 10 262 430 | 15 199 564 | 18 532 400 |
| sys.all_columns КРЪСТО ПРИЕДИНЯВАНЕ към sys.all_columns | 26 594 649 | 52 940 176 | 73 273 600 |
Таблица 1:Брой на редовете за различни заявки за изглед на каталог