Отдавна отминаха дните, когато базата данни беше разгърната като един възел или екземпляр - мощен, самостоятелен сървър, който имаше задача да обработва всички заявки към базата данни. Вертикалното мащабиране беше правилният начин - заменете сървъра с друг, още по-мощен. През тези времена човек наистина не трябва да се притеснява от производителността на мрежата. Докато заявките идваха, всичко беше наред.
Но в днешно време базите данни се изграждат като клъстери с възли, свързани помежду си през мрежа. Това не винаги е бърза локална мрежа. С бизнеса, достигащ глобален мащаб, инфраструктурата на базата данни трябва също да обхваща целия свят, за да остане близо до клиентите и да намали латентността. Той идва с допълнителни предизвикателства, с които трябва да се сблъскаме, когато проектираме високодостъпна среда на база данни. В тази публикация в блога ще разгледаме проблемите с мрежата, с които може да се сблъскате, и ще предоставим някои предложения как да се справите с тях.
Две основни опции за MySQL или MariaDB HA
Покрихме тази конкретна тема доста подробно в един от белите документи, но нека разгледаме двата основни начина за изграждане на висока наличност за MySQL и MariaDB.
Galera Cluster
Galera Cluster е практически синхронна клъстерна технология за MySQL, която не се споделя. Позволява да се изградят настройки с множество записващи устройства, които могат да обхващат целия свят. Galera процъфтява в среди с ниска латентност, но също така може да бъде конфигурирана да работи с дълги WAN връзки. Galera има вграден механизъм за кворум, който гарантира, че данните няма да бъдат компрометирани в случай на разделяне на мрежата на някои от възлите.
Репликация на MySQL
MySQL репликацията може да бъде както асинхронна, така и полусинхронна. И двете са проектирани за изграждане на широкомащабни клъстери за репликация. Както при всяка друга настройка на главен-подчинен или първично-вторичен репликация, може да има само един записващ, главен. Други възли, подчинени, се използват за целите на отказване, тъй като съдържат копие на набора от данни от мазера. Подчинените могат също да се използват за четене на данните и разтоварване на част от натоварването от главния.
И двете решения имат свои собствени граници и характеристики, и двете страдат от различни проблеми. И двете могат да бъдат засегнати от нестабилни мрежови връзки. Нека да разгледаме тези ограничения и как можем да проектираме средата, за да сведем до минимум въздействието на нестабилна мрежова инфраструктура.
Galera Cluster – Проблеми с мрежата
Първо, нека да разгледаме Galera Cluster. Както обсъдихме, той работи най-добре в среда с ниска латентност. Един от основните проблеми, свързани с латентността в Galera, е начинът, по който Galera обработва записите. Няма да навлизаме във всички подробности в този блог, а ще прочетете допълнително в нашия урок за Galera Cluster за MySQL. Изводът е, че поради процеса на сертифициране за записи, където всички възли в клъстера трябва да се споразумеят дали записът може да бъде приложен или не, вашата производителност на запис за един ред е строго ограничена от времето за двупосочно предаване на мрежата между записващия възел и най-далечният възел. Докато латентността е приемлива и стига да нямате твърде много горещи точки в данните си, настройките на WAN може да работят добре. Проблемът започва, когато латентността на мрежата скача от време на време. След това записването ще отнеме 3 или 4 пъти по-дълго от обикновено и в резултат на това базите данни може да започнат да се претоварват с продължителни записи.
Една от страхотните характеристики на Galera Cluster е способността му да открива състоянието на клъстера и да реагира при разделяне на мрежата. Ако възел на клъстера не може да бъде достигнат, той ще бъде изгонен от клъстера и няма да може да извършва никакви записи. Това е от решаващо значение за поддържането на целостта на данните през времето, когато клъстерът е разделен - само по-голямата част от клъстера ще приема запис. Малцинството ще се оплаче. За да се справи с това, Galera въвежда огромен набор от проверки и конфигурируеми изчаквания, за да избегне фалшиви сигнали при много преходни мрежови проблеми. За съжаление, ако мрежата е ненадеждна, Galera Cluster няма да може да работи правилно - възлите ще започнат да напускат клъстера, присъединете се към него по-късно. Ще бъде особено проблематично, когато имаме Galera Cluster, обхващащ WAN – отделните части от клъстера може да изчезнат произволно, ако свързващата се мрежа няма да работи правилно.
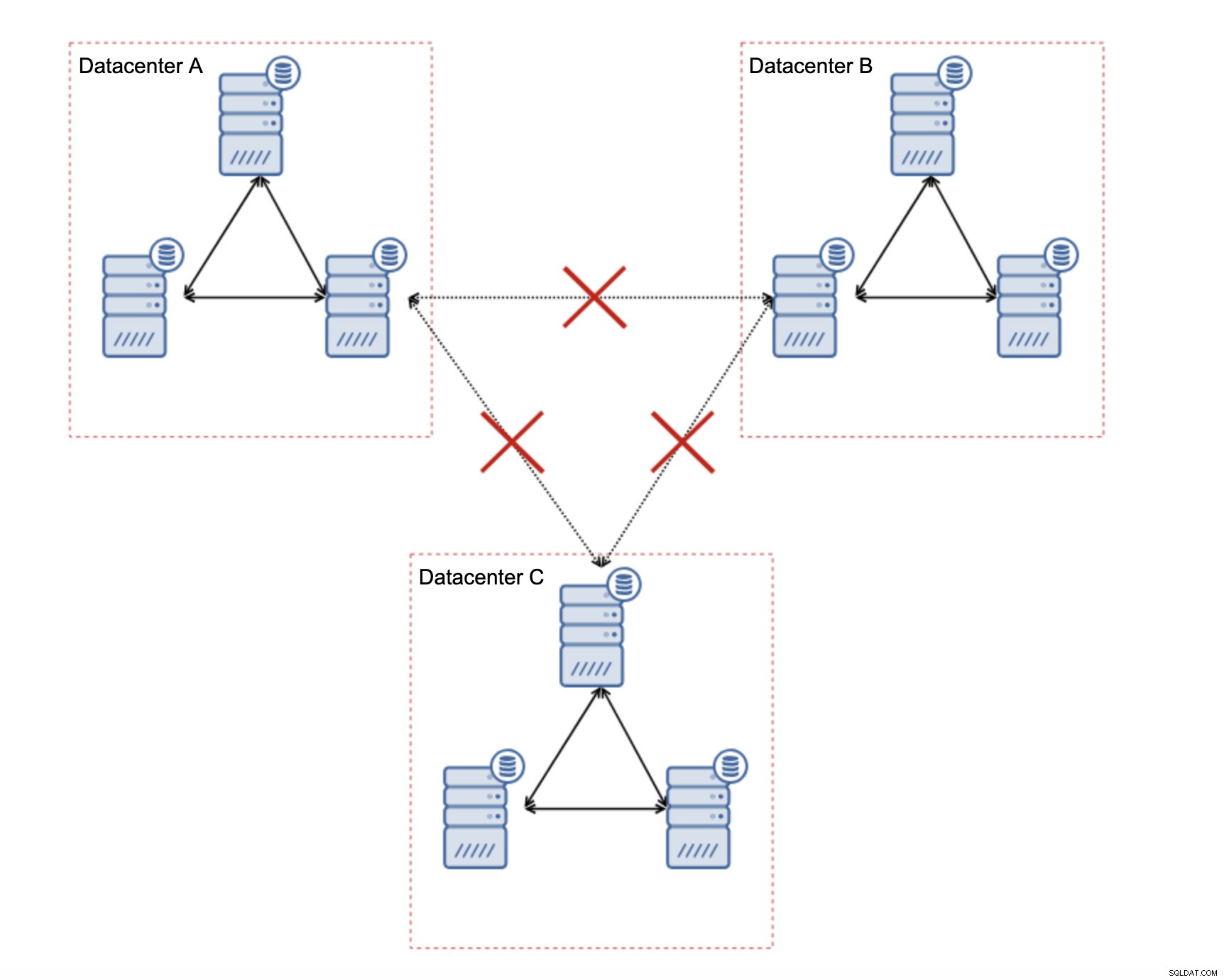
Как да проектираме клъстер Galera за нестабилна мрежа?
Първо, ако имате проблеми с мрежата в рамките на един център за данни, не можете да направите много, освен ако не успеете да разрешите тези проблеми по някакъв начин. Ненадеждната локална мрежа не е подходяща за Galera Cluster, трябва да преосмислите използването на някакво друго решение (въпреки че, честно казано, ненадеждната мрежа винаги ще бъде проблематична). От друга страна, ако проблемите са свързани само с WAN връзки (а това е един от най-типичните случаи), може да е възможно да се заменят WAN Galera връзки с редовно асинхронно репликация (ако настройката на Galera WAN не помогна).
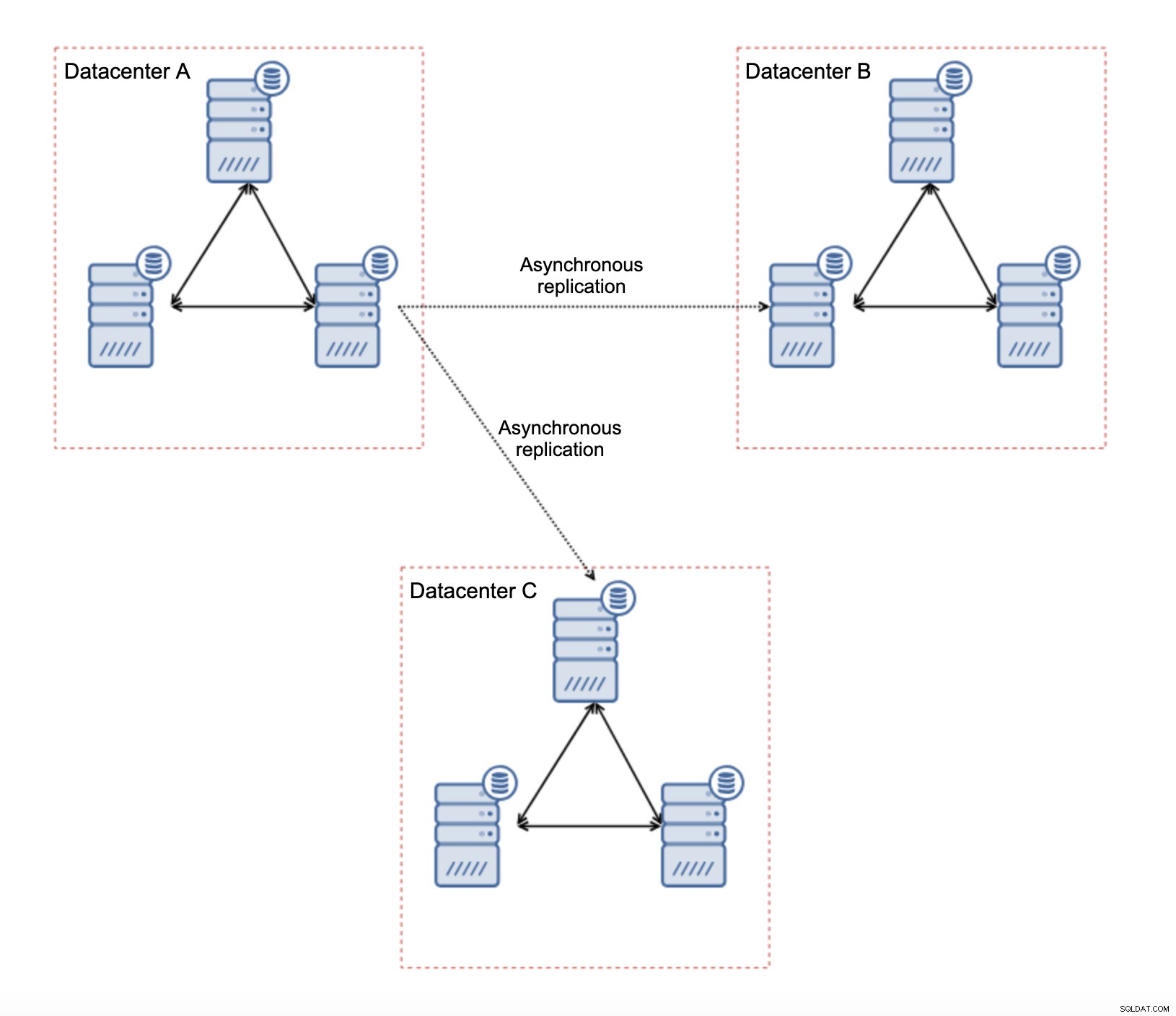
Има няколко присъщи ограничения в тази настройка - основният проблем е, че записите се случваха локално. Сега всички записи ще трябва да се насочат към „главния“ център за данни (DC A в нашия случай). Това не е толкова лошо, колкото звучи. Моля, имайте предвид, че в среда изцяло на Galera записите ще бъдат забавени от латентността между възлите, разположени в различни центрове за данни. Дори местните записи ще бъдат засегнати. Това ще бъде горе-долу същото забавяне като при асинхронна настройка, при която изпращате записите през WAN към „главния“ център за данни.
Използването на асинхронна репликация идва с всички проблеми, типични за асинхронната репликация. Закъснението при репликацията може да се превърне в проблем – не че Galera ще бъде по-ефективна, просто Galera ще забави трафика чрез контрол на потока, докато репликацията няма никакъв механизъм за ограничаване на трафика на главния.
Друг проблем е отказът:ако „главният“ възел на Galera (този, който действа като главен на подчинените в други центрове за данни) се повреди, трябва да се създаде някакъв механизъм за пренасочване на подчинените към друг, работещ главен възел. Може да е някакъв скрипт, също така е възможно да опитате нещо с VIP, при което „подчинения“ клъстер на Galera подчинява виртуален IP адрес, който винаги се присвоява на живия възел на Galera в „главния“ клъстер.
Основното предимство на такава настройка е, че премахваме връзката WAN Galera, което означава, че нашият „главен“ клъстер няма да бъде забавен от факта, че някои от възлите са разделени географски. Както споменахме, губим способността да пишем във всички центрове за данни, но писането по отношение на латентността в WAN е същото като писането локално в клъстера Galera, който се простира през WAN. В резултат на това общата латентност трябва да се подобри. Асинхронната репликация също е по-малко уязвима към нестабилните мрежи. В най-лошия случай връзката за репликация ще прекъсне и ще бъде пресъздадена, когато мрежите се сближат.
Как да проектираме MySQL репликация за нестабилна мрежа?
В предишния раздел разгледахме клъстера Galera и едно от решенията беше да използваме асинхронна репликация. Как изглежда в обикновена настройка на асинхронна репликация? Нека разгледаме как една нестабилна мрежа може да причини най-големите смущения в настройката за репликация.
На първо място, латентността - една от основните болезнени точки за Galera Cluster. В случай на репликация, това почти не е проблем. Освен ако не използвате полусинхронна репликация - в такъв случай увеличената латентност ще забави записите. При асинхронна репликация латентността не оказва влияние върху производителността на запис. Това обаче може да има известно влияние върху забавянето на репликацията. Това не е нещо толкова важно, колкото беше за Galera, но може да очаквате повече пикове на забавяне и цялостна по-малко стабилна производителност на репликация, ако мрежата между възлите страда от висока латентност. Това се дължи най-вече на факта, че главният може също така да обслужва няколко записа, преди да започне прехвърлянето на данни към подчинения в мрежа с висока латентност.
Нестабилността на мрежата определено може да повлияе на връзките за репликация, но отново не е толкова критично. Подчинените на MySQL устройства ще се опитат да се свържат отново със своите главни и репликацията ще започне.
Основният проблем с MySQL репликацията всъщност е нещо, което Galera Cluster решава вътрешно - мрежово разделяне. Говорим за разделянето на мрежата като условие, при което сегментите на мрежата са отделени един от друг. MySQL репликацията използва един единствен записващ възел - главен. Без значение как проектирате вашата среда, трябва да изпратите вашите записи на капитана. Ако главният не е наличен (по каквито и да е причини), приложението не може да свърши своята работа, освен ако не работи в някакъв режим само за четене. Следователно има нужда да изберете новия господар възможно най-скоро. Тук се появяват проблемите.
Първо, как да разберете кой хост е главен и кой не. Един от обичайните начини е да се използва променливата “read_only” за разграничаване на подчинените от главния. Ако възелът е активирал read_only (зададе read_only=1), той е подчинен (тъй като подчинените не трябва да обработват никакви директни записи). Ако възелът е деактивиран само за четене (задайте read_only=0), това е главен. За да направим нещата по-безопасни, често срещан подход е да зададете read_only=1 в конфигурацията на MySQL - в случай на рестарт е по-безопасно, ако възелът се покаже като подчинен. Такъв „език“ може да бъде разбран от прокси сървъри като ProxySQL или MaxScale.
Нека да разгледаме пример.
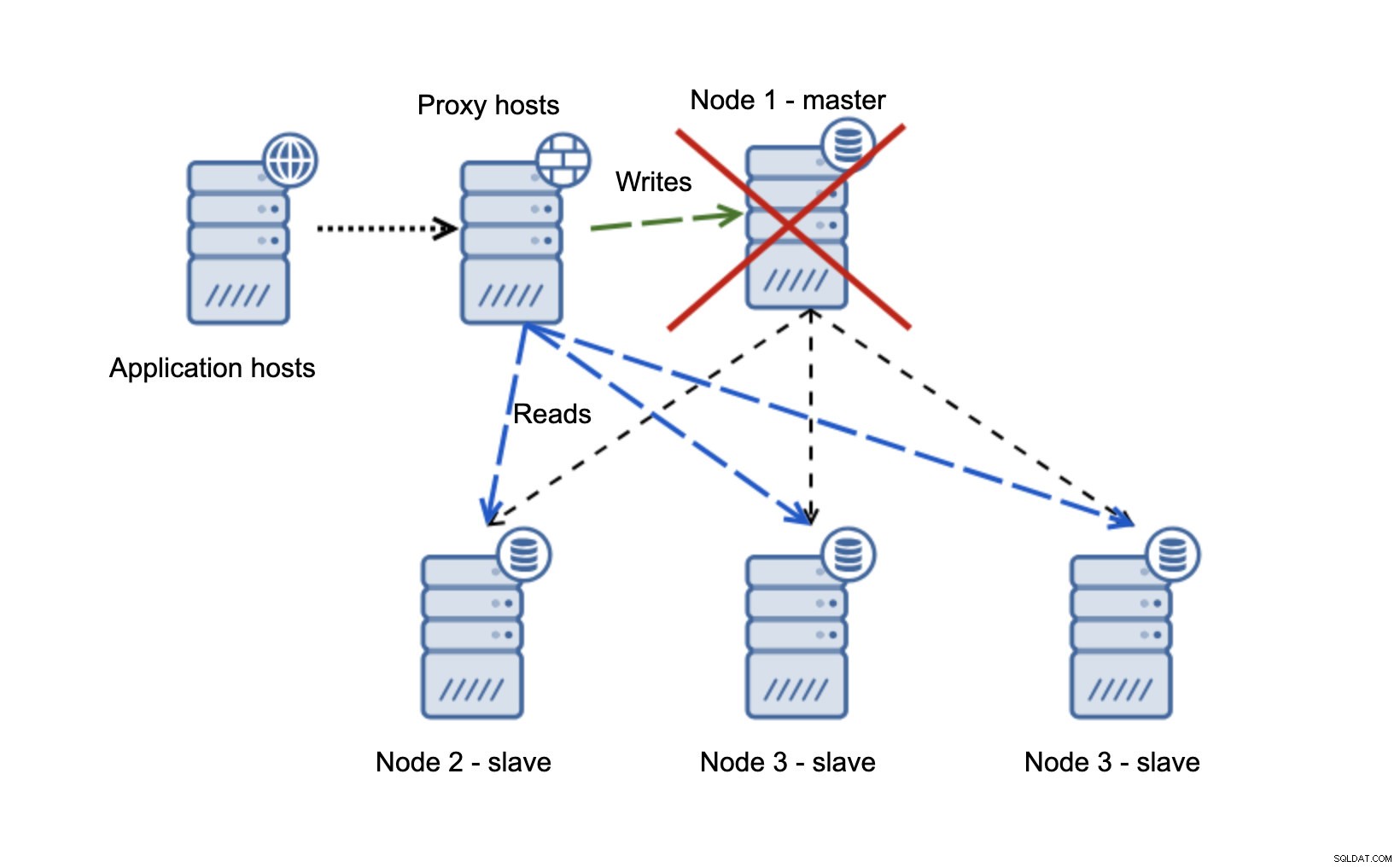
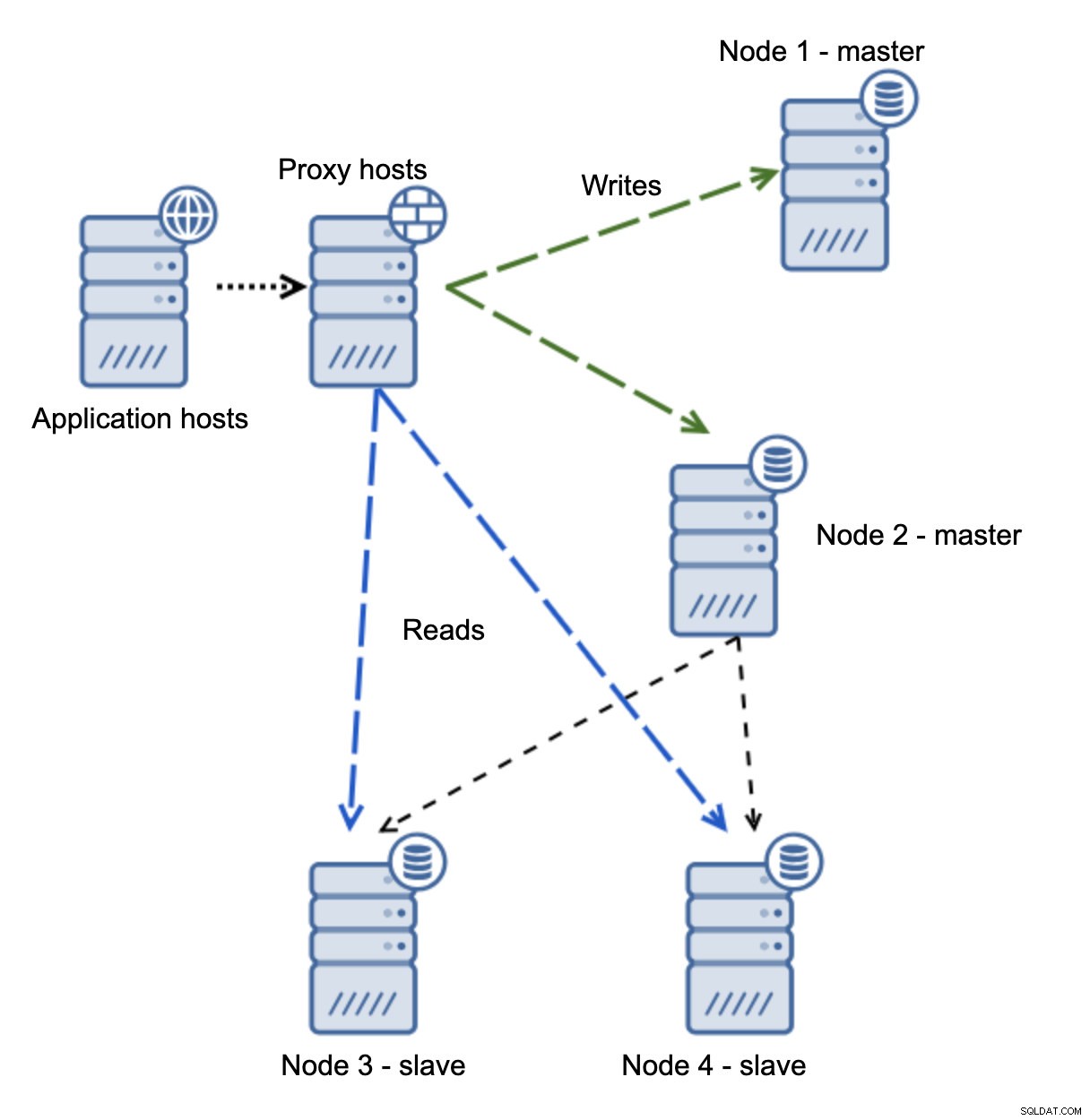
Имаме хостове на приложения, които се свързват към прокси слоя. Прокситата извършват разделянето на четене/запис, изпращайки SELECT към подчинени и записва към главен. Ако главният не работи, се извършва преодоляване на срив, нов главен се повишава, прокси слоят открива това и започва да изпраща записи до друг възел.
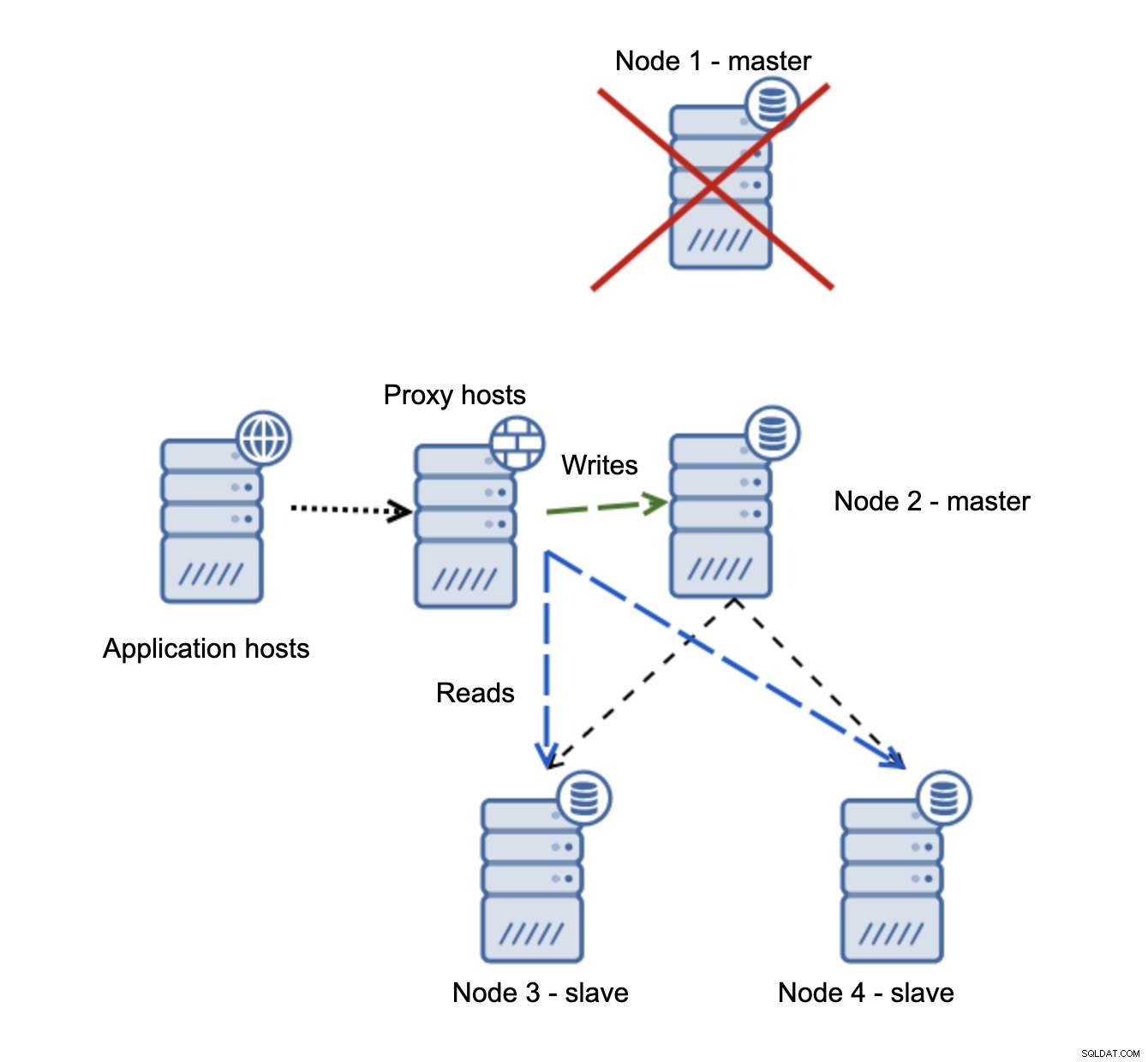
Ако node1 се рестартира, той ще излезе с read_only=1 и ще бъде открит като подчинен. Не е идеален, тъй като не се възпроизвежда, но е приемлив. В идеалния случай старият господар изобщо не трябва да се показва, докато не бъде възстановен и подчинен на новия господар.
Много по-проблемна ситуация е, ако трябва да се справим с разделяне на мрежата. Нека разгледаме същата настройка:ниво на приложение, прокси ниво и бази данни.
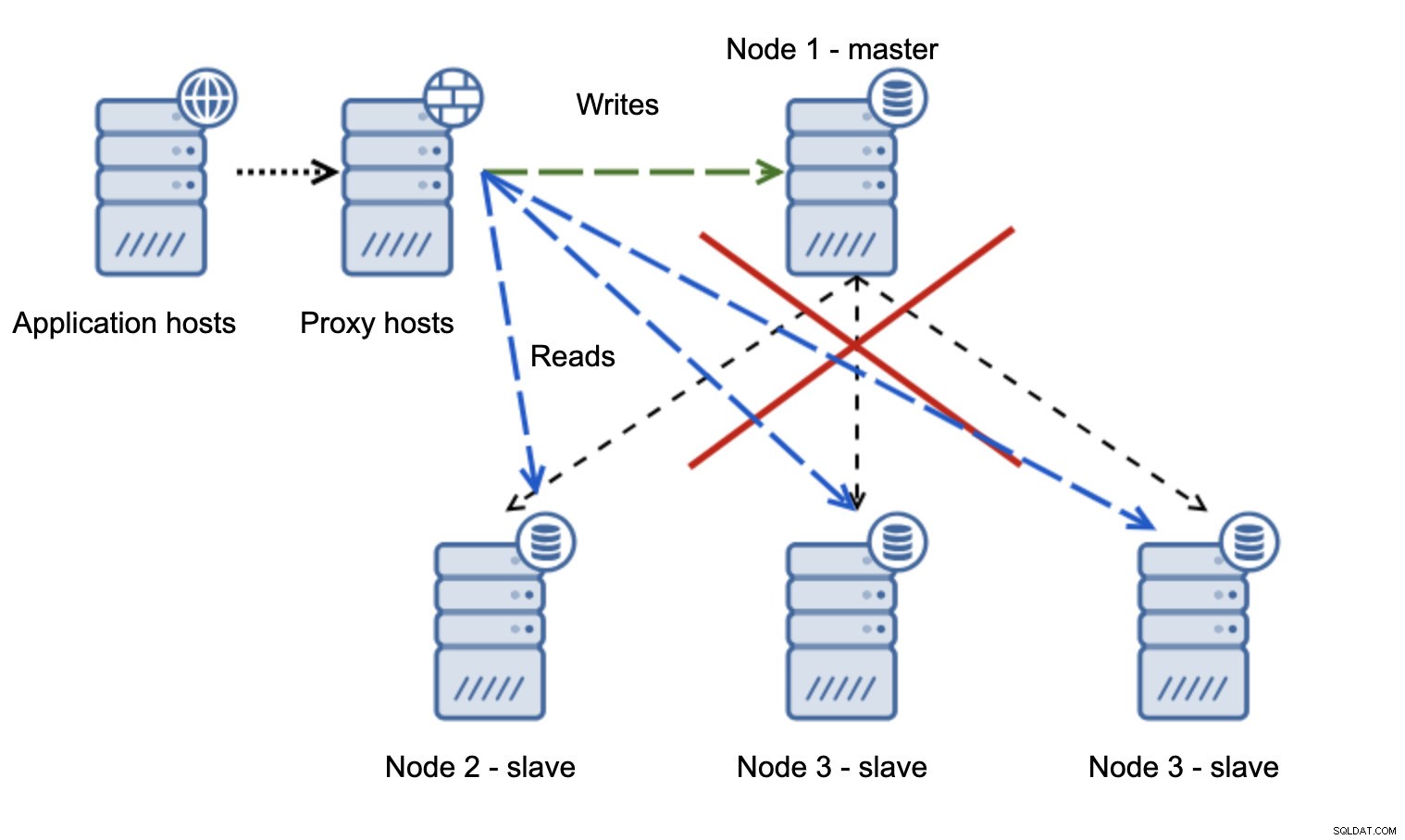
Когато мрежата направи главната недостъпна, приложението не може да се използва, тъй като няма записвания да стигне до местоназначението си. Новият майстор е повишен, записите се пренасочват към него. Какво ще се случи тогава, ако проблемите с мрежата престанат и старият хозяин стане достъпен? Не е спрян, следователно все още използва read_only=0:
Вече сте се озовали в раздвоен мозък, когато записите са били насочени към два възела. Тази ситуация е доста лоша, тъй като обединяването на различни набори от данни може да отнеме известно време и е доста сложен процес.
Какво може да се направи, за да се избегне този проблем? Няма сребърен куршум, но могат да се предприемат някои действия, за да се сведе до минимум вероятността от разцепване на мозъка.
На първо място, можете да бъдете по-умни в откриването на състоянието на главния. Как го виждат робите? Могат ли да се репликират от него? Може би някои от подчинените все още могат да се свържат с главната, което означава, че главният е готов и работи или поне прави възможно спирането му, ако е необходимо. Какво ще кажете за прокси слоя? Всички прокси възли виждат ли главния елемент като недостъпен? Ако някои все още могат да се свържат, тогава можете да опитате да използвате тези възли за ssh в главния и да го спрете преди отказ?
Софтуерът за управление на отказ също може да бъде по-интелигентен при откриване на състоянието на мрежата. Може би използва RAFT или някакъв друг протокол за клъстериране, за да изгради клъстер, осъзнаващ кворума. Ако софтуерът за управление на отказ може да открие разделения мозък, той може също да предприеме някои действия въз основа на това, като например да настрои всички възли в разделения сегмент на read_only, като гарантира, че старият главен файл няма да се покаже като записващ, когато мрежите се сближат.
Можете също да включите инструменти като Consul или Etcd за съхраняване на състоянието на клъстера. Прокси слоят може да бъде конфигуриран да използва данни от Consul, а не състоянието на променливата read_only. След това софтуерът за управление на откази ще направи необходимите промени в Consul, така че всички прокси сървъри да изпращат трафика към правилния, нов главен.
Някои от тези съвети могат дори да бъдат комбинирани заедно, за да направят откриването на повреда още по-надеждно. Като цяло е възможно да се сведат до минимум шансовете клъстерът за репликация да страда от ненадеждни мрежи.
Както можете да видите, без значение дали говорим за Galera или MySQL репликация, нестабилните мрежи могат да се превърнат в сериозен проблем. От друга страна, ако проектирате средата правилно, все още можете да я накарате да работи. Надяваме се, че тази публикация в блога ще ви помогне да създадете среди, които ще работят стабилно, дори ако мрежите не са.