Екипът на SQLskills обича статистиката за чакане. Ако прегледате публикациите в този блог (вижте публикациите на Paul в Knee-Jerk Wait Statistics) и на сайта SQLskills, ще видите публикации от всички нас, обсъждащи стойността на статистиката за чакане, какво търсим и защо определен чакането е проблем. Пол пише за това най-много, но всички ние обикновено започваме със статистика за чакане, когато отстраняваме проблем с производителността. Какво означава това от гледна точка на проактивност?
За да получите пълна представа за това какво означават статистическите данни за чакане по време на проблем с производителността, трябва да знаете какви са вашите нормални изчаквания. Това означава проактивно улавяне на тази информация и използване на тази изходна линия като справка. Ако нямате тези данни, тогава когато възникне проблем с производителността, няма да знаете дали PAGELATCH чаканията са типични за вашата среда (съвсем възможно) или ако изведнъж имате проблем, свързан с tempdb поради някакъв нов код, който беше добавен .
Статистически данни за чакане
По-рано публикувах скрипт, който използвам за заснемане на статистически данни за изчакване и това е скрипт, който използвам от дълго време за клиенти. Въпреки това, наскоро направих промени в моя скрипт и леко промених метода си. Нека обясня защо...
Основната предпоставка зад статистиката за чакане е, че SQL Server проследява всеки път, когато нишка трябва да изчака „нещо“. Чакате да прочетете страница от диск? PAGEIOLATCH_XX изчакайте. Изчаквате да ви бъде предоставено заключване, така че да направите промяна в данните? LCX_M_XXX изчакайте. Чакате за предоставяне на памет, за да може да се изпълни заявка? RESOURCE_SEMAPHORE изчакайте. Всички тези чакания се проследяват в sys.dm_os_wait_stats DMV и данните просто се натрупват с течение на времето... това е кумулативен представител на изчакванията.
Например, имам екземпляр на SQL Server 2014 в една от моите виртуални машини, който работи и от около 9:30 тази сутрин:
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
 Начален час на SQL сървъра
Начален час на SQL сървъра
Сега, ако погледна как изглежда статистиката ми за чакане (запомнете, кумулативна досега) с помощта на скрипта на Paul, виждам, че TRACEWRITE е моето текущо „стандартно“ чакане:
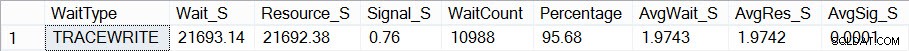 Текущи обобщени изчаквания
Текущи обобщени изчаквания
Добре, сега нека представим пет минути спор за tempdb и да видим как това се отразява на общата ми статистика за чакане. Имам скрипт, който Джонатан е използвал преди, за да създаде tempdb конкуренция, и съм го настроил така, че да работи за 5 минути:
USE AdventureWorks2012;
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentTime SMALLDATETIME = SYSDATETIME(), @EndTime SMALLDATETIME = DATEADD(MINUTE, 5, SYSDATETIME());
WHILE @CurrentTime < @EndTime
BEGIN
IF OBJECT_ID('tempdb..#temp') IS NOT NULL
BEGIN
DROP TABLE #temp;
END
CREATE TABLE #temp
(
ProductID INT PRIMARY KEY,
OrderQty INT,
TotalDiscount MONEY,
LineTotal MONEY,
Filler NCHAR(500) DEFAULT(N'') NOT NULL
);
INSERT INTO #temp(ProductID, OrderQty, TotalDiscount, LineTotal)
SELECT
sod.ProductID,
SUM(sod.OrderQty),
SUM(sod.LineTotal),
SUM(sod.OrderQty + sod.UnitPriceDiscount)
FROM Sales.SalesOrderDetail AS sod
GROUP BY ProductID;
DECLARE
@ProductNumber NVARCHAR(25),
@Name NVARCHAR(50),
@TotalQty INT,
@SalesTotal MONEY,
@TotalDiscount MONEY;
SELECT
@ProductNumber = p.ProductNumber,
@Name = p.Name,
@TotalQty = t1.OrderQty,
@SalesTotal = t1.LineTotal,
@TotalDiscount = t1.TotalDiscount
FROM Production.Product AS p
JOIN #temp AS t1 ON p.ProductID = t1.ProductID;
SET @CurrentTime = SYSDATETIME()
END Използвах командния ред, за да стартирам 10 сесии, които изпълняваха този скрипт, и едновременно с това изпълних скрипт, който засне общата ми статистика за чакане, моментна снимка на чаканията за период от 5 минути и след това отново общата статистика за чакане. Първо, малка тайна, тъй като ние игнорираме доброкачествените изчаквания през цялото време, може да е полезно да ги поставите в таблица, така че да можете да препращате към обект, вместо постоянно да се налага да кодирате твърдо списък с низове за изключване в заявка. И така:
USE SQLskills_WaitStats; GO CREATE TABLE dbo.WaitsToIgnore(WaitType SYSNAME PRIMARY KEY); INSERT dbo.WaitsToIgnore(WaitType) VALUES(N'BROKER_EVENTHANDLER'), (N'BROKER_RECEIVE_WAITFOR'), (N'BROKER_TASK_STOP'), (N'BROKER_TO_FLUSH'), (N'BROKER_TRANSMITTER'), (N'CHECKPOINT_QUEUE'), (N'CHKPT'), (N'CLR_AUTO_EVENT'), (N'CLR_MANUAL_EVENT'), (N'CLR_SEMAPHORE'), (N'DBMIRROR_DBM_EVENT'), (N'DBMIRROR_EVENTS_QUEUE'), (N'DBMIRROR_WORKER_QUEUE'), (N'DBMIRRORING_CMD'), (N'DIRTY_PAGE_POLL'), (N'DISPATCHER_QUEUE_SEMAPHORE'), (N'EXECSYNC'), (N'FSAGENT'), (N'FT_IFTS_SCHEDULER_IDLE_WAIT'), (N'FT_IFTSHC_MUTEX'), (N'HADR_CLUSAPI_CALL'), (N'HADR_FILESTREAM_IOMGR_IOCOMPLETIO(N'), (N'HADR_LOGCAPTURE_WAIT'), (N'HADR_NOTIFICATION_DEQUEUE'), (N'HADR_TIMER_TASK'), (N'HADR_WORK_QUEUE'), (N'KSOURCE_WAKEUP'), (N'LAZYWRITER_SLEEP'), (N'LOGMGR_QUEUE'), (N'ONDEMAND_TASK_QUEUE'), (N'PWAIT_ALL_COMPONENTS_INITIALIZED'), (N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP'), (N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP'), (N'REQUEST_FOR_DEADLOCK_SEARCH'), (N'RESOURCE_QUEUE'), (N'SERVER_IDLE_CHECK'), (N'SLEEP_BPOOL_FLUSH'), (N'SLEEP_DBSTARTUP'), (N'SLEEP_DCOMSTARTUP'), (N'SLEEP_MASTERDBREADY'), (N'SLEEP_MASTERMDREADY'), (N'SLEEP_MASTERUPGRADED'), (N'SLEEP_MSDBSTARTUP'), (N'SLEEP_SYSTEMTASK'), (N'SLEEP_TASK'), (N'SLEEP_TEMPDBSTARTUP'), (N'SNI_HTTP_ACCEPT'), (N'SP_SERVER_DIAGNOSTICS_SLEEP'), (N'SQLTRACE_BUFFER_FLUSH'), (N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP'), (N'SQLTRACE_WAIT_ENTRIES'), (N'WAIT_FOR_RESULTS'), (N'WAITFOR'), (N'WAITFOR_TASKSHUTDOW(N'), (N'WAIT_XTP_HOST_WAIT'), (N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG'), (N'WAIT_XTP_CKPT_CLOSE'), (N'XE_DISPATCHER_JOIN'), (N'XE_DISPATCHER_WAIT'), (N'XE_TIMER_EVENT');
Сега сме готови да уловим нашите чакания:
/* Capture the instance start time
(in this case, time since waits have been accumulating) */
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 1];
/* Get aggregate waits until now */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_Waits.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 2];
/* Capture a snapshot of waits over a 5 minute period */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
WAITFOR DELAY '00:05:00';
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 1];
/* Get aggregate waits again */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 2]; Ако погледнем изхода, можем да видим, че докато се изпълняваха 10-те екземпляра на скрипта за създаване на tempdb конкуренция, SOS_SCHEDULER_YIELD беше нашият най-разпространен тип чакане и също така имахме PAGELATCH_XX изчаквания, както се очакваше:
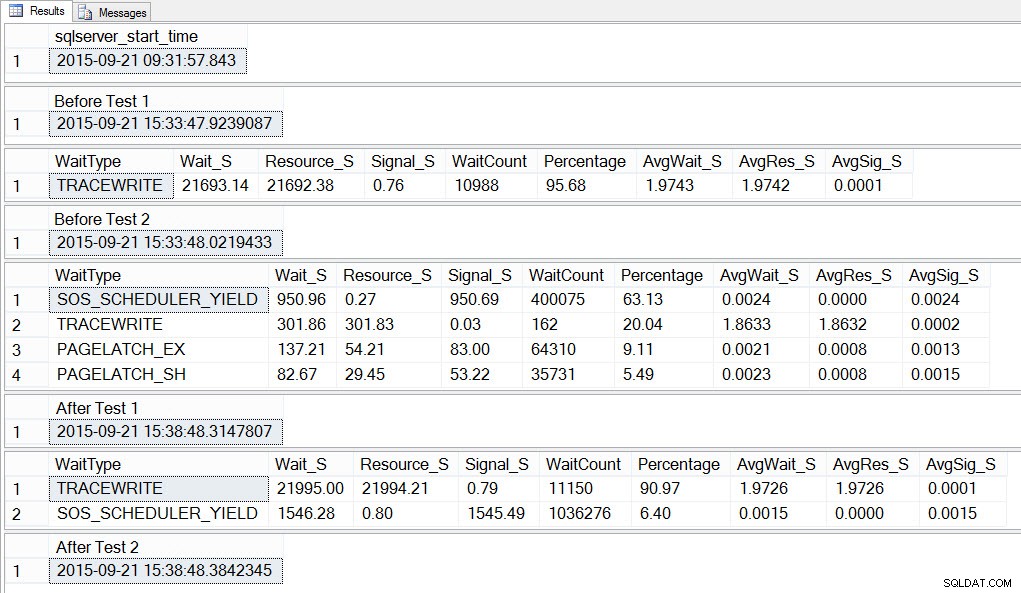
Ако погледнем средното изчакване СЛЕД приключването на теста, отново виждаме TRACEWRITE като най-високото изчакване и виждаме SOS_SCHEDULER_YIELD като изчакване. В зависимост от това какво друго се изпълнява в средата, това изчакване може или не може да продължи дълго време в нашите топ изчаквания и може или не може да се появи като тип чакане за разследване.
Проактивно заснемане на статистически данни за чакане
По подразбиране статистическите данни за чакане са кумулативни . Да, можете да ги изчистите по всяко време, като използвате DBCC SQLPERF, но намирам, че повечето хора не правят това редовно, а просто ги оставят да се натрупват. И това е добре, но разберете как това се отразява на вашите данни. Ако рестартирате своя екземпляр само когато го поправите или когато има проблем (което се надяваме да се случва рядко), тогава тези данни може да се натрупват с месеци. Колкото повече данни имате, толкова по-трудно е да видите малки вариации... неща, които могат да бъдат проблеми с производителността. Дори когато имате „голям проблем“, който засяга целия ви сървър за няколко минути, както направихме тук с tempdb, той може да не създаде достатъчно промяна във вашите данни, за да бъде открит в натрупаните данни. По-скоро трябва да направите моментна снимка на данните (да ги заснемете, изчакайте няколко минути, заснемете ги отново и след това различите данните), за да видите какво наистина се случва в момента .
Като такъв, ако просто статистическите данни за изчакване на моментна снимка на всеки няколко часа, тогава събраните от вас данни просто показват продължаващото агрегиране във времето. Вие можете различете тези моментни снимки, за да получите разбиране за производителността между моментните снимки, но мога да ви кажа, че не се налага да пишете този код срещу голям набор от данни, това е болка (но аз не съм разработчик, така че може би е лесно и лесно за вас ).
Моят традиционен метод за улавяне на статистически данни за чакане беше просто да снимам sys.dm_os_wait_stats на всеки няколко часа, използвайки оригиналния скрипт на Пол:
USE [BaselineData];
GO
IF NOT EXISTS (SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats_OldMethod')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats_OldMethod]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NULL,
[WaitType] [nvarchar](120) NULL,
[Wait_S] [decimal](14, 2) NULL,
[Resource_S] [decimal](14, 2) NULL,
[Signal_S] [decimal](14, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](4, 2) NULL,
[AvgWait_S] [decimal](14, 4) NULL,
[AvgRes_S] [decimal](14, 4) NULL,
[AvgSig_S] [decimal](14, 4) NULL
);
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats_OldMethod]
ON [dbo].[SQLskills_WaitStats_OldMethod] ([CaptureDate],[RowNum]);
END
GO
/* Query to use in scheduled job */
USE [BaselineData];
GO
INSERT INTO [dbo].[SQLskills_WaitStats_OldMethod]
(
[CaptureDate] ,
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
EXEC ('WITH [Waits] AS (SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
GETDATE(),
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL(14, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL(14, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL(14, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL(4, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95;'
); След това ще мина през и ще погледна горното изчакване за всяка моментна снимка, например:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats_OldMethod] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber] , [CaptureDate] FROM [dbo].[SQLskills_WaitStats_OldMethod] WHERE [CaptureDate] IS NOT NULL AND [CaptureDate] > GETDATE() - 60 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Моят нов алтернативен метод е да различавам няколко моментни снимки на статистически данни за изчакване (с две до три минути между моментните снимки) на всеки час или така. След това тази информация ми казва какво точно е чакала системата по това време:
USE [BaselineData];
GO
IF NOT EXISTS ( SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats]
ON [dbo].[SQLskills_WaitStats] ([CaptureDate],[RowNum]);
END
/* Query to use in scheduled job */
USE [BaselineData];
GO
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Capture wait stats */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
/* Wait some amount of time */
WAITFOR DELAY '00:02:00';
GO
/* Capture wait stats again */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
/* Diff the waits */
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
INSERT INTO [BaselineData].[dbo].[SQLskills_WaitStats]
(
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
[W1].[wait_type],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) ,
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) ,
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) ,
[W1].[WaitCount] ,
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) ,
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4))
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
/* Clean up the temp tables */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2]; Новият ми метод по-добър ли е? Мисля, че е така, тъй като това е по-добро представяне на това как изглеждат изчакванията точно в момента на заснемане и все още се взема проби на редовен интервал. И за двата метода обикновено гледам какво е било най-голямото чакане в момента на заснемане:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber], [CaptureDate] FROM [dbo].[SQLskills_WaitStats] WHERE [CaptureDate] > GETDATE() - 30 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Резултати:
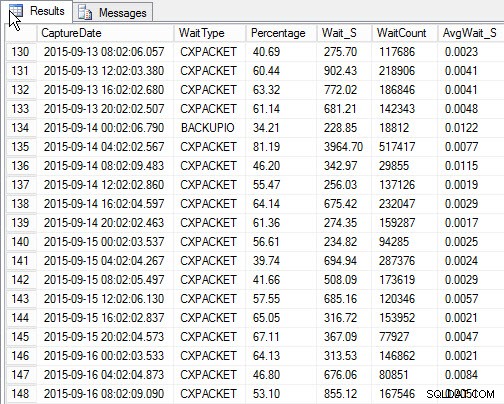 Най-високо изчакване за всяка моментна снимка (примерен изход)
Най-високо изчакване за всяка моментна снимка (примерен изход)
Недостатъкът, който съществуваше с моя оригинален скрипт, е, че все още е само моментна снимка . Мога да определям най-високите изчаквания с течение на времето, но ако има проблем, който възникне между моментните снимки, той няма да се появи. И така, какво можете да направите?
Можете да увеличите честотата на вашите заснемания. Може би вместо да улавяте статистика за чакане на всеки час, вие ги заснемате на всеки 15 минути. Или може би на всеки 10. Колкото по-често улавяте данните, толкова по-голям е шансът да уловите проблем с производителността.
Другата ви опция би била да използвате приложение на трета страна, като SQL Sentry Performance Advisor, за да наблюдавате чаканията. Performance Advisor извлича точно същата информация от sys.dm_os_wait_stats DMV. Запитва sys.dm_os_wait_stats на всеки 10 секунди с много проста заявка:
SELECT * FROM sys.dm_os_wait_stats WHERE wait_time_ms > 0;
След това зад кулисите Performance Advisor взема тези данни и ги добавя към своята база данни за мониторинг. Когато видите данните, доброкачествените изчаквания се премахват и делтите се изчисляват вместо вас. В допълнение, Performance Advisor има фантастичен дисплей (погледът към таблото е много по-приятен от извеждания текст по-горе) и можете да персонализирате колекцията, ако искате. Ако погледнем Performance Advisor и погледнем данните от целия ден, мога лесно да видя къде имам проблем в прозореца за изчакване на SQL Server:
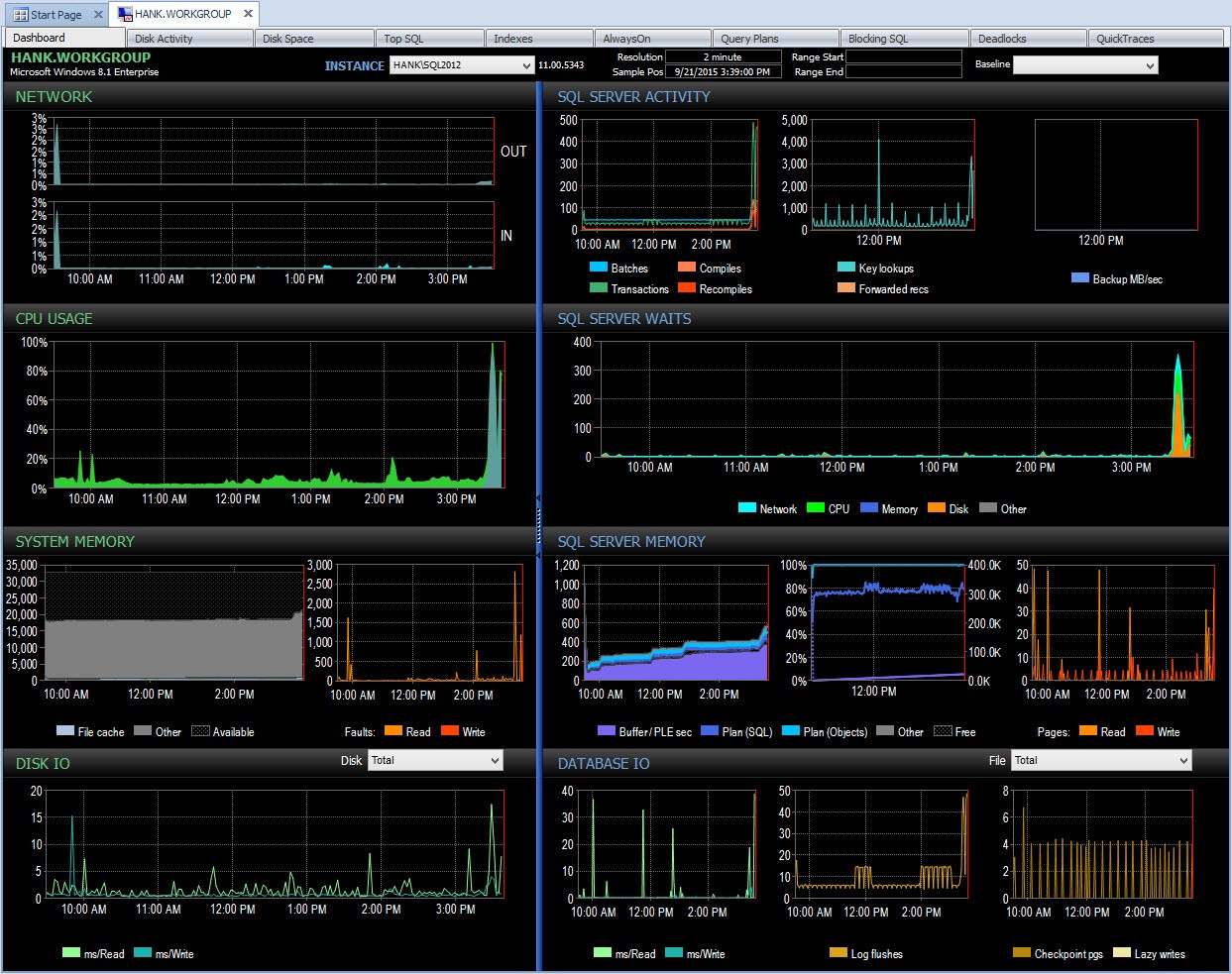 Табло за управление на съветника за ефективност за деня
Табло за управление на съветника за ефективност за деня
След това мога да проследя този период от време след 15:00, за да разследвам по-нататък какво се е случило:
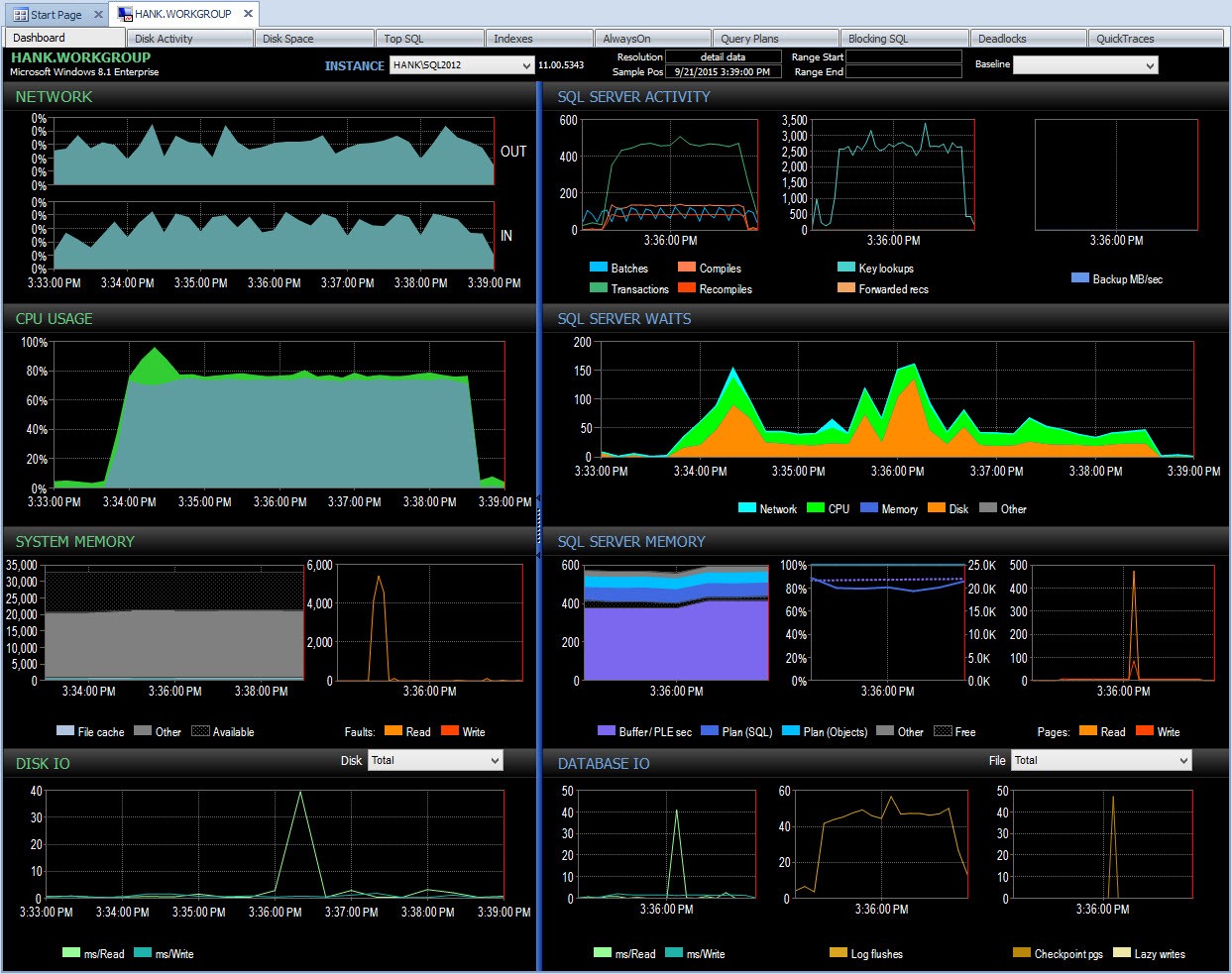 Разбивка в PA по време на проблем с производителността
Разбивка в PA по време на проблем с производителността
Мониторинг сам, освен ако случайно не получих статистика за изчакване на моментна снимка в същото време със скрипт, ще пропусна да заснема всякакви данни за този проблем с производителността. Тъй като Performance Advisor съхранява информацията за продължителен период от време, ако имате пропуск в производителността, вие правите да разполагате със статистическите данни за изчакване (заедно с много друга информация), за да помогнете за проучването на проблема, и също така разполагате с исторически данни, за да разберете какви нормални изчаквания съществуват във вашата среда.
Резюме
Какъвто и метод да изберете да наблюдавате изчакванията, първо е важно да разберете как SQL Server съхранява информация за изчакване, така че да разберете данните, които виждате, ако ги улавяте редовно. Ако трябва да разгръщате свои собствени скриптове, за да улавяте изчаквания, вие сте ограничени в това, че може да не улавяте отклоненията толкова лесно, колкото бихте могли със софтуера на трета страна. Но това е добре – да имате известно количество базови данни, за да можете да започнете да разбирате какво е „нормално“ е по-добре от това да нямате нищо . Докато изграждате своето хранилище и започвате да се запознавате със средата, можете да приспособите вашите скриптове за улавяне, както е необходимо, за да разрешите евентуални проблеми. Ако имате предимствата на софтуера на трети страни, използвайте тази информация в най-голяма степен и се уверете, че разбирате как се събират и съхраняват изчакванията.