Въведение
В кръговете на базата данни е общоизвестно, че индексите подобряват производителността на заявката или като удовлетворяват изцяло необходимия набор от резултати (покриващи индекси) или действат като справки, които лесно насочват Query Engine към точното местоположение на необходимия набор от данни. Въпреки това, както знаят опитните администратори на база данни, човек не трябва да бъде твърде ентусиазиран от създаването на индекси в OLTP среди, без да разбира естеството на работното натоварване. Използвайки Query Store в екземпляр на SQL Server 2019 (Query Store беше въведено в SQL Server 2016), е доста лесно да се покаже ефектът на индекс върху вмъкванията.
Вмъкване без индекс
Започваме с възстановяване на базата данни WideWorldImporters Sample и след това създаваме копие на Sales. Таблица с фактури, използвайки скрипта в листинг 1. Имайте предвид, че в примерната база данни вече е активирано хранилището на заявки в режим четене-запис.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Забележете, че в таблицата, която току-що създадохме, няма никакви индекси. Всичко, което имаме, е структурата на таблицата. След като приключим, изпълняваме вмъквания в новата таблица, използвайки данните от нейния родител, както е показано в листинг 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
По време на тази операция, Query Store улавя плана за изпълнение на заявката. Фигура 1 показва накратко какво се случва под капака. Четейки отляво надясно виждаме, че SQL Server изпълнява вмъкванията, използвайки План ID 563 – индексно сканиране на първичния ключ на таблицата източник за извличане на данните и след това вмъкване на таблица в таблицата местоназначение. (Четене отляво надясно). Обърнете внимание, че в този случай по-голямата част от разходите е върху вложката за таблица – 99% от цената на заявката.
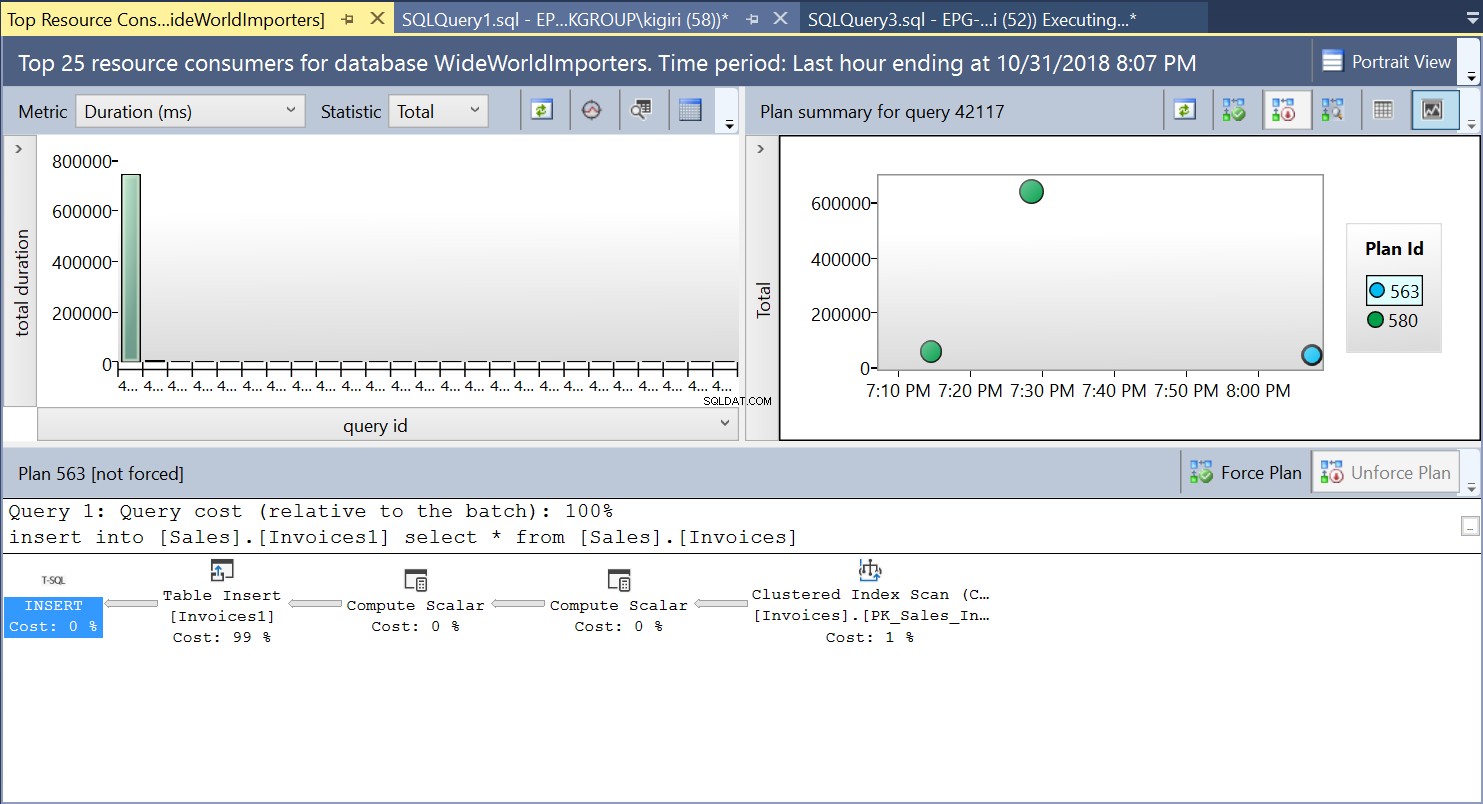
Фиг. 1 План за изпълнение 563
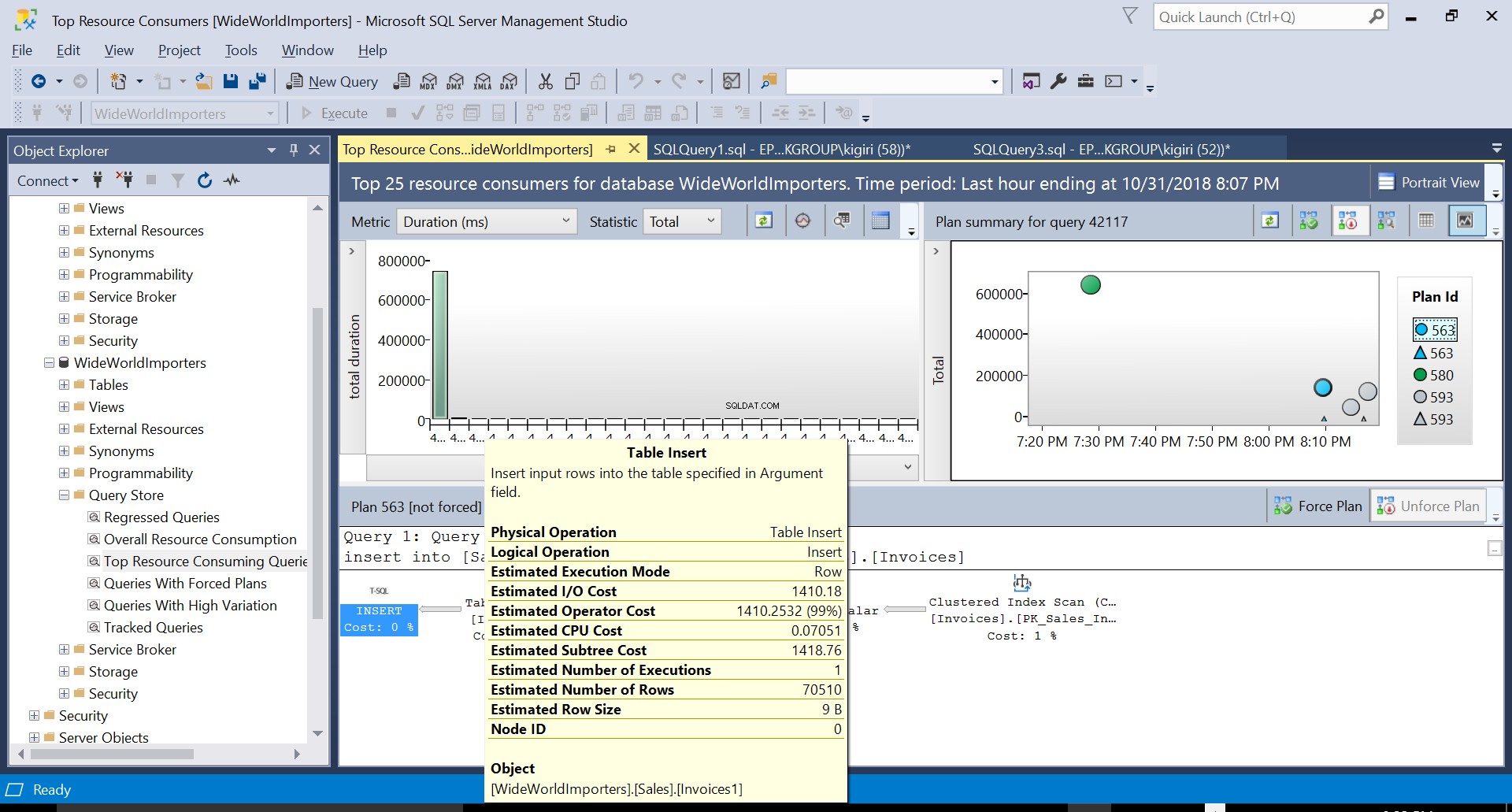
Фиг. 2 Вмъкване на таблица на местоназначение
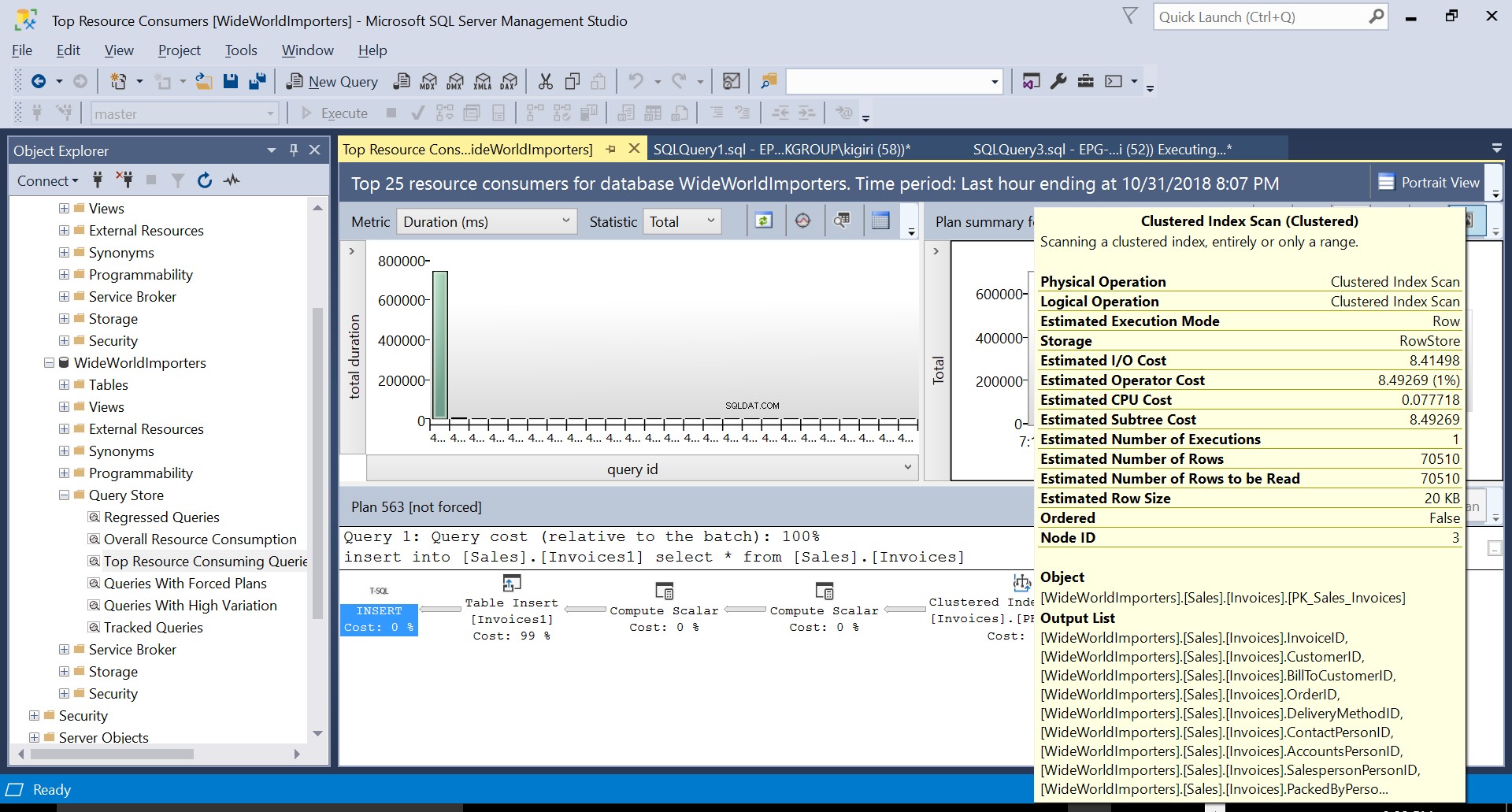
Фиг. 3 Клъстерирано индексно сканиране на таблица с източник
Вмъкване с индекс
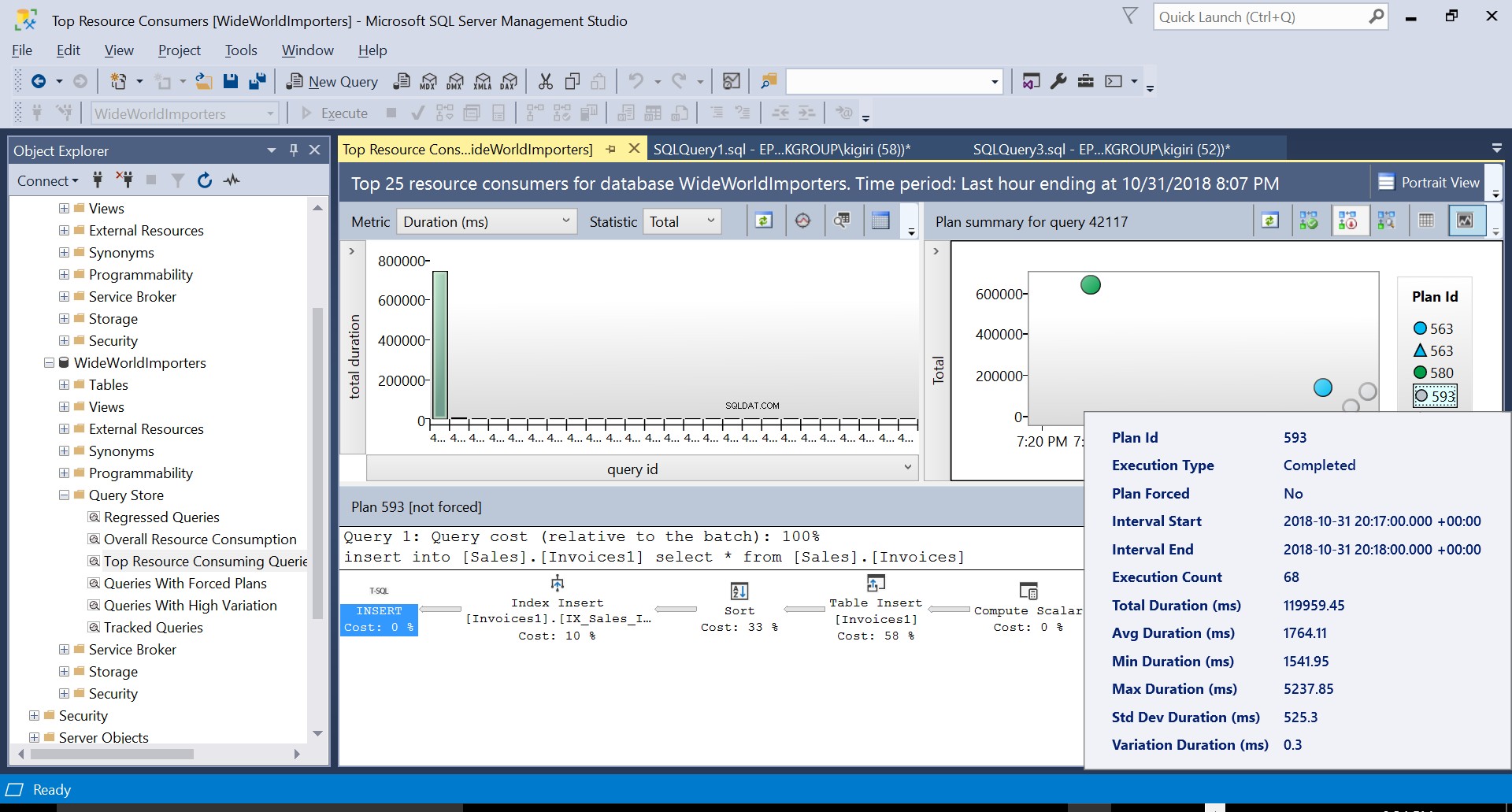
След това създаваме индекс на таблицата местоназначение, използвайки DDL в листинг 3. Когато повторим израза в листинг 2 след съкращаване на таблицата местоназначение, виждаме малко по-различен план за изпълнение (план ID 593, показан на фигура 4). Все още виждаме вмъкването на таблица, но допринася само 58% към цената на заявката. Динамиката на изпълнение е малко изкривена с въвеждането на сортиране и вмъкване на индекс. По същество това, което се случва е, че SQL Server трябва да въведе съответните редове в индекса, когато в таблицата се въвеждат нови записи.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
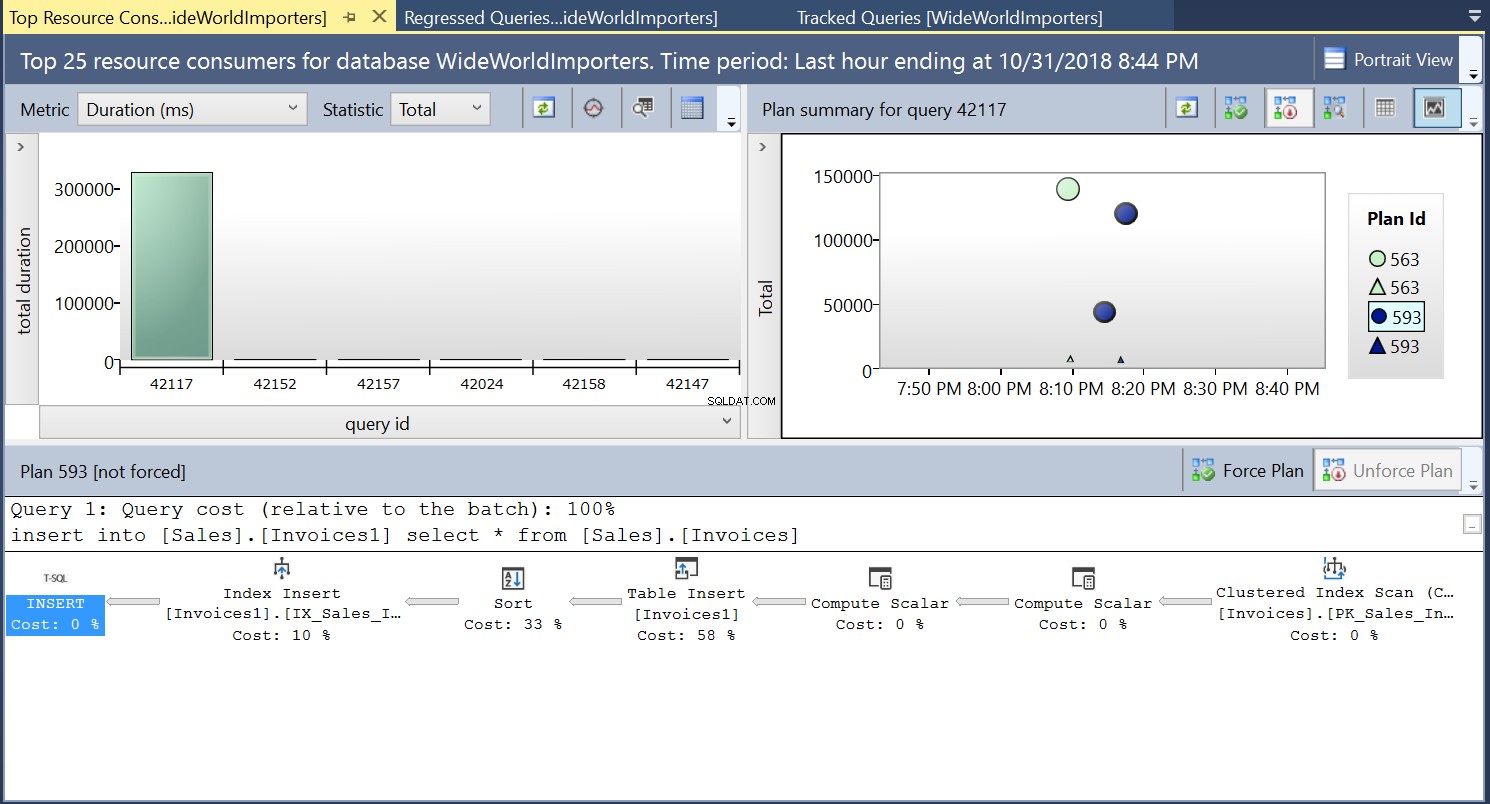
Фиг. 4 План за изпълнение 593
Поглед по-дълбоко
Можем да разгледаме детайлите и на двата плана и да видим как тези нови фактори ескалират времето за изпълнение на изявлението. План 593 добавя още около 300 ms към средната продължителност на изявлението. При голямо натоварване в производствена среда тази разлика може да бъде значителна.
Включването на STATISTICS IO при изпълнение на инструкцията за вмъкване само веднъж и в двата случая – с индекс в таблицата на местоназначението и без индекс в таблицата на местоназначението – също показва, че се работи повече по отношение на логическото IO при вмъкване на редове в таблица с индекси.
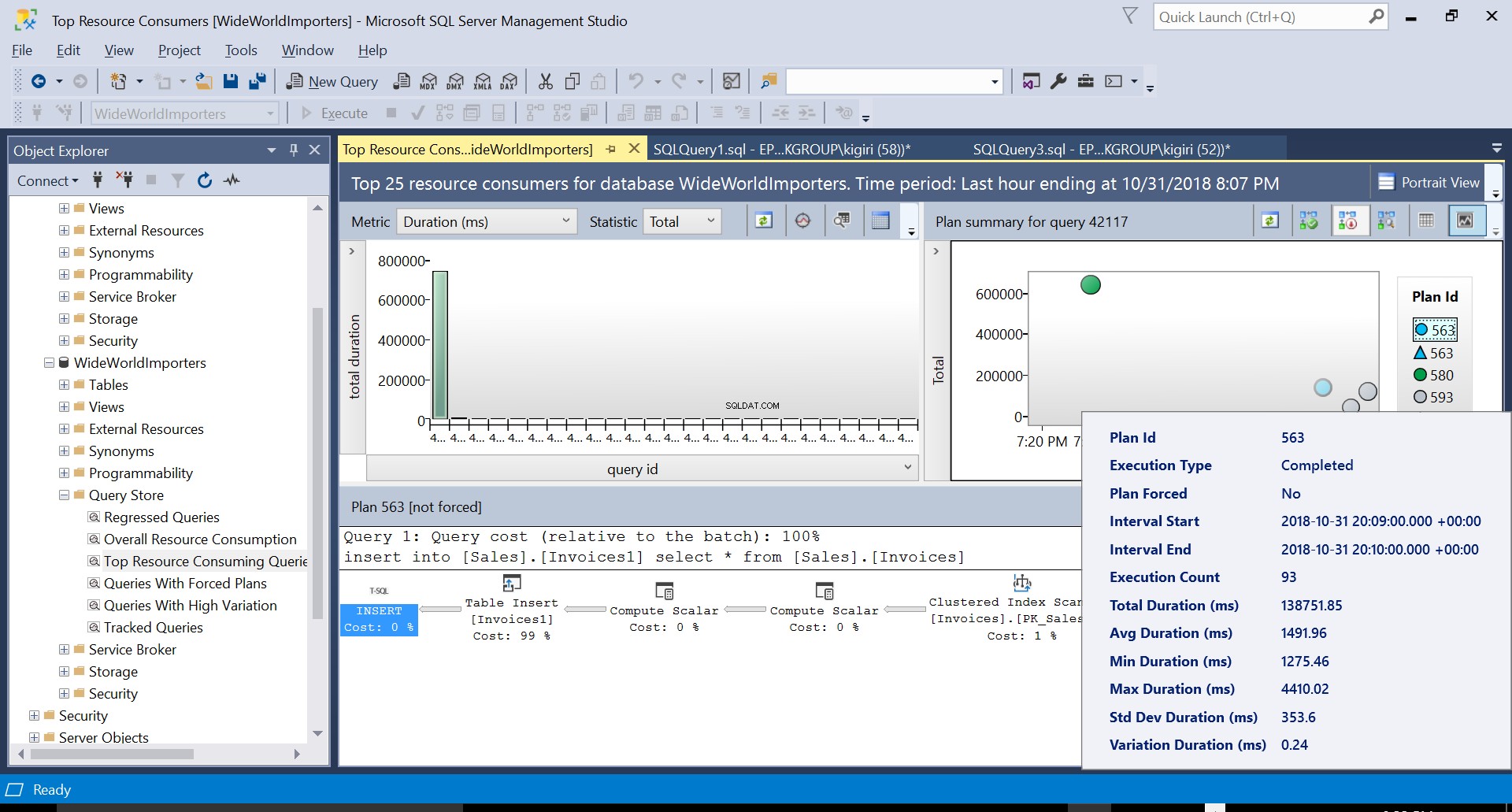
Фиг. 5 Подробности за план за изпълнение 563
Фиг. 4 Подробности за план за изпълнение 593
Без индекс:Изход с включен STATISTICS IO:
Таблица „Фактури1“. Брой на сканирането 0, логическо четене 78372 , физическо четене 0, четене напред четене 0, лобно логическо четене 0, лоб физическо четене 0, лобно четене напред чете 0.
Таблица „Фактури“. Брой сканиране 1, логически четения 11400, физическо четене 0, четене напред четене 0, лобно логическо четене 0, лоб физическо четене 0, лобно четене напред чете 0.
(засегнати 70510 реда)
Индекс:Изход с включен STATISTICS IO:
Таблица „Фактури1“. Брой сканиране 0, логически четения 81119 , физическо четене 0, четене напред четене 0, лобно логическо четене 0, лоб физическо четене 0, лобно четене напред чете 0.
Таблица „Работна маса“. Брой на сканиране 0, логическо четене 0, физическо четене 0, четене напред 0, лобно логическо четене 0, лобно физическо четене 0, лобно четене напред четене 0.
Таблица „Фактури“. Брой сканиране 1, логически четения 11400 , физическо четене 0, четене напред четене 0, лобно логическо четене 0, лоб физическо четене 0, лобно четене напред чете 0.
(засегнати 70510 реда)
Допълнителна информация
Microsoft и други източници предоставят скриптове за изследване на производствената среда на индекси и идентифициране на такива ситуации като:
- Излишни индекси – Индекси, които се дублират
- Липсващи индекси – Индекси, които биха могли да подобрят производителността въз основа на натоварване
- Купини – Таблици без клъстерирани индекси
- Прекалено индексирани таблици – Таблици с повече индекси, отколкото колони
- Използване на индекс – Брой търсения, сканирания и търсения в индекси
Елементи 2, 3 и 5 са по-свързани с въздействието върху производителността по отношение на четенето, докато точки 1 и 4 са свързани с въздействието върху производителността по отношение на записванията. Списъци 4 и 5 са два примера за тези публично достъпни заявки.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Заключение
Ние показахме, използвайки Query Store, че допълнително натоварване с индекс може да въведе в плана за изпълнение на примерен израз за вмъкване. В производството прекомерните и излишни индекси могат да имат отрицателно въздействие върху производителността, особено в бази данни, предназначени за OLTP работни натоварвания. Важно е да използвате наличните скриптове и инструменти, за да проверите индексите и да определите дали те всъщност помагат или влошават производителността.
Полезен инструмент:
dbForge Index Manager – удобна добавка за SSMS за анализиране на състоянието на SQL индексите и отстраняване на проблеми с фрагментацията на индекса.