Когато изпълнява заявка, оптимизаторът на SQL Server се опитва да намери най-добрия план за заявка въз основа на съществуващите индекси и наличните най-нови статистически данни за разумно време, разбира се, ако този план вече не е съхранен в кеша на сървъра. Ако не, заявката се изпълнява според този план и планът се съхранява в кеша на сървъра. Ако планът вече е изграден за тази заявка, заявката се изпълнява според съществуващия план.
Интересуваме се от следния въпрос:
По време на компилиране на план за заявка, при сортиране на възможни индекси, ако сървърът не намери най-добрия индекс, липсващият индекс се маркира в плана на заявката и сървърът поддържа статистика за такива индекси:колко пъти сървърът би използвал този индекс и колко би струвала тази заявка.
В тази статия ще анализираме тези липсващи индекси – как да се справяме с тях.
Нека разгледаме това на конкретен пример. Създайте няколко таблици в нашата база данни на локален и тестов сървър:
[expand title =”Код”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/expand]
Структурата е проста и се състои от две таблици. Първата таблица се нарича поръчки с полета като идентификатор, дата на продажба и продавач. Вторият е детайли за поръчка, където някои стоки са посочени с цена и количество.
Вижте една проста заявка и нейния план:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
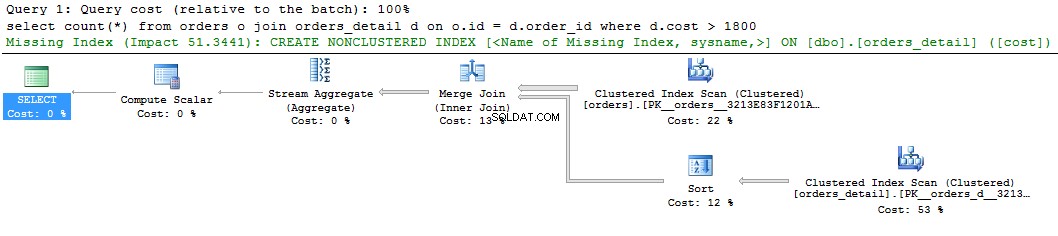
Можем да видим зелен намек за липсващия индекс на графичния дисплей на плана на заявката. Ако щракнете с десния бутон върху него и изберете „Lissing Index Details ..“, ще има текст на предложения индекс. Единственото нещо, което трябва да направите, е да премахнете коментарите в текста и да дадете име на индекса. Скриптът е готов за изпълнение.
Няма да изградим индекса, който получихме от подсказката, предоставена от SSMS. Вместо това ще видим дали този индекс ще бъде препоръчан от динамични изгледи, свързани с липсващи индекси. Изгледите са както следва:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
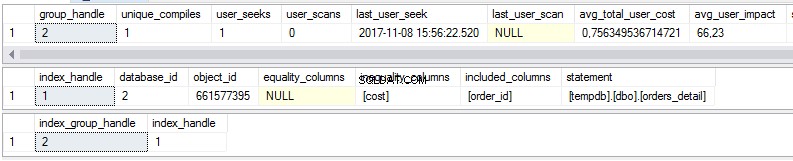
Както виждаме, има някои статистически данни за липсващи индекси в първия изглед:
- Колко пъти би се извършило търсене, ако предложеният индекс съществуваше?
- Колко пъти би се извършило сканиране, ако предложеният индекс съществуваше?
- Последната дата и час, когато използвахме индекса
- Текущата реална цена на плана за заявка без предложения индекс.
Вторият изглед е тялото на индекса:
- База данни
- Обект/таблица
- Сортирани колони
- Добавени са колони за увеличаване на покритието на индекса
Третият изглед е комбинацията от първия и втория изглед.
Съответно не е трудно да се получи скрипт, който да генерира скрипт за създаване на липсващи индекси от тези динамични изгледи. Скриптът е както следва:
[expand title=”Код”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/expand]
За ефективност на индекса се извеждат липсващите индекси. Идеалното решение е, когато този набор от резултати не връща нищо. В нашия пример резултатният набор ще върне поне един индекс:

Когато няма време и не ви се работи с клиентските грешки, аз изпълних заявката, копирах първата колона и я изпълних на сървъра. След това всичко работи добре.
Препоръчвам да третирате информацията за тези индекси съзнателно. Например, ако системата препоръчва следните индекси:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
И тези индекси се използват за търсене, съвсем очевидно е, че е по-логично тези индекси да се заменят с един, който ще покрива и трите предложени:
create index ix_1 on tbl1 (a,b) include (c,d)
По този начин правим преглед на липсващите индекси, преди да ги разположим на производствения сървър. Макар че…. Отново, например, разположих загубените индекси на TFS сървъра, като по този начин увеличих общата производителност. Отне минимално време за извършване на тази оптимизация. Въпреки това, при преминаване от TFS 2015 към TFS 2017, се сблъсках с проблема, че нямаше актуализация поради тези нови индекси. Въпреки това те лесно могат да бъдат намерени от маската
select * from sys.indexes where name like 'ix[_]2017%'
Полезен инструмент:
dbForge Index Manager – удобна добавка за SSMS за анализиране на състоянието на SQL индексите и отстраняване на проблеми с фрагментацията на индекса.