В първата част на този блог покрихме подробно описание на внедряването на MySQL InnoDB Cluster с пример за това как приложенията могат да се свързват с клъстера чрез специален порт за четене/запис.
В това ръководство за операцията ще покажем примери за това как да наблюдавате, управлявате и мащабирате клъстера InnoDB като част от текущите операции по поддръжка на клъстера. Ще използваме същия клъстер, който разположихме в първата част на блога. Следната диаграма показва нашата архитектура:
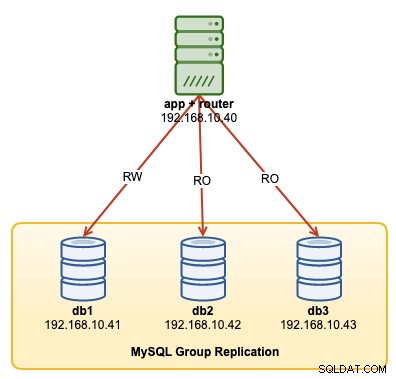
Имаме MySQL групова репликация с три възела и един сървър на приложения, работещ с MySQL рутер. Всички сървъри работят на Ubuntu 18.04 Bionic.
Опции за команди на клъстер MySQL InnoDB
Преди да продължим с някои примери и обяснения, добре е да знаете, че можете да получите обяснение на всяка функция в MySQL клъстер за компонент на клъстер, като използвате функцията help(), както е показано по-долу:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()Следният списък показва наличните функции на MySQL Shell 8.0.18 за MySQL Community Server 8.0.18:
- addInstance(instance[, options])- Добавя екземпляр към клъстера.
- checkInstanceState(instance) – Проверява състоянието на gtid на екземпляра по отношение на клъстера.
- describe() – Опишете структурата на клъстера.
- disconnect() – Прекъсва всички вътрешни сесии, използвани от обекта на клъстера.
- dissolve([options]) – Деактивира репликацията и дерегистрира ReplicaSets от клъстера.
- forceQuorumUsingPartitionOf(instance[, password]) – Възстановява клъстера от загуба на кворум.
- getName() – Извлича името на клъстера.
- помощ([член])- Предоставя помощ за този клас и неговите членове.
- опции([опции]) – Изброява опциите за конфигурация на клъстера.
- rejoinInstance(instance[, options]) – Присъединява отново екземпляр към клъстера.
- removeInstance(instance[, options])- Премахва екземпляр от клъстера.
- rescan([options])- Повторно сканиране на клъстера.
- resetRecoveryAccountsPassword(options) – Нулирайте паролата на акаунтите за възстановяване на клъстера.
- setInstanceOption(екземпляр, опция, стойност) – Променя стойността на опция за конфигурация в член на клъстера.
- setOption(опция, стойност) – Променя стойността на опция за конфигурация за целия клъстер.
- setPrimaryInstance(екземпляр) – Избира конкретен член на клъстера като нов основен.
- състояние([опции]) – Опишете състоянието на клъстера.
- switchToMultiPrimaryMode()- Превключва клъстера в режим на няколко основни.
- switchToSinglePrimaryMode([екземпляр])- Превключва клъстера в едноосновен режим.
Ще разгледаме повечето от наличните функции, които да ни помогнат да наблюдаваме, управляваме и мащабираме клъстера.
Наблюдение на MySQL InnoDB клъстерни операции
Състояние на клъстера
За да проверите състоянието на клъстера, първо използвайте командния ред на обвивката MySQL и след това се свържете като example@sqldat.com{one-of-the-db-nodes}:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");След това създайте обект, наречен "cluster" и го декларирайте като глобален обект "dba", който осигурява достъп до функциите за администриране на клъстер InnoDB с помощта на AdminAPI (вижте документи за MySQL Shell API):
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>След това можем да използваме името на обекта, за да извикаме функциите на API за обект "dba":
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}Изходът е доста дълъг, но можем да го филтрираме, като използваме структурата на картата. Например, ако искаме да видим забавянето на репликацията само за db3, можем да направим следното:
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Имайте предвид, че забавянето на репликацията е нещо, което ще се случи при груповата репликация, в зависимост от интензивността на запис на основния член в набора от реплика и променливите group_replication_flow_control_*. Тук няма да разглеждаме подробно тази тема. Вижте тази публикация в блога, за да разберете по-нататък ефективността на груповата репликация и контрола на потока.
Друга подобна функция е функцията describe(), но тази е малко по-проста. Той описва структурата на клъстера, включително цялата му информация, ReplicaSets и екземпляри:
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}По подобен начин можем да филтрираме изхода на JSON, използвайки структура на картата:
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryКогато първичният възел се повреди (в този случай е db1), изходът върна следното:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Обърнете внимание на състоянието OK_NO_TOLERANCE, при което клъстерът все още работи и работи, но не може да толерира повече отказ, след като един от три възела не е наличен. Основната роля е поета от db2 автоматично и връзките към базата данни от приложението ще бъдат пренасочени към правилния възел, ако се свържат през MySQL Router. След като db1 се върне онлайн, трябва да видим следното състояние:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Показва, че db1 вече е наличен, но служи като вторичен с разрешено само за четене. Основната роля все още се присвоява на db2, докато нещо не се обърка на възела, където автоматично ще бъде прехвърлена към следващия наличен възел.
Проверка на състоянието на екземпляра
Можем да проверим състоянието на MySQL възел, преди да планираме да го добавим в клъстера, като използваме функцията checkInstanceState(). Той анализира изпълнените GTID на екземпляр с изпълнените/изчистените GTID в клъстера, за да определи дали екземплярът е валиден за клъстера.
Следното показва състоянието на екземпляра на db3, когато е бил в самостоятелен режим, преди част от клъстера:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Ако възелът вече е част от клъстера, трябва да получите следното:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Наблюдавайте всяко "запитващо" състояние
С MySQL Shell вече можем да използваме вградената команда \show и \watch, за да наблюдаваме всяка административна заявка в реално време. Например, можем да получим стойността в реално време на свързаните нишки, като използваме:
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';Или вземете текущия списък с процеси на MySQL:
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTСлед това можем да използваме команда \watch, за да стартираме отчет по същия начин като командата \show, но тя опреснява резултатите на редовни интервали, докато не отмените командата с помощта на Ctrl + C. Както е показано на следните примери:
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTИнтервалът за опресняване по подразбиране е 2 секунди. Можете да промените стойността, като използвате флага --interval и посочите стойност от 0,1 до 86400.
Операции за управление на клъстер MySQL InnoDB
Първично превключване
Първичният екземпляр е възелът, който може да се счита за лидер в група за репликация, който има способността да изпълнява операции за четене и запис. Само един първичен екземпляр на клъстер е разрешен в режим на единична първична топология. Тази топология е известна още като набор от реплики и е препоръчителният режим на топология за групова репликация със защита срещу конфликти при заключване.
За да извършите превключване на първичен екземпляр, влезте в един от възлите на базата данни като потребител на администратора на клъстера и посочете възела на базата данни, който искате да популяризирате, като използвате функцията setPrimaryInstance():
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Току-що популяризирахме db1 като нов основен компонент, заменяйки db2, докато db3 остава като вторичен възел.
Изключване на клъстера
Най-добрият начин да изключите грациозно клъстера, като първо спрете услугата MySQL Router (ако тя работи) на сървъра на приложения:
$ myrouter/stop.shГорната стъпка осигурява защита на клъстера срещу случайни записи от приложенията. След това изключете един възел на базата данни наведнъж, като използвате стандартната команда за спиране на MySQL или извършете изключване на системата, както желаете:
$ systemctl stop mysqlСтартиране на клъстера след изключване
Ако вашият клъстер страда от пълно прекъсване или искате да стартирате клъстера след чисто изключване, можете да се уверите, че е преконфигуриран правилно, като използвате функцията dba.rebootClusterFromCompleteOutage(). Той просто връща клъстер обратно ОНЛАЙН, когато всички членове са ОФЛАЙН. В случай, че клъстерът е спрял напълно, екземплярите трябва да бъдат стартирани и едва тогава може да се стартира клъстерът.
По този начин се уверете, че всички MySQL сървъри са стартирани и работят. На всеки възел на базата данни вижте дали процесът mysqld работи:
$ ps -ef | grep -i mysqlСлед това изберете един сървър на база данни да бъде основен възел и се свържете с него чрез MySQL shell:
MySQL|JS> shell.connect("example@sqldat.com:3306");Изпълнете следната команда от този хост, за да ги стартирате:
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Ще ви бъдат представени следните въпроси:
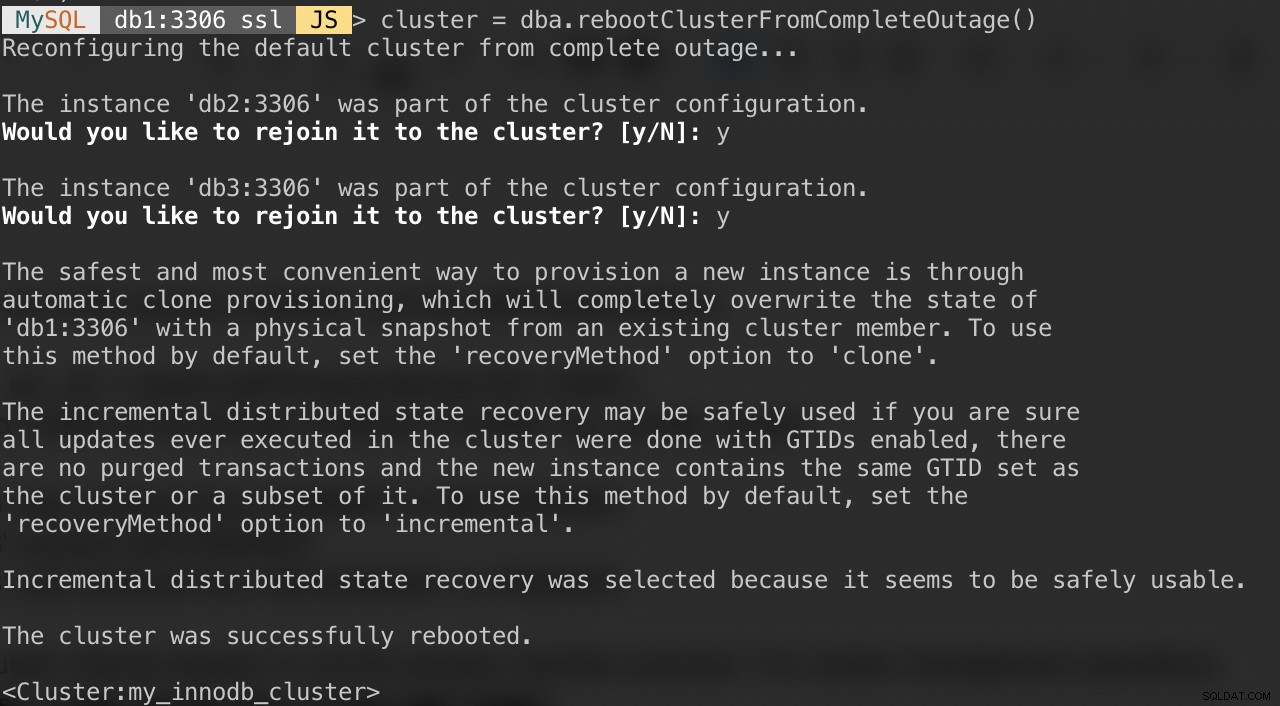
След като горното приключи, можете да проверите състоянието на клъстера:
MySQL|db1:3306 ssl|JS> cluster.status()В този момент db1 е основният възел и записващият. Останалите ще бъдат второстепенните членове. Ако искате да стартирате клъстера с db2 или db3 като основен, можете да използвате функцията shell.connect(), за да се свържете със съответния възел и да извършите rebootClusterFromCompleteOutage() от този конкретен възел.
След това можете да стартирате услугата MySQL Router (ако не е стартирана) и да оставите приложението да се свърже отново с клъстера.
Задаване на опции за член и клъстер
За да получите опциите за целия клъстер, просто изпълнете:
MySQL|db1:3306 ssl|JS> cluster.options()Гореното ще изброи глобалните опции за набора от реплика, както и индивидуалните опции за член в клъстера. Тази функция променя опцията за конфигурация на InnoDB Cluster във всички членове на клъстера. Поддържаните опции са:
- clusterName:низова стойност за дефиниране на името на клъстера.
- exitStateAction:низова стойност, указваща действието за изходно състояние на репликацията на групата.
- memberWeight:целочислена стойност с процентно тегло за автоматичен първичен избор при отказ.
- failoverConsistency:стойност на низ, указваща гаранциите за последователност, които клъстерът предоставя.
- последователност: стойност на низ, указваща гаранциите за последователност, които клъстерът предоставя.
- expelTimeout:целочислена стойност за дефиниране на периода от време в секунди, през който членовете на клъстера трябва да изчакат неотговарящ член, преди да го извадят от клъстера.
- autoRejoinTries:целочислена стойност за дефиниране на колко пъти даден екземпляр ще се опита да се присъедини отново към клъстера, след като бъде изгонен.
- disableClone:булева стойност, използвана за деактивиране на използването на клонинг в клъстера.
Подобно на друга функция, изходът може да бъде филтриран в структура на картата. Следната команда ще изброи само опциите за db2:
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]Можете също да получите горния списък с помощта на функцията help():
MySQL|db1:3306 ssl|JS> cluster.help("setOption")Следната команда показва пример за задаване на опция, наречена memberWeight на 60 (от 50) за всички членове:
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.Можем също така да извършваме управление на конфигурацията автоматично чрез MySQL Shell, като използваме функцията setInstanceOption() и предаваме хоста на базата данни, съответно името и стойността на опцията:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)Поддържаните опции са:
- exitStateAction: стойност на низ, указваща действието за изходно състояние на репликацията на групата.
- memberWeight:целочислена стойност с процентно тегло за автоматичен първичен избор при отказ.
- autoRejoinTries:целочислена стойност за дефиниране на колко пъти даден екземпляр ще се опита да се присъедини отново към клъстера, след като бъде изгонен.
- маркирайте идентификатор на низ на екземпляра.
Преминаване към режим с няколко основни/единично първичен режим
По подразбиране InnoDB Cluster е конфигуриран с един първичен, само един член, който може да извършва четене и запис в даден момент. Това е най-безопасният и препоръчан начин за стартиране на клъстера и подходящ за повечето натоварвания.
Въпреки това, ако логиката на приложението може да се справи с разпределени записи, вероятно е добра идея да преминете към мулти-първичен режим, където всички членове в клъстера могат да обработват четене и запис по едно и също време. За да превключите от едноосновен към многоосновен режим, просто използвайте функцията switchToMultiPrimaryMode():
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Потвърдете с:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}В многоосновен режим всички възли са първични и могат да обработват четене и запис. Когато изпращате нова връзка през MySQL рутер на порт с един запис (6446), връзката ще бъде изпратена само до един възел, както в този пример, db1:
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Ако приложението се свърже към порта за мулти записване (6447), връзката ще бъде балансирана на натоварването чрез кръгов алгоритъм за всички членове:
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Както можете да видите от изхода по-горе, всички възли са в състояние да обработват четене и запис с read_only =OFF. Можете да разпространявате безопасни записи до всички членове, като се свържете към порта за множество записвания (6447) и изпращате конфликтните или тежки записи към порта за единичен запис (6446).
За да превключите обратно към единичен първичен режим, използвайте функцията switchToSinglePrimaryMode() и посочете един член като основен възел. В този пример избрахме db1:
MySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.В този момент db1 вече е основният възел, конфигуриран с деактивиран само четене, а останалата част ще бъде конфигурирана като вторична с активирана само за четене.
Операции за мащабиране на клъстер MySQL InnoDB
Увеличаване (Добавяне на нов DB възел)
Когато добавяте нов екземпляр, първо трябва да се осигури възел, преди да му бъде разрешено да участва с групата за репликация. Процесът на осигуряване ще се обработва автоматично от MySQL. Също така можете първо да проверите състоянието на екземпляра дали възелът е валиден за присъединяване към клъстера, като използвате функцията checkInstanceState(), както беше обяснено по-горе.
За да добавите нов DB възел, използвайте функцията addInstances() и посочете хоста:
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Следното е това, което бихте получили, когато добавите нов екземпляр:
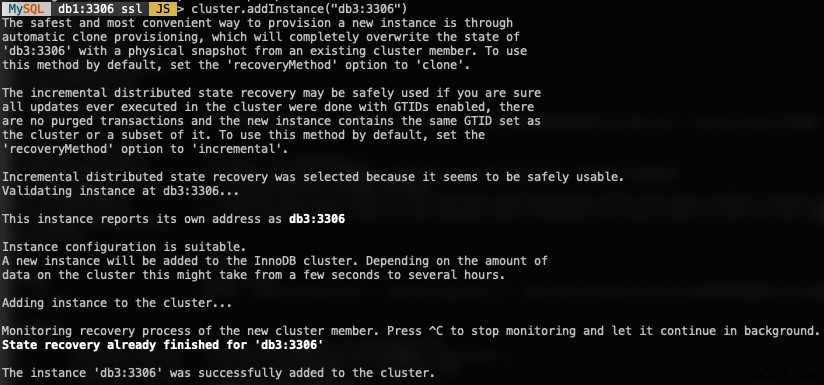
Проверете новия размер на клъстера с:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router автоматично ще включи добавения възел, db3 в комплекта за балансиране на натоварването.
Намаляване (премахване на възел)
За да премахнете възел, свържете се с някой от възлите на DB с изключение на този, който ще премахнем и използвайте функцията removeInstance() с името на екземпляра на базата данни:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")Следното е това, което бихте получили, когато премахнете екземпляр:
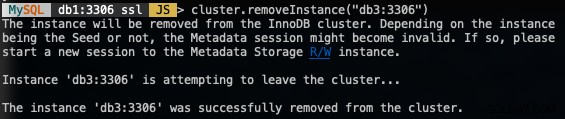
Проверете новия размер на клъстера с:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router автоматично ще изключи премахнатия възел, db3 от набора за балансиране на натоварването.
Добавяне на ново подчинено устройство за репликация
Можем да мащабираме клъстера InnoDB с подчинени реплики на асинхронна репликация от всеки от възлите на клъстера. Подчинен е слабо свързан към клъстера и ще може да се справи с тежък товар, без да влияе на производителността на клъстера. Подчинения може също да бъде копие на живо на базата данни за целите на възстановяване след бедствие. В многоосновен режим можете да използвате подчинения като специален MySQL процесор само за четене, за да намалите работното натоварване при четене, да извършите операция за анализ или като специален сървър за архивиране.
На подчинения сървър изтеглете най-новия конфигурационен пакет на APT, инсталирайте го (изберете MySQL 8.0 в съветника за конфигурация), инсталирайте ключа APT, актуализирайте реполиста и инсталирайте MySQL сървъра.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellПроменете конфигурационния файл на MySQL, за да подготвите сървъра за подчинен сървър за репликация. Отворете конфигурационния файл чрез текстов редактор:
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfИ добавете следните редове:
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Рестартирайте MySQL сървъра на подчинения, за да приложите промените:
$ systemctl restart mysqlНа един от сървърите на InnoDB Cluster (избрахме db3), създайте подчинен потребител за репликация и последван от пълен дъмп на MySQL:
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlПрехвърлете дъмп файла от db3 към подчинения:
$ scp dump.sql example@sqldat.com:~И извършете възстановяването на подчинения:
$ mysql -uroot -p < dump.sqlС master-data=1, нашият MySQL dump файл автоматично ще конфигурира изпълнената и изчистена стойност на GTID. Можем да го проверим със следното изявление на подчинения сървър след възстановяването:
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Изглежда добре. След това можем да конфигурираме връзката за репликация и да стартираме нишките за репликация на подчинения:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Проверете състоянието на репликация и се уверете, че следното състояние връща „Да“:
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...В този момент нашата архитектура сега изглежда така:
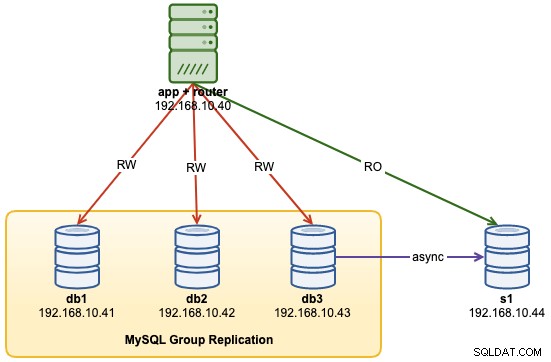
Чести проблеми с MySQL InnoDB клъстери
Изчерпване на паметта
Когато използвахме MySQL Shell с MySQL 8.0, постоянно получавахме следната грешка, когато екземплярите бяха конфигурирани с 1GB RAM:
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)Надстройването на RAM на всеки хост до 2 GB RAM реши проблема. Очевидно компонентите на MySQL 8.0 изискват повече RAM, за да работят ефективно.
Загубена връзка с MySQL сървър
In case the primary node goes down, you would probably see the "lost connection to MySQL server error" when trying to query something on the current session:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.
Заключение
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).