[ Част 1 | Част 2 | Част 3 ]
В част 1 показах как компресирането както на страница, така и на columnstore може да намали размера на таблица от 1TB с 80% или повече. Въпреки че бях впечатлен, че мога да свия таблица от 1TB на 50GB, не бях много доволен от времето, което ми отне (от 2 до 14 часа). С някои съвети, любезно заимствани от хора като Джо Оббиш, Лони Нидерщат, Нико Нойгебауер и други, в тази публикация ще се опитам да направя някои промени в първоначалния си опит за по-добро натоварване. Тъй като обикновеният индекс на columnstore не се компресира по-добре от компресирането на страници на този набор от данни , и отне 13 часа повече, за да стигна до там, ще се съсредоточа единствено върху по-усъвършенстваното решение, използвайки COLUMNSTORE_ARCHIVE компресия.
Някои от проблемите, които според мен са повлияли на производителността, включват следното:
- Лош избор на оформление на файла – Поставих 8 файла в една файлова група, с паралелизъм, но без (или неоптимално) разделяне, пръскайки I/O в множество файлове с безразсъдно изоставяне. За да се справя с това, ще:
- разделете таблицата на 8 дяла (по един на ядро)
- поставете файла с данни на всеки дял в собствена файлова група
- използвайте 8 отделни процеса, за да се присъедините към всеки дял
- използвайте архивна компресия на всички, освен на „активния“ дял
- твърде много малки партиди и неоптимална популация на групи от редове – като обработвах 10 милиона реда наведнъж, попълвах девет групи от редове с хубави, 1 048 576 реда, а след това останалите 562 816 реда щяха да се окажат в друга по-малка група редове. И всякакви неравномерни разпределения, които оставят остатък <102 400 реда, биха вкарали вмъквания в по-малко ефективната структура на делта магазин. За да разпределя редовете по-равномерно и да избягвам делта магазин, ще:
- обработете възможно най-много от данните в точни кратни на 1 048 576 реда
- разпределете ги в 8 дяла възможно най-равномерно
- използвайте размер на партида, по-близък до 10x -> 100 милиона реда
- подреждане на график – въпреки че не проверих за това, възможно е част от забавянето да е причинено от това, че един планировчик поема твърде много работа, а друг планировчик не е достатъчен, поради кръговото обединяване на графика. Сега, когато умишлено ще зареждам данните с 8 maxdop 1 процеса вместо един процес maxdop 8, за да поддържам всички планировчици еднакво заети, ще:
- използвайте съхранена процедура, която се опитва да балансира равномерно между планировчиците (вижте страници 189-191 в Ръководството на SQLCAT за:Relational Engine за вдъхновението зад тази идея)
- активирайте глобален флаг за проследяване 2467 и 2469, както е предупредено в документацията
- задача за компресиране на фоновата колона – беше разточително да позволявам това да работи по време на населението, тъй като така или иначе планирах да възстановя в края. Този път ще:
- деактивирайте тази задача, като използвате глобален флаг за проследяване 634
Премахнах първоначалната функция и схема за дялове и създадох нова, базирана на по-равномерно разпределение на данните. Искам 8 дяла да съвпадат с броя на ядрата и броя на файловете с данни, за да максимизирам „паралелизма на бедния човек“, който смятам да използвам.
Първо, трябва да създадем нов набор от файлови групи, всяка със собствен файл:
ПРОМЕНЯ БАЗА ДАННИ OCopy ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА FG_CCI_Part1; ПРОМЕНИ БАЗА ДАННИ OCopy ДОБАВЯНЕ НА ФАЙЛ (име =N'CCI_Part_1', размер =250000, име на файл ='K:\Data\o_cci_p_1.mdf') КЪМ ФАЙЛОВА ГРУПА FG_CCI_Part1; -- ... още 6 ... ПРОМЕНИ БАЗА ДАННИ OCopy ДОБАВЯНЕ НА ФАЙЛГРУПА FG_CCI_Part8; ПРОМЕНИ БАЗА ДАННИ OCopy ДОБАВЯНЕ НА ФАЙЛ (име =N'CCI_Part_8', размер =250000, име на файл ='K:\Data\o_cci_p_8.mdf') КЪМ ФАЙЛОВА ГРУПА FG_CCI_Part8;
След това погледнах броя на редовете в таблицата:3,754,965,954. За да ги разпространявате точно равномерно в 8 дяла, това би било 469 370 744,25 реда на дял. За да работи добре, нека направим границите на дяла да поемат следващия кратно на 1 048 576 реда. Това е 1,048,576 x 448 = 469,762,048 – който би бил броят на редовете, за които снимаме в първите 7 дяла, оставяйки 466 631 618 реда в последния дял. За да видите действителния OID стойности, които биха послужили като граници за съдържане на оптималния брой редове във всеки дял, изпълних тази заявка срещу оригиналната таблица (тъй като отне 25 минути за изпълнение, бързо се научих да изхвърлям тези резултати в отделна таблица):
;С x AS ( ИЗБЕРЕТЕ OID, rn =ROW_NUMBER() НАД (ПОРЕД ПО OID) ОТ dbo.tblOriginal С (NOLOCK))ИЗБЕРЕТЕ OID, PartitionID =1+(rn/((1048576*448)+1) ) INTO dbo.stage FROM x WHERE rn % (1048576*112) =0;
 Тук можете да разопаковате повече, отколкото бихте очаквали. CTE върши цялата тежка работа, тъй като трябва да сканира цялата таблица от 1,14 TB и да присвои номер на ред на всеки ред . Искам да връщам само всеки
Тук можете да разопаковате повече, отколкото бихте очаквали. CTE върши цялата тежка работа, тъй като трябва да сканира цялата таблица от 1,14 TB и да присвои номер на ред на всеки ред . Искам да връщам само всеки (1048576*112)th ред обаче, тъй като това са моите гранични редове на партидата, това е, което WHERE клаузата прави. Не забравяйте, че искам да разделя работата на партиди, по-близки до 100 милиона реда наведнъж, но също така всъщност не искам да обработвам 469 милиона реда наведнъж. Така че в допълнение към разделянето на данните на 8 дяла, искам да разделя всеки от тези дялове на четири партиди от 117 440 512 (1,048,576*112) редове. Всеки съседен набор от четири партиди принадлежи на един дял, така че PartitionID Извличам просто добавя едно към резултата от текущия номер на ред цяло число разделено на (1,048,576*448) , което гарантира, че границата винаги е в "лявото" множество. След това добавяме едно към резултата, защото в противен случай щяхме да се позоваваме на колекция от дялове, базирана на 0, а никой не иска това.
Добре, това бяха много думи. Вдясно е снимка, показваща (съкратеното) съдържание на stage таблица (щракнете, за да покажете пълния резултат, като подчертаете граничните стойности на дяла).
След това можем да извлечем друга заявка от тази таблица за етапи, която ни показва минималните и максималните стойности за всяка партида във всеки дял, както и допълнителната партида, която не е отчетена (редовете в оригиналната таблица с OID по-голямо от най-високата гранична стойност):
;WITH x AS ( ИЗБЕРЕТЕ OID, PartitionID ОТ dbo.stage),y AS ( SELECT PartitionID, MinID =COALESCE(LAG(OID,1) OVER (РЕД ПО OID),-1)+1, MaxID =OID FROM x UNION ALL SELECT PartitionID =8, MinID =MAX(OID)+1, MaxID =4000000000 -- по-лесно от запомнянето на реалния максимален FROM x)SELECT PartitionID, BatchID =ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID), MinID, MaxID, RowsInRange =CONVERT(int, NULL)INTO dbo.BatchQueueFROM y; -- нека не оставяме това като купчина:СЪЗДАЙТЕ УНИКАЛЕН КЛУСТРИРАН ИНДЕКС PK_bq НА dbo.BatchQueue(PartitionID, BatchID);
Тези стойности изглеждат така:
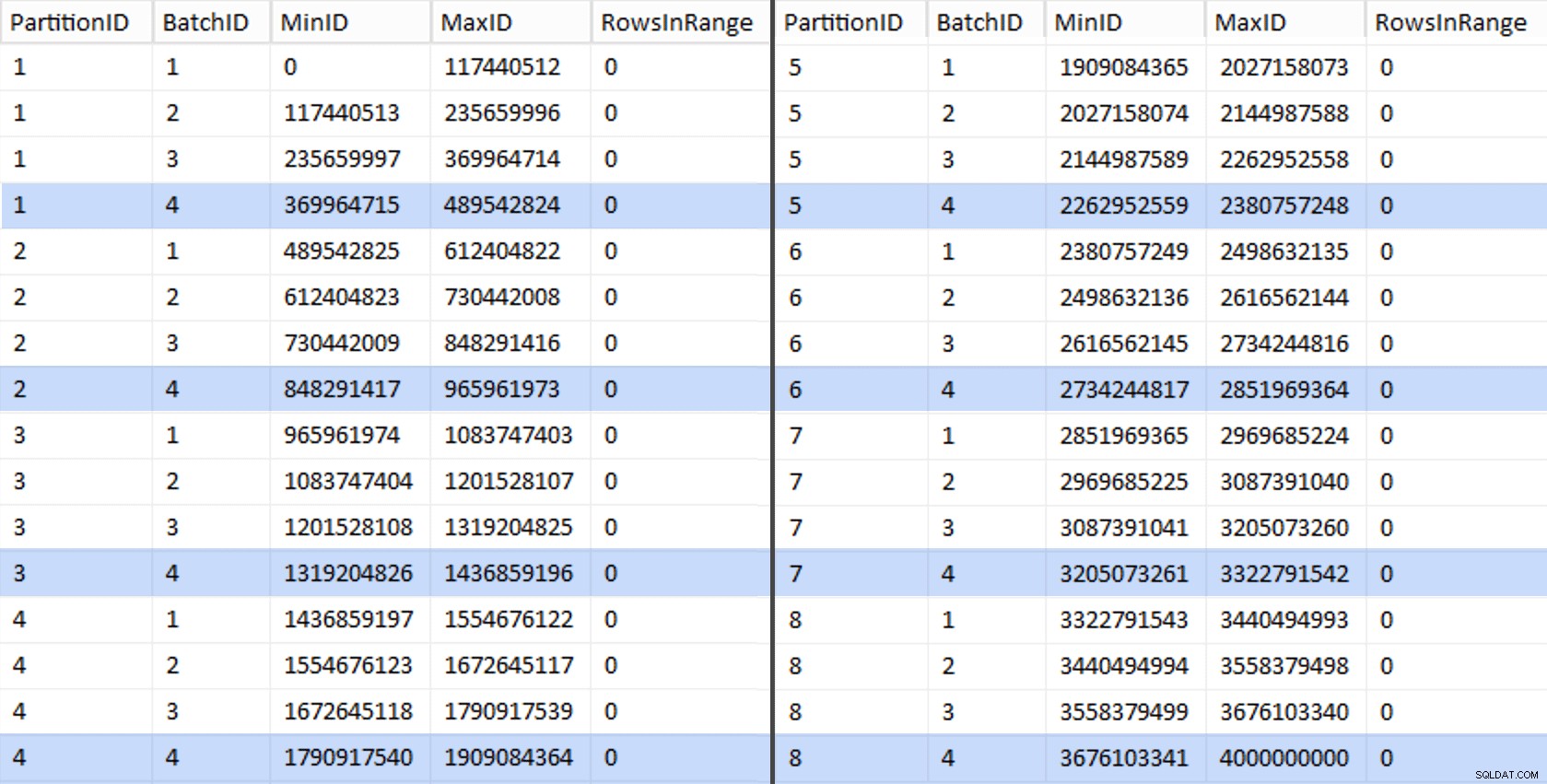
За да тестваме нашата работа, можем да извлечем от там набор от заявки, които ще актуализират BatchQueue с действителен брой редове от таблицата.
DECLARE @sql nvarchar(max) =N''; SELECT @sql +='АКТУАЛИЗИРАНЕ dbo.BatchQueue SET RowsInRange =( ИЗБЕРЕТЕ COUNT(*) ОТ dbo.tblOriginal WITH (NOLOCK) WHERE CostID МЕЖДУ ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) WHER) + MinID) =' + RTRIM(MinID) + ' И MaxID =' + RTRIM(MaxID) + ';'ОТ dbo.BatchQueue; EXEC sys.sp_executesql @sql;
Това отне около 6 минути на моята система. След това можете да изпълните следната заявка, за да покажете, че всяка партида с изключение на последната е в състояние да попълни напълно групи от редове и да не оставя остатък за потенциално използване на делта магазин:
ПРОМЕНЯ ТАБЛИЦА dbo.BatchQueue ДОБАВЯНЕ на DeltaStore AS (RowsInRange % 1048576);
Сега таблицата изглежда така:
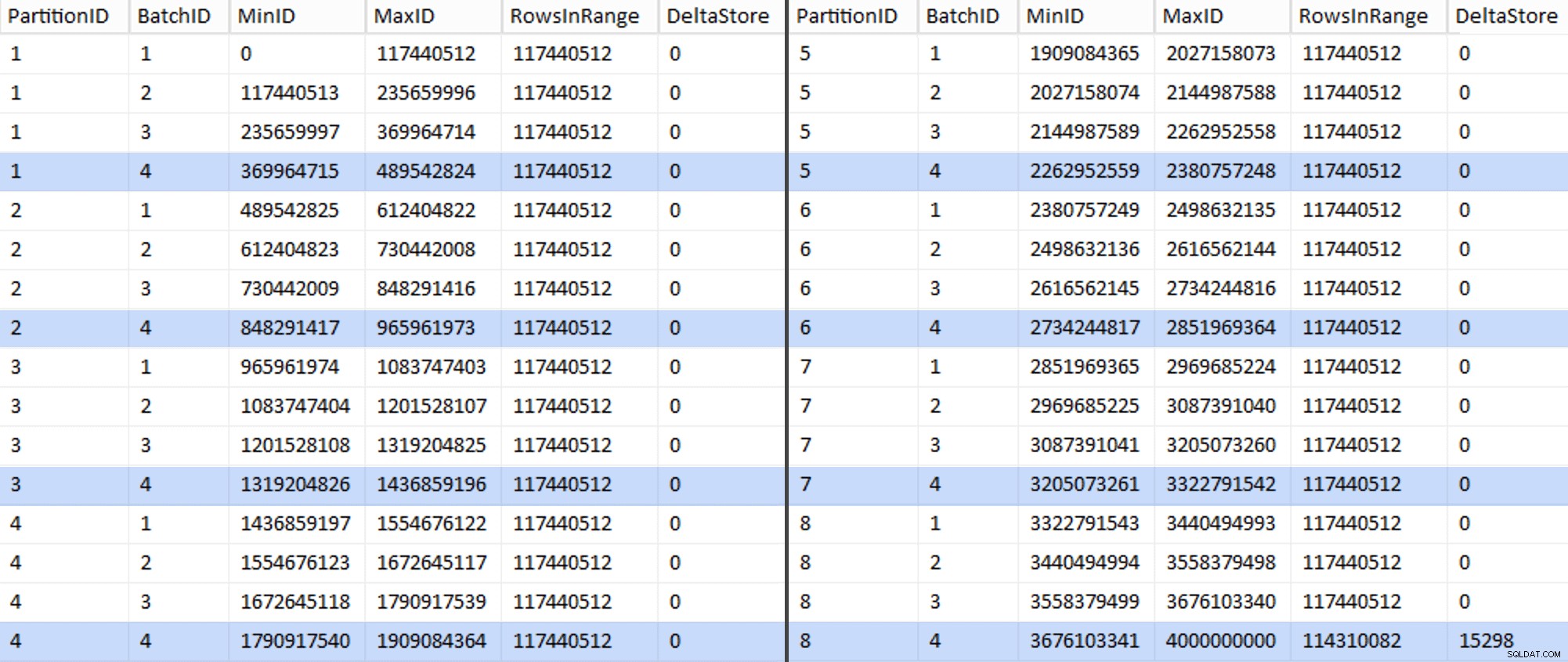
Разбира се, всяка партида има изчислените 117 440 512 милиона реда, с изключение на последния, който, поне в идеалния случай, ще съдържа нашето единствено некомпресирано делта магазин. Вероятно можем да предотвратим и това, като променим само леко размера на партидата за този дял така че и четирите партиди да се изпълняват с еднакъв размер или чрез промяна на броя на партидите, за да се побере друго кратно на 102 400 или 1 048 576. Тъй като това ще изисква получаване на нов OID стойности от основната таблица, добавяйки още 25 минути към усилията ни за миграция, ще оставя този един несъвършен дял да се плъзга — особено след като така или иначе не получаваме пълната полза от компресирането на архива от него.
BatchQueue таблицата започва да показва признаци, че е полезна за обработката на нашите партиди за мигриране на данни към нашата нова, разделена, клъстерирана таблица за columnstore. Което трябва да създадем, сега, когато знаем границите. Има само 7 граници, така че със сигурност можете да направите това ръчно, но аз обичам да карам динамичен SQL да върши работата ми вместо мен:
DECLARE @sql nvarchar(max) =N''; SELECT @sql =N'CREATE PARTITION FUNCTION PF_OID([bigint])КАТО ДИАПАЗОН, ОСТАВЕН ЗА СТОЙНОСТИ ( ' + STRING_AGG(MaxID, ', ') + ');' ОТ dbo.BatchQueue КЪДЕ PartitionID <8 И BatchID =4; PRINT @sql;-- EXEC sys.sp_executesql @sql;
Резултати:
СЪЗДАВАНЕ НА ФУНКЦИЯ НА PARTITION PF_OID([bigint]) КАТО ОБХВАТ, ОСТАВЕН ЗА СТОЙНОСТИ ( 489542824, 965961973, 1436859196, 1909084364, 23807572519);След като това бъде създадено, можем да създадем нашата схема на дялове и да присвоим всеки следващ дял към неговия специален файл:
СЪЗЗДАЙТЕ СХЕМА НА ДЯЛО PS_OID КАТО ДЯЛ PF_OID КЪМ ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8);Сега можем да създадем таблицата и да я подготвим за миграция:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.tblPartitionedCCI( OID bigint НЕ НУЛ, IN1 int НЕ НУЛ, IN2 int НЕ NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL( VC3 varchar(, 128) NOT NULL, VC4 varchar(128) NULL, NM1 число (24,12) NULL, NM2 число (24,12) NULL, NM3 число (24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL , NM4 число (24,12) NULL, IN5 int NULL, NM5 число (24,12) NULL, DT1 дата NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, NUBTLL бит N , NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- трябва да се създаде PK ограничение в схемата на дяловете... ОГРАНИЧЕНИЕ PK_CCI_Part ПЪРВЕН КЛЮЧОВ КЛУСТЕР ВКЛЮЧЕНО PS_OID(OID)); -- ... само за да го пуснете незабавно... ПРОМЕНИ ТАБЛИЦА dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part;GO -- ... за да можем да го заменим с CCI:CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI НА PS_OID(OID );GO -- сега възстановете с компресията, която искаме:ALTER TABLE dbo.tblPartitionedCCI ПОВТОРНО ИЗГРАЖДАНЕ НА PARTITION =ALL WITH ( DATA_COMPRESSION =COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION =COLUMNSTORE ON PARTITIONS);В част 3 допълнително ще конфигурирам
BatchQueueтаблица, изградете процедура за процеси, които да изтласкат данните към новата структура и анализирайте резултатите.[ Част 1 | Част 2 | Част 3 ]