Докато Джеф Атууд и Джо Селко изглежда смятат, че цената на GUID не е голяма работа (вижте публикацията в блога на Джеф, „Първични ключове:ID срещу GUID“ и тази дискусионна тема, озаглавена „Identity Vs. Uniqueidentifier“), други експерти – по-конкретно експертите по индекси и архитектура, фокусиращи се върху пространството на SQL Server – са склонни да не са съгласни. Например, Кимбърли Трип разглежда някои подробности в публикацията си „Дисковото пространство е евтино – НЕ В това е важното!”, където тя обяснява, че въздействието не е само върху дисковото пространство и фрагментацията, но по-важното е върху размера на индекса и паметта отпечатък.
Това, което казва Кимбърли, е наистина вярно – постоянно се натъквам на оправданието „дисковото пространство е евтино“ за GUID (пример от миналата седмица). Има и други оправдания за GUID, включително необходимостта от генериране на уникални идентификатори извън базата данни (и понякога преди действително създаването на реда) и необходимостта от уникални идентификатори в отделни разпределени системи (и когато диапазоните на идентичност не са практични). Но наистина искам да разсея мита, че GUID не струват толкова много, защото струват, и трябва да претеглите тези разходи във вашето решение.
Започнах тази мисия да тествам производителността на различни размери на ключове, като се имат предвид едни и същи данни в същия брой редове, със същите индекси и приблизително същото работно натоварване (преиграването на *точното* същото работно натоварване може да бъде доста предизвикателно). Исках не само да измеря основните неща като размера на индекса и фрагментацията на индекса, но и ефектите, които те имат в бъдеще, като например:
- въздействие върху използването на буферен пул
- честота на „лоши“ разделяния на страници
- общо въздействие върху реалистичната продължителност на натоварването
- въздействие върху средното време на изпълнение на отделните заявки
- въздействие върху продължителността на изпълнение на след задействания
- въздействие върху използването на tempdb
Ще използвам различни техники, за да изследвам тези данни, включително разширени събития, проследяване по подразбиране, свързани с tempdb DMV и SQL Sentry Performance Advisor.
Настройка
Първо, създадох милион клиенти, които да поставя в начална таблица, използвайки някои вградени метаданни на SQL Server; това ще гарантира, че "случайните" клиенти ще се състоят от едни и същи естествени данни по време на всеки тест.
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.CustomerSeeds( rn INT ПЪРВИЧЕН КЛУСТРИРАН, Име NVARCHAR(64), Фамилия NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERT dbo.CustomerSeeds С (TABLOCKX) (rn, Firstname, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() НАД (ПОРЪЧКА ПО n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) ОТ ( ИЗБЕРЕТЕ fn, ln, em, a, r =ROW_NUMBER() НАД (РАЗДЕЛЯНЕ ПО em ПОРЪЧКА ПО em) ОТ ( SELECT TOP (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c. име, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =СЛУЧАЙ, КОГАТО c.name КАТО '%y%' ТОГАВА 0 ДРУГО 1 КРАЙ ОТ sys.all_objects КАТО o КРЪСТО ПРИСЪЕДИНЕНЕ към sys.all_columns КАТО c ПОРЪЧКА ОТ NEWID() ) КАТО x ) КАТО y КЪДЕТО r =1 ГРУПА ПО fn, ln, em ПОРЪЧАЙТЕ ПО n) AS z ПОРЪЧАЙТЕ ПО rn;GO ИЗБЕРЕТЕ ТОП (10) * ОТ dbo.CustomerSeeds ПОРЪЧАЙТЕ ПО rn;GO
Вашият пробег може да варира, но в моята система тази популация отне 86 секунди. Десет представителни реда (щракнете за увеличаване):
 Примерни клиенти
Примерни клиенти
След това имах нужда от таблици, за да съхранявам началните данни за всеки случай на употреба, с няколко допълнителни индекса, за да симулирам някаква реалност, и измислих кратки суфикси, за да улесня всички видове диагностика по-късно:
| тип данни | по подразбиране | компресия | наставка за случаи на използване |
|---|---|---|---|
| INT | ИДЕНТИЧНОСТ | няма | I |
| INT | ИДЕНТИЧНОСТ | страница + ред | Ic |
| ГОЛЯМ | ИДЕНТИЧНОСТ | няма | B |
| ГОЛЯМ | ИДЕНТИЧНОСТ | страница + ред | Bc |
| УНИКАЛЕН ИДЕНТИФИКАТОР | NEWID() | няма | G |
| УНИКАЛЕН ИДЕНТИФИКАТОР | NEWID() | страница + ред | Gc |
| УНИКАЛЕН ИДЕНТИФИКАТОР | NEWSEQUENTIALID() | няма | S |
| УНИКАЛЕН ИДЕНТИФИКАТОР | NEWSEQUENTIALID() | страница + ред | Sc |
Таблица 1:Случаи на употреба, типове данни и суфикси
Всичките осем таблици са направени от един и същ шаблон (просто бих променил коментарите, за да съответстват на случая на употреба, и заменя $use_case$ със съответния суфикс от таблицата по-горе):
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), Име NVARCHAR(64) NOT NULL, Фамилия NVARCHAR(64) EMail NOT NNULL Активен BIT NOT NULL DEFAULT 1, Създаден DATETIME NOT NULL DEFAULT SYSDATETIME(), Актуализиран DATETIME NULL, ОГРАНИЧЕНИЕ C_PK_Customers_$use_case$ ПРАВИЛЕН КЛЮЧ (CustomerID)) --WITH (DATA_COMPRESSION =PAGE)QUEE;CREATE dtomuse_case_case. Customers_$use_case$(EMail) --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Active_Customers_$use_case$ НА dbo.Customers_$use_case$(FirstName, Lastname, EMail) WHERE Active =1 --WISGOC PAGE COMPANY =DATA_COMPRES; ИНДЕКС C_Name_Customers_$use_case$ НА dbo.Customers_$use_case$(Фамилия, Име) ВКЛЮЧВА (ИМЕЙЛ) --С (DATA_COMPRESSION =PAGE);GOСлед като таблиците бяха създадени, продължих да попълвам таблиците и да измервам много от показателите, за които споменах по-горе. Рестартирах услугата SQL Server между всеки тест, за да съм сигурен, че всички започват от една и съща базова линия, че DMV ще бъдат нулирани и т.н.
Неоспорени вложки
Моята крайна цел беше да запълня таблицата с 1 000 000 реда, но първо исках да видя въздействието на типа данни и компресията върху необработените вмъквания без спор. Генерирах следната заявка – която ще попълни таблицата с първите 200 000 контакта, 2000 реда наведнъж – и я изпълних срещу всяка таблица:
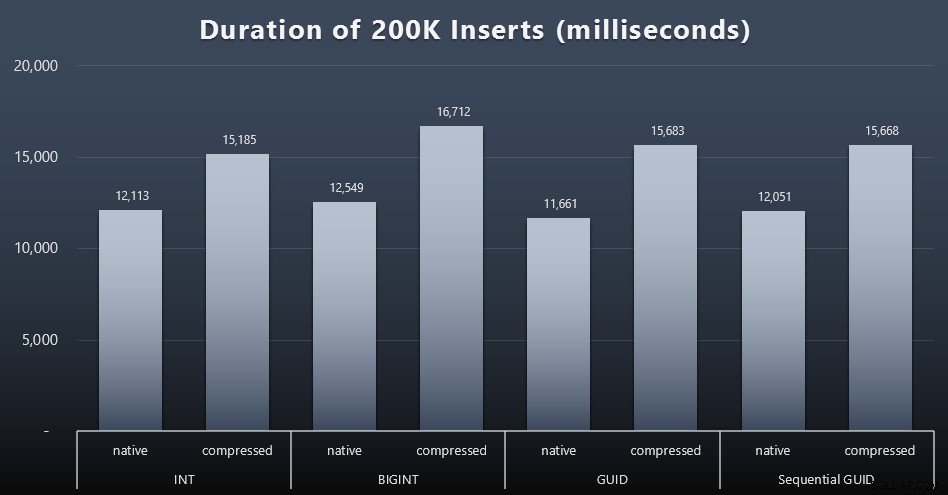
DECLARE @i INT =1;WHILE @i <=100BEGIN INSERT dbo.Customers_$use_case$(FirstName, LastName, Email, Active) SELECT First Name, LastName, Email, Active FROM dbo.CustomerSeeds AS c ПОРЪЧКА ОТ rn 2000 * (@i-1) ИЗВЛЕЧВАНЕ НА РЕДОВЕ СЛЕДВАЩИ 2000 РЕДА САМО; SET @i +=1; КРАЙРезултати (щракнете за увеличаване):
Всеки случай отне около 12 секунди (без компресия) и 16 секунди (с компресия), без ясен победител в нито един режим на съхранение. Ефектът от компресията (главно върху режийните разходи на процесора) е доста последователен, но тъй като това се изпълнява на бърз SSD, влиянието на I/O от различните типове данни е незначително. Всъщност компресията срещу BIGINT изглежда имаше най-голямо въздействие (и това има смисъл, тъй като всяка една стойност под 2 милиарда ще бъде компресирана).
По-спорно работно натоварване
След това исках да видя как едно смесено работно натоварване ще се конкурира за ресурси и като цяло ще се представи срещу всеки тип данни. Затова създадох тези процедури (заменяйки
$use_case$и$data_type$подходящо за всеки тест):-- произволни единични актуализации на данни в повече от един индексСЪЗДАВАНЕ НА ПРОЦЕДУРА [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN SET NOCOUNT ON; АКТУАЛИЗАЦИЯ dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- чете ("пагинация") - поддържа множество сортове-- използвайте динамичен SQL за проследяване на статистиките на заявката поотделно СЪЗДАВАТЕ ПРОЦЕДУРА [dbo].[Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT CustomerID, First Name, LastName, Email, Active, Created, Updated FROM dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET ((@pn-1)*@ ps) ИЗВЛЕЧВАНЕ НА РЕДОВЕ СЛЕДВАЩ @ps САМО РЕДОВЕ;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGOСлед това създадох работни места, които ще извикват тези процедури многократно, с леки закъснения, а също и – едновременно – завършват попълването на останалите 800 000 контакта. Този скрипт създава всички 32 задания и също така отпечатва изход, който може да се използва по-късно за извикване на всички задания за конкретен тест асинхронно:
ИЗПОЛЗВАЙТЕ msdb; ИЗПОЛЗВАЙТЕ ДЕКЛАРИРАЙТЕ @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); ДЕКЛАРИРАЙТЕ @jobs TABLE(име SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(name, cmd) VALUES( N'Произволно работно натоварване за актуализиране', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BEGIN SELECT TOP (1) @CustomerID =CustomerID ОТ dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@WAIT0CustomerID:0DELAY ''0CustomerID:0 :01''; SET @i +=1; END'),( N'Попълване на клиенти', N'SET QUOTED_IDENTIFIER ON; ДЕКЛАРИРАНЕ @i INT =101; ДОКАТО @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (Първо име, фамилия, имейл, активен) ИЗБЕРЕТЕ Име, фамилия, имейл, активен ОТ dbo.CustomerSeeds КАТО c ПОРЪЧАЙ ПО rn ОТМЕСТВАНЕ 2000 * (@i-1) РЕДОВЕ ИЗВЛЕЧВАТ САМО СЛЕДВАЩИТЕ 2000 РЕДА; ИЗЧАКАЙТЕ:00 ''00 01''; SET @i +=1; END'),( N'Натоварване на страници 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- сортиране по CustomerID SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; ИЗЧАКВАНЕ ЗАБАВЯНЕ ''00:00:01''; SET @i +=2; END'),( N'Натоварване на страници 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); ДОКАТО @i <=1001 BEGIN -- сортиране по фамилно име, име SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''LastName, FirstName'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WAITFOR DELAY ''00:00:01''; SET @i +=2; END'); ДЕКЛАРИРАНЕ @n SYSNAME, @c NVARCHAR(MAX); ДЕКЛАРИ c КУРСОР ЛОКАЛЕН FAST_FORWARD FORSELECT име =t.use_case + N' ' + j.name, cmd =REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) FROM @typ AS t CROSS JOIN @jobs AS j; ОТВОРЕНО c; ИЗВЛЕЧВАНЕ c В @n, @c; WHILE @@FETCH_STATUS <> -1BEGIN АКО СЪЩЕСТВУВА (ИЗБЕРЕТЕ 1 ОТ msdb.dbo.sysjobs WHERE name =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'IDs'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(local)'; ПЕЧАТ 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; ИЗВЛЕЧИ c В @n, @c;ENDИзмерването на времето за работа във всеки случай беше тривиално – можех да проверя началните/крайните дати в
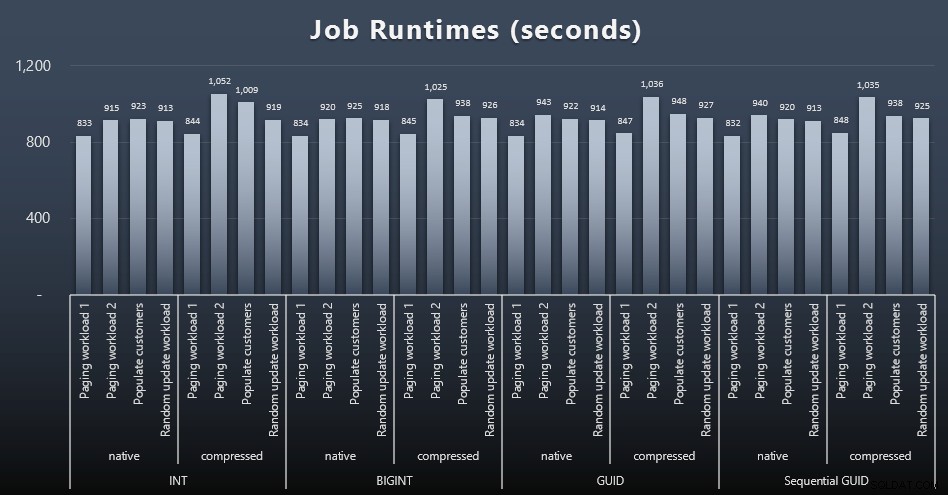
msdb.dbo.sysjobhistoryили ги изтеглете от SQL Sentry Event Manager. Ето резултатите (щракнете за уголемяване):
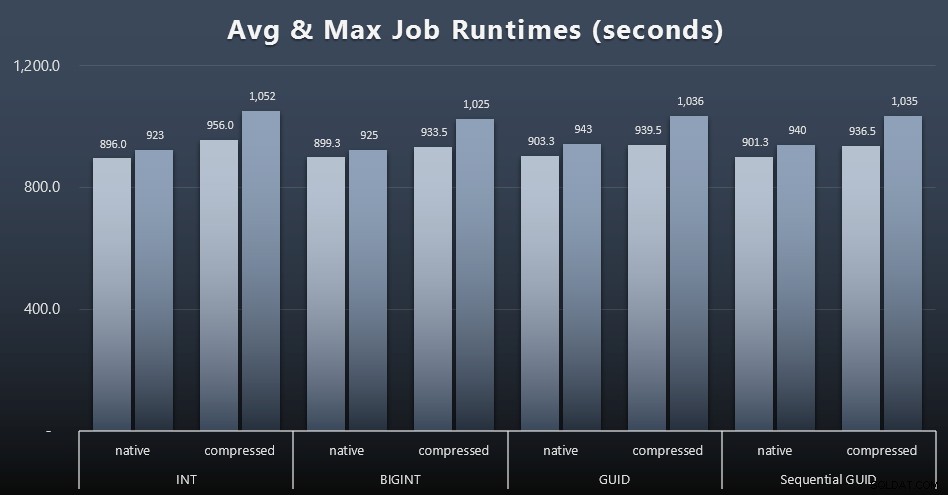
И ако искате да имате малко по-малко за смилане, просто погледнете средното и максималното време на изпълнение за четирите работни места (щракнете, за да увеличите):
Но дори и в тази втора графика всъщност няма достатъчно отклонение, за да се направи убедителна аргументация за или против някой от подходите.
Време за изпълнение на заявка
Взех някои показатели от
sys.dm_exec_query_statsиsys.dm_exec_trigger_statsза да определите колко време отнемат средно отделните заявки.
Население
Първите 200 000 клиенти бяха заредени доста бързо – под 20 секунди – поради липса на конкуриращи се натоварвания. След като четирите задания се изпълняваха едновременно, обаче, имаше значително влияние върху продължителността на запис поради едновременност. Останалите 800 000 реда изискваха средно поне порядък повече време за завършване. Ето резултатите от усредняването на всеки 2000 клиентски вмъкнат (щракнете, за да увеличите):
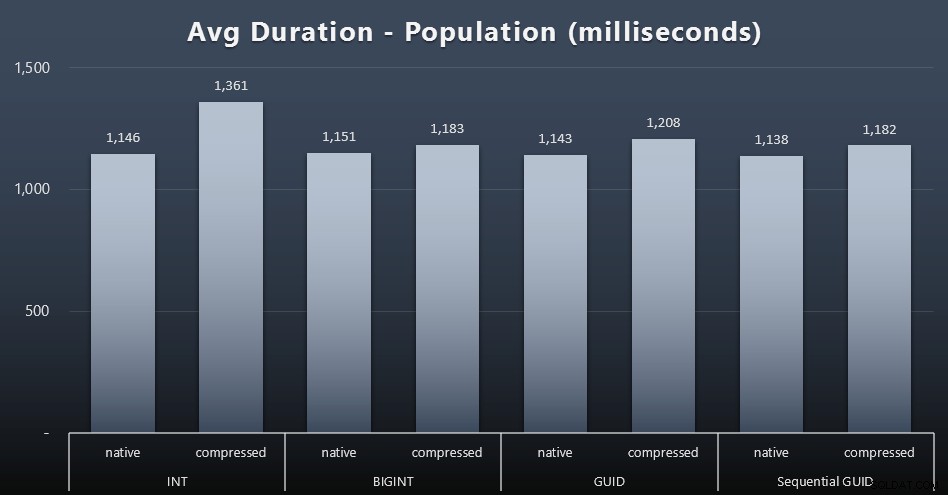
Тук виждаме, че компресирането на INT беше единственият реален отклонение – имам някои теории за това, но все още нищо окончателно.
Натоварвания за пейджинг
Средното време на изпълнение на заявките за пейджинг също изглежда е било значително повлияно от паралелността в сравнение с моите тестови работи в изолация. Ето резултатите (щракнете за уголемяване):
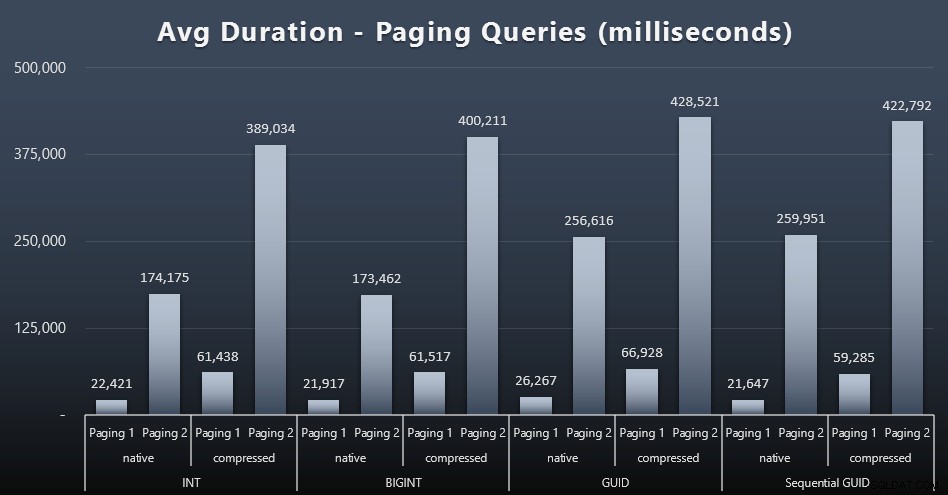
(Page 1 =поръчка по CustomerID, Paging 2 =поръчка по фамилия, име.)
Виждаме, че както за Пейджинг 1 (поръчка по CustomerID), така и за Пейджинг 2 (Поръчка по имена), има значително влияние върху времето за изпълнение поради компресия (до ~700%). И двата GUID изглежда са най-бавните коне в това състезание, като NEWID() се представя най-зле.
Актуализиране на работните натоварвания
Единичните актуализации бяха доста бързи дори при тежък паралелизъм, но все пак имаше някои забележими разлики поради компресия и дори някои изненадващи разлики между типовете данни (щракнете, за да увеличите):
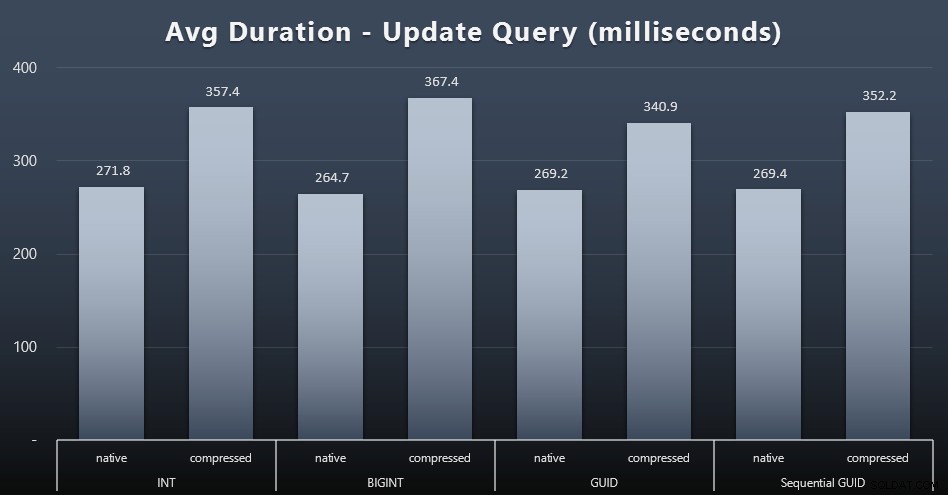
Най-вече, актуализациите на редовете, съдържащи стойности на GUID, всъщност бяха по-бързи отколкото актуализациите, съдържащи INT/BIGINT, когато се използва компресия. При естественото хранилище разликите бяха по-малко забележителни (но INT все още беше губещ там).
Статистика за задействане
Ето средното и максималното време на изпълнение за простия тригер във всеки отделен случай (щракнете, за да увеличите):
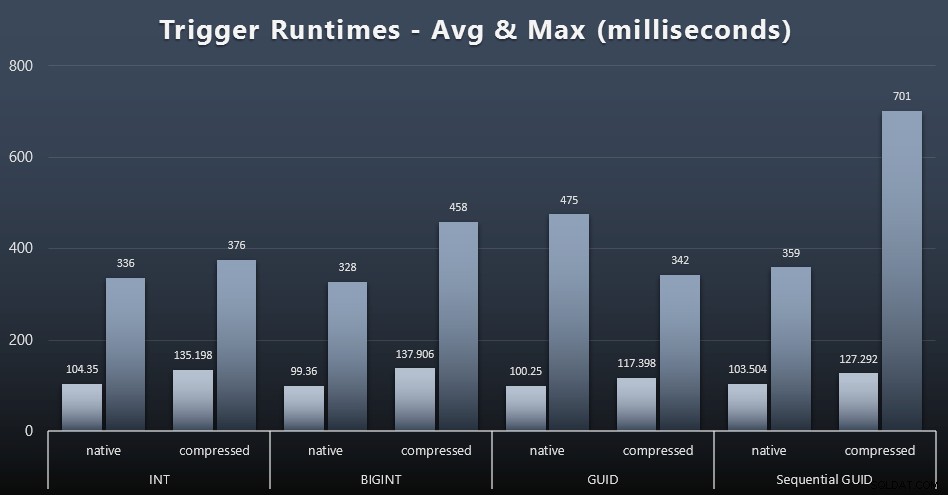
Изглежда, че компресията има много по-голямо влияние тук от избора на тип данни (въпреки че това вероятно би било по-изразено, ако част от моето работно натоварване за актуализиране беше актуализирало много редове, вместо да се състои само от едноредови търсения). Максимумът за последователен GUID очевидно е отклонение от някакъв вид, което не съм изследвал (можете да кажете, че е незначителен въз основа на средната стойност, която все още е в съответствие).
Какво чакаха тези заявки?
След всяко работно натоварване също разгледах най-големите изчаквания в системата, изхвърляйки очевидните изчаквания на опашка/таймер (както е описано от Пол Рандал) и неуместната активност от софтуера за наблюдение (като TRACEWRITE ). Ето първите 3 изчаквания във всеки случай (щракнете за увеличаване):
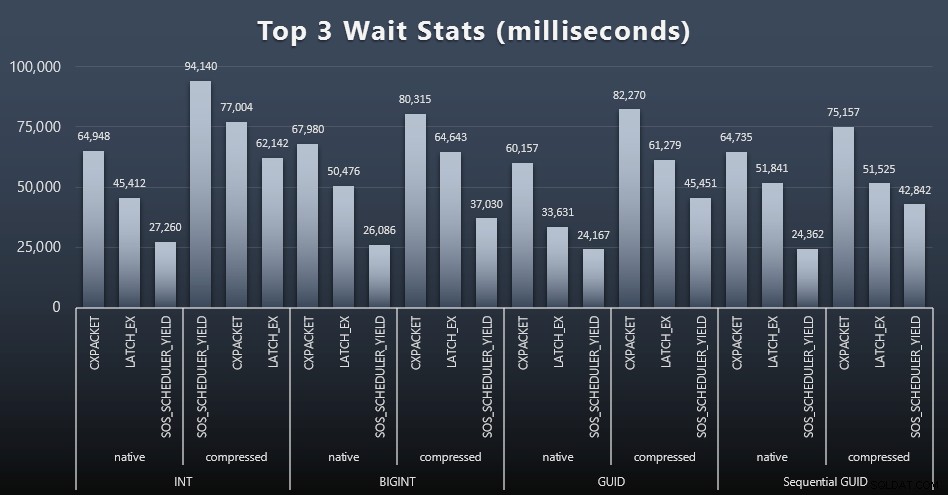
В повечето случаи изчакванията бяха CXPACKET, след това LATCH_EX, след това SOS_SCHEDULER_YIELD. В случая на използване, включващ цели числа и компресия, обаче, SOS_SCHEDULER_YIELD пое, което за мен предполага известна неефективност в алгоритъма за компресиране на цели числа (което може да е напълно несвързано с алгоритъма, използван за притискане на BIGINT в INT). Не проучвах това допълнително, нито намерих оправдание за проследяване на изчаквания за отделна заявка.
Дисково пространство/Фрагментация
Въпреки че съм склонен да се съглася, че не става въпрос за дисковото пространство, това все пак е показател, който си струва да се представи. Дори в този много опростен случай, когато има само една таблица и ключът не присъства във всички други свързани таблици (които със сигурност биха съществували в реално приложение), разликата е значителна. Първо нека разгледаме reserved колона от sp_spaceused (щракнете за увеличаване):
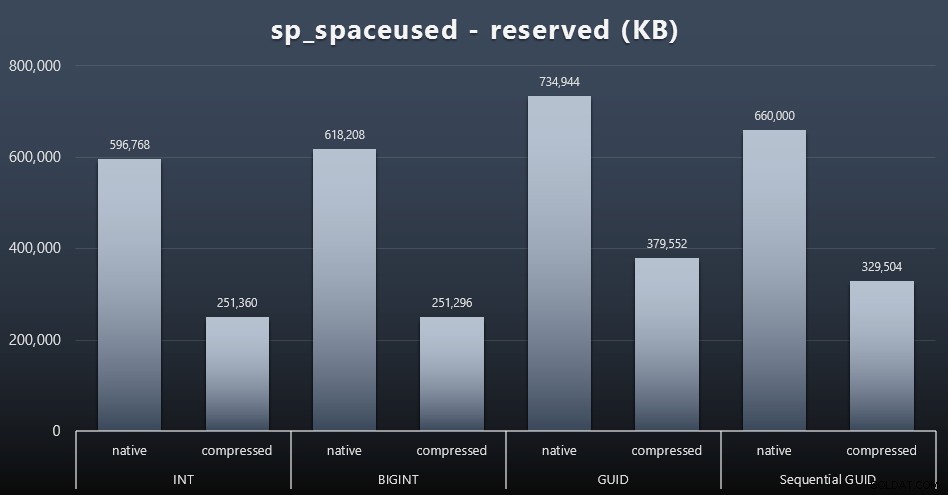
Тук BIGINT заема само малко повече място от INT, а GUID (както се очакваше) имаше по-голям скок. Последователният GUID имаше по-малко значително увеличение на използваното пространство и също беше компресиран много по-добре от традиционния GUID. Отново, тук няма изненади – GUID е по-голям от число, точка. Сега, привържениците на GUID може да твърдят, че цената, която плащате по отношение на дисковото пространство, не е толкова голяма (18% над BIGINT без компресия, около 50% с компресия). Но не забравяйте, че това е една таблица от 1 милион реда. Представете си как това ще се екстраполира, когато имате 10 милиона клиенти и много от тях имат 10, 30 или 500 поръчки – тези ключове могат да се повторят в дузина други таблици и да заемат същото допълнително място във всеки ред.
Когато разгледах фрагментацията след всяко натоварване (не забравяйте, че не се извършва поддръжка на индекс), използвайки тази заявка:
ИЗБЕРЕТЕ index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); Резултатите направиха много по-малко интересни визуализации; всички неклъстерираните индекси бяха фрагментирани над 99%. Клъстерираните индекси обаче са или много силно фрагментирани, или изобщо не са фрагментирани (щракнете, за да увеличите):
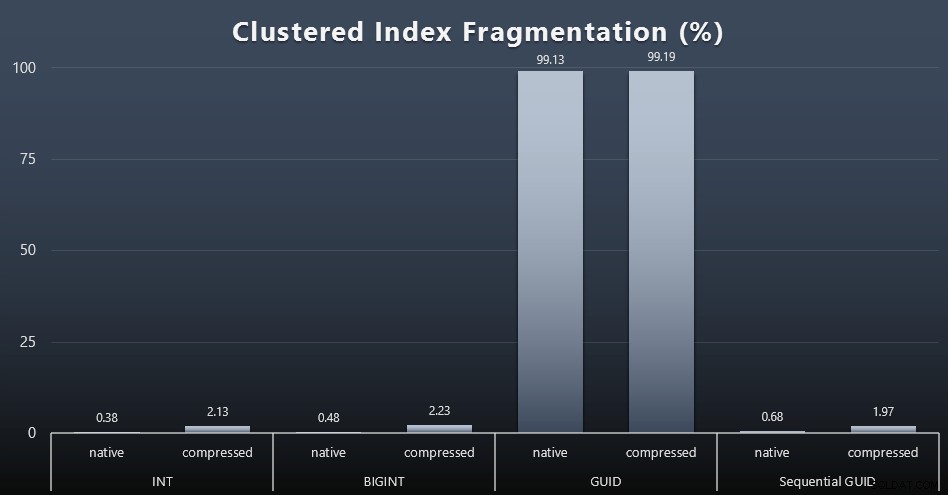
Фрагментацията е друг показател, който често означава много по-малко, когато говорим за SSD дискове, но е важно да се отбележи все едно, тъй като не всички системи могат да си позволят да не са наясно с влиянието, което фрагментацията може да има върху I/O моделите. Вярвам, че при използване на непоследователни GUID в по-обвързана с I/O система въздействието само на тази фрагментация би било драстично засилено върху повечето други показатели в този тест.
Използване на буферен пул
Това е мястото, където да бъдете разумни относно количеството дисково пространство, използвано от вашите таблици, наистина се отплаща – колкото по-големи са вашите таблици, толкова повече място заемат в буферния пул. Преместването на данни във и извън буферния пул е скъпо и отново, това е много опростен случай, при който тестовете се изпълняват изолирано и в екземпляра няма други приложения и бази данни, които се конкурират за ценна памет.
Това е проста мярка за следната заявка в края на всяко работно натоварване:
ИЗБЕРЕТЕ total_kb ОТ sys.dm_os_memory_broker_clerks WHERE clerk_name =N'Buffer Pool';
Резултати (щракнете за увеличаване):
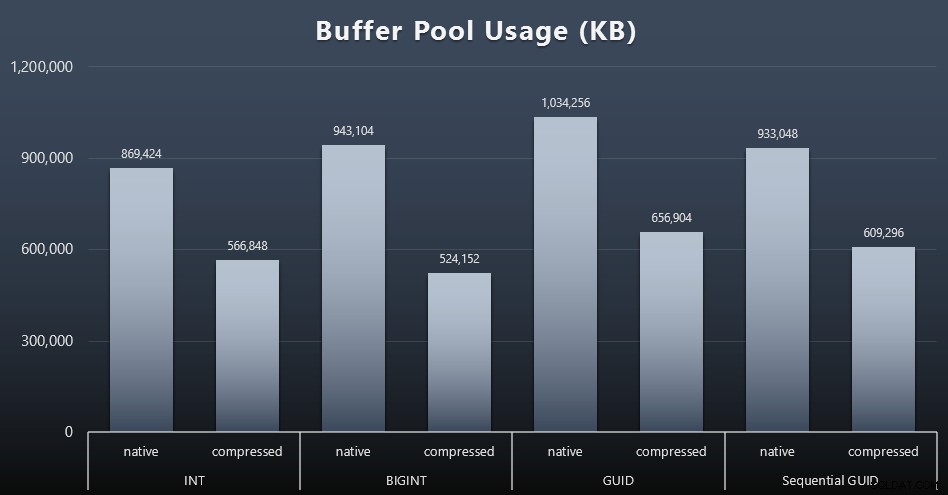
Въпреки че по-голямата част от тази графика изобщо не е изненадваща – GUID заема повече място от BIGINT, BIGINT повече от INT – намерих за интересно, че последователният GUID заема по-малко място от BIGINT, дори без компресия. Направих бележка, за да извърша някои криминалисти на ниво страница, за да определя какъв вид ефективност се извършва тук под кориците.
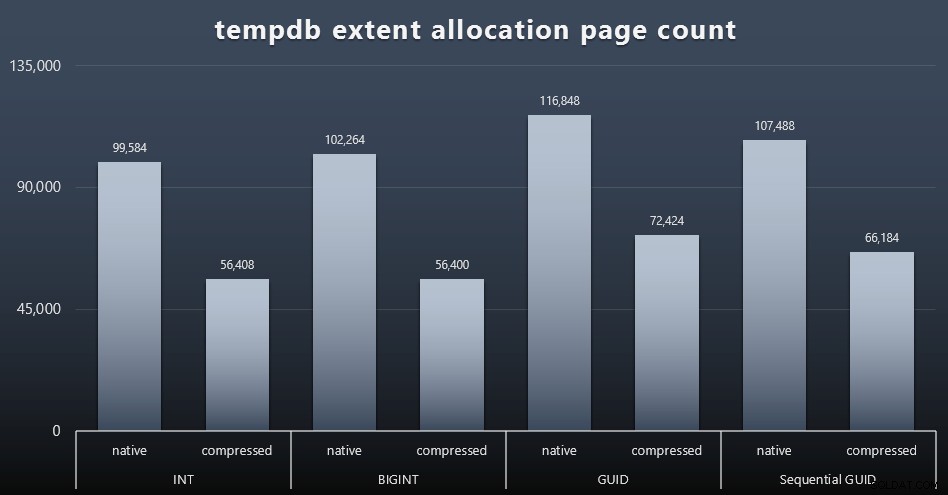
Използване на tempdb
Не съм сигурен какво очаквах тук, но след всяко работно натоварване събирах съдържанието на трите DMV за използване на пространството, свързани с tempdb, sys.dm_db_file|session|task_space_usage . Единственият, който изглежда показваше някаква нестабилност въз основа на типа данни, беше sys.dm_db_file_space_usage extent_allocation_page_count на . Това показва, че – поне в моята конфигурация и това специфично натоварване – GUID ще прекарат tempdb през малко по-задълбочена тренировка (щракнете, за да увеличите):
„Лоши“ разделяния на страници
Едно от нещата, които исках да измеря, беше въздействието върху разделянето на страници – не нормалното разделяне на страници (когато добавяте нова страница), а когато всъщност трябва да премествате данни между страниците, за да освободите място за повече редове. Jonathan Kehayias говори за това по-задълбочено в публикацията си в блога „Проследяване на проблемни разделяния на страници в разширени събития на SQL Server 2012 – не наистина този път!“, който също предоставя основата за сесията с разширени събития, която използвах за заснемане на данните:
СЪЗДАВАНЕ НА СЪБИТИЯ [BadPageSplits] НА СЪРВЪР ДОБАВЯНЕ НА СЪБИТИЕ sqlserver.transaction_log (WHERE операция =11 И database_id =10) ДОБАВЯНЕ НА ЦЕЛ package0.histogram ( SET filtering_event_name ='sqlserver.transaction_id' =source_transaction_id' );ГОЛТЕР СЪБИТИЯ [BadPageSplits] НА СЪСТОЯНИЕ НА СЪРВЪР =СТАРТ;GO
И заявката, която използвах, за да го начертая:
ИЗБЕРЕТЕ t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST(target_data като XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address =t.event_session_address_name =t.event_session_address_AND.t'Batarget_address WHERE. ='хистограма' ) КАТО x КРЪСТО ПРИЛОЖИ target_data.nodes('HistogramTarget/Slot') като q(n)) КАТО tabINNER JOIN sys.allocation_units КАТО au ON tab.alloc_unit_id =au.allocation_unit_idINNER au sys.parti. container_id =p.partition_idINNER JOIN sys.tables AS t ON p.object_id =t.[object_id]GROUP BY t.name; А ето и резултатите (щракнете за уголемяване):
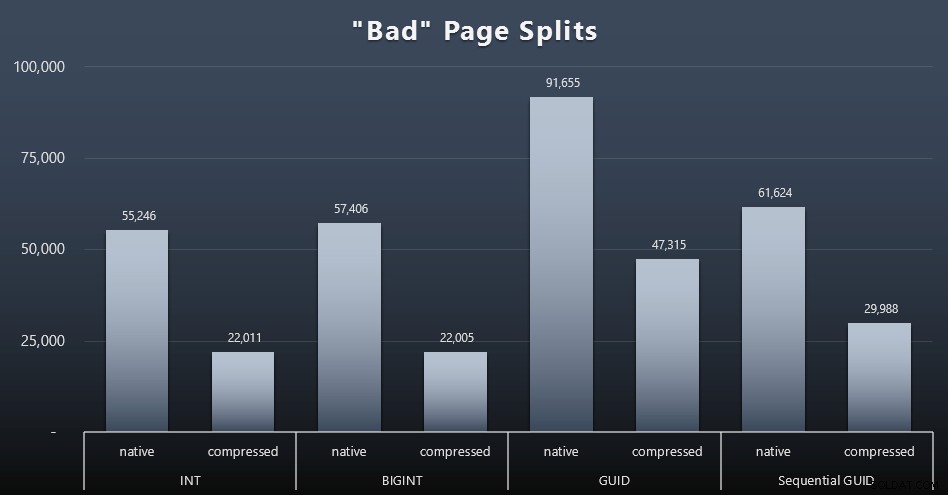
Въпреки че вече отбелязах, че в моя сценарий (където работя на бързи SSD дискове) безспорната разлика в I/O активността не оказва пряко влияние върху общото време на изпълнение, това все още е показател, който ще искате да вземете предвид – особено ако нямате SSD или ако работното ви натоварване вече е свързано с I/O.
Заключение
Въпреки че тези тестове ми отвориха малко по-широко очите за това колко дълготрайни възприятия, които съм имал, са били променени от по-модерен хардуер, аз все още съм доста твърдо против губенето на място на диска или в паметта. Въпреки че се опитах да демонстрирам известен баланс и да оставя GUID да блестят, тук има много малко от гледна точка на производителността, което да поддържа превключване от INT/BIGINT към която и да е форма на UNIQUEIDENTIFIER – освен ако не се нуждаете от други по-малко осезаеми причини (като създаване на ключа в приложението или поддържането на уникални ключови стойности в различни системи). Кратко обобщение, показващо, че NEWID() е най-лошият избор за много от показателите, където е имало значителна разлика (и в повечето от тези случаи NEWSEQUENTIALID() е близък втори)):
| Показател | Изчистване на губещия(ите)? |
|---|---|
| Неоспорени вложки | – теглене – |
| Едновременно натоварване | – теглене – |
| Индивидуални заявки – Население | INT (компресиран) |
| Индивидуални заявки – пейджинг | NEWID() / NEWSEQUENTIALID() |
| Отделни заявки – Актуализация | INT (роден) / BIGINT (компресиран) |
| Отделни заявки – задействане СЛЕД | – теглене – |
| Дисково пространство | NEWID() |
| Клъстерна фрагментация на индекс | NEWID() |
| Използване на буферен пул | NEWID() |
| Използване на tempdb | NEWID() |
| „Лоши“ разделяния на страници | NEWID() |
Таблица 2:Най-големите губещи
Чувствайте се свободни да тествате тези неща сами; Мога да събера пълния си набор от скриптове, ако искате да ги стартирате във вашата собствена среда. Кратката цел на цялата тази публикация е доста проста:има много важни показатели, които трябва да се вземат предвид, освен предвидимото въздействие върху дисковото пространство, така че не трябва да се използва самостоятелно като аргумент в нито една от двете посоки.
Сега, не искам тази линия на мислене да се ограничава само до ключове. Наистина трябва да се мисли за това, когато се прави избор на тип данни. Виждам datetime често се избира, например, когато е само date или smalldatetime е необходимо. При транзакционни таблици това също може да доведе до много пропиляно дисково пространство и това се свежда до някои от тези други ресурси.
В бъдещ тест бих искал да сравня резултатите за много по-голяма таблица (> 2 милиарда реда). Мога да симулирам това с INT, като задам началното число на идентичността на -2 милиарда, което позволява ~4 милиарда реда. И бих искал сравненията на работното натоварване и дисковото пространство/отпечатъка на паметта да включват повече от една таблица, тъй като едно от предимствата на тънкия ключ е, когато този ключ е представен в десетки свързани таблици. Наблюдавах за събития за автоматично нарастване, но нямаше такива, тъй като базата данни беше предварително оразмерена, достатъчно голяма, за да побере растежа, и не мислех да измервам действителното използване на регистрационни файлове в съществуващия лог файл, така че бих искал да тествам отново с настройките по подразбиране за размера на журнала и автоматичното нарастване и този път измерване на DBCC SQLPERF(LOGSPACE); . Би било интересно също така да се изгради време за повторно изграждане и да се измери използването на регистрационни файлове в резултат на тези операции. И накрая, бих искал да направя I/O по-подходящ фактор, като намеря сървър с механични твърди дискове – знам, че има много, но в някои магазини те са доста оскъдни.



