Има ли значение изборът ви на типове данни на SQL сървър и техните размери?
Отговорът се крие в резултата, който сте получили. Базата ви данни нарасна ли за кратко време? Бавни ли са вашите запитвания? Имахте ли грешни резултати? Какво ще кажете за грешки по време на изпълнение по време на вмъкване и актуализации?
Това не е толкова трудна задача, ако знаете какво правите. Днес ще научите 5-те най-лоши избора, които човек може да направи с тези типове данни. Ако са ви станали навик, това е нещото, което трябва да поправим заради вас и вашите потребители.
Много типове данни в SQL, много объркване
Когато за първи път научих за типовете данни на SQL Server, изборът беше огромен. Всички типове са смесени в съзнанието ми като този облак от думи на фигура 1:

Въпреки това можем да го организираме в категории:
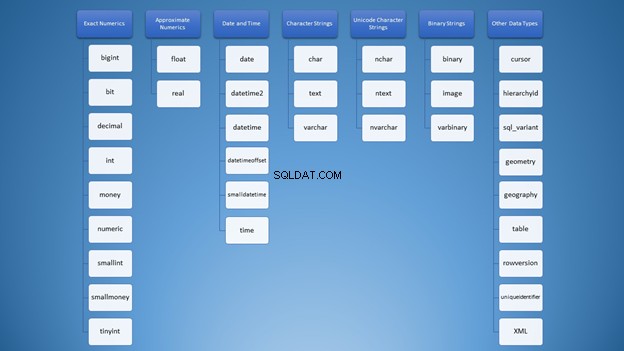
Все пак, за използването на низове, имате много опции, които могат да доведат до неправилно използване. Първоначално си помислих, че varchar и nvarchar бяха точно същите. Освен това и двете са тип символни низове. Използването на числа не е по-различно. Като разработчици, ние трябва да знаем кой тип да използваме в различни ситуации.
Но може да се чудите какво е най-лошото нещо, което може да се случи, ако направя грешен избор? Нека ти кажа!
1. Избор на грешни SQL типове данни
Този елемент ще използва низове и цели числа, за да докаже тезата.
Използване на грешен символен низ SQL тип данни
Първо, нека се върнем към струните. Има това нещо, наречено Unicode и не-Unicode низове. И двете имат различни размери за съхранение. Често дефинирате това в колони и декларации на променливи.
Синтаксисът е или varchar (n)/char (n) или nvarchar (n)/nchar (n) където n е размерът.
Имайте предвид, че n не е броят на знаците, а броят на байтовете. Това е често срещано погрешно схващане, което се случва, защото в varchar , броят на знаците е същият като размера в байтове. Но не и в nvarchar .
За да докажем този факт, нека създадем 2 таблици и да поставим някои данни в тях.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Сега нека проверим техните размери на редовете с помощта на DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Фигура 3 показва, че разликата е двойна. Вижте го по-долу.
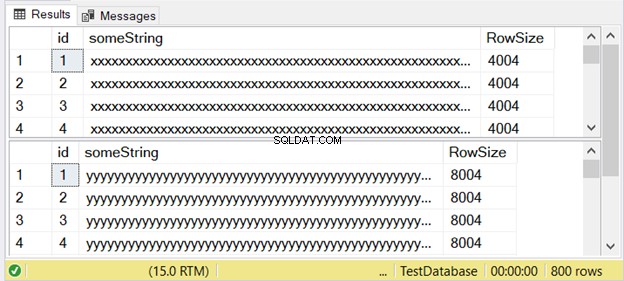
Забележете втория набор от резултати с размер на ред 8004. Това използва nvarchar тип данни. Освен това е почти два пъти по-голям от размера на реда на първия набор от резултати. И това използва varchar тип данни.
Виждате отражението върху съхранението и I/O. Фигура 4 показва логическите четения на 2-те заявки.
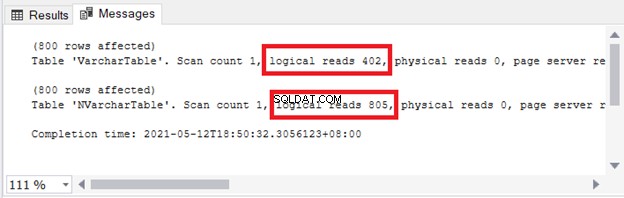
Виждаш ли? Логическите четения също са двойни, когато използвате nvarchar в сравнение с varchar .
Така че не можете просто да използвате взаимозаменяемо всеки. Ако трябва да съхранявате многоезични знаци, използвайте nvarchar . В противен случай използвайте varchar .
Това означава, че ако използвате nvarchar само за еднобайтови знаци (като английски), размерът на паметта е по-голям . Производителността на заявката е по-бавна с по-високи логически четения.
В SQL Server 2019 (и по-нова версия) можете да съхранявате пълния набор от данни за символи в Unicode, като използвате varchar или char с някоя от опциите за съпоставяне UTF-8.
Използване на грешен числов тип SQL на данни
Същата концепция важи и заbigint срещу int – техните размери могат да означават ден и нощ. Като nvarchar и varchar , голям е двойно по-голям от int (8 байта за bigint и 4 байта за int ).
Все пак е възможен друг проблем. Ако нямате нищо против размерите им, може да възникнат грешки. Ако използвате int колона и запишете число, по-голямо от 2 147 483 647, ще възникне аритметично препълване:
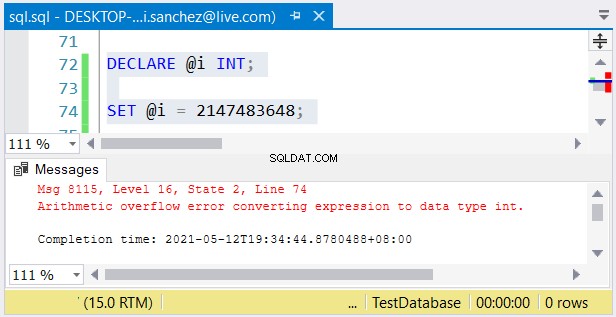
Когато избирате типове цели числа, уверете се, че данните с максимална стойност ще се поберат . Например, може да проектирате таблица с исторически данни. Планирате да използвате цели числа като стойност на първичен ключ. Мислите ли, че няма да достигне 2 147 483 647 реда? След това използвайте int вместо голям като тип колона с първичен ключ.
Най-лошото нещо, което може да се случи
Изборът на грешен тип данни може да повлияе на производителността на заявката или да причини грешки по време на изпълнение. По този начин изберете типа данни, който е подходящ за данните.
2. Създаване на големи редове в таблицата с помощта на големи типове данни за SQL
Следващият ни елемент е свързан с първия, но ще разшири темата още повече с примери. Освен това има нещо общо със страниците и големия varchar или nvarchar колони.
Какво става със страниците и размерите на редовете?
Концепцията за страници в SQL Server може да се сравни със страниците на спираловиден бележник. Всяка страница в бележника има същия физически размер. Пишете думи и рисувате картини върху тях. Ако една страница не е достатъчна за набор от параграфи и снимки, продължавате на следващата страница. Понякога също разкъсате страница и започнете отначало.
По същия начин данните от таблицата, записите в индекса и изображенията в SQL Server се съхраняват в страници.
Страница има същия размер от 8 KB. Ако ред с данни е много голям, той няма да се побере на страницата от 8 KB. Една или повече колони ще бъдат записани на друга страница под единицата за разпределение ROW_OVERFLOW_DATA. Той съдържа указател към оригиналния ред на страницата под единицата за разпределение IN_ROW_DATA.
Въз основа на това не можете просто да поставите много колони в таблица по време на проектирането на базата данни. Ще има последствия за I/O. Освен това, ако правите много заявки за тези данни за препълване на редове, времето за изпълнение е по-бавно . Това може да е кошмар.
Проблем възниква, когато максимизирате всички колони с различен размер. След това данните ще се разлеят на следващата страница под ROW_OVERFLOW_DATA. актуализирайте колоните с данни с по-малък размер и те трябва да бъдат премахнати на тази страница. Новият по-малък ред с данни ще бъде написан на страницата под IN_ROW_DATA заедно с другите колони. Представете си входно/изходното участие тук.
Пример за голям ред
Нека първо подготвим нашите данни. Ще използваме типове данни за низове от знаци с големи размери.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Получаване на размера на реда
От генерираните данни, нека проверим техните размери на редове въз основа на DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
Първите 300 записа ще се поберат на страниците IN_ROW_DATA, тъй като всеки ред има по-малко от 8060 байта или 8 KB. Но последните 100 реда са твърде големи. Вижте набора от резултати на фигура 6.
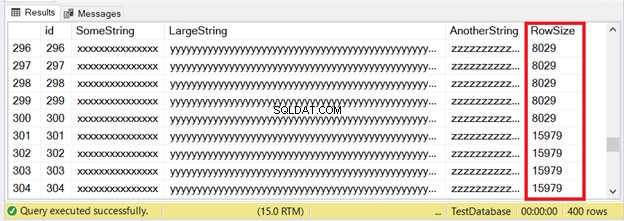
Виждате част от първите 300 реда. Следващите 100 надвишават ограничението за размер на страницата. Как да разберем, че последните 100 реда са в единицата за разпределение ROW_OVERFLOW_DATA?
Проверка на ROW_OVERFLOW_DATA
Ще използваме sys.dm_db_index_physical_stats . Връща информация за страницата за записи в таблица и индекс.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Резултатът е на фигура 7.

Ето го. Фигура 7 показва 100 реда под ROW_OVERFLOW_DATA. Това е в съответствие с фигура 6, когато съществуват големи редове, започващи с редове от 301 до 400.
Следващият въпрос е колко логически показания получаваме, когато запитаме тези 100 реда. Нека опитаме.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Виждаме 102 логически четения и 100 логически четения на LargeTable . Оставете тези числа засега – ще ги сравним по-късно.
Сега нека видим какво ще се случи, ако актуализираме 100-те реда с по-малки данни.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Този оператор за актуализиране използва същите логически четения и логически четения, както на фигура 8. От това знаем, че се е случило нещо по-голямо поради логическите четения на lob на 100 страници.
Но за да сме сигурни, нека го проверим с sys.dm_db_index_physical_stats както направихме по-рано. Фигура 9 показва резултата:

Си отиде! Страниците и редовете от ROW_OVERFLOW_DATA станаха нула след актуализиране на 100 реда с по-малки данни. Сега знаем, че движението на данните от ROW_OVERFLOW_DATA към IN_ROW_DATA се случва, когато големи редове се свиват. Представете си, ако това се случи много за хиляди или дори милиони записи. Лудо, нали?
На фигура 8 видяхме 100 логически четения. Сега вижте Фигура 10 след повторно изпълнение на заявката:

Стана нула!
Най-лошото нещо, което може да се случи
Бавната производителност на заявката е страничен продукт на данните за препълване на редове. Помислете за преместване на колоните с голям размер в друга таблица, за да го избегнете. Или, ако е приложимо, намалете размера на varchar или nvarchar колона.
3. Сляпо използване на имплицитно преобразуване
SQL не ни позволява да използваме данни без да посочим типа. Но е прощаващо, ако направим грешен избор. Той се опитва да преобразува стойността в типа, който очаква, но с наказание. Това може да се случи в клауза WHERE или JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Номерът на картата колоната не е числов тип. Това е nvarchar . И така, първият SELECT ще причини имплицитно преобразуване. И двете обаче ще работят добре и ще дадат същия набор от резултати.
Нека проверим плана за изпълнение на фигура 11.
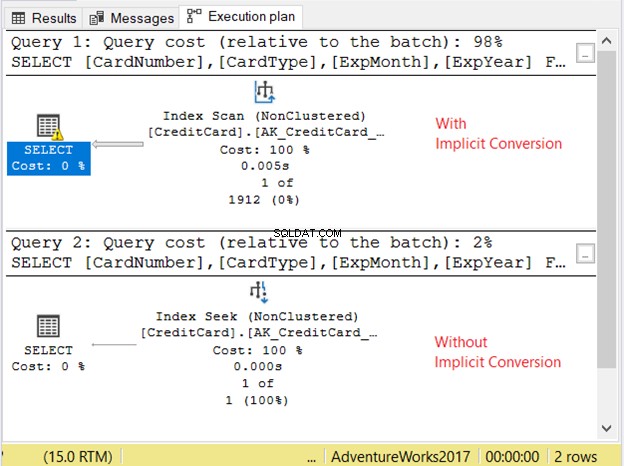
2-те заявки се изпълниха много бързо. На фигура 11 това е нула секунди. Но вижте 2-те плана. Този с имплицитно преобразуване имаше индексно сканиране. Има също икона за предупреждение и дебела стрелка, сочеща оператора SELECT. Това ни казва, че е лошо.
Но това не свършва дотук. Ако задържите курсора на мишката върху оператора SELECT, ще видите нещо друго:

Иконата за предупреждение в оператора SELECT е за имплицитното преобразуване. Но колко голямо е въздействието? Нека проверим логическите показания.
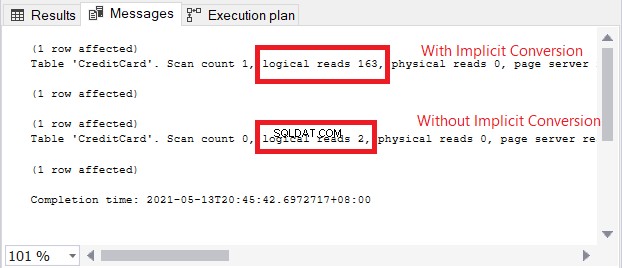
Сравнението на логическите показания на фигура 13 е като небето и земята. При заявката за информация за кредитна карта имплицитното преобразуване предизвика повече от стократно логически четения. Много лошо!
Най-лошото нещо, което може да се случи
Ако неявно преобразуване е причинило високи логически четения и лош план, очаквайте бавна производителност на заявката при големи набори от резултати. За да избегнете това, използвайте точния тип данни в клаузата WHERE и JOIN за съпоставяне на колоните, които сравнявате.
4. Използване на приблизителни числа и закръгляне
Вижте отново фигура 2. Типовете данни на SQL сървъра, принадлежащи към приблизителните числа, са float и истински . Колони и променливи, направени от тях, съхраняват близко приближение на числова стойност. Ако планирате да закръглите тези числа нагоре или надолу, може да получите голяма изненада. Имам статия, която обсъжда подробно това тук. Вижте как 1 + 1 води до 3 и как можете да се справите със закръгляването на числата.
Най-лошото нещо, което може да се случи
Закръгляване на поплавък или истински може да има луди резултати. Ако искате точни стойности след закръгляване, използвайте десетични или числово вместо това.
5. Задаване на низови данни с фиксиран размер на NULL
Нека насочим вниманието си към типове данни с фиксиран размер като char и nchar . Освен подплатените интервали, задаването им на NULL пак ще има размер за съхранение, равен на размера на char колона. И така, задаване на char (500) колона до NULL ще има размер 500, а не нула или 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
В горния код данните са изчерпани въз основа на размера на char и varchar колони. Проверката на техния размер на ред с помощта на DATALENGTH също ще покаже сумата от размерите на всяка колона. Сега нека зададем колоните на NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
След това правим заявка за редовете, използвайки DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Какви според вас ще бъдат размерите на данните за всяка колона? Вижте фигура 14.
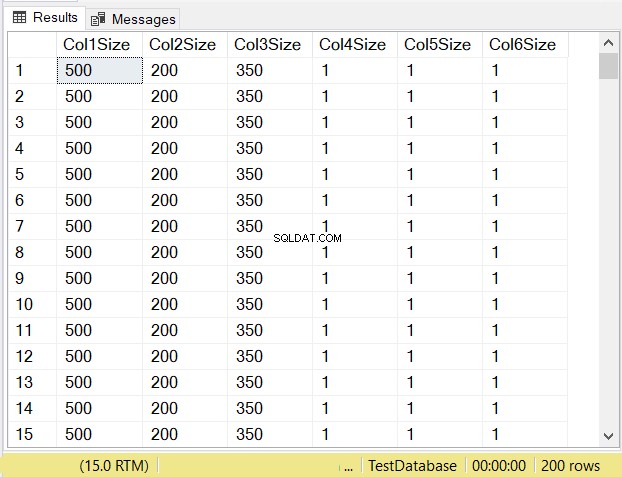
Вижте размерите на колоните на първите 3 колони. След това ги сравнете с кода по-горе, когато е създадена таблицата. Размерът на данните на колоните NULL е равен на размера на колоната. Междувременно varchar колони, когато NULL имат размер на данните 1.
Най-лошото нещо, което може да се случи
По време на проектиране на таблици, nullable char колоните, когато са зададени на NULL, пак ще имат същия размер за съхранение. Те също ще консумират същите страници и RAM. Ако не попълните цялата колона със знаци, помислете за използването на varchar вместо това.
Какво следва?
И така, има ли значение изборът ви в типовете данни на SQL сървъра и техните размери? Представените тук точки трябва да са достатъчни, за да се направи точка. И така, какво можете да направите сега?
- Отделете време за преглед на базата данни, която поддържате. Започнете с най-лесния, ако имате няколко в чинията си. И да, намирайте време, а не намирайте време. В нашата сфера на работа е почти невъзможно да намерим време.
- Прегледайте таблиците, съхранените процедури и всичко, което се занимава с типове данни. Отбележете положителното въздействие при идентифициране на проблеми. Ще ви трябва, когато шефът ви попита защо трябва да работите върху това.
- Планирайте да атакувате всяка от проблемните области. Следвайте каквито и методики или политики да има вашата компания за справяне с проблемите.
- След като проблемите изчезнат, празнувайте.
Звучи лесно, но всички знаем, че не е. Ние също така знаем, че има светла страна в края на пътуването. Ето защо те се наричат проблеми – защото има решение. Така че, развесели се.
Имате ли още нещо да добавите по тази тема? Уведомете ни в секцията за коментари. И ако тази публикация ви даде ярка идея, споделете я в любимите си социални медийни платформи.