Както може би сте отбелязали от предишния ми блог, последните няколко месеца бяха заети с актуализирането на Postgres-XL с най-новата версия 9.5 на PostgreSQL. След като имахме сравнително стабилна версия на Postgres-XL 9.5, насочихме вниманието си към измерване на производителността на тази чисто нова версия на Postgres-XL. Изборът ни на бенчмарк е до голяма степен повлиян от текущата работа по проекта AXLE, финансиран от Европейския съюз по споразумение за отпускане на безвъзмездни средства 318633. Тъй като използваме TPC BENCHMARK™ H за измерване на ефективността на цялата друга работа, извършена по този проект, решихме да използвайте същия бенчмарк за оценка на Postgres-XL. Също така е подходящ за Postgres-XL, защото TPC-H се опитва да измерва OLAP работните натоварвания, нещо, което Postgres-XL трябва да направи добре.
1. Настройка на клъстер Postgres-XL
След като бенчмаркът беше решен, друго голямо предизвикателство беше да се намерят правилните ресурси за тестване. Нямахме достъп до голям клъстер от физически машини. Така че направихме това, което повечето биха направили. Решихме да използваме Amazon AWS за настройка на клъстера Postgres-XL. AWS предлага широка гама от екземпляри, като всеки тип екземпляр предлага различна изчислителна или IO мощност.
Тази страница в AWS показва различни налични типове екземпляри, налични ресурси и техните цени за различни региони. Трябва да се отбележи, че цените и наличността може да варират в различните региони, така че е важно да проверите всички региони. Тъй като Postgres-XL изисква ниска латентност и висока пропускателна способност между своите компоненти, също така е важно да се инстанцират всички екземпляри в един и същи регион. За нашия 3TB TPC-H решихме да използваме клъстер с 16 данни от i2.xlarge AWS инстанции. Тези екземпляри имат 4 vCPU, 30 GB RAM и 800 GB SSD всеки, достатъчно място за съхранение за съхраняване на всички разпределени таблици, репликирани таблици (които заемат повече място с увеличаване на размера на клъстера), индексите върху тях и все още оставят достатъчно свободно място във временно пространство за таблици за CREATE INDEX и други заявки.
2. Настройка на сравнителен тест
2.1 TPC Benchmark™ H
Бенчмаркът съдържа 22 заявки с цел да се изследват големи обеми данни, да се изпълняват заявки с висока степен на сложност и да се дадат отговори на критични бизнес въпроси. Бихме искали да отбележим, че пълната спецификация TPC Benchmark™ H се занимава с различни тестове като натоварване, мощност и пропускателна способност тестове. За нашето тестване сме изпълнили само отделни заявки, а не пълния тестов пакет. TPC Benchmark™ H се състои от набор от бизнес заявки, предназначени да упражняват функционалностите на системата по начин, представителен за сложни приложения за бизнес анализ. На тези заявки е даден реалистичен контекст, изобразяващ дейността на доставчик на едро, за да помогне на читателя да се свърже интуитивно с компонентите на бенчмарка.
2.2 Обекти, връзки и характеристики на база данни
Компонентите на базата данни TPC-H са дефинирани така, че да се състоят от осем отделни и отделни таблици (базовите таблици). Връзките между колоните на тези таблици са илюстрирани на следващата диаграма. 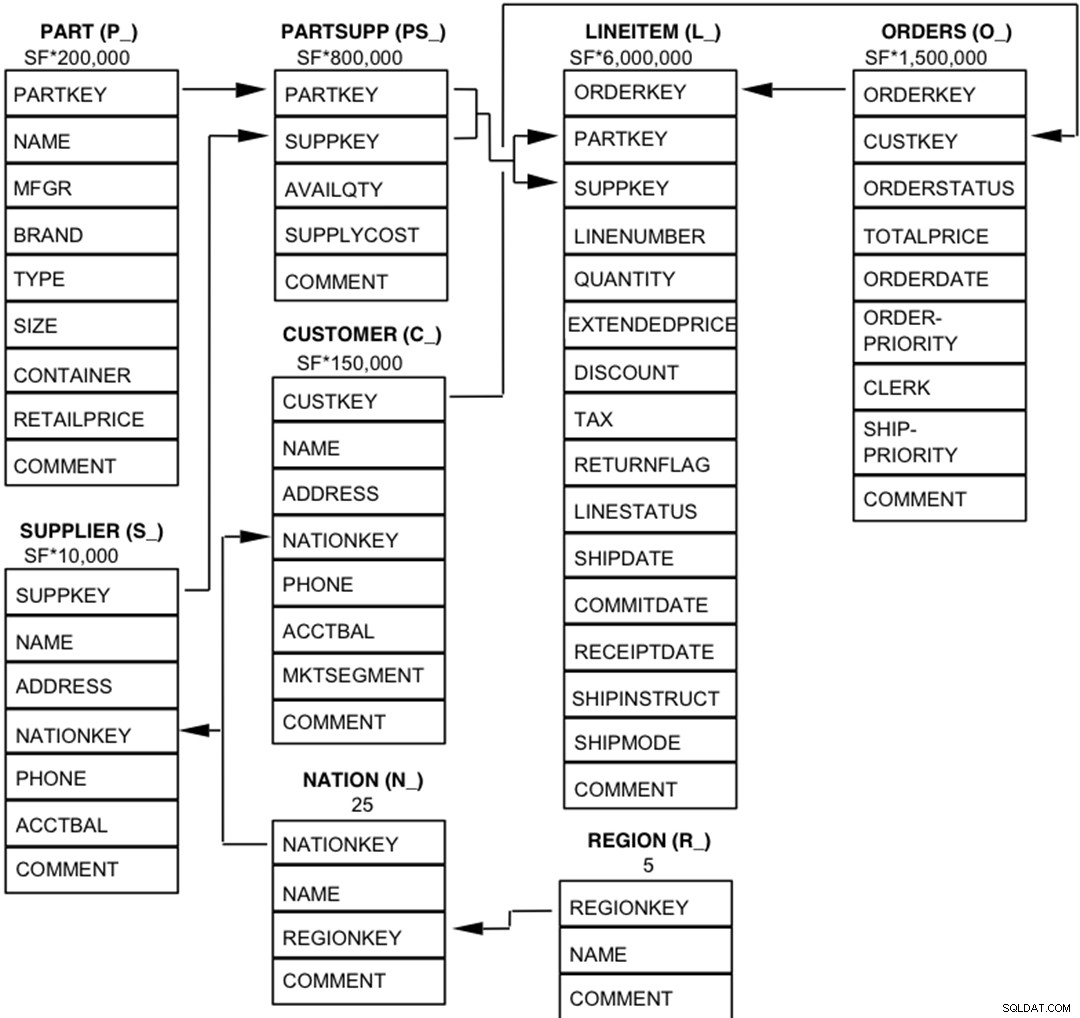 Легенда :
Легенда :
- Скобите след всяко име на таблица съдържат префикса на имената на колоните за тази таблица;
- Стрелките сочат в посоката на връзките едно към много между таблиците
- Числото/формулата под всяко име на таблица представлява кардиналността (броя на редовете) на таблицата. Някои се разлагат на множители от SF, Scale Factor, за да се получи избрания размер на базата данни. Кардиналността за таблицата LINEITEM е приблизителна
2.3 Разпределение на данни за Postgres-XL
Анализирахме всички 22 заявки в бенчмарка и излязохме със следната стратегия за разпространение на данни за различни таблици в бенчмарка.
| Име на таблица | Стратегия за разпространение |
| LINEITEM | HASH (l_orderkey) |
| ПОРЪЧКИ | HASH (o_orderkey) |
| ЧАСТ | HASH (p_partkey) |
| PARTSUPP | ХЕШ (ps_partkey) |
| КЛИЕНТ | РЕПЛИЦИРАНО |
| ДОСТАВЧИК | РЕПЛИЦИРАНО |
| НАЦИЯ | РЕПЛИЦИРАНО |
| РЕГИОН | РЕПЛИЦИРАНО |
Обърнете внимание, че LINEITEM и ORDERS, които са най-големите таблици в еталонния показател, често се обединяват в ORDERKEY. Така че има много смисъл да се разпределят тези таблици в ORDERKEY. По същия начин, PART и PARTSUPP често се свързват в PARTKEY и следователно са разположени в колоната PARTKEY. Останалите таблици се репликират, за да се гарантира, че могат да бъдат свързани локално, когато е необходимо.
3. Резултати от сравнителния анализ
3.1 Тест на натоварване
Сравнихме резултатите, получени чрез провеждане на 3TB TPC-H тест за натоварване на PostgreSQL 9.6 срещу 16-възел Postgres-XL клъстер. Следните диаграми демонстрират характеристиките на ефективността на Postgres-XL.
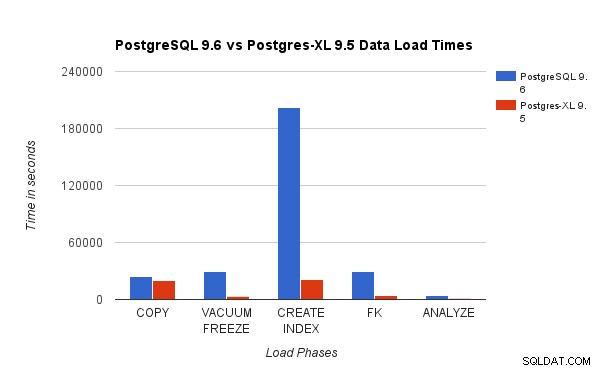 Горната диаграма показва времето, необходимо за завършване на различни фази на тест за натоварване с PostgreSQL и Postgres-XL. Както се вижда, Postgres-XL се представя малко по-добре за COPY и се справя много по-добре за всички останали случаи. Забележка :Забелязахме, че координаторът изисква много изчислителна мощност по време на фазата COPY, особено когато повече от един COPY поток се изпълняват едновременно. За да се справи с това, координаторът беше стартиран на оптимизиран за изчисления AWS екземпляр с 16 vCPU. Като алтернатива бихме могли също да стартираме множество координатори и да разпределим изчислителния товар между тях.
Горната диаграма показва времето, необходимо за завършване на различни фази на тест за натоварване с PostgreSQL и Postgres-XL. Както се вижда, Postgres-XL се представя малко по-добре за COPY и се справя много по-добре за всички останали случаи. Забележка :Забелязахме, че координаторът изисква много изчислителна мощност по време на фазата COPY, особено когато повече от един COPY поток се изпълняват едновременно. За да се справи с това, координаторът беше стартиран на оптимизиран за изчисления AWS екземпляр с 16 vCPU. Като алтернатива бихме могли също да стартираме множество координатори и да разпределим изчислителния товар между тях.
3.2 Тест на захранването
Също така сравнихме времето за изпълнение на заявката за бенчмарк от 3TB на PostgreSQL 9.6 и Postgres-XL 9.5. Следващата диаграма показва характеристиките на ефективността на изпълнението на заявката в двете настройки.
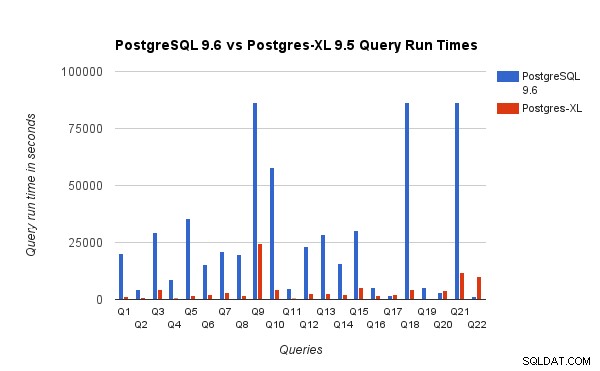 Наблюдавахме, че средно заявките се изпълняват около 6,4 пъти по-бързо в Postgres-XL и поне 25% от заявките показа почти линейно подобрение в производителността, с други думи, те се представиха почти 16 пъти по-бързо в този 16-възел Postgres-XL клъстер. Освен това поне 50% от заявките показаха 10 пъти подобрение в производителността. Освен това анализирахме производителността на заявките и стигнахме до заключението, че заявките, които са добре разделени във всички налични възли с данни, така че да има минимален обмен на данни между възли и без многократни извиквания за отдалечено изпълнение, се мащабират много добре в Postgres-XL. Такива заявки обикновено имат възел за отдалечено сканиране на подзаявки в горната част и поддървото под възела се изпълнява на един или повече възли паралелно. Също така е обичайно да има някои други възли, като възел Limit или Aggregate възел върху възела за отдалечено сканиране на подзаявка. Дори такива заявки се представят много добре на Postgres-XL. Заявка Q1 е пример за заявка, която трябва да се мащабира много добре с Postgres-XL. От друга страна, заявките, които изискват много обмен на кортежи между datanode-datanode и/или координатор-datanode, може да не се справят добре в Postgres-XL. По същия начин заявките, които изискват много връзки между възли, също могат да покажат лоша производителност. Например, ще забележите, че производителността на Q22 е лоша в сравнение с PostgreSQL сървър с един възел. Когато анализирахме плана на заявката за Q22, забелязахме, че има три нива на вложени възли за отдалечено сканиране на подзаявки в плана на заявката, където всеки възел отваря равен брой връзки към възлите с данни. Освен това Nest Loop Anti Join има вътрешна връзка с възел за сканиране на отдалечено подзаявка от най-високо ниво и следователно за всеки кортеж от външната връзка трябва да изпълни отдалечена подзаявка. Това води до лошо изпълнение на заявката.
Наблюдавахме, че средно заявките се изпълняват около 6,4 пъти по-бързо в Postgres-XL и поне 25% от заявките показа почти линейно подобрение в производителността, с други думи, те се представиха почти 16 пъти по-бързо в този 16-възел Postgres-XL клъстер. Освен това поне 50% от заявките показаха 10 пъти подобрение в производителността. Освен това анализирахме производителността на заявките и стигнахме до заключението, че заявките, които са добре разделени във всички налични възли с данни, така че да има минимален обмен на данни между възли и без многократни извиквания за отдалечено изпълнение, се мащабират много добре в Postgres-XL. Такива заявки обикновено имат възел за отдалечено сканиране на подзаявки в горната част и поддървото под възела се изпълнява на един или повече възли паралелно. Също така е обичайно да има някои други възли, като възел Limit или Aggregate възел върху възела за отдалечено сканиране на подзаявка. Дори такива заявки се представят много добре на Postgres-XL. Заявка Q1 е пример за заявка, която трябва да се мащабира много добре с Postgres-XL. От друга страна, заявките, които изискват много обмен на кортежи между datanode-datanode и/или координатор-datanode, може да не се справят добре в Postgres-XL. По същия начин заявките, които изискват много връзки между възли, също могат да покажат лоша производителност. Например, ще забележите, че производителността на Q22 е лоша в сравнение с PostgreSQL сървър с един възел. Когато анализирахме плана на заявката за Q22, забелязахме, че има три нива на вложени възли за отдалечено сканиране на подзаявки в плана на заявката, където всеки възел отваря равен брой връзки към възлите с данни. Освен това Nest Loop Anti Join има вътрешна връзка с възел за сканиране на отдалечено подзаявка от най-високо ниво и следователно за всеки кортеж от външната връзка трябва да изпълни отдалечена подзаявка. Това води до лошо изпълнение на заявката.
4. Няколко урока за AWS
Докато сравнихме Postgres-XL, научихме няколко урока за използването на AWS. Мислехме, че ще бъдат полезни за всеки, който иска да използва/тества Postgres-XL на AWS.
- AWS предлага няколко различни типа екземпляри. Трябва внимателно да оцените работното си натоварване и необходимото количество хранилище, преди да изберете конкретен тип екземпляр.
- Повечето от оптимизираните за съхранение екземпляри имат прикачени към тях ефимерни дискове. Не е нужно да плащате нищо допълнително за тези дискове, те са свързани към инстанцията и често работят по-добре от EBS. Но трябва да ги монтирате изрично, за да можете да ги използвате. Имайте предвид обаче, че данните, съхранявани на тези дискове, не са постоянни и ще бъдат изтрити, ако екземплярът бъде спрян. Затова се уверете, че сте готови да се справите с тази ситуация. Тъй като използвахме AWS предимно за сравнителен анализ, решихме да използваме тези ефимерни дискове.
- Ако използвате EBS, уверете се, че сте избрали подходящи осигурени IOPS. Твърде ниската стойност ще доведе до много бавен IO, но много висока стойност може да увеличи значително сметката ви за AWS, особено когато работите с голям брой възли.
- Уверете се, че стартирате екземплярите в една и съща зона, за да намалите латентността и да подобрите пропускателната способност за връзките между тях.
- Уверете се, че сте конфигурирали екземпляри, така че да използват частна мрежа, за да разговарят помежду си.
- Разгледайте екземпляри на място. Те са относително по-евтини. Тъй като AWS може да прекрати спот екземпляри по свое желание, например, ако спот цената стане по-висока от максималната ви оферта, бъдете готови за това. Postgres-XL може да стане частично или напълно неизползваем в зависимост от това кои възли са прекратени. AWS поддържа концепция за launch_group. Ако няколко екземпляра са групирани в една и съща launch_group, ако AWS реши да прекрати един екземпляр, всички екземпляри ще бъдат прекратени.
5. Заключение
Ние сме в състояние да покажем чрез различни бенчмаркове, че Postgres-XL може да се мащабира наистина добре за голям набор от сложни заявки в реалния свят. Тези показатели ни помагат да демонстрираме способността на Postgres-XL като ефективно решение за OLAP работни натоварвания. Нашите експерименти също показват, че има някои проблеми с производителността с Postgres-XL, особено за много големи клъстери и когато плановникът направи лош избор на план. Ние също така забелязахме, че когато има много голям брой едновременни връзки към възел на данни, производителността се влошава. Ще продължим да работим по тези проблеми с производителността. Бихме искали също да тестваме възможностите на Postgres-XL като OLTP решение, като използваме подходящи работни натоварвания.