Отдавна съм привърженик на избора на правилния тип данни. Говорих за някои примери в предишна публикация в блога „Лоши навици“, но този уикенд в SQL Saturday #162 (Кеймбридж, Обединеното кралство), темата за използване на DATETIME по подразбиране се появи. В разговор след моето представяне на T-SQL:Лоши навици и най-добри практики потребител заяви, че просто използва DATETIME дори ако се нуждаят само от детайлност до минута или ден, по този начин колоните за дата/час в тяхното предприятие винаги са от един и същ тип данни. Предполагах, че това може да е разточително и че последователността може да не си струва, но днес реших да се заема да докажа теорията си.
TL;DR версия
Моето тестване по-долу разкрива, че със сигурност има сценарии, при които може да искате да обмислите използването на по-слаб тип данни, вместо да се придържате към DATETIME навсякъде. Но е важно да се види къде моите тестове за това сочат обратното и също така е важно да тествате тези сценарии срещу вашата схема, във вашата среда, с хардуер и данни, които са възможно най-верни за производството. Резултатите ви може и почти сигурно ще се различават.
Таблиците на местоназначението
Нека разгледаме случая, когато детайлността е важна само за деня (не ни интересуват часове, минути, секунди). За това можем да изберем DATETIME (като предложения от потребителя) или SMALLDATETIME , или DATE на SQL Server 2008+. Има и два различни типа данни, които исках да разгледам:
- Данни, които биха били вмъкнати приблизително последователно в реално време (напр. събития, които се случват в момента);
- Данни, които ще бъдат вмъкнати на случаен принцип (напр. рождени дати на нови членове).
Започнах с 2 таблици като следната, след което създадох още 4 (2 за SMALLDATETIME, 2 за DATE):
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.BirthDatesRandom_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE TABLE dbo.EventsSequential_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); СЪЗДАВАНЕ НА ИНДЕКС d НА dbo.BirthDatesRandom_Datetime(dt);CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -- След това повторете за DATE и SMALLDATETIME.
И моята цел беше да тествам производителността на пакетно вмъкване по тези два различни начина, както и въздействието върху общия размер на хранилището и фрагментацията и накрая ефективността на заявките за диапазон.
Примерни данни
За да генерирам някои примерни данни, използвах една от моите удобни техники за генериране на нещо смислено от нещо, което не е:изгледите на каталога. В моята система това върна 971 различни стойности за дата/час (общо 1 000 000 реда) за около 12 секунди:
;WITH y AS ( SELECT TOP (1000000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101')) FROM ( SELECT s1.[object_id] % 1000 FROM). sys.all_objects AS s1 КРЪСТО ПРИСЪЕДИНЯВАНЕ sys.all_objects AS s2 ) КАТО x(x) ПОРЪЧАЙТЕ ОТ NEWID()) ИЗБЕРЕТЕ РАЗЛИЧНО d ОТ y;
Поставих тези милиони реда в таблица, за да мога да симулирам последователни/случайни вмъквания, използвайки различни методи за достъп за същите данни от три различни прозореца на сесия:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.Staging( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL);;WITH Staging_Data AS ( SELECT TOP (1000000) dt =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101')) FROM ( SELECT s1.[object_id] % 1000 FROM_object sys.all). AS s1 CROSS JOIN sys.all_objects AS s2 ) AS sd(x) ORDER BY NEWID())INSERT dbo.Staging(source_date) SELECT dt FROM y ORDER BY dt;
Този процес отне малко повече време (20 секунди). След това създадох втора таблица, за да съхранявам същите данни, но разпределени на случаен принцип (за да мога да повторя едно и също разпределение във всички вмъквания).
CREATE TABLE dbo.Staging_Random( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL); INSERT dbo.Staging_Random(source_date) SELECT source_date ОТ dbo.Staging ORDER BY NEWID();
Запитвания за попълване на таблиците
След това написах набор от заявки за попълване на другите таблици с тези данни, като използвах три прозореца на заявки, за да симулирам поне малко паралелност:
ВРЕМЕ НА ИЗЧАКВАНЕ '13:53';ОТИДИ ДЕКЛАРИРАНЕ @d DATETIME2 =SYSDATETIME(); INSERT dbo.{table_name}(dt) -- в зависимост от метода/типа данни SELECT source_date ОТ dbo.Staging[_Random] -- в зависимост от дестинацията WHERE ID % 3 =<0,1,2> -- в зависимост от прозореца на заявка ORDER ПО ИД; ИЗБЕРЕТЕ ДАТА (МИЛИСЕКУНДА, @d, SYSDATETIME()); Както в последната си публикация, аз предварително разширих базата данни, за да предотвратя намеса на резултатите от всякакъв тип събития за автоматично нарастване на файлове с данни. Осъзнавам, че не е напълно реалистично да се извършват вмъквания на милиони редове с един проход, тъй като не мога да предотвратя намесата на активността на журнала за толкова голяма транзакция, но трябва да го прави последователно във всеки метод. Като се има предвид, че хардуерът, с който тествам, е напълно различен от хардуера, който използвате, абсолютните резултати не трябва да са ключов извод, а само относителното сравнение.
(В бъдещ тест ще опитам и това с реални партиди, идващи от регистрационни файлове с относително смесени данни и използване на части от таблицата източник в цикли – мисля, че това също биха били интересни експерименти. И разбира се добавяне компресиране в сместа.)
Резултатите:
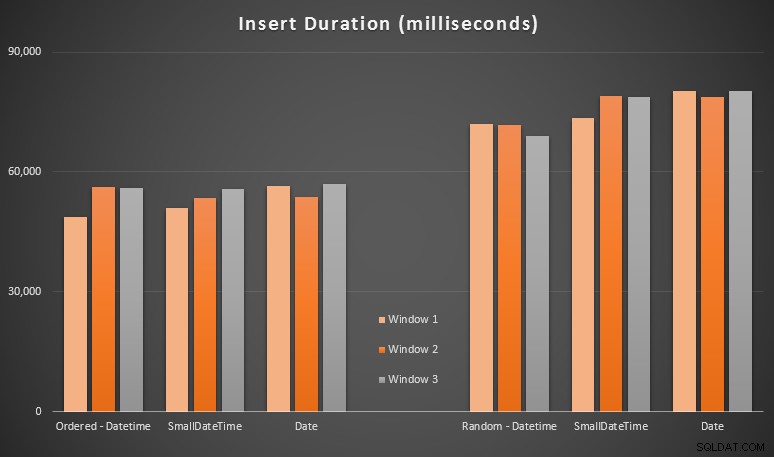
Тези резултати не бяха толкова изненадващи за мен – вмъкването в произволен ред доведе до по-дълги времена на изпълнение, отколкото последователното вмъкване, нещо, което всички можем да върнем към нашите корени на разбирането как работят индексите в SQL Server и как могат да се случат повече „лоши“ разделяния на страници в този сценарий (не наблюдавах специално за разделяне на страници в това упражнение, но това е нещо, което ще разгледам в бъдещи тестове).
Забелязах, че от страна на произволната страна имплицитните преобразувания на входящите данни може да са оказали влияние върху времето, тъй като изглеждат малко по-високи от естествения DATETIME -> DATETIME вложки. Затова реших да създам две нови таблици, съдържащи изходни данни:едната с DATE и един, използващ SMALLDATETIME . Това би симулирало до известна степен правилното преобразуване на вашия тип данни, преди да ги предадете на израза за вмъкване, така че да не се изисква имплицитно преобразуване по време на вмъкването. Ето новите таблици и как са били попълнени:
CREATE TABLE dbo.Staging_Random_SmallDatetime( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID;
Това нямаше ефекта, на който се надявах – моментите бяха сходни във всички случаи. Така че това беше преследване на дива гъска.
Използвано пространство и фрагментация
Изпълних следната заявка, за да определя колко страници са запазени за всяка таблица:
ИЗБЕРЕТЕ име ='dbo.' + OBJECT_NAME([object_id]), pages =SUM(reserved_page_count)FROM sys.dm_db_partition_stats ГРУПА ПО OBJECT_NAME([object_id])ПОРЪЧАЙТЕ ПО страници;
Резултатите:
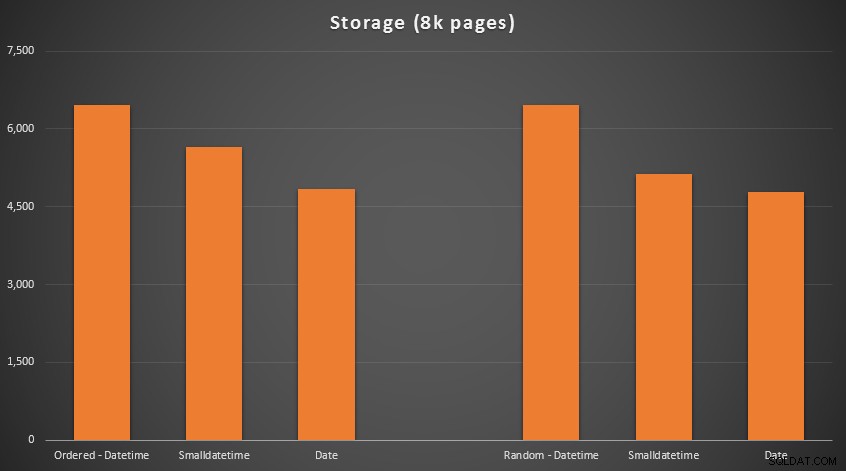
Тук няма ракетна наука; използвайте по-малък тип данни, трябва да използвате по-малко страници. Превключване от DATETIME до DATE постоянно даваше 25% намаление на броя на използваните страници, докато SMALLDATETIME намали изискването с 13-20%.
Сега за фрагментацията и плътността на страниците за неклъстерираните индекси (имаше много малка разлика за клъстерираните индекси):
ИЗБЕРЕТЕ '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('{table_name}'), NULL, NULL_index') NULL, NULL_index') AND NULL_index') AND NULL_index') /предварително>
Резултати:
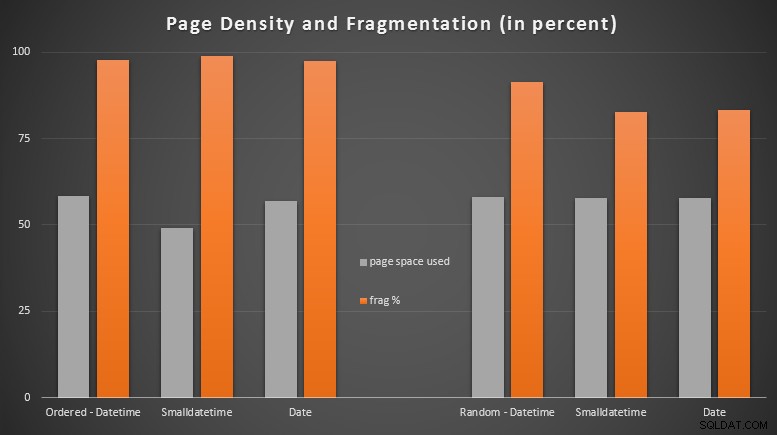
Бях доста изненадан да видя, че подредените данни станаха почти напълно фрагментирани, докато данните, които бяха вмъкнати на случаен принцип, всъщност завършиха с малко по-добро използване на страницата. Отбелязах, че това изисква допълнително разследване извън обхвата на тези специфични тестове, но може да е нещо, което ще искате да проверите, ако имате неклъстерни индекси, които разчитат до голяма степен на последователни вмъквания.
[Онлайн възстановяване на неклъстерираните индекси на всичките 6 таблици се изпълни за 7 секунди, връщайки плътността на страниците до диапазона от 99,5% и намалявайки фрагментацията до под 1%. Но не го стартирах, докато не извърших тестовете на заявката по-долу...]
Тест на заявка за обхват
И накрая, исках да видя въздействието върху времето за изпълнение за прости заявки за диапазон от време спрямо различните индекси, както с присъщата фрагментация, причинена от активността на запис от типа OLTP, така и върху чист индекс, който се възстановява. Самата заявка е доста проста:
ИЗБЕРЕТЕ ТОП (200000) dt ОТ dbo.{table_name} КЪДЕ dt>='20110101' ПОРЪЧАЙТЕ ПО dt;
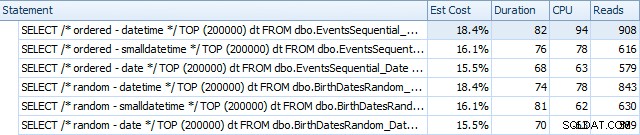
Ето резултатите преди възстановяването на индексите с помощта на SQL Sentry Plan Explorer:
И те се различават леко след реконструкциите:
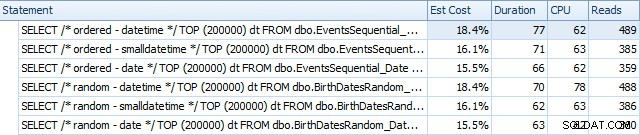
По същество виждаме малко по-висока продължителност и четене за версиите DATETIME, но много малка разлика в процесора. И разликите между SMALLDATETIME и DATE са незначителни в сравнение. Всички заявки имаха опростени планове за заявки като този:

(Търсенето е, разбира се, подредено сканиране на обхват.)
Заключение
Въпреки че, разбира се, тези тестове са доста измислени и биха могли да се възползват от повече пермутации, те показват приблизително това, което очаквах да видя:най-голямото въздействие върху този конкретен избор е върху пространството, заето от неклъстерирания индекс (където изборът на по-слаб тип данни ще със сигурност се възползват) и за времето, необходимо за извършване на вмъквания в произволен, а не последователен ред (където DATETIME има само ръб).
Бих искал да чуя вашите идеи как да подложите избори на типове данни като тези през по-задълбочени и наказващи тестове. Смятам да вляза в повече подробности в бъдещи публикации.