Важно е първо да знаете по кои от колоните искате да групирате и как искате да ги групирате. Ще трябва да знаете това, за да настроите ИЗЯВЛЕНИЕ НА СЛУЧАЙ ще запишем като колона в нашия оператор select. В нашия случай, в група имейли, които имат достъп до нашия сайт, искаме да знаем колко кликвания отчита всеки доставчик на имейл от началото на август. Също така бихме искали да сравним отделен доставчик на имейл услуги с останалите. За този пример ще използваме Gmail като наш доставчик на услуги.
В нашия SELECT изявление, ще ни трябва DATE , ДОСТАВЧИК и SUM от КЛИКВАНЕ към нашия сайт. Можем да ги получим от ТЕСТОВИТЕ Е-МАЙЛИ таблица в нашия източник на данни.
DATE колоната е доста ясна:
"Test E Mails"."Created_Date" AS "DATE
И тъй като търсим SUM от КЛИКВАНЕ , ще трябва да изпратим SUM функция над CLICKS колона.
SUM("Test E Mails"."Clicks") AS "CLICKS"
Това ни отвежда до нашия ИЗЛОЖЕНИЕ НА СЛУЧАЙ . Знаем от документацията на PostgreSQL, че CASE ИЗЯВЛЕНИЕ или условно изявление трябва да бъде подредено по следния начин:
CASE
WHEN condition THEN result
[WHEN ...]
[ELSE result]
END
Първото ни и единствено в този случай условие е, че искаме да знаем всички имейл адреси, предоставени от Gmail, за да бъдат отделени от всеки друг доставчик на имейл. Така че единственият WHEN е:
WHEN "Test E Mails"."Provider" = 'Gmail' THEN 'Gmail'
И изявлението else ще бъде „Друго“ за всеки друг доставчик на имейл адрес. Получената таблица на този CASE STATEMENT само със съответните имейли. Ще изглежда така:
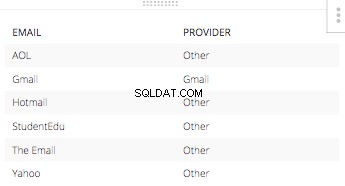
Когато разделите и трите колони за един ИЗБЕРЕТЕ ИЗЯВЛЕНИЕ и добавете останалите необходими части, за да изградите SQL заявка, всичко се оформя по-долу.
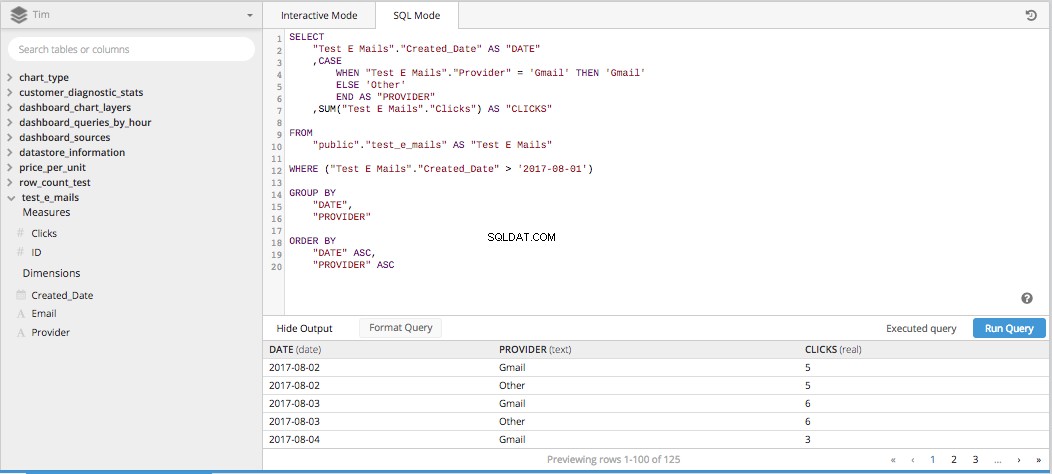
След това след добавяне на ОСВЕТНИ ДАННИ Влезте в тръбопровода за данни, ще получим таблица, правилно подредена в правилния формат, за да настроим линейна диаграма, показваща как се сравняват кликванията във времето.
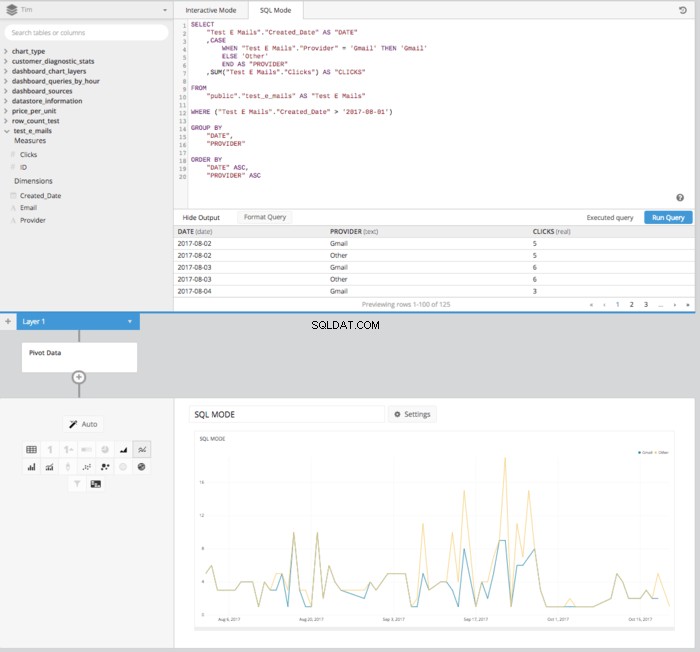
При използването на Chartio можем да направим всичко по-горе, без да пишем SQL, но използвайки Data Explorer и функциите на Data Pipeline. След като изградим основната ни заявка, за да извлечем всички колони, ще ни трябва СУМА НА КЛИКВАНИЯ , ДАТА и ИМЕЙЛ АДРЕС можем да използваме Data Pipeline, за да манипулираме тези данни след SQL. Първо, нека изградим заявката.
Плъзнете „Колоната за кликвания“ в полето с мерки и я обобщете по ОБЩА СУМА от кликванията в колоната, след което я означете отново с „КЛИКВАНИ“.
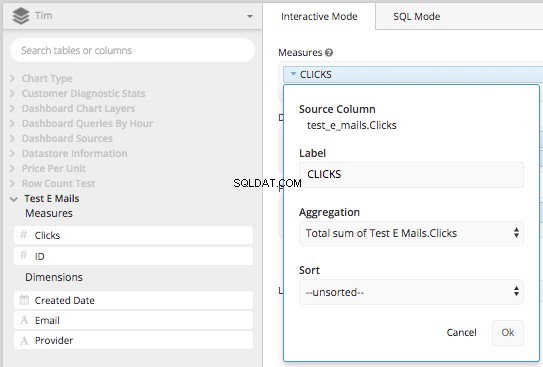
След това плъзнете „Дата на създаване“ и „Доставчик“ в полето за измерения и ги означете отново като „Дата“ и „Доставчик на имейл“.>КЪДЕ клауза) да бъде всичко след 2017-08-01. Това ефективно ще изгради всичко, от което се нуждаем в основна заявка, за да създадем CASE STATEMENT направихме по-горе, в Data Pipeline на Chartio.
Добавяне на ИЗЛОЖЕНИЕ НА СЛУЧАЙ pipeline step ни позволява да зададем условията за WHEN и ELSE точно както направихме преди, без да се налага да въвеждате целия синтаксис на SQL.
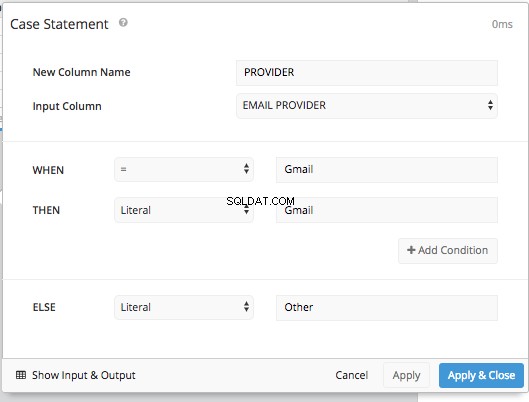
След това след скриване на оригиналната колона „Доставчик“ и използване на ПРЕПОРЪЧВАНЕ НА КОЛОНИ стъпка и ОСВЕТНИ ДАННИ стъпка ще получим същата подредба на таблицата, която получихме в SQL режим и можем да представим същата таблица, която направихме в SQL режим.
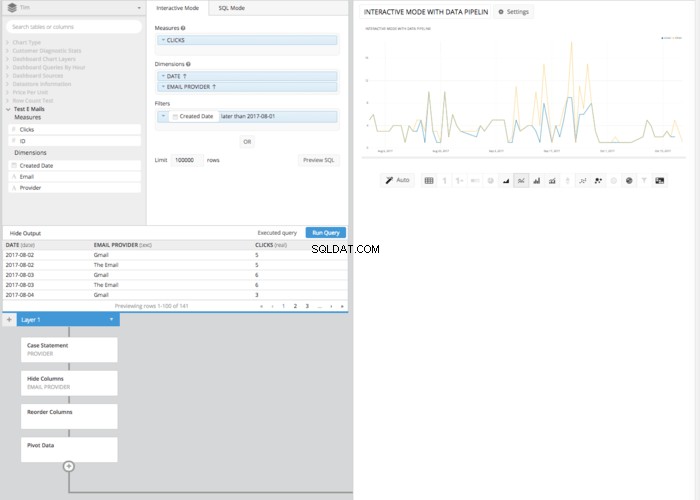
Въпреки че може да отнеме няколко щраквания и стъпки повече, отколкото в SQL режим, получената линейна диаграма, направена в интерактивен режим, не изисква познаване на SQL синтаксиса. Вместо това всичко, което е необходимо, е основно разбиране на включените принципи. Това е друг пример за това как Chartio помага да се постави силата на данните в ръцете на всеки, независимо от познанията на SQL.



