В част 1 от тази серия използвахте Flask и Connexion, за да създадете REST API, осигуряващ CRUD операции към проста структура в паметта, наречена PEOPLE . Това работи, за да демонстрира как модулът Connexion ви помага да изградите приятен REST API заедно с интерактивна документация.
Както някои отбелязаха в коментарите за част 1, PEOPLE структурата се инициализира отново всеки път, когато приложението се рестартира. В тази статия ще научите как да съхранявате PEOPLE структура и действията, които API предоставя, към база данни с помощта на SQLAlchemy и Marshmallow.
SQLAlchemy предоставя обектен релационен модел (ORM), който съхранява обекти на Python в представяне на база данни на данните на обекта. Това може да ви помогне да продължите да мислите по Pythonic начин и да не се занимавате с това как данните за обекта ще бъдат представени в база данни.
Marshmallow предоставя функционалност за сериализиране и десериализиране на Python обекти, докато те изтичат от и в нашия базиран на JSON REST API. Marshmallow преобразува екземпляри на клас Python в обекти, които могат да бъдат преобразувани в JSON.
Можете да намерите кода на Python за тази статия тук.
Безплатен бонус: Щракнете тук, за да изтеглите копие от ръководството „Примери за REST API“ и да получите практическо въведение в принципите на Python + REST API с примери за действие.
За кого е тази статия
Ако ви е харесала част 1 от тази поредица, тази статия разширява колана ви с инструменти още повече. Ще използвате SQLAlchemy за достъп до база данни по по-питоничен начин от директния SQL. Също така ще използвате Marshmallow за сериализиране и десериализиране на данните, управлявани от REST API. За да направите това, ще използвате основните функции за обектно-ориентирано програмиране, налични в Python.
Също така ще използвате SQLAlchemy за създаване на база данни, както и за взаимодействие с нея. Това е необходимо, за да стартирате REST API и да работи с PEOPLE данни, използвани в част 1.
Уеб приложението, представено в част 1, ще има своите HTML и JavaScript файлове, променени по незначителни начини, за да поддържа и промените. Можете да прегледате окончателната версия на кода от част 1 тук.
Допълнителни зависимости
Преди да започнете да изграждате тази нова функционалност, ще трябва да актуализирате virtualenv, който сте създали, за да стартирате кода на част 1, или да създадете нов за този проект. Най-лесният начин да направите това, след като сте активирали своя virtualenv, е да изпълните тази команда:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Това добавя повече функционалност към вашия virtualenv:
-
Flask-SQLAlchemyдобавя SQLAlchemy, заедно с някои връзки към Flask, позволявайки на програмите да имат достъп до бази данни. -
flask-marshmallowдобавя Flask частите на Marshmallow, което позволява на програмите да конвертират Python обекти към и от сериализиращи се структури. -
marshmallow-sqlalchemyдобавя някои куки Marshmallow в SQLAlchemy, за да позволи на програмите да сериализират и десериализират Python обекти, генерирани от SQLAlchemy. -
marshmallowдобавя по-голямата част от функционалността на Marshmallow.
Данни за хората
Както бе споменато по-горе, PEOPLE структурата на данните в предишната статия е речник на Python в паметта. В този речник сте използвали фамилното име на лицето като ключ за търсене. Структурата на данните изглеждаше така в кода:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Промените, които ще направите в програмата, ще преместят всички данни в таблица на база данни. Това означава, че данните ще бъдат запазени на вашия диск и ще съществуват между стартиранията на server.py програма.
Тъй като фамилното име беше ключът на речника, кодът ограничаваше промяната на фамилното име на човек:можеше да се промени само първото име. Освен това преместването към база данни ще ви позволи да промените фамилното име, тъй като то вече няма да се използва като ключ за търсене на човек.
Концептуално таблицата на базата данни може да се разглежда като двуизмерен масив, където редовете са записи, а колоните са полета в тези записи.
Таблиците на базата данни обикновено имат автоматично увеличаваща се целочислена стойност като ключ за търсене на редове. Това се нарича първичен ключ. Всеки запис в таблицата ще има първичен ключ, чиято стойност е уникална в цялата таблица. Наличието на първичен ключ, независим от данните, съхранявани в таблицата, ви освобождава да променяте всяко друго поле в реда.
Забележка:
Автоматично увеличаващият се първичен ключ означава, че базата данни се грижи за:
- Увеличаване на най-голямото съществуващо поле за първичен ключ всеки път, когато в таблицата се вмъкне нов запис
- Използване на тази стойност като първичен ключ за нововмъкнатите данни
Това гарантира уникален първичен ключ с нарастването на таблицата.
Ще следвате конвенцията на базата данни за именуване на таблицата като единствено число, така че таблицата ще се нарича person . Превеждаме нашите PEOPLE структура по-горе в таблица на база данни с име person ви дава това:
| person_id | име | fname | timestamp |
|---|---|---|---|
| 1 | Фарел | Дъг | 2018-08-08 21:16:01.888444 |
| 2 | Брокман | Кент | 2018-08-08 21:16:01.889060 |
| 3 | Великден | Зайче | 2018-08-08 21:16:01.886834 |
Всяка колона в таблицата има име на поле, както следва:
person_id: поле за първичен ключ за всяко лицеlname: фамилно име на лицетоfname: собствено име на лицетоtimestamp: клеймо за време, свързано с действия за вмъкване/актуализация
Взаимодействие с базата данни
Ще използвате SQLite като машина за база данни за съхраняване на PEOPLE данни. SQLite е най-широко разпространената база данни в света и се предлага с Python безплатно. Той е бърз, изпълнява цялата си работа с файлове и е подходящ за много проекти. Това е цялостна RDBMS (система за управление на релационни бази данни), която включва SQL, езикът на много системи за бази данни.
За момента си представете person таблицата вече съществува в база данни на SQLite. Ако сте имали някакъв опит с RDBMS, вероятно сте запознати с SQL, езикът за структурирани заявки, който повечето RDBMS използват за взаимодействие с базата данни.
За разлика от езиците за програмиране като Python, SQL не дефинира как за да получите данните:описва какво данните са желани, оставяйки как до двигателя на базата данни.
SQL заявка, която получава всички данни в нашия person таблицата, сортирана по фамилно име, ще изглежда така:
SELECT * FROM person ORDER BY 'lname';
Тази заявка казва на двигателя на базата данни да получи всички полета от таблицата с хора и да ги сортира във възходящ ред по подразбиране с помощта на lname поле.
Ако трябва да изпълните тази заявка срещу SQLite база данни, съдържаща person таблица, резултатите ще бъдат набор от записи, съдържащи всички редове в таблицата, като всеки ред съдържа данните от всички полета, съставляващи един ред. По-долу е даден пример за използване на инструмента за команден ред SQLite, изпълняващ горната заявка срещу person таблица на базата данни:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
Резултатът по-горе е списък на всички редове в person таблица на базата данни със символи (‘|’), разделящи полетата в реда, което се прави за целите на показване от SQLite.
Python е напълно способен да взаимодейства с много машини за бази данни и да изпълнява SQL заявката по-горе. Резултатите най-вероятно ще бъдат списък с кортежи. Външният списък съдържа всички записи в person маса. Всеки отделен вътрешен кортеж ще съдържа всички данни, представляващи всяко поле, дефинирано за ред на таблица.
Получаването на данни по този начин не е много Pythonic. Списъкът със записи е наред, но всеки отделен запис е просто набор от данни. Програмата трябва да знае индекса на всяко поле, за да извлече конкретно поле. Следният код на Python използва SQLite, за да демонстрира как да изпълните горната заявка и да покаже данните:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Програмата по-горе прави следното:
-
Линия 1 импортира
sqlite3модул. -
Ред 3 създава връзка с файла на базата данни.
-
Реда 4 създава курсор от връзката.
-
Ред 5 използва курсора, за да изпълни
SQLзаявка, изразена като низ. -
Ред 6 получава всички записи, върнати от
SQLзаявка и ги присвоява наpeopleпроменлива. -
Ред 7 и 8 итерирайте над
peopleсписък на променлива и отпечатайте името и фамилията на всеки човек.
people променлива от ред 6 по-горе ще изглежда така в Python:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
Резултатът от програмата по-горе изглежда така:
Kent Brockman
Bunny Easter
Doug Farrell
В горната програма трябва да знаете, че името на човек е в индекс 2 , а фамилното име на човек е в индекс 1 . Още по-лошо, вътрешната структура на person трябва също да се знае всеки път, когато предавате итерационната променлива person като параметър на функция или метод.
Би било много по-добре това, което сте получили обратно за person беше обект на Python, където всяко от полетата е атрибут на обекта. Това е едно от нещата, които SQLAlchemy прави.
Масички Боби
В горната програма SQL операторът е прост низ, предаван директно на базата данни за изпълнение. В този случай това не е проблем, защото SQL е низов литерал, изцяло под контрола на програмата. Въпреки това, случаят на използване на вашия REST API ще вземе потребителски вход от уеб приложението и ще го използва за създаване на SQL заявки. Това може да отвори приложението ви за атака.
Ще си спомните от част 1, че REST API за получаване на един person от PEOPLE данните изглеждаха така:
GET /api/people/{lname}
Това означава, че вашият API очаква променлива, lname , в пътя на крайната точка на URL адреса, който използва за намиране на един person . Промяната на кода на Python SQLite отгоре, за да се направи това, би изглеждала така:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Горният кодов фрагмент прави следното:
-
Линия 1 задава
lnameпроменлива до'Farrell'. Това ще дойде от пътя на крайната точка на URL адреса на REST API. -
Ред 2 използва форматиране на низове на Python, за да създаде SQL низ и да го изпълни.
За да бъде нещата опростени, горният код задава lname променлива към константа, но наистина тя би идвала от пътя на крайната точка на URL адреса на API и може да бъде всичко, предоставено от потребителя. SQL, генериран от форматирането на низа, изглежда така:
SELECT * FROM person WHERE lname = 'Farrell'
Когато този SQL се изпълнява от базата данни, той търси person таблица за запис, където фамилното име е равно на 'Farrell' . Това е, което е предназначено, но всяка програма, която приема въвеждане на потребител, е отворена и за злонамерени потребители. В програмата по-горе, където lname променливата се задава от предоставено от потребителя въвеждане, това отваря вашата програма за това, което се нарича атака с инжектиране на SQL. Това е това, което нежно е известно като Little Bobby Tables:
Например, представете си злонамерен потребител, наречен вашия REST API по този начин:
GET /api/people/Farrell');DROP TABLE person;
Заявката за REST API по-горе задава lname променлива към 'Farrell');DROP TABLE person;' , който в кода по-горе ще генерира този SQL израз:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
Горният SQL оператор е валиден и когато се изпълни от базата данни, той ще намери един запис, където lname съвпада с 'Farrell' . След това ще намери разделителя на SQL израза ; и ще продължи напред и ще пусне цялата маса. Това по същество би разрушило приложението ви.
Можете да защитите програмата си, като дезинфекцирате всички данни, които получавате от потребителите на вашето приложение. Дезинфекцията на данните в този контекст означава, че програмата ви проверява предоставените от потребителя данни и се уверява, че не съдържат нищо опасно за програмата. Това може да бъде трудно да се направи правилно и ще трябва да се прави навсякъде, където потребителските данни взаимодействат с базата данни.
Има друг начин, който е много по-лесен:използвайте SQLAlchemy. Той ще дезинфекцира потребителските данни вместо вас, преди да създаде SQL изрази. Това е друго голямо предимство и причина да използвате SQLAlchemy при работа с бази данни.
Моделиране на данни с SQLAlchemy
SQLAlchemy е голям проект и предоставя много функционалност за работа с бази данни с помощта на Python. Едно от нещата, които предоставя, е ORM или Object Relational Mapper и това е, което ще използвате, за да създадете и работите с person таблица на базата данни. Това ви позволява да картографирате ред полета от таблицата на базата данни към обект на Python.
Обектно ориентираното програмиране ви позволява да свържете данни заедно с поведението, функциите, които оперират с тези данни. Чрез създаване на класове SQLAlchemy вие можете да свържете полетата от редовете на таблицата на базата данни с поведението, което ви позволява да взаимодействате с данните. Ето дефиницията на клас SQLAlchemy за данните в person таблица на базата данни:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
Класът Person наследява от db.Model , до който ще стигнете, когато започнете да създавате програмния код. Засега това означава, че наследявате от базов клас, наречен Model , предоставящ атрибути и функционалност, общи за всички класове, получени от него.
Останалите дефиниции са атрибути на ниво клас, дефинирани както следва:
-
__tablename__ = 'person'свързва дефиницията на класа сpersonтаблица на базата данни. -
person_id = db.Column(db.Integer, primary_key=True)създава колона на база данни, съдържаща цяло число, действащо като първичен ключ за таблицата. Това също така казва на базата данни, чеperson_idще бъде автоматично увеличаваща се целочислена стойност. -
lname = db.Column(db.String)създава полето за фамилно име, колона на базата данни, съдържаща стойност на низ. -
fname = db.Column(db.String)създава първото поле за име, колона на базата данни, съдържаща стойност на низ. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)създава поле за времеви отпечатък, колона на базата данни, съдържаща стойност за дата/час.default=datetime.utcnowпараметърът по подразбиране задава стойността на времевата марка на текущияutcnowстойност, когато е създаден запис.onupdate=datetime.utcnowпараметър актуализира времевата марка с текущияutcnowстойност, когато записът се актуализира.
Забележка:UTC маркировки за време
Може би се чудите защо времевата марка в горния клас по подразбиране е и се актуализира от datetime.utcnow() метод, който връща UTC или координирано универсално време. Това е начин за стандартизиране на източника на вашата времева марка.
Източникът или нулево време е линия, минаваща на север и юг от северния до южния полюс на Земята през Обединеното кралство. Това е нулевата часова зона, от която всички останали часови зони са изместени. Като използвате това като нулев източник на време, вашите времеви марки са отместени спрямо тази стандартна референтна точка.
Ако приложението ви бъде достъпно от различни часови зони, имате начин да извършвате изчисления за дата/час. Всичко, от което се нуждаете, е времева марка по UTC и часова зона на местоназначението.
Ако трябваше да използвате местните часови зони като източник на времеви отпечатъци, тогава не бихте могли да извършвате изчисления за дата/час без информация за местните часови зони, изместени от нулево време. Без информацията за източника на времевата марка не бихте могли да правите никакви сравнения на дата/час или математика.
Работата с времеви марки, базирани на UTC, е добър стандарт, който трябва да се следва. Ето един сайт с инструменти, с който да работите и да ги разберете по-добре.
Накъде се насочвате с това Person дефиниция на класа? Крайната цел е да можете да изпълните заявка с помощта на SQLAlchemy и да получите обратно списък с екземпляри на Person клас. Като пример, нека разгледаме предишния SQL израз:
SELECT * FROM people ORDER BY lname;
Покажете същата малка примерна програма отгоре, но сега с помощта на SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Като игнорирате ред 1 за момента, това, което искате, е целият person записи, сортирани във възходящ ред по lname поле. Какво получавате от операторите на SQLAlchemy Person.query.order_by(Person.lname).all() е списък на Person обекти за всички записи в person таблица на базата данни в този ред. В горната програма people променливата съдържа списъка на Person обекти.
Програмата преглежда people променлива, като всеки person на свой ред и отпечатване на името и фамилията на лицето от базата данни. Забележете, че програмата не трябва да използва индекси, за да получи fname или lname стойности:използва атрибутите, дефинирани в Person обект.
Използването на SQLAlchemy ви позволява да мислите по отношение на обекти с поведение, а не суров SQL . Това става още по-полезно, когато таблиците на вашата база данни станат по-големи и взаимодействията по-сложни.
Сериализиране/десериализиране на моделирани данни
Работата с SQLAlchemy моделирани данни във вашите програми е много удобна. Това е особено удобно в програми, които манипулират данните, може би правят изчисления или ги използват за създаване на презентации на екрана. Приложението ви е REST API, което по същество осигурява CRUD операции върху данните и като такова не извършва много манипулации на данни.
REST API работи с JSON данни и тук можете да срещнете проблем с модела SQLAlchemy. Тъй като данните, върнати от SQLAlchemy, са екземпляри на клас Python, Connexion не може да сериализира тези екземпляри на клас в JSON форматирани данни. Не забравяйте от част 1, че Connexion е инструментът, който сте използвали за проектиране и конфигуриране на REST API с помощта на YAML файл и свързване на методите на Python към него.
В този контекст сериализирането означава преобразуване на Python обекти, които могат да съдържат други обекти на Python и сложни типове данни, в по-прости структури от данни, които могат да бъдат анализирани в JSON типове данни, които са изброени тук:
string: тип низnumber: числа, поддържани от Python (цели числа, плаващи числа, дълги)object: JSON обект, който е приблизително еквивалентен на речник на Pythonarray: приблизително еквивалентен на списък на Pythonboolean: представено в JSON катоtrueилиfalse, но в Python катоTrueилиFalsenull: по съществоNoneв Python
Като пример, вашето Person клас съдържа времева марка, която е DateTime на Python . В JSON няма дефиниция за дата/час, така че клеймото за време трябва да бъде преобразувано в низ, за да съществува в JSON структура.
Вашето Person class е достатъчно прост, така че получаването на атрибутите на данните от него и ръчното създаване на речник, който да се върне от нашите крайни точки на REST URL, няма да бъде много трудно. В по-сложно приложение с много по-големи модели на SQLAlchemy това няма да е така. По-добро решение е да използвате модул, наречен Marshmallow, за да свърши работата вместо вас.
Marshmallow ви помага да създадете PersonSchema клас, който е като SQLAlchemy Person клас, който създадохме. Тук обаче, вместо да съпоставя таблици на база данни и имена на полета към класа и неговите атрибути, PersonSchema class определя как атрибутите на клас ще бъдат преобразувани в удобни за JSON формати. Ето дефиницията на класа Marshmallow за данните в нашия person таблица:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Класът PersonSchema наследява от ma.ModelSchema , до който ще стигнете, когато започнете да създавате програмния код. Засега това означава PersonSchema наследява от базов клас Marshmallow, наречен ModelSchema , предоставящ атрибути и функционалност, общи за всички класове, получени от него.
Останалата част от определението е както следва:
-
class Metaдефинира клас с имеMetaв рамките на вашия клас.ModelSchemaклас, койтоPersonSchemaкласът наследява от външния вид на този вътрешенMetaклас и го използва за намиране на SQLAlchemy моделPersonиdb.session. Ето как Marshmallow намира атрибути вPersonклас и типа на тези атрибути, така че да знае как да ги сериализира/десериализира. -
modelказва на класа какъв SQLAlchemy модел да използва за сериализиране/десериализиране на данни към и от. -
db.sessionказва на класа коя сесия на базата данни да използва за интроспекция и определяне на типове данни за атрибути.
Накъде се насочвате с тази дефиниция на клас? Искате да можете да сериализирате екземпляр на Person клас в JSON данни и за десериализиране на JSON данни и създаване на Person екземпляри на клас от него.
Създайте инициализираната база данни
SQLAlchemy обработва много от взаимодействията, специфични за конкретни бази данни и ви позволява да се съсредоточите върху моделите на данни, както и как да ги използвате.
Сега, когато всъщност ще създадете база данни, както беше споменато по-горе, ще използвате SQLite. Правите това по няколко причини. Той идва с Python и не е необходимо да се инсталира като отделен модул. Той записва цялата информация за базата данни в един файл и следователно е лесен за настройка и използване.
Инсталирането на отделен сървър на база данни като MySQL или PostgreSQL би работило добре, но ще изисква инсталиране на тези системи и тяхното стартиране, което е извън обхвата на тази статия.
Тъй като SQLAlchemy обработва базата данни, в много отношения наистина няма значение каква е основната база данни.
Ще създадете нова помощна програма, наречена build_database.py за създаване и инициализиране на SQLite people.db файл с база данни, съдържащ вашето person таблица на базата данни. По пътя ще създадете два модула на Python, config.py и models.py , който ще се използва от build_database.py и модифицираният server.py от част 1.
Ето къде можете да намерите изходния код за модулите, които предстои да създадете, които са представени тук:
-
config.pyполучава необходимите модули, импортирани в програмата и конфигурирани. Това включва Flask, Connexion, SQLAlchemy и Marshmallow. Тъй като ще се използва както отbuild_database.pyиserver.py, някои части от конфигурацията ще се прилагат само заserver.pyприложение. -
models.pyе модулът, в който ще създадетеPersonSQLAlchemy иPersonSchemaДефинициите на клас Marshmallow, описани по-горе. Този модул зависи отconfig.pyза някои от обектите, създадени и конфигурирани там.
Конфигурационен модул
config.py модул, както подсказва името, е мястото, където се създава и инициализира цялата информация за конфигурацията. Ще използваме този модул както за нашия build_database.py програмен файл и скоро ще бъде актуализиран server.py файл от част 1 статия. Това означава, че тук ще конфигурираме Flask, Connexion, SQLAlchemy и Marshmallow.
Въпреки че build_database.py програмата не използва Flask, Connexion или Marshmallow, тя използва SQLAlchemy, за да създаде нашата връзка с базата данни на SQLite. Ето кода за config.py модул:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Ето какво прави горният код:
-
Редове 2 – 4 импортирайте Connexion, както направихте в
server.pyпрограма от част 1. Освен това импортираSQLAlchemyотflask_sqlalchemyмодул. Това дава на вашата програма достъп до базата данни. И накрая, импортираMarshmallowотflask_marshamllowмодул. -
Ред 6 създава променливата
basedirсочещи към директорията, в която се изпълнява програмата. -
Линия 9 използва
basedirпроменлива, за да създадете екземпляра на приложението Connexion и да му дадете пътя къмswagger.ymlфайл. -
Ред 12 създава променлива
app, което е екземплярът на Flask, инициализиран от Connexion. -
Редове 15 използва
appпроменлива за конфигуриране на стойности, използвани от SQLAlchemy. Първо задаваSQLALCHEMY_ECHOдоTrue. Това кара SQLAlchemy да повтаря SQL изрази, които изпълнява, към конзолата. Това е много полезно за отстраняване на грешки при изграждане на програми за бази данни. Задайте това наFalseза производствени среди. -
Линия 16 задава
SQLALCHEMY_DATABASE_URIкъмsqlite:////' + os.path.join(basedir, 'people.db'). Това казва на SQLAlchemy да използва SQLite като база данни и файл с имеpeople.dbв текущата директория като файл на базата данни. Различните машини за бази данни, като MySQL и PostgreSQL, ще имат различенSQLALCHEMY_DATABASE_URIнизове, за да ги конфигурирате. -
Линия 17 задава
SQLALCHEMY_TRACK_MODIFICATIONSдоFalse, изключване на системата за събития SQLAlchemy, която е включена по подразбиране. Системата за събития генерира събития, полезни в програми, управлявани от събития, но добавя значителни допълнителни разходи. Тъй като не създавате програма, управлявана от събития, изключете тази функция. -
Линия 19 създава
dbпроменлива чрез извикване наSQLAlchemy(app). Това инициализира SQLAlchemy чрез предаване наappтоку-що зададена информация за конфигурацията.dbпроменливата е това, което се импортира вbuild_database.pyпрограма, за да му даде достъп до SQLAlchemy и базата данни. Той ще служи за същата цел вserver.pyпрограма иpeople.pyмодул. -
Ред 23 създава
maпроменлива чрез извикване наMarshmallow(app). Това инициализира Marshmallow и му позволява да интроспектира компонентите на SQLAlchemy, прикачени към приложението. Ето защо Marshmallow се инициализира след SQLAlchemy.
Модул за модели
models.py модулът е създаден, за да предостави Person и PersonSchema класове точно както е описано в разделите по-горе относно моделирането и сериализирането на данните. Ето кода за този модул:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Ето какво прави горният код:
-
Линия 1 импортира
datetimeобект отdatetimeмодул, който идва с Python. Това ви дава начин да създадете времева марка вPersonклас. -
Ред 2 импортира
dbиmaпроменливи на екземпляра, дефинирани вconfig.pyмодул. Това дава на модула достъп до атрибути и методи на SQLAlchemy, прикачени къмdbпроменлива и атрибутите и методите на Marshmallow, прикачени къмmaпроменлива. -
Редове 4 – 9 дефинирайте
Personклас, както беше обсъдено в раздела за моделиране на данни по-горе, но сега знаете къде се намираdb.Modelче класът наследява от origins. Това даваPersonфункции на клас SQLAlchemy, като връзка с базата данни и достъп до нейните таблици. -
Редове 11 – 14 дефинирайте
PersonSchemaклас, както беше обсъдено в раздела за сериализиране на данни по-горе. Този клас наследява отma.ModelSchemaи даваPersonSchemaфункции на клас Marshmallow, като интроспекция наPersonклас, за да помогне за сериализирането/десериализирането на екземпляри от този клас.
Създаване на базата данни
Видяхте как таблиците на базата данни могат да бъдат съпоставени с SQLAlchemy класове. Сега използвайте това, което сте научили, за да създадете база данни и да я попълните с данни. Ще създадете малка помощна програма за създаване и изграждане на база данни с people данни. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Ред 2 imports the
dbinstance from theconfig.pymodule. -
Ред 3 imports the
Personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()обадете се. This creates the database by using thedbinstance imported from theconfigмодул. Thedbinstance is our connection to the database. -
Lines 20 – 22 повторете над
PEOPLElist and use the dictionaries within to instantiate aPersonклас. After it is instantiated, you call thedb.session.add(p)функция. This uses the database connection instancedbto access thesessionобект. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionобект. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Забележка: At Line 22, no data has been added to the database. Everything is being saved within the session обект. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py файл. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname value.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Действие | HTTP глагол | URL път | Описание |
|---|---|---|---|
| Създаване | POST | /api/people | Defines a unique URL to create a new person |
| Прочетете | GET | /api/people | Defines a unique URL to read a collection of people |
| Прочетете | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Актуализиране | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Изтриване | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people маса. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT отговори. You can check out the updated swagger.yml file.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pyмодул. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeopleсписък. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Забележка: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person база данни. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()екземпляр. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person обект. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personеNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} section. This section of the UI gets a single person from the database and looks like this:
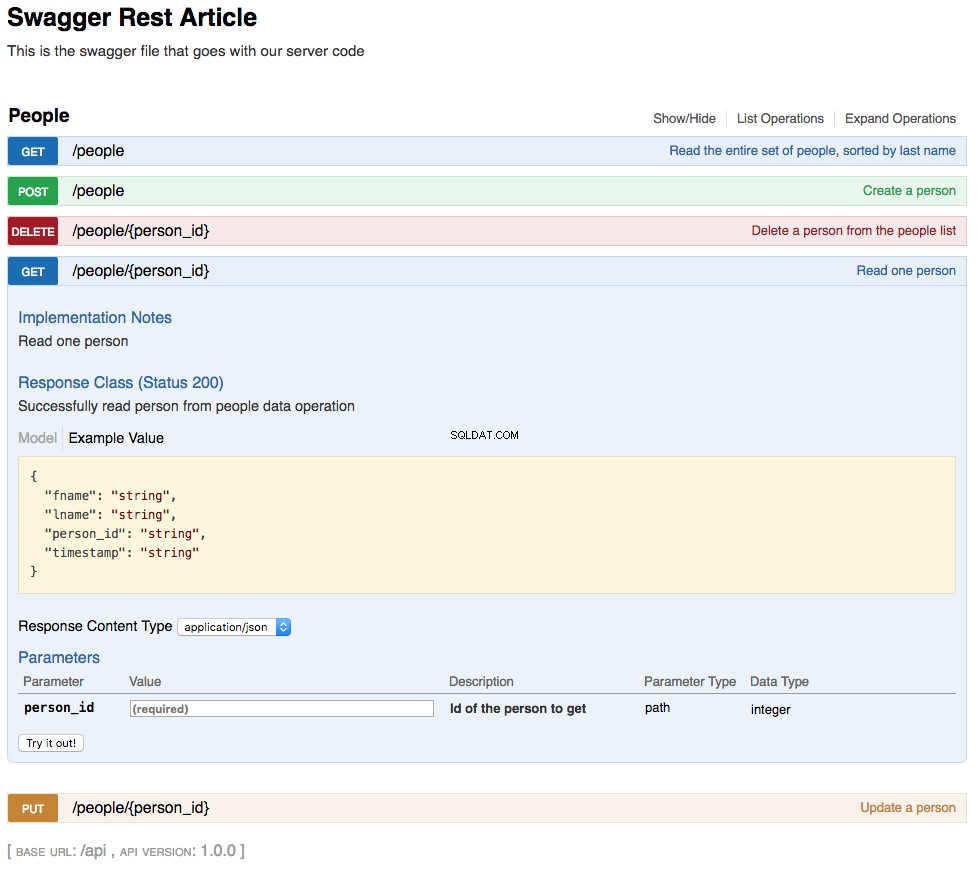
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Заключение
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.