В последната си публикация демонстрирах, че при малки обеми, оптимизиран за паметта TVP може да осигури значителни ползи за производителността на типичните модели на заявки.
За да тествам в малко по-висок мащаб, направих копие на SalesOrderDetailEnlarged таблица, която разширих до приблизително 5 000 000 реда благодарение на този скрипт от Джонатан Кехайяс (блог | @SQLPoolBoy)).
ПУСКАНЕ ТАБЛИЦА dbo.SalesOrderDetailEnlarged;ИЗБИРАЙТЕ ИЗБЕРЕТЕ * В dbo.SalesOrderDetailEnlarged ОТ AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4 973 997 реда СЪЗДАВАНЕ НА КЛУСТРИРАН ИНДЕКС PK_SODE НА dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Също така създадох три версии на тази таблица в паметта, всяка с различен брой кофи (ловене на „сладко място“) – 16 384, 131 072 и 1 048 576. (Можете да използвате по-закръглени числа, но те така или иначе се закръгляват до следващата степен на 2.) Пример:
СЪЗДАДЕТЕ ТАБЛИЦА [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- и _131K и _1MM( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] (2_Latin SQLATECHNumber] (2_5NUL) [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [числова ](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL ПЪРВИЧЕН КЛЮЧ НЕКЛУСТРИРАН ХЕШ ( [SalesOrderID], [SalesOrderDetailID] ) СЪС ( BUCKET AND BUCKET_COUNT) 1048576) С ( MEMORY_OPTIMIZED =ON , DURABILITY =SCHEMA_AND_DATA );GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged;GO
Забележете, че промених размера на кофата от предишния пример (256). Когато съставяте таблицата, искате да изберете „сладкото място“ за размера на сегмента – искате да оптимизирате хеш индекса за търсене на точки, което означава, че искате възможно най-много кофи с възможно най-малко редове във всяка кофа. Разбира се, ако създадете ~5 милиона кофи (тъй като в този случай, може би не е много добър пример, има ~5 милиона уникални комбинации от стойности), ще имате някои компромиси с използване на паметта и събиране на боклук. Ако обаче се опитате да напълните ~5 милиона уникални стойности в 256 кофи, също ще изпитате някои проблеми. Във всеки случай тази дискусия надхвърля обхвата на моите тестове за тази публикация.
За да тествам спрямо стандартната таблица, направих подобни съхранени процедури, както в предишните тестове:
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.SODE_InMemory @InMemory dbo.InMemoryTVP ЧЕТЕНЕ САМО ЗАПОЧНЕТЕ ЗАДАДЕТЕ NOCOUNT ON; ДЕКЛАРИРАНЕ @tn NVARCHAR(25); SELECT @tn =CarrierTrackingNumber ОТ dbo.SalesOrderDetailEnlarged КАТО sode WHERE EXIST (ИЗБЕРЕТЕ 1 ОТ @InMemory КАТО t WHERE sode.SalesOrderID =t.Item);ENDGO СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.SODE_Classic dbo.ClassIC ОТНОВО ЗАДАВАТЕ ДЕКЛАРИРАНЕ @tn NVARCHAR(25); SELECT @tn =CarrierTrackingNumber ОТ dbo.SalesOrderDetailEnlarged AS sode WHERE EXIST (ИЗБЕРЕТЕ 1 ОТ @Classic AS t WHERE sode.SalesOrderID =t.Item);ENDGO
Така че първо, за да разгледате плановете за, да речем, 1000 реда, които се вмъкват в променливите на таблицата, и след това стартирайте процедурите:
DECLARE @InMemory dbo.InMemoryTVP;INSERT @InMemory SELECT TOP (1000) SalesOrderID ОТ dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP;INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic =@Classic;EXEC dbo.SODE_InMemory @InMemory =@InMemory;
Този път виждаме, че и в двата случая оптимизаторът е избрал клъстерно търсене на индекс спрямо базовата таблица и вложени цикли, присъединени към TVP. Някои показатели за разходите са различни, но иначе плановете са доста сходни:
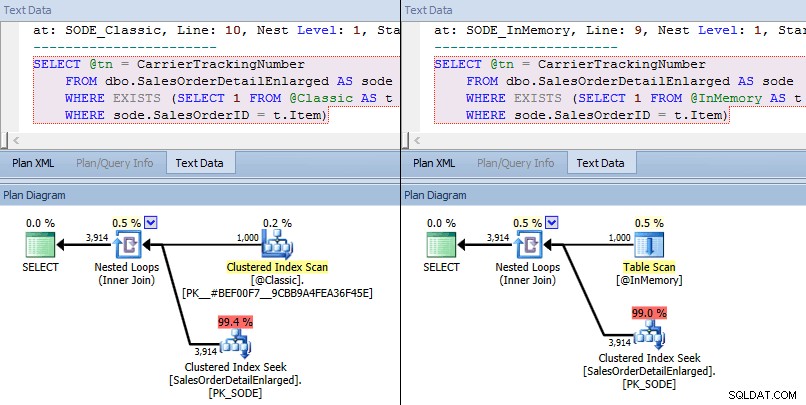 Подобни планове за TVP в паметта срещу класически TVP в по-висок мащаб
Подобни планове за TVP в паметта срещу класически TVP в по-висок мащаб
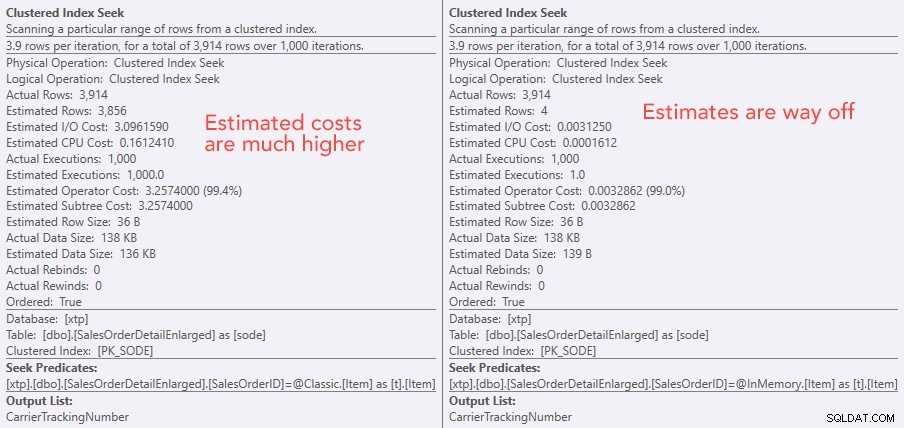 Сравняване на разходите за оператор за търсене – класически отляво, In-Memory отдясно
Сравняване на разходите за оператор за търсене – класически отляво, In-Memory отдясно
Абсолютната стойност на разходите кара да изглежда, че класическият TVP би бил много по-малко ефективен от TVP в паметта. Но се чудех дали това ще е вярно на практика (особено след като цифрата за прогнозен брой екзекуции вдясно изглеждаше съмнителна), така че, разбира се, проведох някои тестове. Реших да проверя срещу 100, 1000 и 2000 стойности, които да бъдат изпратени на процедурата.
DECLARE @values INT =100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP;DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID ОТ dbo.SalesOrderDetailEnlarged ГРУПА ПО SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) ИЗБЕРЕТЕ Елемент ОТ @Classic; ДЕКЛАРИРАНЕ @i INT =1; ИЗБЕРЕТЕ SYSDATETIME(); WHILE @i <=10000BEGIN EXEC dbo.SODE_Classic @Classic =@Classic; SET @i +=1; END SELECT SYSDATETIME(); SET @i =1; WHILE @i <=10000BEGIN EXEC dbo.SODE_InMemory @InMemory =@InMemory; SET @i +=1;END SELECT SYSDATETIME();
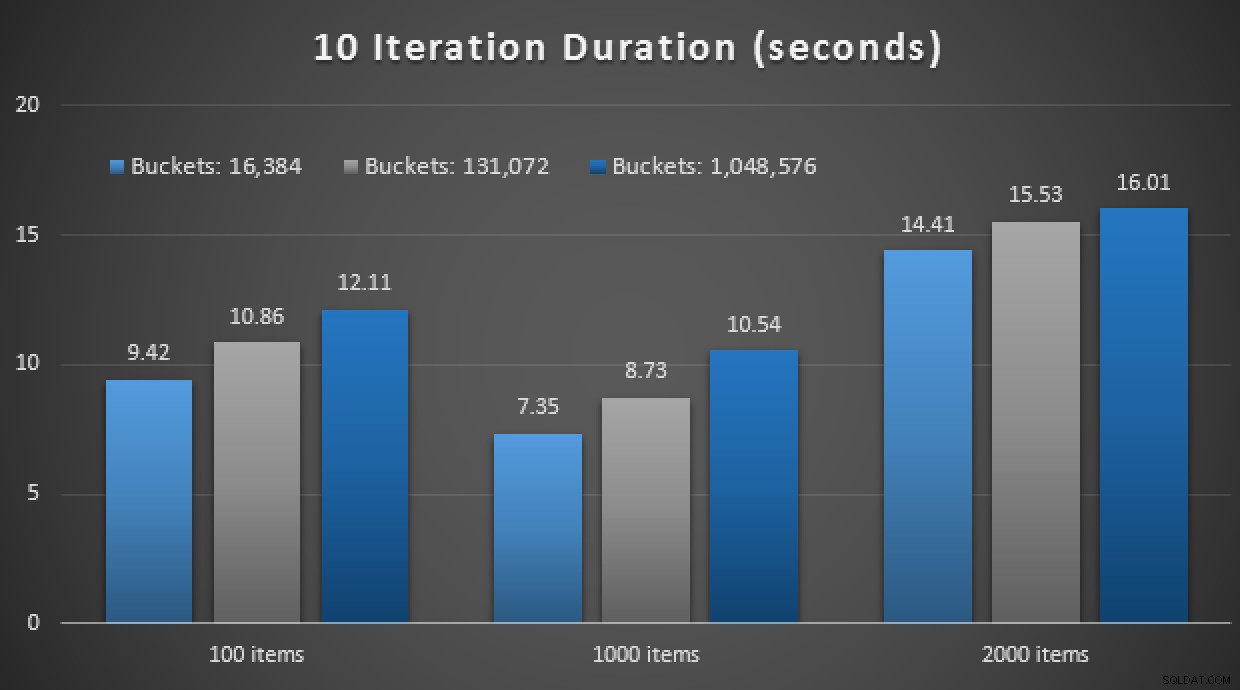
Резултатите от производителността показват, че при по-голям брой търсения на точки, използването на TVP в паметта води до леко намаляваща възвръщаемост, като всеки път е малко по-бавна:
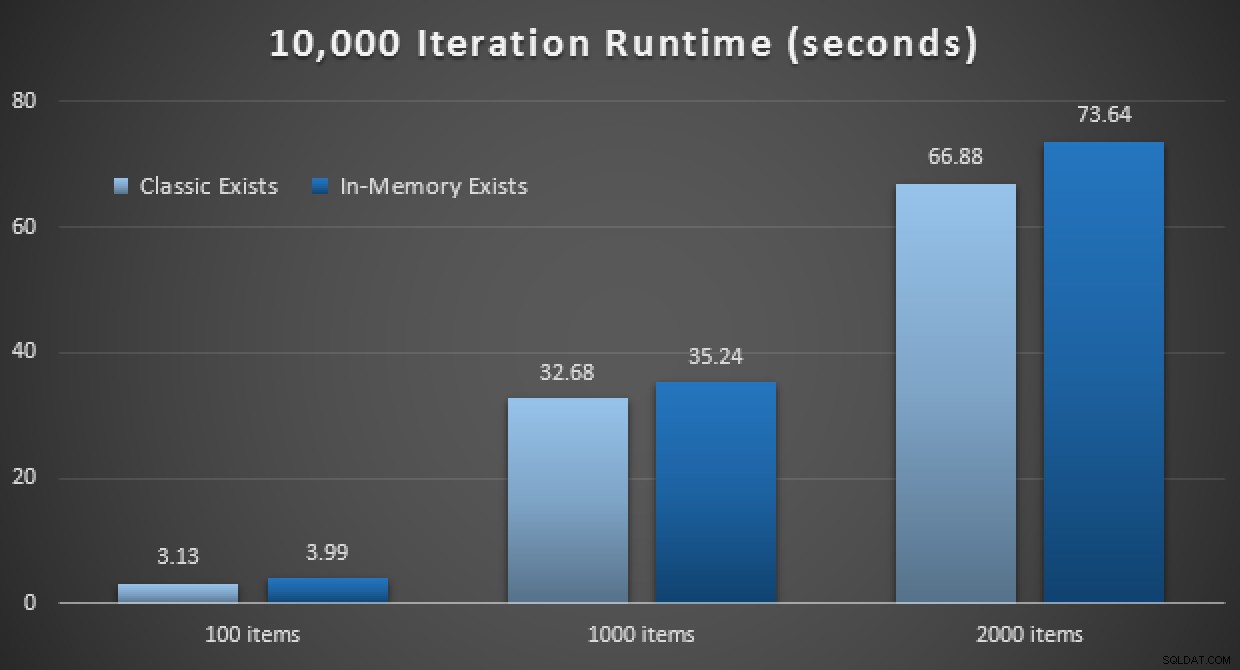
Резултати от 10 000 екзекуции с помощта на класически и в памет TVPs
Така че, противно на впечатлението, което може би сте направили от предишната ми публикация, използването на TVP в паметта не е непременно от полза във всички случаи.
По-рано също разгледах компилираните нативно съхранени процедури и таблици в паметта, в комбинация с TVP в паметта. Може ли това да направи разлика тук? Спойлер:абсолютно не. Създадох три процедури като тази:
СЪЗДАВАНЕ НА ПРОЦЕДУРА [dbo].[SODE_Native_InMem_16K] -- и _131K и _1MM @InMemory dbo.InMemoryTVP САМО ЧЕТЕНЕ С NATIVE_COMPILATION, SCHEMABINDING, EXECUTE КАТО СОБСТВЕНИК КАТО BEGIN ATOMIC' SHOT engl. ДЕКЛАРИРАНЕ @tn NVARCHAR(25); SELECT @tn =CarrierTrackingNumber FROM dbo.SalesOrderDetailEnlarged_InMem_16K КАТО sode -- и _131K и _1MM INNER JOIN @InMemory AS t -- тук не е разрешено СЪЩЕСТВУВАНЕ НА sode.SalesOrderID =t.Item;ENDGO;ENDGOДруг спойлер:не успях да изпълня тези 9 теста с брой повторения от 10 000 – отне твърде много време. Вместо това прегледах и изпълних всяка процедура 10 пъти, проведох този набор от тестове 10 пъти и взех средната стойност. Ето резултатите:
Резултати от 10 изпълнения с използване на TVP в паметта и съхранени нативно компилирани процедуриКато цяло този експеримент беше доста разочароващ. Само като погледнем абсолютната величина на разликата, с таблица на диска, средното извикване на съхранената процедура беше завършено средно за 0,0036 секунди. Въпреки това, когато всичко използваше технологии в паметта, средното извикване на съхранената процедура беше 1,1662 секунди. Ох . Много вероятно е току-що избрал лош случай на използване за демонстрация като цяло, но тогава изглеждаше, че е интуитивен „първи опит“.
Заключение
Има още много за тестване около този сценарий и имам още публикации в блога, които да следвам. Все още не съм идентифицирал оптималния случай на употреба за TVP в паметта в по-голям мащаб, но се надявам, че тази публикация служи като напомняне, че въпреки че решението изглежда оптимално в един случай, никога не е безопасно да се приеме, че е еднакво приложимо към различни сценарии. Точно така трябва да се подходи към In-Memory OLTP:като решение с тесен набор от случаи на употреба, които абсолютно трябва да бъдат валидирани, преди да бъдат внедрени в производството.