Отговорността за работата на SQL Server може да бъде трудна задача. Има много области, които трябва да наблюдаваме и разбираме. Също така се очаква да можем да бъдем в течение на всички тези показатели и да знаем какво се случва на нашите сървъри по всяко време. Обичам да питам администраторите на база данни какво е първото нещо, за което си помислят, когато чуят фразата „настройване на SQL Server;“ преобладаващият отговор, който получавам, е „настройка на заявка“. Съгласен съм, че заявките за настройка са много важни и са безкрайна задача, пред която сме изправени, защото работните натоварвания непрекъснато се променят.
Има обаче много други аспекти, които трябва да имате предвид, когато мислите за производителността на SQL Server. Има много настройки на ниво инстанция, ОС и база данни, които трябва да бъдат коригирани от настройките по подразбиране. Да бъда консултант ми позволява да работя в много различни бизнес линии и да се излагам на всякакви проблеми с производителността. Когато работя с нов клиент, се опитвам винаги да извършвам одит на състоянието на сървъра, за да знам с какво си имам работа. Докато извършвах тези одити, едно от нещата, които открих многократно, е прекомерното забавяне на четене и запис на дисковете, където се намират данните и регистрационните файлове на SQL Server.
Закъснение за четене/запис
За да видите латентностите на диска си в SQL Server, можете бързо и лесно да заявите DMV sys.dm_io_virtual_file_stats . Този DMV приема два параметъра:database_id и file_id . Страхотното е, че можете да подадете NULL като и двете стойности и връща латентностите за всички файлове за всички бази данни. Изходните колони включват:
- идентификатор на база данни
- file_id
- sample_ms
- брой_прочетения
- брой_прочетени_байтове
- io_stall_read_ms
- брой_записи
- брой_написани_байтове
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- дръжка_файл
Както можете да видите от списъка с колони, има наистина полезна информация, която този DMV извлича, но просто се изпълнява SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); не помага много, освен ако не сте запомнили своите database_ids и не можете да направите малко математика в главата си.
Когато отправям заявка към статистическите данни на файла, използвам заявка от публикацията в блога на Пол Рандал „Как да изследвам латентностите на IO подсистемата от SQL Server“. Този скрипт прави имената на колоните по-лесни за четене, включва устройството, на което се намира файлът, името на базата данни и пътя към файла.
Чрез запитване към този DMV можете лесно да разберете къде се намират I/O горещите точки за вашите файлове. Можете да видите къде са най-високите закъснения при запис и четене и кои бази данни са виновните. Познаването на това ще ви позволи да започнете да разглеждате възможностите за настройка за тези специфични бази данни. Това може да включва настройка на индекса, проверка дали буферният пул е под натиск от паметта, евентуално преместване на базата данни към по-бърза част от I/O подсистемата или евентуално разделяне на базата данни и разпространение на файловите групи между други LUN.
Така че стартирате заявката и тя връща много стойности в ms за латентност – кои стойности са наред и кои са лоши?
Кои ценности са добри или лоши?
Ако попитате SQLskills, ние ще ви кажем нещо от рода на:
- Отличен:<1 мс
- Много добър:<5 мс
- Добър:5 – 10 мс
- Лошо:10 – 20 мс
- Лошо:20 – 100 мс
- Наистина лошо:100 – 500 мс
- OMG!:> 500 мс
Ако направите търсене в Bing, ще намерите статии от Microsoft, които дават препоръки, подобни на:
- Добър:<10 мс
- Добре:10 – 20 мс
- Лошо:20 – 50 мс
- Сериозно лошо:> 50 мс
Както можете да видите, има някои леки вариации в числата, но консенсусът е, че всичко над 20 мс може да се счита за обезпокоително. Като се има предвид това, средната ви латентност при запис може да бъде 20 мс и това е 100% приемливо за вашата организация и това е добре. Трябва да знаете общите I/O латентности за вашата система, така че, когато нещата се влошат, да знаете какво е нормално.
Закъсненията ми за четене/запис са лоши, какво да правя?
Ако установите, че забавянията за четене и запис са лоши на вашия сървър, има няколко места, където можете да започнете да търсите проблеми. Това не е изчерпателен списък, а някои насоки откъде да започнете.
- Анализирайте натовареността си. Правилна ли е вашата стратегия за индексиране? Липсата на подходящи индекси ще доведе до четене на много повече данни от диска. Сканира вместо търси.
- Актуални ли са вашите статистически данни? Лошата статистика може да доведе до лош избор за планове за изпълнение.
- Имате ли проблеми с подслушването на параметри, които причиняват лоши планове за изпълнение?
- Буферният пул подложен ли е на натиск от паметта, например от раздут планов кеш?
- Някакви проблеми с мрежата? Вашият SAN плат работи ли правилно? Накарайте вашия инженер за съхранение да потвърди пътя и мрежата.
- Преместете горещите точки в различни масиви за съхранение. В някои случаи може да е една база данни или само няколко бази данни, които причиняват всички проблеми. Изолирането им в различен набор от дискове или по-бърз диск от висок клас, като SSD, може да е най-доброто логично решение.
- Можете ли да разделите базата данни, за да преместите проблемни таблици на друг диск, за да разпределите натоварването?
Изчакайте статистика
Точно като наблюдението на вашите файлови статистики, наблюдението на вашите статистики за чакане може да ви каже много за тесните места във вашата среда. Имаме късмет, че имаме още един страхотен DMV (sys.dm_os_wait_stats ), че можем да направим заявка, която ще изтегли цялата налична информация за изчакване, събрана от последното рестартиране или от последния път, когато изчакванията са били нулирани; има и изчаквания, свързани с производителността на диска. Този DMV ще върне важна информация, включително:
- тип_чакане
- waiting_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
Запитването на този DMV на моята SQL Server 2014 машина върна 771 типа на изчакване. SQL Server винаги чака нещо, но има много чакания, за които не бива да се притесняваме. Поради тази причина използвам друга заявка от Пол Рандал; публикацията му в блога „Изчакайте статистика или, моля, кажете ми къде боли“, има отличен скрипт, който изключва куп чакания, за които всъщност не ни пука. Пол също така изброява много от често срещаните проблемни изчаквания, както и предлага насоки за често срещаните изчаквания.
Защо статистиката за чакане е важна?
Наблюдението за дълго време на чакане за определени събития ще ви каже кога има проблеми. Имате нужда от изходно ниво, за да разберете какво е нормално и кога нещата надхвърлят праг или ниво на болка. Ако имате наистина високо PAGEIOLATCH_XX тогава знаете, че SQL Server трябва да изчака страница с данни да бъде прочетена от диска. Това може да бъде диск, памет, промяна на работното натоварване или редица други проблеми.
Скорошен клиент, с когото работех, виждаше много необичайно поведение. Когато се свързах със сървъра на базата данни и успях да наблюдавам сървъра под натоварване, веднага започнах да проверявам статистики за файлове, статистика за чакане, използване на паметта, използване на tempdb и т.н. Едно нещо, което веднага се открои, беше WRITELOG е най-разпространеното чакане. Знам, че това изчакване е свързано с изтриване на регистрационни файлове на диск и ми напомни за поредицата на Пол за Изрязване на мазнините в дневника на транзакциите. Висок WRITELOG изчакванията обикновено могат да бъдат идентифицирани чрез големи латентности при запис за регистрационния файл на транзакциите. Така че след това използвах моя скрипт за статистика на файловете, за да прегледам латентностите за четене и запис на диска. Тогава успях да видя висока латентност при запис във файла с данни, но не и моя регистрационен файл. Разглеждайки WRITELOG беше много чакане, но времето за чакане в ms беше изключително малко. Все пак нещо във втория пост от поредицата на Пол все още беше в главата ми. Трябва да погледна настройките за автоматичен растеж за базата данни, само за да изключа „Смърт от хиляда съкращения“. Разглеждайки свойствата на базата данни на базата данни, видях, че файлът с данни е настроен да нараства автоматично с 1MB, а регистрационният файл на транзакциите е настроен да нараства автоматично с 10%. И двата файла имаха почти 0 неизползвано място. Споделих с клиента какво открих и как това убива представянето им. Бързо направихме подходящата промяна и тестването продължи, между другото много по-добре. За съжаление това не е единственият път, когато се сблъсквам точно с този проблем. Друг път, когато база данни беше с размер 66 GB, тя стигна до там с ръст от 1 MB.
Заснемане на вашите данни
Много специалисти по данни са създали процеси за редовно улавяне на статистически данни за файлове и изчакване за анализ. Тъй като статистическите данни за чакането са кумулативни, бихте искали да ги уловите и да сравните делтите между различните часове на деня или преди и след изпълнението на определени процеси. Това не е твърде сложно и има многобройни публикации в блогове, където хората споделят как са постигнали това. Важната част е да измервате тези данни, за да можете да ги наблюдавате. Как да разберете днес, че нещата са по-добри или по-лоши на вашия сървър на база данни, освен ако не знаете данните от вчера?
Как може да помогне SQL Sentry?
Радвам се, че попитахте! SQL Sentry Performance Advisor носи латентност и изчаква отпред и в центъра на таблото. Всички аномалии се забелязват лесно; можете да преминете към исторически режим и да видите предишната тенденция и да я сравните с предишни периоди. Това може да се окаже безценно, когато анализираме тези „какво се случи?“ моменти. Всички са получили това обаждане:„Вчера около 15:00 часа системата просто сякаш замръзна, можете ли да ни кажете какво се случи?“ Хм, разбира се, нека извадя Profiler и да се върна назад във времето. Ако имате инструмент за наблюдение като Performance Advisor, ще имате тази историческа информация на една ръка разстояние.
В допълнение към диаграмите и графиките на таблото за управление, имате възможност да използвате вградени сигнали за условия като високо изчакване на диска, висок VLF брой, висок процесор, ниска продължителност на живота на страницата и много други. Освен това имате възможността да създавате свои собствени персонализирани условия и можете да се поучите от примерите на сайта SQL Sentry или чрез Condition Exchange (Аарон Бертран е писал в блог за това). Засегнах предупредителната страна на това в последната си статия за Сигналите за агент на SQL Server.
В раздела Disk Space на Performance Advisor е много лесно да видите неща като настройки за автоматичен растеж и висок VLF брой. Трябва да знаете, но в случай, че не го направите, автоматичното нарастване с 1MB или 10% не е най-добрата настройка. Ако видите тези стойности (Performance Advisor ги подчертава вместо вас), можете бързо да си направите бележка и да планирате времето, за да направите правилните корекции. Харесва ми как показва и Total VLFs; твърде много VLF могат да бъдат много проблематични. Трябва да прочетете публикацията на Кимбърли „VLFs на журнала на транзакциите – твърде много или твърде малко?“ ако още не сте го направили.
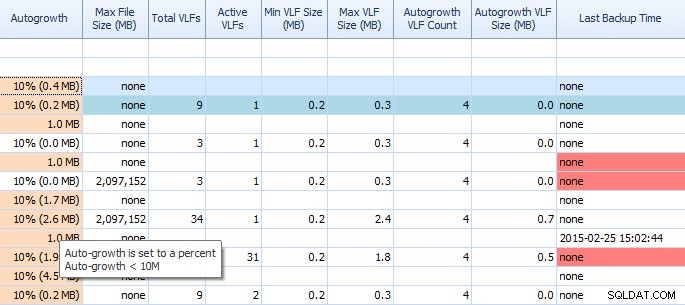 Частична решетка в раздела Disk Space на съветника за производителност
Частична решетка в раздела Disk Space на съветника за производителност
Друг начин, по който Performance Advisor може да помогне, е чрез своя патентован модул Disk Activity. Тук можете да видите, че tempdb на F:изпитва значително забавяне при запис; можете да разберете това по дебелите червени линии под графиката на диска. Може също да забележите, че F:е единствената буква на устройството, чийто диск е представен в червено; това е визуална подсказка, че устройството има неправилно подравнен дял, което може да допринесе за I/O проблеми.
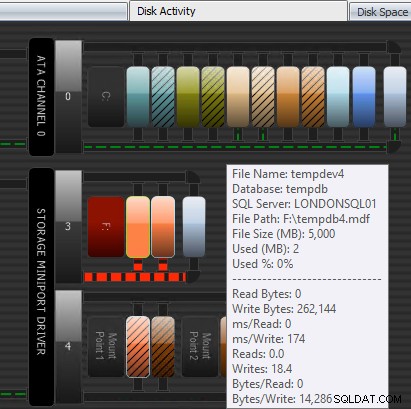 Модул за дискова активност на съветника за производителност
Модул за дискова активност на съветника за производителност
И можете да съпоставите тази информация в решетките по-долу – проблемите също са подчертани в решетките там и разгледайте ms/Write колона:
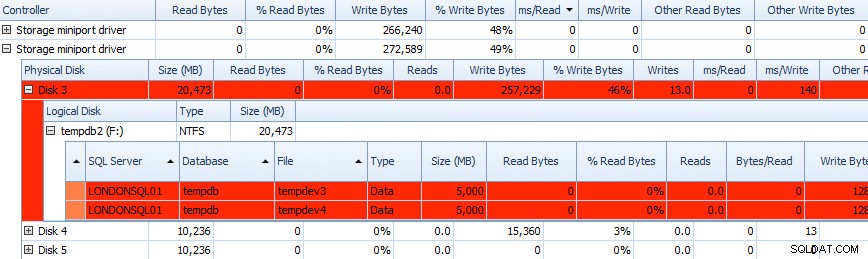 Частична решетка от данни за активността на диска на съветника за производителност
Частична решетка от данни за активността на диска на съветника за производителност
Можете също да разгледате тази информация със задна дата; ако някой се оплаква от усещано затруднение на диска вчера следобед или миналия вторник, можете просто да се върнете назад, като използвате инструментите за избор на дата в лентата с инструменти и да видите средната пропускателна способност и латентност за всеки диапазон. За повече информация относно модула Disk Activity вижте Ръководството на потребителя.
Performance Advisor също има много вградени отчети в категориите производителност, блокиране, най-добър SQL, дисково/файлово пространство и застой. Изображението по-долу ви показва как да стигнете до отчетите за дисково/файловото пространство. Наличието на отчетите само на няколко щраквания с мишката е много ценно, за да можете незабавно да се вкопаете и да видите какво се случва (или се е случвало) на вашия сървър.
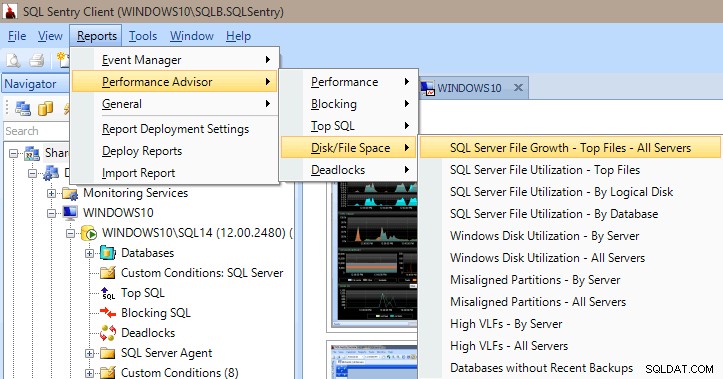 Отчети на съветника за ефективност
Отчети на съветника за ефективност
Резюме
Важният извод от тази публикация е да знаете вашите показатели за ефективност. Често срещано твърдение сред професионалистите по данни е, че дискът е нашето тесно място номер 1. Познаването на статистическите данни за файловете на вашия сървър ще ви помогне да разберете болезнените точки на вашия сървър. Във връзка със статистиката на файловете, статистиката ви за чакане също е чудесно място за разглеждане. Много хора, включително и аз, започват оттам. Наличието на инструмент като SQL Sentry Performance Advisor може драстично да ви помогне да отстраните неизправности и да намерите проблеми с производителността, преди да станат твърде проблематични; ако обаче нямате такъв инструмент, запознайте се с sys.dm_os_wait_stats и sys.dm_io_virtual_file_stats ще ви послужи добре, за да започнете да настройвате сървъра си.