Вътрешно съединение, външно съединение, кръстосано съединение? Какво дава?
Това е валиден въпрос. Веднъж видях код на Visual Basic с T-SQL кодове, вградени в него. VB кодът извлича записи на таблица с множество изрази SELECT, по един SELECT * на таблица. След това комбинира множество набори от резултати в набор от записи. Абсурдно?
За младите разработчици, които го направиха, не беше. Но когато ме помолиха да преценя защо системата е бавна, този въпрос беше първият, който привлече вниманието ми. Това е вярно. Никога не са чували за SQL присъединявания. Честно казано към тях, те бяха честни и отворени за предложения.
Как описвате SQL присъединяванията? Може би си спомняте една песен – Imagine от Джон Ленън:
Можете да кажете, че съм мечтател, но не съм единственият.
Надявам се някой ден да се присъедините към нас и светът ще бъде като едно цяло.
В контекста на песента присъединяването е обединяване. В SQL база данни, комбинирането на записи от 2 или повече таблици в един набор от резултати образува присъединяване .
Тази статия е началото на поредица от 3 части, която говори за SQL присъединявания:
- INNER JOIN
- ВЪНШНО ПРИЕДИНЕНИЕ, което включва ЛЯВО, ДЯСНО и ПЪЛНО
- Кръстосано присъединяване
Но преди да започнем да обсъждаме INNER JOIN, нека опишем присъединяванията като цяло.

Още за SQL JOIN
Съединенията се появяват веднага след клаузата FROM. В най-простата си форма изглежда като използване на стандарта SQL-92:
FROM <table source> [<alias1>]
<join type> JOIN <table source> [<alias2>] [ON <join condition>]
[<join type> JOIN <table source> [<alias3>] [ON <join condition>]
<join type> JOIN <table source> [<aliasN>] [ON <join condition>]]
[WHERE <condition>]Нека опишем ежедневните неща около JOIN.
Източници на таблица
Можете да добавите до 256 източника на таблици, според Microsoft. Разбира се, зависи от ресурсите на вашия сървър. Никога не съм се присъединил към повече от 10 маси в живота си, да не говорим за 256. Както и да е, източниците на таблица могат да бъдат някои от следните:
- Таблица
- Преглед
- Синоним на таблица или изглед
- Променлива в таблицата
- Функция със стойност на таблица
- Извлечена таблица
Псевдоним на таблица
Псевдонимът не е задължителен, но съкращава кода ви и свежда до минимум въвеждането. Също така ви помага да избягвате грешки, когато име на колона съществува в две или повече таблици, използвани в SELECT, UPDATE, INSERT или DELETE. Освен това добавя яснота към вашия код. Не е задължително, но бих препоръчал да използвате псевдоними. (Освен ако не обичате да пишете източници на таблица по име.)
Условие за присъединяване
Ключовата дума ON предхожда условието за присъединяване, което може да бъде едно съединение или колони с 2 ключа от 2-те присъединени таблици. Или може да бъде съставно съединение, използващо повече от 2 ключови колони. Той определя как таблиците са свързани.
Въпреки това, ние използваме условието за присъединяване само за INNER и OUTER присъединения. Използването му при CROSS JOIN ще предизвика грешка.
Тъй като условията за присъединяване определят връзките, те се нуждаят от оператори.
Най-често срещаният оператор за условие за присъединяване е операторът за равенство (=). Други оператори като> или <също работят, но са рядкост.
SQL JOIN срещу подзаявки
Повечето обединения могат да бъдат пренаписани като подзаявки и обратно. Вижте тази статия, за да научите повече за подзаявките в сравнение с присъединяванията.
Съединения и извлечени таблици
Използването на производни таблици в обединяване изглежда така:
FROM table1 a
INNER JOIN (SELECT y.column3 from table2 x
INNER JOIN table3 y on x.column1 = y.column1) b ON a.col1 = b.col2Той се присъединява от резултата от друг оператор SELECT и е напълно валиден.
Ще имате още примери, но нека се заемем с едно последно нещо за SQL JOINS. Това е начинът, по който процесите на Query Optimizer на SQL Server се присъединяват.
Как SQL Server процеси се присъединяват
За да разберете как работи процесът, трябва да знаете за двата типа операции:
- Логически операции съответстват на типовете съединения, използвани в заявка:INNER, OUTER или CROSS. Вие, като разработчик, дефинирате тази част от обработката при формиране на заявката.
- Физически операции – Оптимизаторът на заявки избира най-добрата физическа операция, приложима за вашето присъединяване. Най-доброто означава най-бързото за постигане на резултати. Планът за изпълнение на вашата заявка ще покаже избраните оператори за физическо присъединяване. Тези операции са:
- Присъединяване на вложен цикъл. Тази операция е бърза, ако едната от двете таблици е малка, а втората е голяма и индексирана. Изисква най-малко I/O с най-малко сравнения, но не е добре за големи набори от резултати.
- Сливане на присъединяване. Това е най-бързата операция за големи и сортирани набори от резултати по колони, използвани в обединяването.
- Присъединяване към хеш. Оптимизаторът на заявки го използва, когато наборът от резултати е твърде голям за вложен цикъл и входните данни са несортирани за обединяване на сливане. Хешът е по-ефективен, отколкото първо да го сортирате и да приложите присъединяване за сливане.
- Адаптивно присъединяване. Започвайки със SQL Server 2017, той позволява избора между вложен цикъл или хеш . Методът на присъединяване се отлага, докато не бъде сканиран първият вход. Тази операция динамично превключва към по-добро физическо присъединяване без повторно компилиране.

Защо трябва да се занимаваме с това?
Една дума:производителност.
Едно нещо е да знаете как да формирате заявки с обединения, за да получите правилни резултати. Друго е да го накарате да работи възможно най-бързо. Трябва да сте особено загрижени за това, ако искате добра репутация сред потребителите си.
И така, какво трябва да внимавате в плана за изпълнение за тези логически операции?
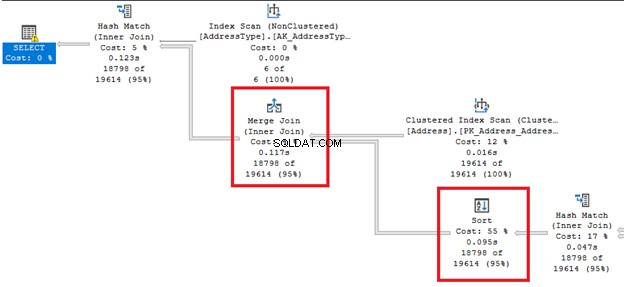
- Да предположим, че оператор за сортиране предхожда обединяването с обединяване . Тази операция за сортиране е скъпа за големи таблици (Фигура 2). Можете да коригирате това, като предварително сортирате входните таблици в обединението.
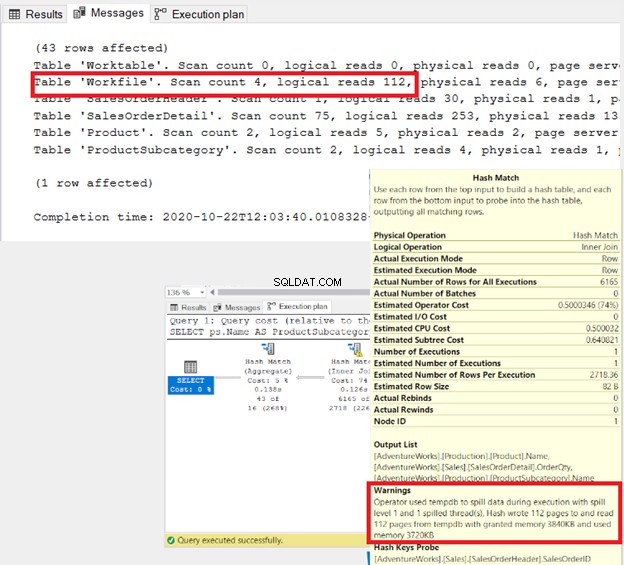
- Да предположим, че има дубликати във входните таблици на присъединяване за сливане . SQL Server ще запише дубликатите на втората таблица в работна таблица в tempdb. След това ще направи сравненията там. IO STATISTICS ще разкрие всички включени работни таблици.
- Когато огромни данни се разлеят към tempdb в Hash jo в, STATISTICS IO ще разкрие голямо логическо четене на работни файлове или работни таблици. Предупреждение ще се появи и в плана за изпълнение (Фигура 3). Можете да приложите две неща:предварително сортиране на входните таблици или намаляване на обединяванията, ако е възможно. В резултат на това оптимизаторът на заявки може да избере друго физическо присъединяване.
Съвети за присъединяване
Подсказките за присъединяване са нови в SQL Server 2019. Когато го използвате във вашите обединения, той казва на оптимизатора на заявки да спре да решава кое е най-доброто за заявката. Вие сте шефът, когато става въпрос за физическото присъединяване, което да използвате.
Сега спри, точно там. Истината е, че оптимизаторът на заявки обикновено избира най-доброто физическо присъединяване за вашата заявка. Ако не знаете какво правите, не използвайте съвети за присъединяване.
Възможните съвети, които можете да посочите, са LOOP, MERGE, HASH или REMOTE.
Не съм използвал съвети за присъединяване, но ето синтаксиса:
<join type> <join hint> JOIN <table source> [<alias>] ON <join condition>Всичко за INNER JOIN
INNER JOIN връща редовете със съвпадащи записи в двете таблици въз основа на условие. Това също е присъединяването по подразбиране, ако не посочите ключовата дума INNER:
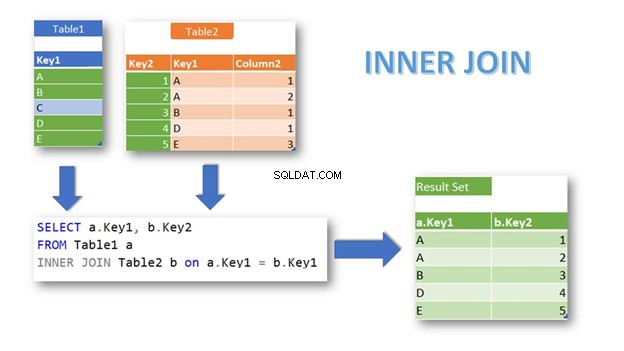
Както виждате, съвпадащи редове от Таблица1 и Таблица2 се връщат с помощта на Ключ1 като условие за присъединяване. Таблица1 запис с Ключ1 =„C“ е изключено, защото няма съвпадащи записи в Таблица2 .
Всеки път, когато образувам заявка, първият ми избор е INNER JOIN. OUTER JOIN идва само когато изискванията го диктуват.
Синтаксис INNER JOIN
Има два синтаксиса INNER JOIN, поддържани в T-SQL:SQL-92 и SQL-89.
SQL-92 INNER JOIN
FROM <table source1> [<alias1>]
INNER JOIN <table source2> [<alias2>] ON <join condition1>
[INNER JOIN <table source3> [<alias3>] ON <join condition2>
INNER JOIN <table sourceN> [<aliasN>] ON <join conditionN>]
[WHERE <condition>]SQL-89 INNER JOIN
FROM <table source1> [alias1], <table source2> [alias2] [, <table source3> [alias3], <table sourceN> [aliasN]]
WHERE (<join condition1>)
[AND (<join condition2>)
AND (<join condition3>)
AND (<join conditionN>)]Кой синтаксис INNER JOIN е по-добър?
Първият синтаксис на присъединяване, който научих, беше SQL-89. Когато SQL-92 най-накрая пристигна, реших, че е твърде дълъг. Мислех също, че тъй като изходът е същият, защо да си правите труда да пишете повече ключови думи? Графичен дизайнер на заявки имаше генерирания код SQL-92 и аз го промених обратно на SQL-89. Но днес предпочитам SQL-92, дори ако трябва да пиша повече. Ето защо:
- Намерението на типа на присъединяване е ясно. Следващият човек или момиче, който ще поддържа кода ми, ще знае какво е предназначено в заявката.
- Забравянето на условието за присъединяване в синтаксис на SQL-92 ще предизвика грешка. Междувременно забравянето на условието за присъединяване в SQL-89 ще се третира като КРЪСТО ПРИСЪЕДИНЕНИЕ. Ако имах предвид INNER или OUTER присъединяване, това би било незабележима логическа грешка, докато потребителите не се оплакват.
- Новите инструменти са по-склонни към SQL-92. Ако някога отново използвам графичен дизайнер на заявки, не е нужно да го променям на SQL-89. Вече не съм упорит, така че сърдечната ми честота се нормализира. Наздраве за мен.
Горните причини са мои. Може да имате своите причини защо предпочитате SQL-92 или защо го мразите. Чудя се какви са тези причини. Уведомете ме в секцията за коментари по-долу.
Но не можем да завършим тази статия без примери и обяснения.
10 примера за INNER JOIN
1. Съединяване на 2 таблици
Ето пример за 2 таблици, обединени заедно с помощта на INNER JOIN в синтаксис на SQL-92.
-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON P.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE P.ProductSubcategoryID IN (25, 31, 33); -- for vest, helmet, and light
-- product subcategoriesВие посочвате само колоните, от които се нуждаете. В горния пример са посочени 4 колони. Знам, че е твърде продължително от SELECT *, но имайте предвид това:това е най-добрата практика.
Обърнете внимание и на използването на псевдоними на таблици. И двата Продукта и Подкатегория на продукта таблиците имат колона с име [Име ]. Ако не посочите псевдонима, ще се задейства грешка.
Междувременно, ето еквивалентния синтаксис на SQL-89:
-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p, Production.ProductSubcategory ps
WHERE P.ProductSubcategoryID = ps.ProductSubcategoryID
AND P.ProductSubcategoryID IN (25, 31, 33);Те са еднакви с изключение на условието за присъединяване, смесено в клаузата WHERE с ключова дума AND. Но под капака наистина ли са еднакви? Нека проверим набора от резултати, STATISTICS IO и плана за изпълнение.
Вижте резултатния набор от 9 записа:
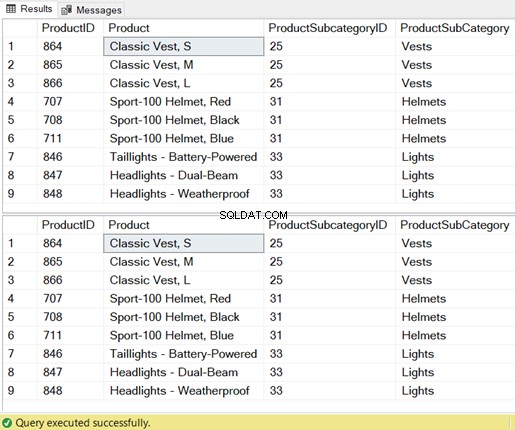
Не са само резултатите, но и ресурсите, изисквани от SQL Server, също са едни и същи.
Вижте логичното четене:
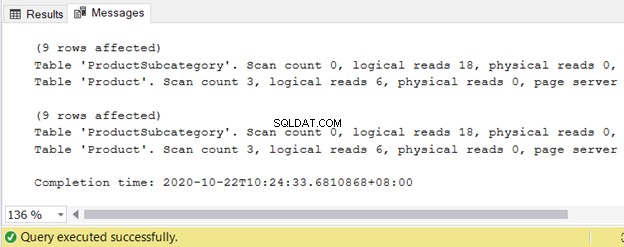
И накрая, планът за изпълнение разкрива един и същ план за заявка и за двете заявки, когато техните QueryPlanHashes са равни. Обърнете внимание и на подчертаните операции в диаграмата:
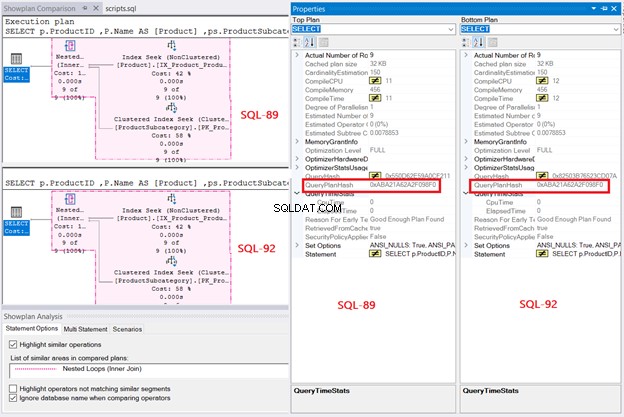
Въз основа на констатациите обработката на заявки в SQL Server е една и съща, независимо дали е SQL-92 или SQL-89. Но както казах, яснотата в SQL-92 е много по-добра за мен.
Фигура 7 също показва свързване на вложен цикъл, използвано в плана. Защо? Резултатът е малък.
2. Съединяване на множество таблици
Вижте заявката по-долу, като използвате 3 свързани таблици.
-- Get the total number of orders per Product Category
USE AdventureWorks
GO
SELECT
ps.Name AS ProductSubcategory
,SUM(sod.OrderQty) AS TotalOrders
FROM Production.Product p
INNER JOIN Sales.SalesOrderDetail sod ON P.ProductID = sod.ProductID
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '1/1/2014' AND '12/31/2014'
AND p.ProductSubcategoryID IN (1,2)
GROUP BY ps.Name
HAVING ps.Name IN ('Mountain Bikes', 'Road Bikes')3. Съставно присъединяване
Можете също да се присъедините към 2 таблици, като използвате 2 ключа, за да ги свържете. Вижте извадката по-долу. Използва 2 условия за присъединяване с оператор И.
SELECT
a.column1
,b.column1
,b.column2
FROM Table1 a
INNER JOIN Table2 b ON a.column1 = b.column1 AND a.column2 = b.column24. ВЪТРЕШНО ПРИСЪЕДИНЕНИЕ Използване на физическо свързване с вложен цикъл
В примера по-долу Продукт таблицата има 9 записа – малък набор. Обединената таблица е SalesOrderDetail – голям комплект. Оптимизаторът на заявки ще използва присъединяване на вложен цикъл, както е показано на фигура 8.
USE AdventureWorks
GO
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);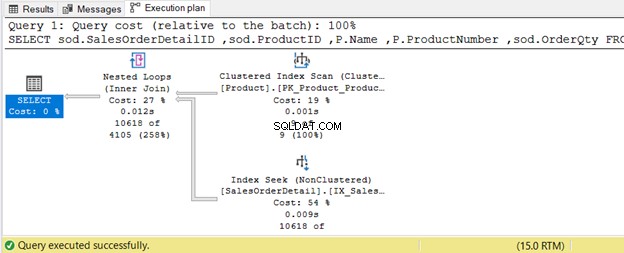
5. ВЪТРЕШНО ПРИСЪЕДИНЕНИЕ Използване на физическо обединяване с обединяване
Примерът по-долу използва Merge Join, тъй като и двете входни таблици са сортирани по SalesOrderID.
SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID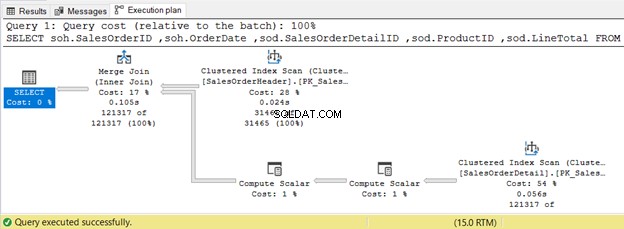
6. ВЪТРЕШНО ПРИСЪЕДИНЕНИЕ Използване на хеш физическо присъединяване
Следният пример ще използва хеш присъединяване:
SELECT
s.Name AS Store
,SUM(soh.TotalDue) AS TotalSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.Store s ON soh.SalesPersonID = s.SalesPersonID
GROUP BY s.Name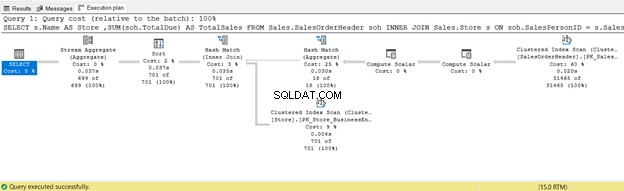
7. INNER JOIN Използване на Adaptive Physical Join
В примера по-долу Продавач таблицата има Non-clustered ColumnStore Index на TerritoryID колона. Оптимизаторът на заявки е избрал свързване на вложен цикъл, както е показано на фигура 11.
SELECT
sp.BusinessEntityID
,sp.SalesQuota
,st.Name AS Territory
FROM Sales.SalesPerson sp
INNER JOIN Sales.SalesTerritory st ON sp.TerritoryID = st.TerritoryID
WHERE sp.TerritoryID BETWEEN 1 AND 5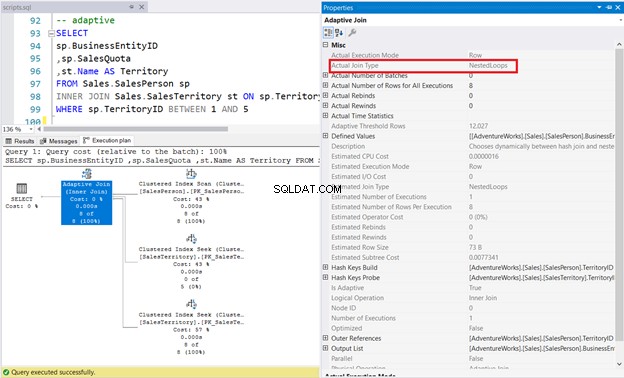
8. Два начина за пренаписване на подзаявка към INNER JOIN
Помислете за това изявление с вложена подзаявка:
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT [CustomerID] FROM Sales.Customer
WHERE PersonID IN (SELECT BusinessEntityID FROM Person.Person
WHERE lastname LIKE N'I%' AND PersonType='SC'))Същите резултати могат да се получат, ако го промените на INNER JOIN, както е по-долу:
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.lastname LIKE N'I%'Друг начин да го пренапишете е като използвате извлечена таблица като източник на таблица за INNER JOIN:
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN (SELECT c.CustomerID, P.PersonType, P.LastName
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = P.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.LastName LIKE N'I%') AS q ON o.CustomerID = q.CustomerIDВсичките 3 заявки извеждат едни и същи 48 записа.
9. Използване на съвети за присъединяване
Следната заявка използва вложен цикъл:
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);Ако искате да го принудите към хеш присъединяване, това се случва:
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER HASH JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);Обърнете внимание обаче, че STATISTICS IO показва, че производителността ще стане лоша, когато я принудите към хеш присъединяване.
Междувременно заявката по-долу използва Merge Join:
SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderIDЕто какво става, когато го принудите към вложен цикъл:
SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER LOOP JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderIDСлед проверка на STATISTICS IO и на двете, принуждаването му към вложен цикъл изисква повече ресурси за обработка на заявката:
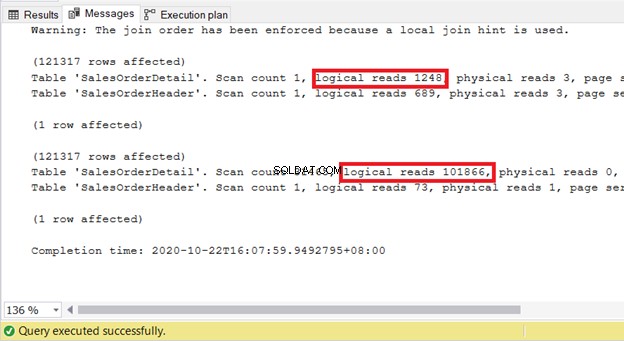
По този начин използването на съвети за присъединяване трябва да бъде последното ви средство, когато настройвате за производителност. Оставете вашия SQL Server да се справи вместо вас.
10. Използване на INNER JOIN в UPDATE
Можете също да използвате INNER JOIN в израз UPDATE. Ето един пример:
UPDATE Sales.SalesOrderHeader
SET ShipDate = getdate()
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Тъй като е възможно да се използва присъединяване в UPDATE, защо не го изпробвате с помощта на DELETE и INSERT?
SQL Join и INNER JOIN Извлечения
И така, какво е голямото в SQL присъединяването?
- SQL JOIN комбинира записи от 2 или повече таблици, за да образува един набор от резултати.
- В SQL има типове обединения:INNER, OUTER и CROSS.
- Като разработчик или администратор вие решавате кои логически операции или типове присъединяване да използвате за вашите изисквания.
- От друга страна, оптимизаторът на заявки решава кои оператори за физическо свързване да се използват най-добре. Може да бъде вложен цикъл, сливане, хеш или адаптивен.
- Можете да използвате подсказки за присъединяване, за да принудите какво физическо присъединяване да използвате, но това трябва да е последното ви средство. В повечето случаи е по-добре да оставите SQL Server да се справи с това.
- Познаването на операторите за физическо свързване също ви помага да настроите производителността на заявката.
- Също така, подзаявките могат да бъдат пренаписани с помощта на присъединяване.
Междувременно тази публикация показа 10 примера за INNER JOIN. Това не са само примерни кодове. Някои от тях включват и проверка на това как кодът работи отвътре навън. Това не е само за да ви помогне да кодирате, но и да ви помогне да имате предвид производителността. В края на деня резултатите трябва не само да са правилни, но и да се доставят бързо.
Все още не сме готови. Следващата статия ще се занимава с OUTER JOINS. Останете на линия.
Вижте също
SQL Joins ви позволява да извличате и комбинирате данни от повече от една таблица. Гледайте този видеоклип, за да научите повече за SQL присъединяванията.



