В предишна статия обсъждахме модела на звездната схема. Схемата снежинка е до схемата звезда по отношение на нейното значение в моделирането на хранилища за данни. Той е разработен на базата на звездната схема и предлага някои предимства пред своя предшественик. Но тези предимства имат цена. В тази статия ще обсъдим кога и как да използваме схемата на снежинката.
Схема на снежинката
Името на схемата снежинка идва от факта, че таблиците с размери се разклоняват и изглеждат нещо като снежинка. Когато разгледаме модела по-горе, ще забележим, че това е таблица с факти, заобиколена от няколко таблици с измерения, някои от които извършват гореспоменатото разклонение. За разлика от звездната схема, таблиците с размери в схемата снежинка могат да имат свои собствени категории.
Основната идея зад схемата на снежинката е, че таблиците с размери са напълно нормализирани. Всяка таблица с измерения може да бъде описана с една или повече справочни таблици. Всяка справочна таблица може да бъде описана с една или повече допълнителни справочни таблици. Това се повтаря, докато моделът се нормализира напълно. Процесът на нормализиране на таблици с размери на звездна схема се нарича снежинка.
Ще чуете много за нормализирането в тази статия. Какво е нормализиране? По принцип това е организиране на база данни по начин, който минимизира съкращенията и защитава целостта на данните. Вижте тази публикация, за да научите повече за нормализирането и денормализирането.
Пример за схема на снежинка:Модел на продажби
По-рано използвахме звездна схема за моделиране на измислен търговски отдел – това би било подобно на витрина с данни, използвана за проследяване на продажбите и резултатите. Моделът има пет измерения:продукт , време , магазин , продажби тип и служител . В fact_sales таблица, цена и количество се съхраняват и групират въз основа на стойности в таблици с измерения. За освежаване вижте модела за продажби със звездна схема по-долу:
Ето същия модел, организиран като схема на снежинка:
dim_employee и dim_sales_type таблиците с размери са абсолютно същите като в модела на звездната схема, защото вече са нормализирани.
От друга страна, приложихме правила за нормализиране към останалите таблици с измерения.


dim_product таблицата с размери от звездната схема е разделена на две таблици в модела снежинка. dim_product_type таблицата беше добавена за препратка към типа на съвпадението в dim_product маса. Използвайки това, избегнахме някои проблеми с целостта на данните.
Логично е да предположим, че вече ще имаме всички имена на продукти и свързаните с тях типове, вмъкнати като част от ETL процеса, но да предположим, че трябва да добавим още имена и типове продукти. В схема със звезда можем по погрешка да въведем грешен тип продукт в таблицата. В схемата на снежинката:
- Ако срещнем ново име на тип продукт, можем да добавим нов тип продукт и след това да свържем този тип с новодобавен запис. Това обаче може да доведе до въвеждането на грешна информация от потребителя, точно както в схемата със звезда.
- Можем да проверим дали името на продукта, което искаме да добавим, вече съществува. Ако е така, можем да получим неговия ID; ако не, ще се появи предупреждение, което ни пита дали искаме да добавим нов продукт и свързан тип.

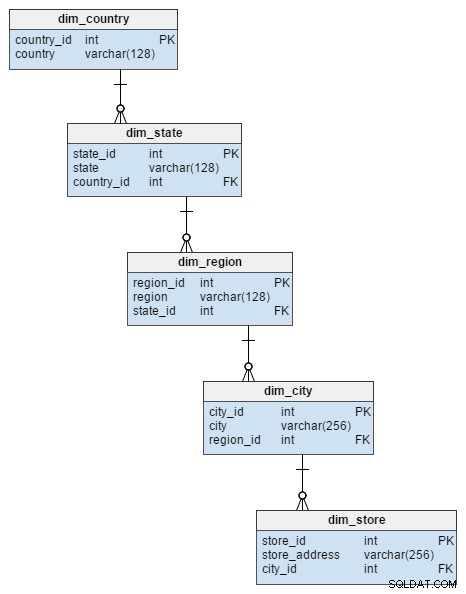
dim_store таблицата с размери от звездната схема е представена от 5 таблици в схемата снежинка. Те разделят атрибутите за град, регион, щат и държава, които са били съхранени в dim_store маса. Нормализирането на тази таблица не само избегна риска за целостта на данните, но и спести малко дисково пространство.
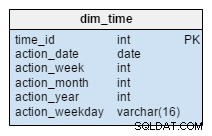
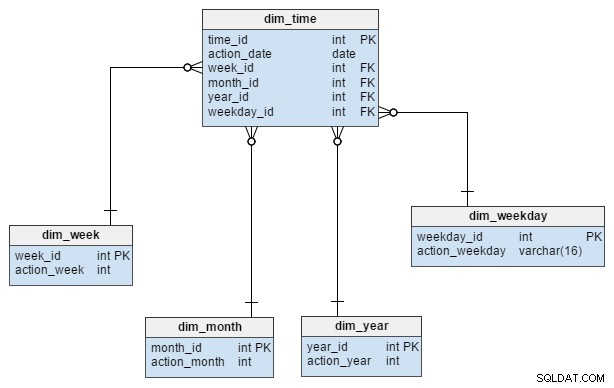
dim_time измерението е представено с пет таблици. Можем да мислим за dim_week , dim_month , dim_year и dim_weekday таблици като речници, които описват dim_time маса.
dim_week , dim_month , dim_year и dim_weekday таблиците са четири различни йерархии, използвани за описание на нашето времево измерение. Бихме могли да добавим още измерения като четвъртини или други свързани таблици, ако имаме нужда от тях. В този пример dim_month е речник, съдържащ 12 месеца; само от това измерение няма как да разберем към коя година принадлежи този месец; това е функцията на dim_year маса.
Пример за схема на снежинка:Модел на поръчки за доставка
Другата витрина с данни, която обсъдихме, беше за поръчки за доставка. Идеята е да се съхраняват и обобщават всички данни за поръчките за доставки за следните четири измерения:продукт , време , доставчик и служител . Още веднъж ще разгледаме съответната звездна схема:
Преобразувайки това в схемата на снежинката, получаваме следния модел:
Същите правила за нормализиране като тези, описани за модела на продажби, бяха използвани за dim_product , dim_time и dim_supplier таблици с размери.
Предимства и недостатъци на схемата за снежинки
Имадве основни предимства към схемата на снежинката:
- По-добро качество на данните (данните са по-структурирани, така че проблемите с целостта на данните са намалени)
- Използва се по-малко дисково пространство в сравнение с денормализиран модел
Най-забележими недостатък за модела снежинка е, че изисква по-сложни заявки. Тези заявки, с увеличения им брой присъединявания, могат значително да намалят производителността.
Ще пренапишем същата заявка, използвана в статията за звездната схема за модела на продажбите на схемата снежинка. Ето заявката, необходима за връщане на количеството на всички видове продукти от телефонен тип, продадени в магазините в Берлин през 2016 г.:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
Схемата на звездната звезда
Схемата на звездата е комбинация от схемите на снежинката и звездата. Можем да го разглеждаме като схема на снежинка, която има денормализирани таблици с размери. Когато се използва правилно, схемата на звездната звезда може да даде подход на най-доброто от двата свята. Очевидно частта със снежинка на модела трябва да спести дисково пространство, докато частта със звезда трябва да подобри производителността.
Моделът по-горе е основно модел на снежинка с денормализирано dim_time маса. Тъй като тази схема намалява броя на необходимите присъединявания на заявка, тя може да подобри производителността. От друга страна, няма да загубим значително количество от дисковото пространство, тъй като повечето от атрибутите на таблицата и атрибутите на външния ключ споделят int тип.
Схема на галактиката
В съхраняването на данни схемата на галактиката е, когато две или повече таблици с факти споделят една или повече таблици с измерения. Една от причините да използвате тази схема е да спестите дисково пространство. Създадохме примерна галактична схема по-долу:
Тук имаме две таблици с факти, fact_sales и fact_supply_order , които директно споделят таблици с три измерения:dim_product , dim_employee и dim_time . Забележете, че дори dim_store и dim_supplier споделяйте същата таблица за търсене, dim_city .
Ще спестим място по този начин, но трябва да имаме предвид няколко неща, преди да обединим две витрини с данни (в този случай поръчки за продажби и доставки) в една галактична схема:
- Има ли някаква логика да се присъедините към тях? Напр. И двата витрина с данни биха ли се използвали от един и същи отдел?
- Сигурни ли сме, че се нуждаем от точно еднакви размери и гранулиране за двата витрина с данни?
Схемата снежинка често се използва при моделиране на данни. Може да е правилният избор в ситуации, когато дисковото пространство е по-важно от производителността. Ако искаме баланс между спестяване на място и производителност, можем да използваме схемата на звездната звезда. И все пак, правилното прилягане за всеки конкретен проблем зависи от много параметри. Това е една от областите в ИТ, където можем да „играем“ с фактори, за да намерим най-доброто решение.