Преди няколко седмици написах колко изненадан бях от представянето на нова естествена функция в SQL Server 2016, STRING_SPLIT() :
- Изненади и предположения в производителността:STRING_SPLIT()
След публикуването на публикацията получих няколко коментара (публично и частно) с тези предложения (или въпроси, които превърнах в предложения):
- Указване на изричен тип изходни данни за подхода JSON, така че този метод да не страда от потенциални излишни разходи за производителност поради отмяната на
nvarchar(max). - Тестване на малко по-различен подход, при който нещо всъщност се прави с данните – а именно
SELECT INTO #temp. - Показване на сравнение на прогнозния брой редове със съществуващите методи, особено при вложени операции за разделяне.
Отговорих на някои хора офлайн, но реших, че си струва да публикувам последващи действия тук.
Да бъдем по-справедливи спрямо JSON
Оригиналната функция JSON изглеждаше така, без спецификация за тип изходни данни:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Преименувах го и създадох още две със следните дефиниции:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Мислех, че това драстично ще подобри производителността, но уви, това не беше така. Проведох тестовете отново и резултатите бяха както следва:
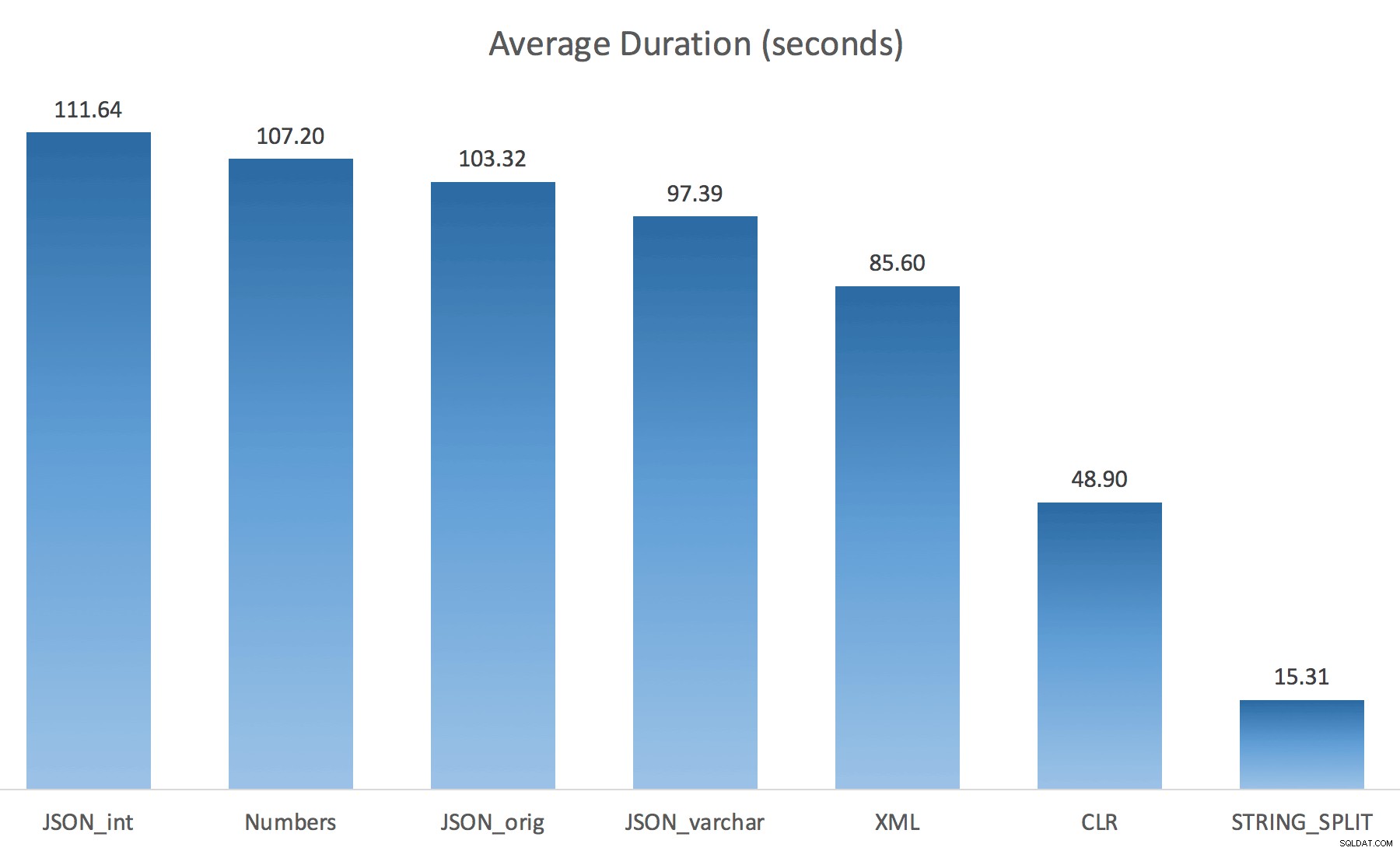
Чаканията, наблюдавани по време на произволен екземпляр на теста (филтриран до тези> 25):
| CLR | IO_COMPLETION | 1595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6 294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Числа | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1917 |
| IO_COMPLETION | 1616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Наблюдава се изчакване> 25 (обърнете внимание, че няма запис за STRING_SPLIT )
Докато се променя от по подразбиране на varchar(100) подобри малко производителността, печалбата беше незначителна и се промени на int всъщност го направи по-лошо. Добавете към това, че вероятно трябва да добавите STRING_ESCAPE() към входящия низ в някои сценарии, само в случай, че имат знаци, които ще объркат анализа на JSON. Моето заключение все пак е, че това е чист начин за използване на новата JSON функционалност, но най-вече новост, неподходяща за разумен мащаб.
Материализиране на изхода
Джонатан Маган направи това проницателно наблюдение в предишната ми публикация:
STRING_SPLIT наистина е много бърз, но също така адски бавен при работа с временна таблица (освен ако не бъде коригирана в бъдеща сборка).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Ще бъде МНОГО по-бавно от SQL CLR решението (15x и повече!).
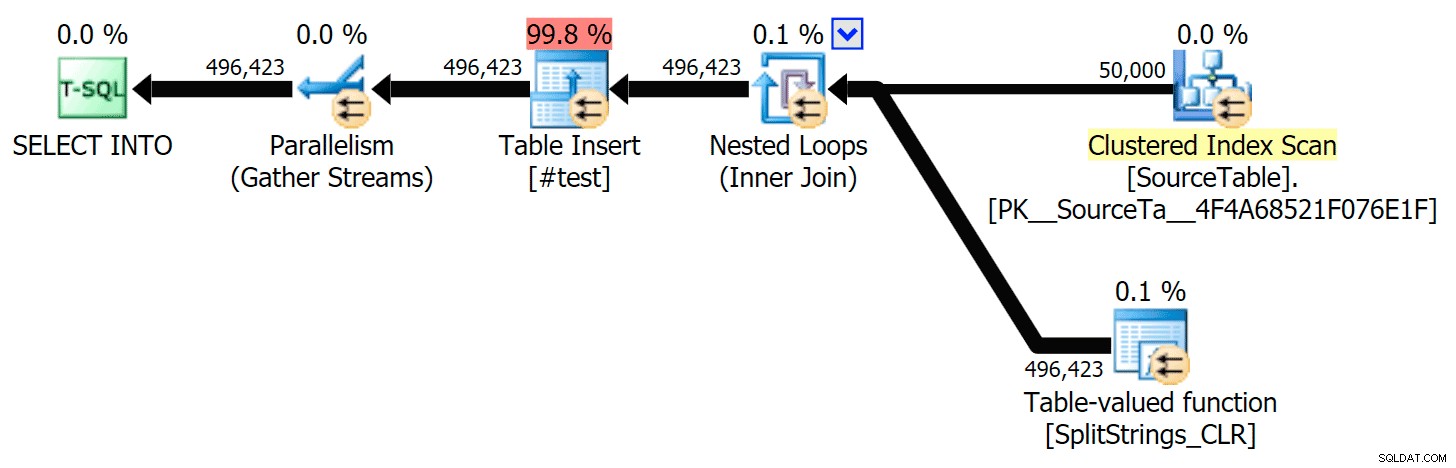
И така, разрових се. Създадох код, който ще извика всяка от моите функции и ще изхвърли резултатите в таблица #temp и ще ги определи времето:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
Просто пуснах всеки тест веднъж (вместо да завъртя 100 пъти), защото не исках напълно да разбия I/O на моята система. И все пак, след усредняване на три теста, Джонатан беше абсолютно, 100% прав. Ето продължителността на попълването на таблица #temp с ~500 000 реда, използвайки всеки метод:
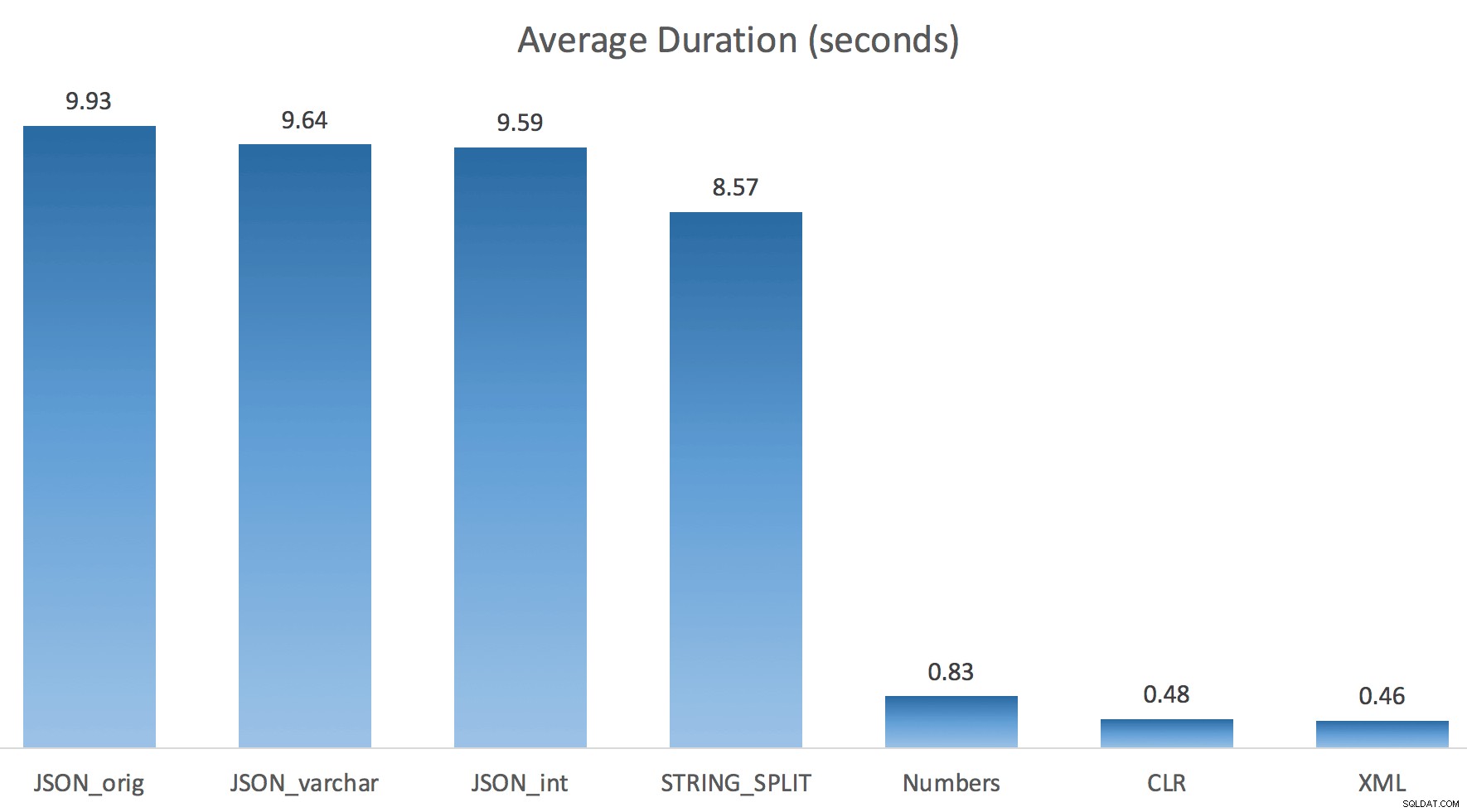
И така, тук, JSON и STRING_SPLIT методите отнемаха около 10 секунди всеки, докато подходите на таблицата Numbers, CLR и XML отнеха по-малко от секунда. Объркан, изследвах чаканията и със сигурност четирите метода вляво предизвикаха значителен LATCH_EX изчаквания (около 25 секунди), които не се виждат в другите три, и нямаше други значими изчаквания, за които да говорим.
И тъй като изчакванията на ключалката бяха по-големи от общата продължителност, това ми даде представа, че това е свързано с паралелизъм (тази конкретна машина има 4 ядра). Затова генерирах тестов код отново, променяйки само един ред, за да видя какво ще се случи без паралелизъм:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Сега STRING_SPLIT се справи много по-добре (както и методите JSON), но все пак поне удвоява времето, необходимо на CLR:
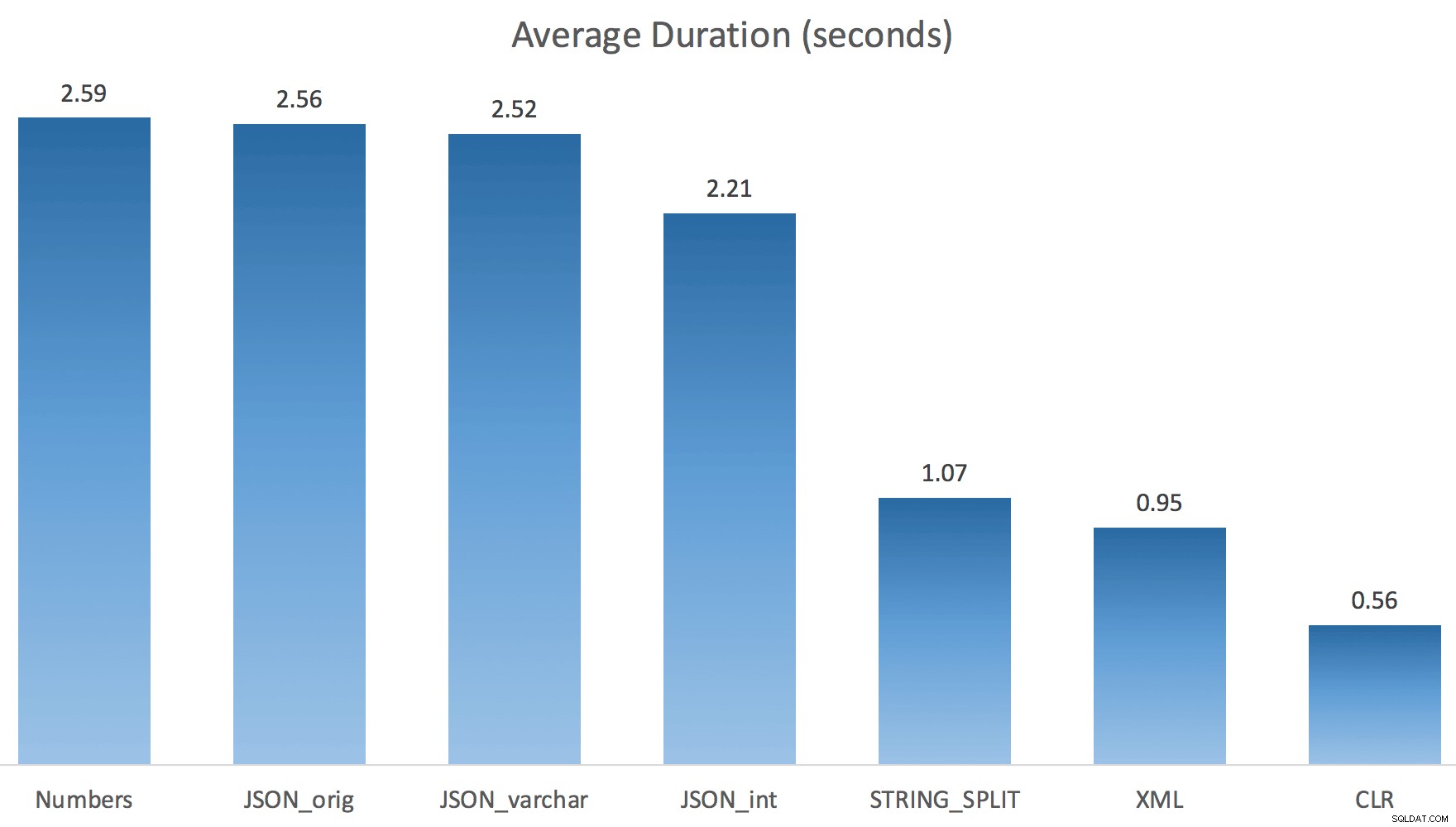
Така че може да има оставащ проблем в тези нови методи, когато е включен паралелизъм. Това не беше проблем с разпространението на нишки (проверих това) и CLR всъщност имаше по-лоши оценки (100x действителни срещу само 5x за STRING_SPLIT ); просто някакъв основен проблем с координирането на ключалки между нишките, предполагам. Засега може да си струва да използвате MAXDOP 1 ако знаете, че пишете изхода на нови страници.
Включих графичните планове, сравняващи CLR подхода с естествения, както за паралелно, така и за серийно изпълнение (също качих файл за анализ на заявки, който можете да отворите в SQL Sentry Plan Explorer, за да шурнете сами):
STRING_SPLIT
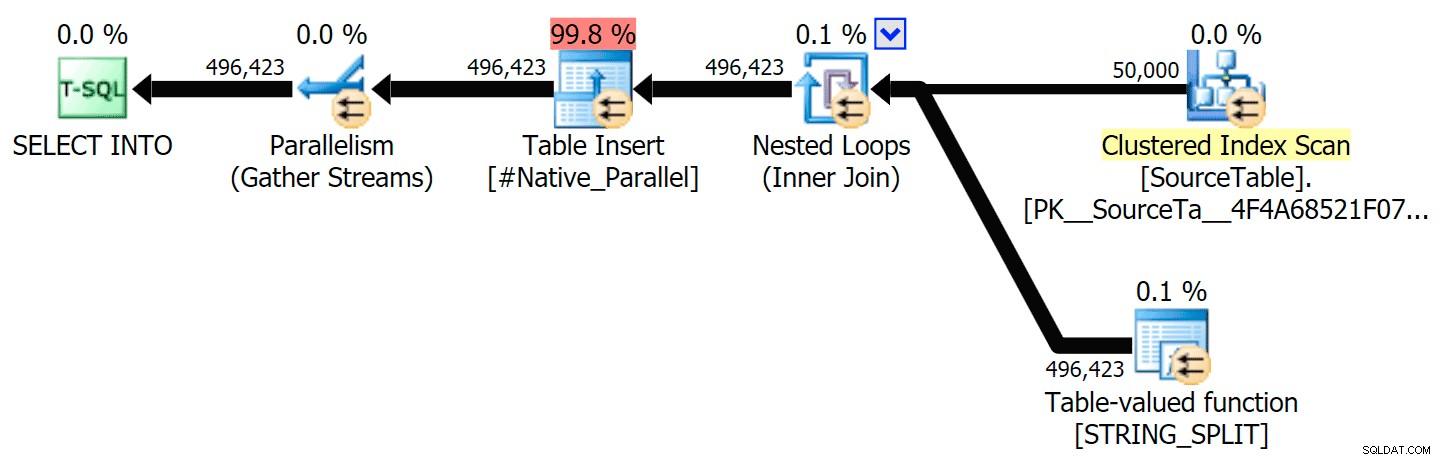
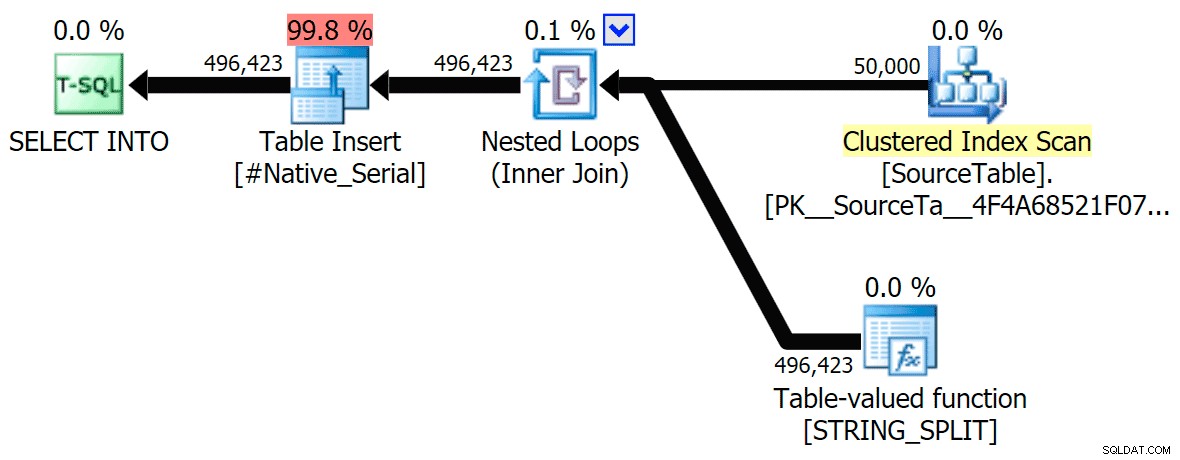
CLR
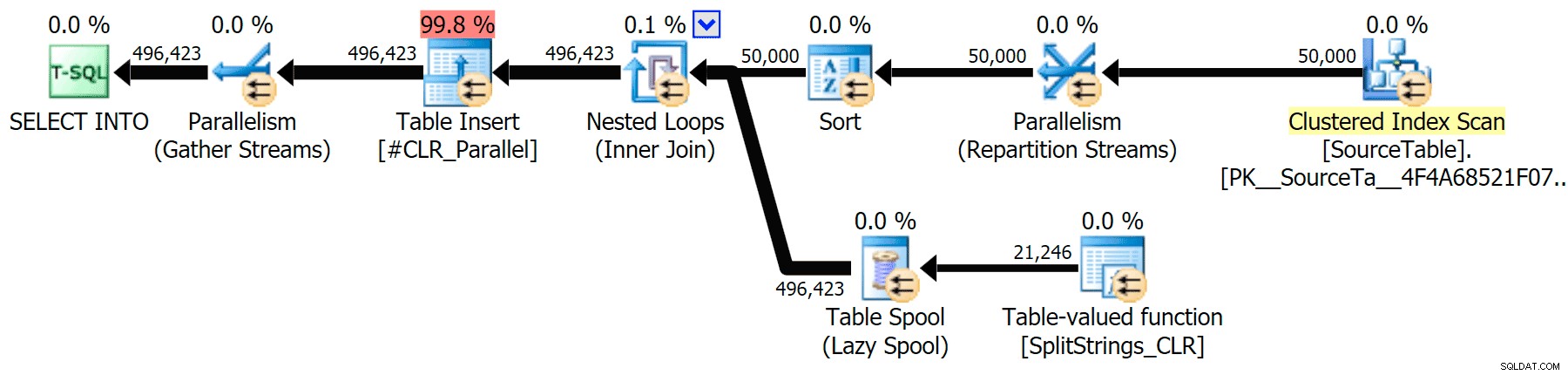
Предупреждението за сортиране, FYI, не беше нищо твърде шокиращо и очевидно нямаше много осезаем ефект върху продължителността на заявката:

- StringSplit.queryanalysis.zip (25kb)
Маки за лятото
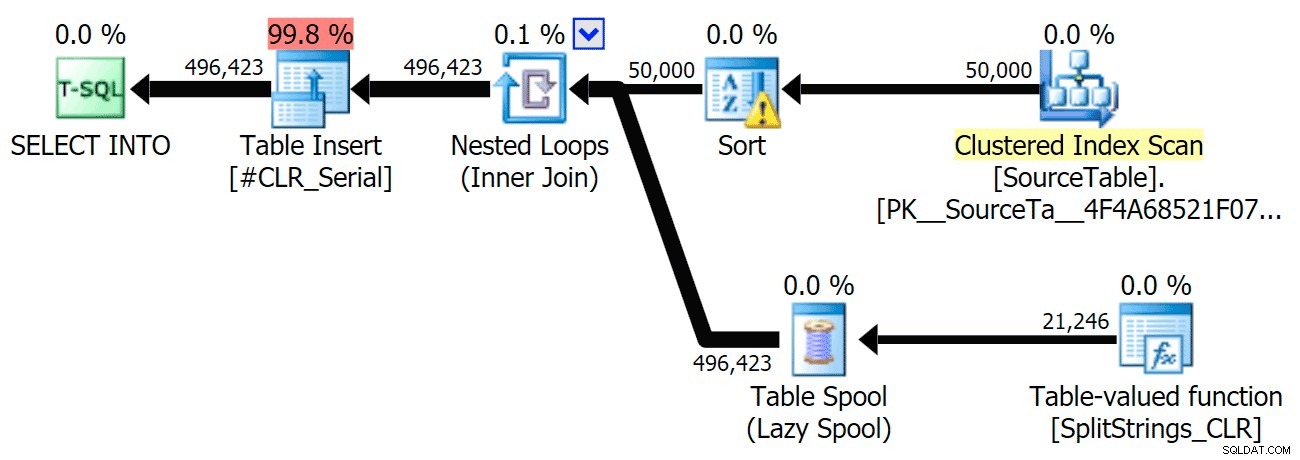
Когато погледнах малко по-отблизо тези планове, забелязах, че в плана CLR има мързелива макара. Това се въвежда, за да се гарантира, че дубликатите се обработват заедно (за да се спести работа, като се прави по-малко действително разделяне), но тази макара не винаги е възможна във всички форми на плана и може да даде малко предимство на тези, които могат да я използват ( например план CLR), в зависимост от оценките. За да сравнявам без шпули, активирах флага за проследяване 8690 и стартирах тестовете отново. Първо, ето паралелния CLR план без макарата:
И ето новите продължителности за всички заявки, които вървят паралелно с активиран TF 8690:
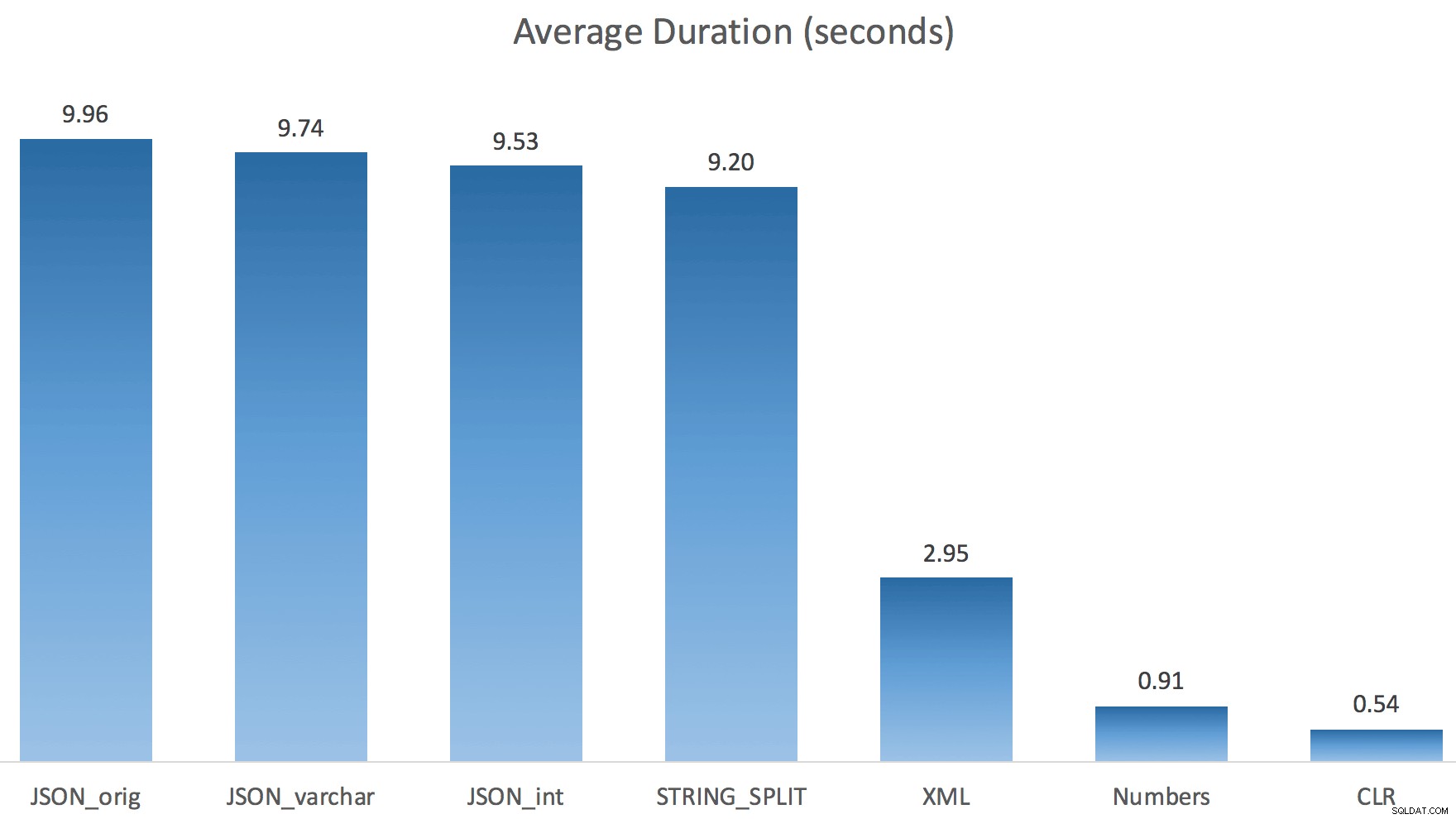
Сега, ето серийния CLR план без макарата:
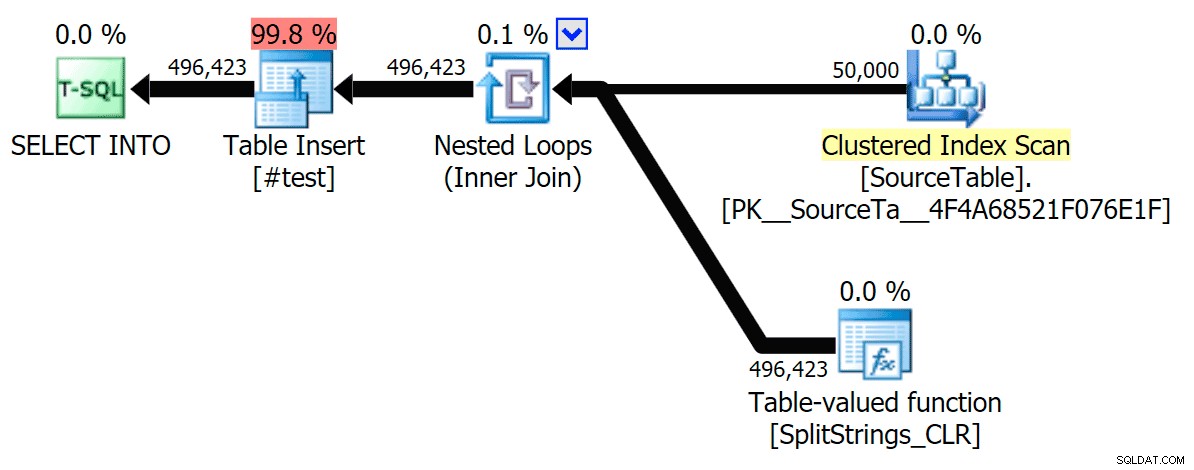
И ето резултатите от времето за заявки, използващи както TF 8690, така и MAXDOP 1 :
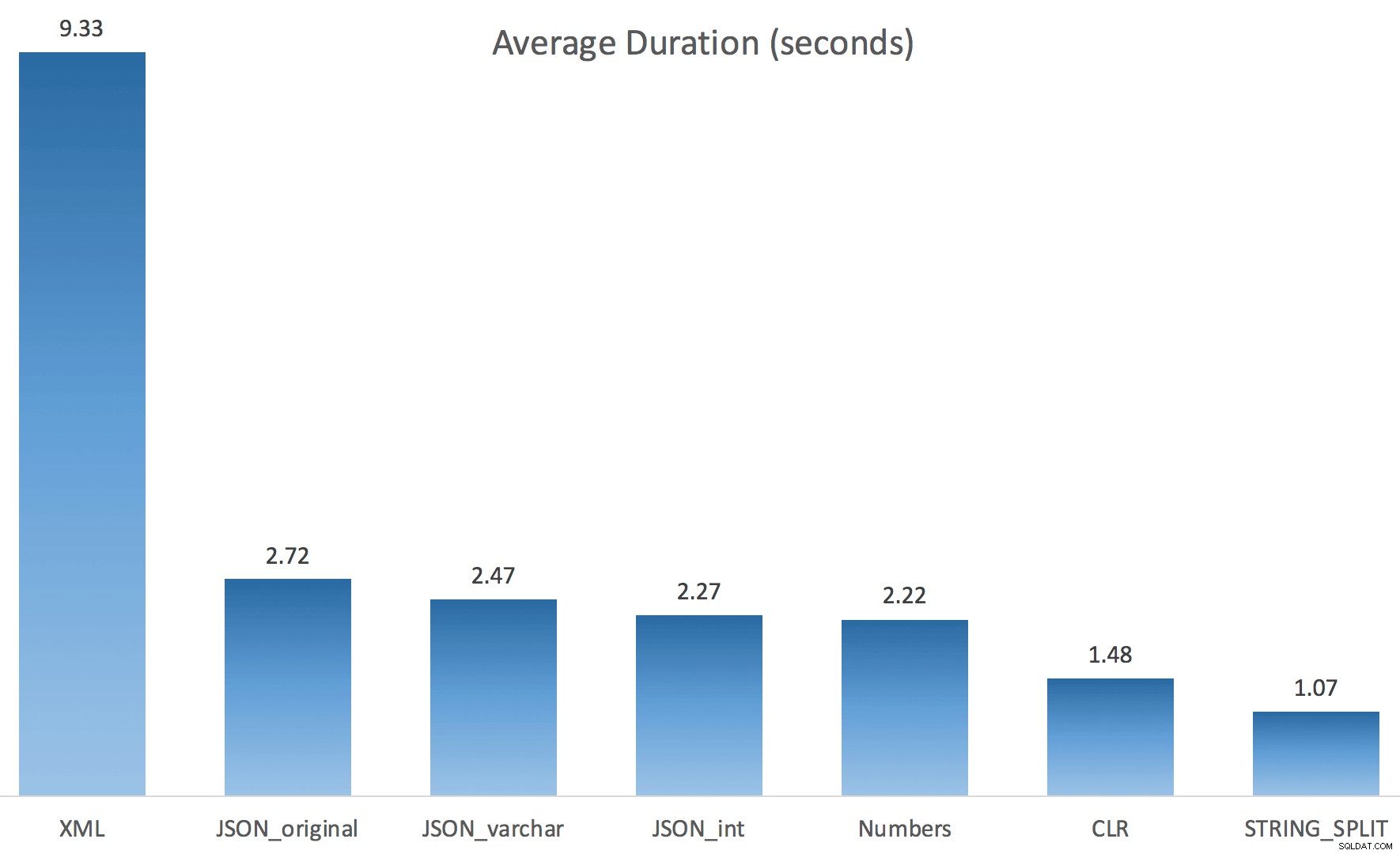
(Обърнете внимание, че освен XML плана, повечето от останалите изобщо не са се променили, със или без флага за проследяване.)
Сравняване на прогнозния брой редове
Дан Холмс зададе следния въпрос:
Как оценява размера на данните, когато се присъедини към друга (или множество) функция за разделяне? Връзката по-долу е описание на CLR базирана разделна реализация. Дали 2016 г. върши „по-добра“ работа с оценките на данните? (за съжаление все още нямам възможност да инсталирам RC).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
И така, извадих кода от публикацията на Дан, промених го, за да използвам моите функции, и го пуснах през Plan Explorer:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
SPLIT_STRING подходът със сигурност дава *по-добри* оценки от CLR, но все пак много надхвърля (в този случай, когато низът е празен; това може да не винаги е така). Функцията има вградена по подразбиране, която изчислява, че входящият низ ще има 50 елемента, така че когато ги вложите, получавате 50 x 50 (2500); ако ги гнездите отново, 50 x 2 500 (125 000); и накрая, 50 x 125 000 (6 250 000):
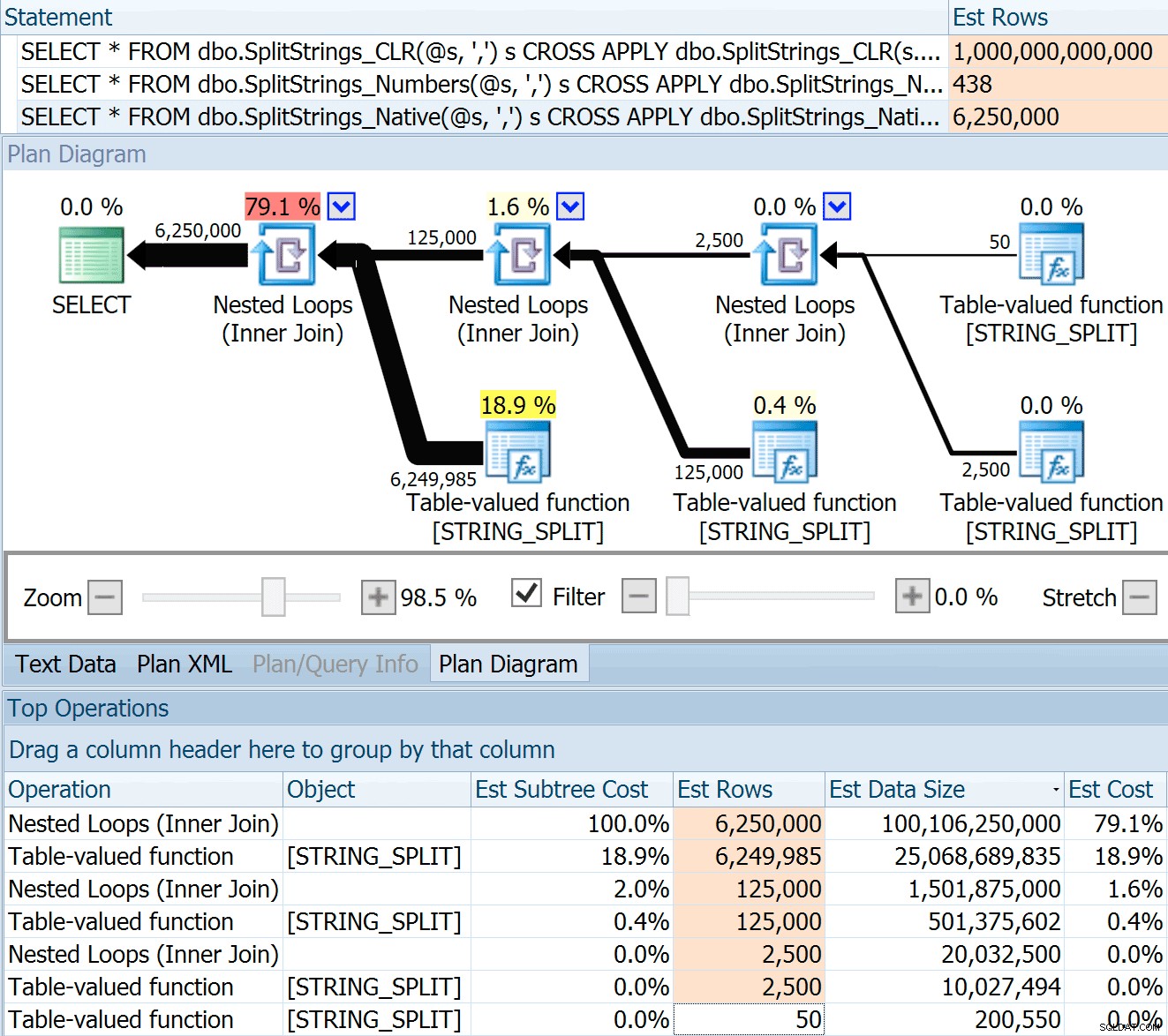
Забележка:OPENJSON() се държи по същия начин като STRING_SPLIT – той също предполага, че 50 реда ще излязат от всяка дадена операция на разделяне. Мисля, че може да е полезно да има начин да се намекне за кардиналност за функции като тази, в допълнение към флагове за проследяване като 4137 (преди 2014), 9471 и 9472 (2014+) и разбира се 9481...
Тази оценка за 6,25 милиона реда не е страхотна, но е много по-добра от CLR подхода, за който говори Дан, който изчислява ТРилион РЕДА , и загубих броя на запетаите, за да определя размера на данните – 16 петабайта? ексабайта?
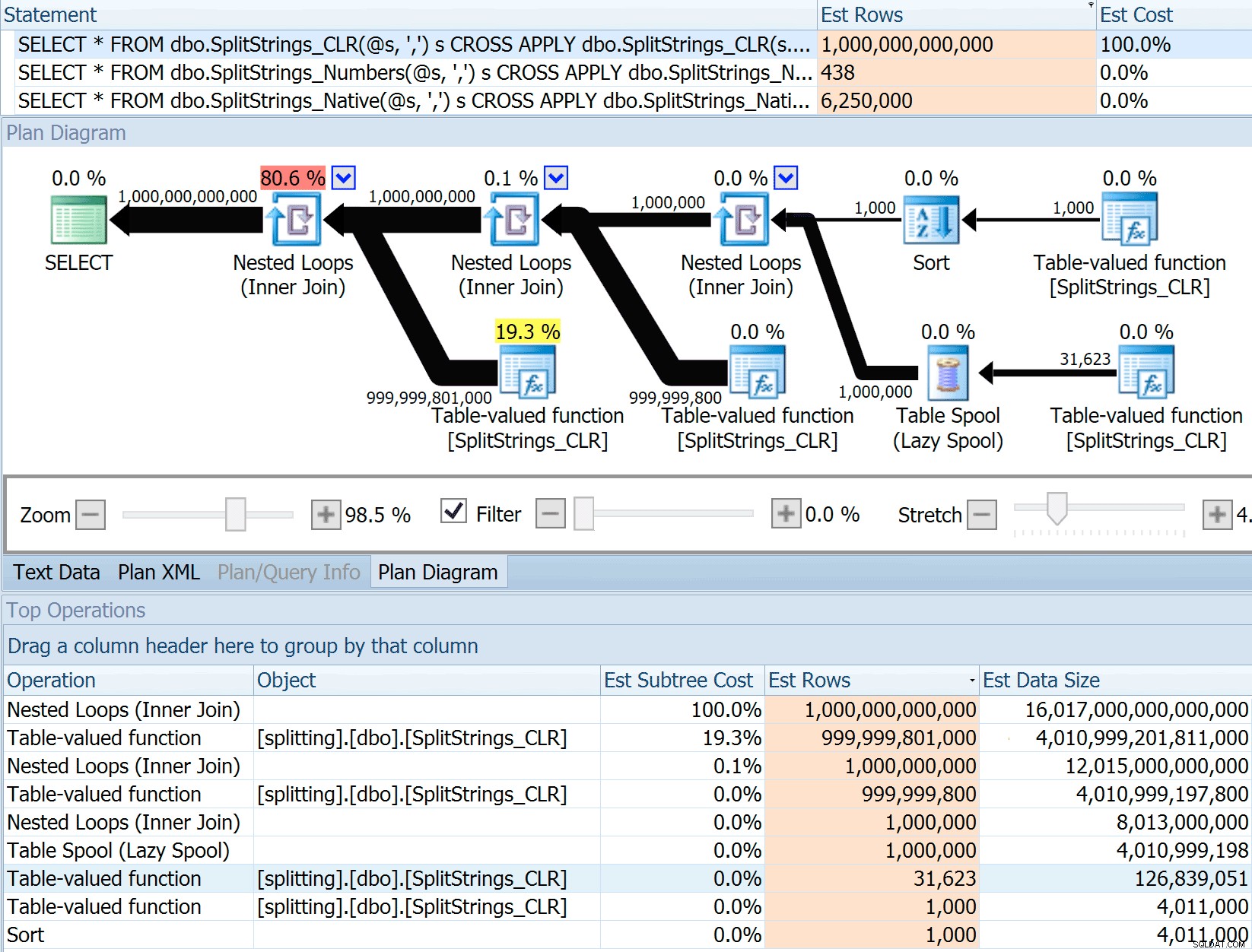
Някои от другите подходи очевидно са по-добри по отношение на оценките. Таблицата с числа например изчисли много по-разумни 438 реда (в SQL Server 2016 RC2). Откъде идва това число? Е, има 8000 реда в таблицата и ако си спомняте, функцията има предикат за равенство и неравенство:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter И така, SQL Server умножава броя на редовете в таблицата с 10% (като предположение) за филтъра за равенство, след което корен квадратен от 30% (отново предположение) за филтъра за неравенство. Квадратният корен се дължи на експоненциално отстъпване, което Пол Уайт обяснява тук. Това ни дава:
8000 * 0,1 * SQRT(0,3) =438,178Вариантът на XML се оценява на малко над милиард реда (поради една таблица за пулове, за които се оценява, че ще бъдат изпълнени 5,8 милиона пъти), но планът й беше твърде сложен, за да се опита да илюстрира тук. Във всеки случай, не забравяйте, че оценките очевидно не разказват цялата история – само защото заявката има по-точни оценки, не означава, че ще работи по-добре.
Имаше няколко други начина, по които можех да настроя малко оценките:а именно, форсиране на стария модел за оценка на мощността (който засегна както вариациите на таблицата XML и Numbers) и използване на TFs 9471 и 9472 (които засегнаха само вариацията на таблицата Numbers, т.к. и двамата контролират мощността около множество предикати). Ето начините, по които мога да променя прогнозите само малко (или МНОГО). , в случай на връщане към стария модел CE):

Старият модел на CE намали оценките на XML с порядък, но за таблицата с числата напълно я взриви. Флаговете на предиката промениха оценките за таблицата Numbers, но тези промени са много по-малко интересни.
Нито един от тези флагове за проследяване не оказва влияние върху оценките за CLR, JSON или STRING_SPLIT вариации.
Заключение
И така, какво научих тук? Всъщност цял куп:
- Паралелизмът може да помогне в някои случаи, но когато не помогне, наистина не помага. Методите JSON бяха ~5 пъти по-бързи без паралелизъм и
STRING_SPLITбеше почти 10 пъти по-бързо. - Шпулата всъщност помогна на подхода CLR да се представи по-добре в този случай, но TF 8690 може да е полезен за експериментиране в други случаи, когато виждате макари и се опитвате да подобрите производителността. Сигурен съм, че има ситуации, при които премахването на макарата ще бъде по-добре като цяло.
- Елиминирането на макарата наистина навреди на XML подхода (но само драстично, когато беше принуден да бъде еднонишков).
- Много странни неща могат да се случат с оценки в зависимост от подхода, заедно с обичайните флагове за статистика, разпространение и проследяване. Е, предполагам, че вече знаех това, но определено има няколко добри, осезаеми примера тук.
Благодаря на хората, които зададоха въпроси или ме подтикнаха да включа повече информация. И както може би се досещате от заглавието, обръщам се към още един въпрос във второ продължение, този за TVP:
- STRING_SPLIT() в SQL Server 2016 :Продължение №2



