Функциите RANK, DENSE_RANK и ROW_NUMBER се използват за извличане на нарастваща целочислена стойност. Те започват със стойност, базирана на условието, наложено от клаузата ORDER BY. Всички тези функции изискват клаузата ORDER BY да функционира правилно. В случай на разделени данни, броячът на целочисленото число се нулира на 1 за всеки дял.
В тази статия ще проучим подробно функциите RANK, DENSE_RANK и ROW_NUMBER, но преди това нека създадем фиктивни данни, върху които тези функции могат да се използват, освен ако вашата база данни не е напълно архивирана.
Подготовка на фиктивни данни
Изпълнете следния скрипт, за да създадете база данни, наречена ShowRoom и съдържаща таблица, наречена Cars (която съдържа 15 произволни записа на автомобили):
CREATE Database ShowRoom; GO USE ShowRoom; CREATE TABLE Cars ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) USE ShowRoom INSERT INTO Cars VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 1500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 5000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200), (11, 'Atlas', 'Volkswagen', 5000), (12, '110', 'Bugatti', 8000), (13, 'Landcruiser', 'Toyota', 3000), (14, 'Civic', 'Honda', 1800), (15, 'Accord', 'Honda', 2000)
Функция RANK
Функцията RANK се използва за извличане на класирани редове въз основа на условието на клаузата ORDER BY. Например, ако искате да намерите името на автомобила с трета най-висока мощност, можете да използвате функцията RANK.
Нека видим функцията RANK в действие:
SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS PowerRank FROM Cars
Скриптът по-горе намира и класира всички записи в таблицата Cars и ги подрежда в низходящ ред. Резултатът изглежда така:
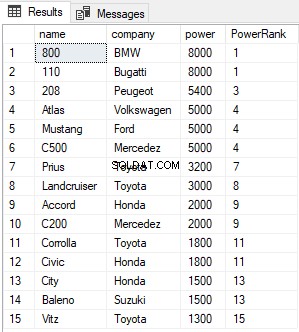
Колоната PowerRank в горната таблица съдържа RANK на колите, подредени по низходящ ред на тяхната мощност. Интересно нещо за функцията RANK е, че ако има връзка между N предишни записи за стойността в колоната ORDER BY, функциите RANK пропускат следващите N-1 позиции, преди да увеличат брояча. Например, в горния резултат има равенство за стойностите в колоната за мощност между 1-ви и 2-ри ред, следователно функцията RANK пропуска следващия (2-1 =1) един запис и прескача директно към 3-ия ред.
Функцията RANK може да се използва в комбинация с клаузата PARTITION BY. В този случай рангът ще бъде нулиран за всеки нов дял. Разгледайте следния скрипт:
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
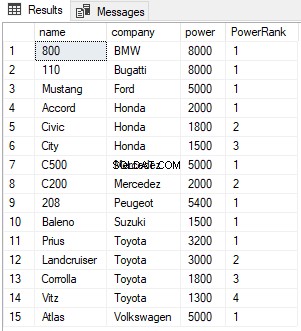
В скрипта по-горе разделяме резултатите по колона на компанията. Сега за всяка компания RANK ще бъде нулиран на 1, както е показано по-долу:
Функция DENSE_RANK
Функцията DENSE_RANK е подобна на функцията RANK, но функцията DENSE_RANK не пропуска нито един ранг, ако има равенство между ранговете на предходните записи. Разгледайте следния скрипт.
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
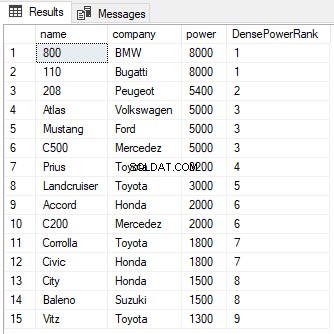
Можете да видите от изхода, че въпреки че има равенство между ранговете на първите два реда, следващият ранг не се пропуска и му е присвоена стойност от 2 вместо 3. Както при функцията RANK, клаузата PARTITION BY може да се използва и с функцията DENSE_RANK, както е показано по-долу:
SELECT name,company, power, DENSE_RANK() OVER(PARTITION BY company ORDER BY power DESC) AS DensePowerRank FROM Cars
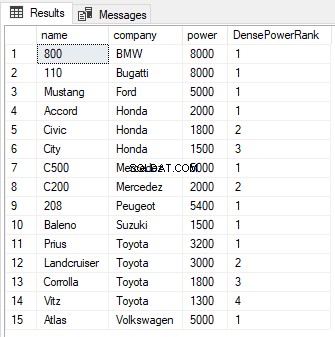
ROW_NUMBER функция
За разлика от функциите RANK и DENSE_RANK, функцията ROW_NUMBER просто връща номера на реда на сортираните записи, започващи с 1. Например, ако функциите RANK и DENSE_RANK на първите два записа в колоната ORDER BY са равни, и на двата се присвоява 1 като техен RANK и DENSE_RANK. Функцията ROW_NUMBER обаче ще присвои стойности 1 и 2 на тези редове, без да взема предвид факта, че те са еднакво взети предвид. Изпълнете следния скрипт, за да видите функцията ROW_NUMBER в действие.
SELECT name,company, power, ROW_NUMBER() OVER(ORDER BY power DESC) AS RowRank FROM Cars
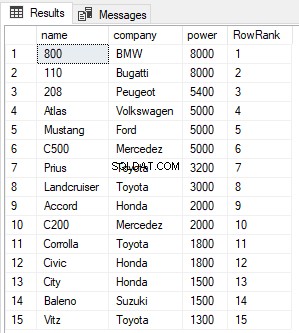
От изхода можете да видите, че функцията ROW_NUMBER просто присвоява нов номер на ред на всеки запис, независимо от неговата стойност.
Клаузата PARTITION BY може да се използва и с функцията ROW_NUMBER, както е показано по-долу:
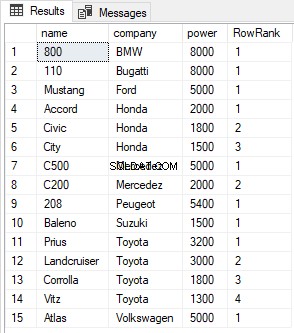
SELECT name, company, power, ROW_NUMBER() OVER(PARTITION BY company ORDER BY power DESC) AS RowRank FROM Cars
Резултатът изглежда така:
Прилики между функциите RANK, DENSE_RANK и ROW_NUMBER
Функциите RANK, DENSE_RANK и ROW_NUMBER имат следните прилики:
1- Всички те изискват подреждане по клауза.
2- Всички те връщат нарастващо цяло число с основна стойност 1.
3- Когато се комбинират с клауза PARTITION BY, всички тези функции нулират върнатата целочислена стойност на 1, както видяхме.
4- Ако няма дублирани стойности в колоната, използвана от клаузата ORDER BY, тези функциите връщат същия изход.
За да илюстрираме последната точка, нека създадем нова таблица Car1 в базата данни на ShowRoom без дублиращи се стойности в колоната за мощност. Изпълнете следния скрипт:
USE ShowRoom; CREATE TABLE Cars1 ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) INSERT INTO Cars1 VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 2500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 4000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200) The cars1 table has no duplicate values. Now let’s execute the RANK, DENSE_RANK and ROW_NUMBER functions on the Cars1 table ORDER BY power column. Execute the following script: SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars1
Резултатът изглежда така:
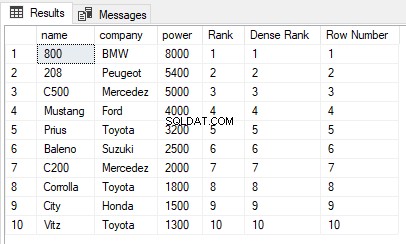
Можете да видите, че няма дублиращи се стойности в колоната за мощност, която се използва в клаузата ORDER BY, следователно изходът на функциите RANK, DENSE_RANK и ROW_NUMBER е един и същ.
Разлика между функции RANK, DENSE_RANK и ROW_NUMBER
Единствената разлика между функцията RANK, DENSE_RANK и ROW_NUMBER е, когато има дублиращи се стойности в колоната, използвани в клауза ORDER BY.
Ако се върнете към таблицата Cars в базата данни на ShowRoom, можете да видите, че съдържа много дублиращи се стойности. Нека се опитаме да намерим RANK, DENSE_RANK и ROW_NUMBER от таблицата Cars1, подредени по сила. Изпълнете следния скрипт:
ИЗБЕРЕТЕ име,компания, мощност,
RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars
Резултатът изглежда така:
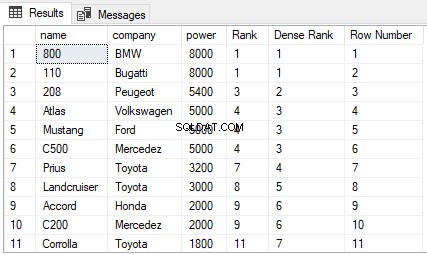
От изхода можете да видите, че функцията RANK пропуска следващите N-1 ранга, ако има равенство между N предишни рангове. От друга страна, функцията DENSE_RANK не пропуска ранговете, ако има равенство между ранговете. И накрая, функцията ROW_NUMBER няма отношение към класирането. Той просто връща номера на реда на сортираните записи. Дори ако има дублиращи се записи в колоната, използвана в клаузата ORDER BY, функцията ROW_NUMBER няма да върне дублирани стойности. Вместо това тя ще продължи да се увеличава независимо от дублиращите се стойности.
Полезни връзки:
За да научите повече за функциите ROW_NUMBER(), RANK() и DENSE_RANK(), прочетете фантастичната статия на Ahmad Yaseen:
Методи за класиране на редове в SQL Server:ROW_NUMBER(), RANK(), DENSE_RANK() и NTILE()