По-рано тази седмица публикувах продължение на скорошната си публикация относно STRING_SPLIT() в SQL Server 2016, адресиране на няколко коментара, оставени в публикацията и/или изпратени директно до мен:
STRING_SPLIT()в SQL Server 2016 :Продължение №1
След като тази публикация беше предимно написана, имаше един късен въпрос от Дъг Елнър:
Как се сравняват тези функции с параметрите с таблица?
Сега тестването на TVP вече беше в списъка ми с бъдещи проекти, след скорошен обмен в Twitter с @Nick_Craver в Stack Overflow. Той каза, че са развълнувани, че STRING_SPLIT() се представиха добре, тъй като не бяха доволни от представянето на изпращане на ~7000 стойности чрез параметър с таблица.
Моите тестове
За тези тестове използвах SQL Server 2016 RC3 (13.0.1400.361) на 8-ядрен Windows 10 VM, с PCIe съхранение и 32 GB RAM.
Създадох проста таблица, която имитира това, което правят (избирайки около 10 000 стойности от таблица с публикации от 3+ милиона реда), но за моите тестове тя има много по-малко колони и по-малко индекси:
CREATE TABLE dbo.Posts_Regular( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() НАД (ПОРЪЧКА ПО s1.[object_id]) ОТ sys.all_objects КАТО s1 КРЪСТО ПРИСЪЕДИНЕТЕ sys.all_objects AS s2;
Също така създадох версия в паметта, защото ми беше любопитно дали някой подход ще работи по различен начин там:
СЪЗДАДЕТЕ ТАБЛИЦА dbo.Posts_InMemory( PostID int ПЪРВИЧЕН КЛЮЧ НЕКЛУСТРИРАН ХЕШ С (BUCKET_COUNT =4000000), HitCount int NOT NULL DEFAULT 0) С (MEMORY_OPTIMIZED =ON);
Сега исках да създам приложение на C#, което да предава 10 000 уникални стойности, или като разделен със запетая низ (изграден с помощта на StringBuilder) или като TVP (предаден от DataTable). Въпросът би бил да се извлече или актуализира селекция от редове въз основа на съвпадение, или на елемент, произведен чрез разделяне на списъка, или на изрична стойност в TVP. Така кодът беше написан, за да добави всяка 300-та стойност към низа или DataTable (кодът на C# е в приложение по-долу). Взех функциите, които създадох в оригиналната публикация, промених ги, за да обработват varchar(max) и след това добави две функции, които приемат TVP – едната от тях е оптимизирана за памет. Ето типовете таблици (функциите са в приложението по-долу):
СЪЗДАВАЙТЕ ТИП dbo.PostIDs_Regular КАТО ТАБЛИЦА(PostID int PRIMARY KEY);GO CREATE TYPE dbo.PostIDs_InMemory КАТО ТАБЛИЦА( PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT =10MEZ) /предварително>Също така трябваше да направя таблицата Numbers по-голяма, за да обработвам низове> 8K и с> 8K елементи (направих я с 1MM редове). След това създадох седем съхранени процедури:пет от тях приемат
varchar(max)и присъединяване с изхода на функцията, за да се актуализира основната таблица, и след това две, за да приемат TVP и да се присъединят директно към него. Кодът на C# извиква всяка от тези седем процедури със списъка от 10 000 публикации за избор или актуализиране 1000 пъти. Тези процедури също са в приложението по-долу. Така че само за да обобщим, методите, които се тестват са:
- Натив (
STRING_SPLIT()) - XML
- CLR
- Таблица с числа
- JSON (с изричен
intизход) - Параметър със стойност на таблица
- Оптимизиран за паметта параметър с таблична стойност
Ще тестваме извличане на 10 000 стойности, 1000 пъти, с помощта на DataReader – но без итерация над DataReader, тъй като това просто ще направи теста по-дълъг и ще бъде същото количество работа за приложението C#, независимо от това как базата данни произведе комплекта. Ще тестваме също актуализирането на 10 000 реда, 1000 пъти всеки, използвайки ExecuteNonQuery() . И ще тестваме както с обикновената, така и с оптимизираната за паметта версия на таблицата Posts, която можем да превключваме много лесно, без да се налага да променяме която и да е от функциите или процедурите, използвайки синоним:
СЪЗДАЙТЕ СИНОНИМ dbo.Posts FOR dbo.Posts_Regular; -- за тестване на оптимизирана за паметта версия:ИЗПУСКАНЕ СИНОНИМ dbo.Posts;СЪЗДАВАНЕ НА СИНОНИМ dbo.Posts ЗА dbo.Posts_InMemory; -- за да тествате отново базираната на диск версия:ИЗПУСКАНЕ НА СИНОНИМ dbo.Posts;СЪЗДАВАНЕ НА СИНОНИМ dbo.Posts ЗА dbo.Posts_Regular;
Стартирах приложението, стартирах го няколко пъти за всяка комбинация, за да се уверя, че компилацията, кеширането и други фактори не са нечестни по отношение на пакета, изпълнен първо, и след това анализирах резултатите от таблицата за регистриране (също проверих на място sys. dm_exec_procedure_stats, за да се уверите, че нито един от подходите не е имал значителни режийни разходи, базирани на приложения, и не са го направили).
Резултати – Дискови таблици
Понякога се боря с визуализацията на данни – наистина се опитах да измисля начин да представя тези показатели на една диаграма, но мисля, че имаше твърде много точки от данни, за да изпъкнат най-важните.
Можете да щракнете, за да увеличите някое от тях в нов раздел/прозорец, но дори и да имате малък прозорец, аз се опитах да изясня победителя чрез използване на цвят (и победителят беше един и същ във всеки случай). И за да бъде ясно, под „Средна продължителност“ имам предвид средното време, необходимо на приложението да завърши цикъл от 1000 операции.
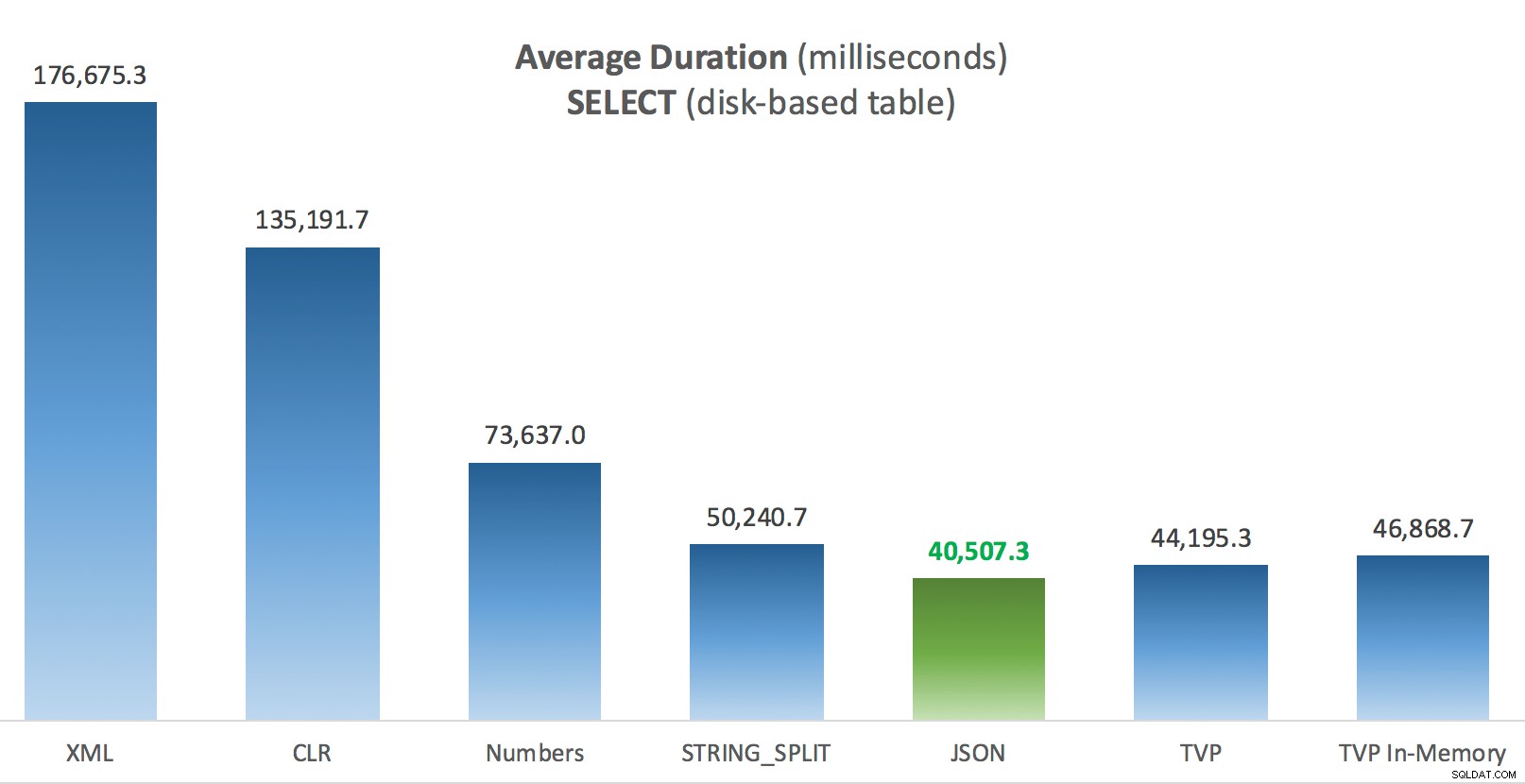 Средна продължителност (милисекунди) за SELECT срещу дискова таблица с публикации
Средна продължителност (милисекунди) за SELECT срещу дискова таблица с публикации
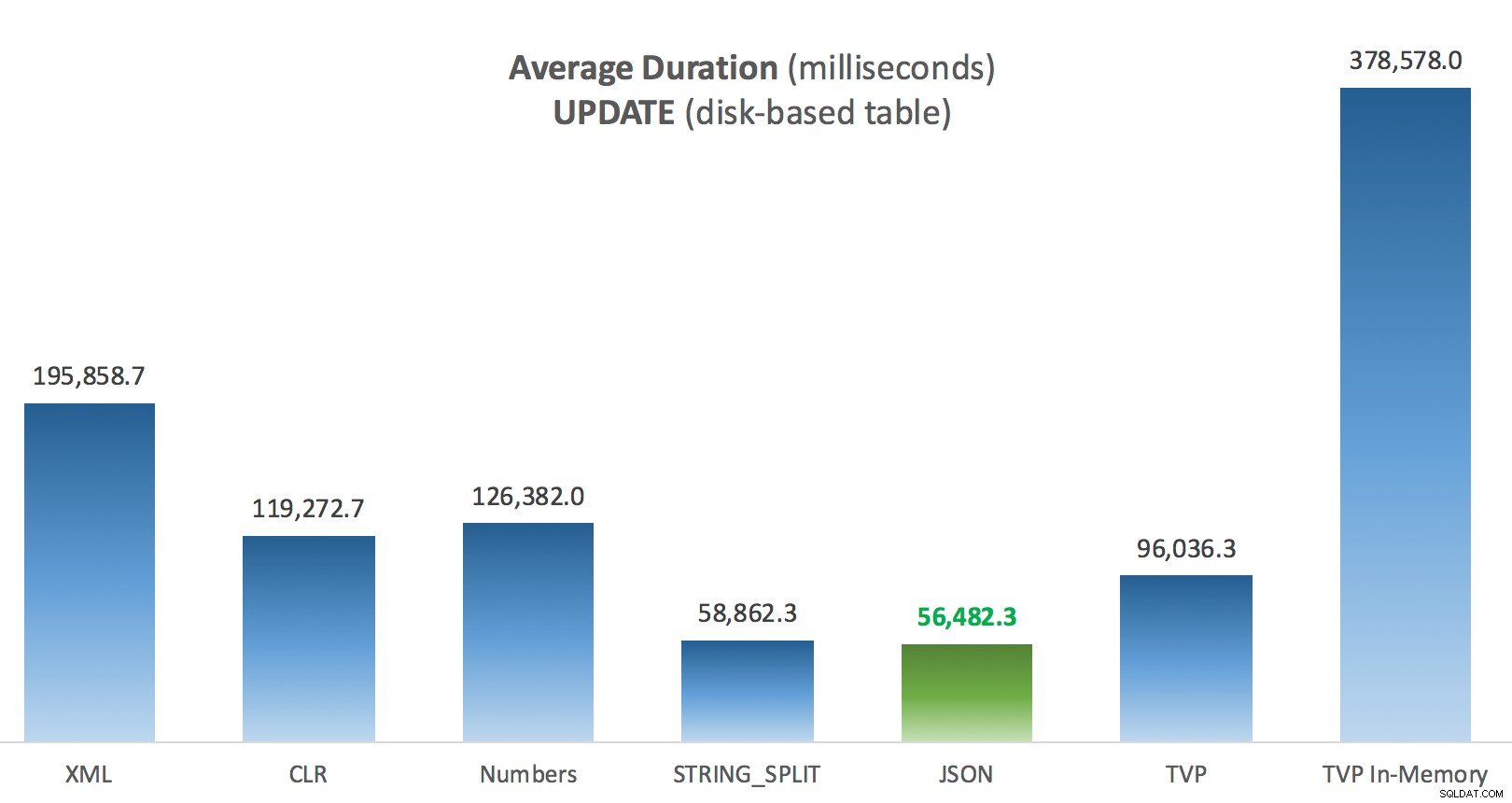 Средна продължителност (милисекунди) за актуализации срещу дискова таблица с публикации
Средна продължителност (милисекунди) за актуализации срещу дискова таблица с публикации
Най-интересното тук за мен е колко зле се справи оптимизираният за паметта TVP, когато помага с UPDATE . Оказва се, че паралелните сканирания в момента са блокирани твърде агресивно, когато е включен DML; Microsoft разпозна това като пропуск в функциите и се надяват скоро да го преодолеят. Имайте предвид, че понастоящем е възможно паралелно сканиране с SELECT но в момента е блокиран за DML. (Това няма да бъде разрешено в SQL Server 2014, тъй като тези специфични операции за паралелно сканиране не са налични там за никакви операции.) Когато това е фиксирано или когато вашите TVP са по-малки и/или паралелизмът така или иначе не е от полза, трябва да видите че оптимизираните за паметта TVP ще се представят по-добре (шаблонът просто не работи добре за този конкретен случай на използване на относително големи TVP).
За този конкретен случай ето плановете за SELECT (което бих могъл да принудя да върви паралелно) и UPDATE (което не можах):
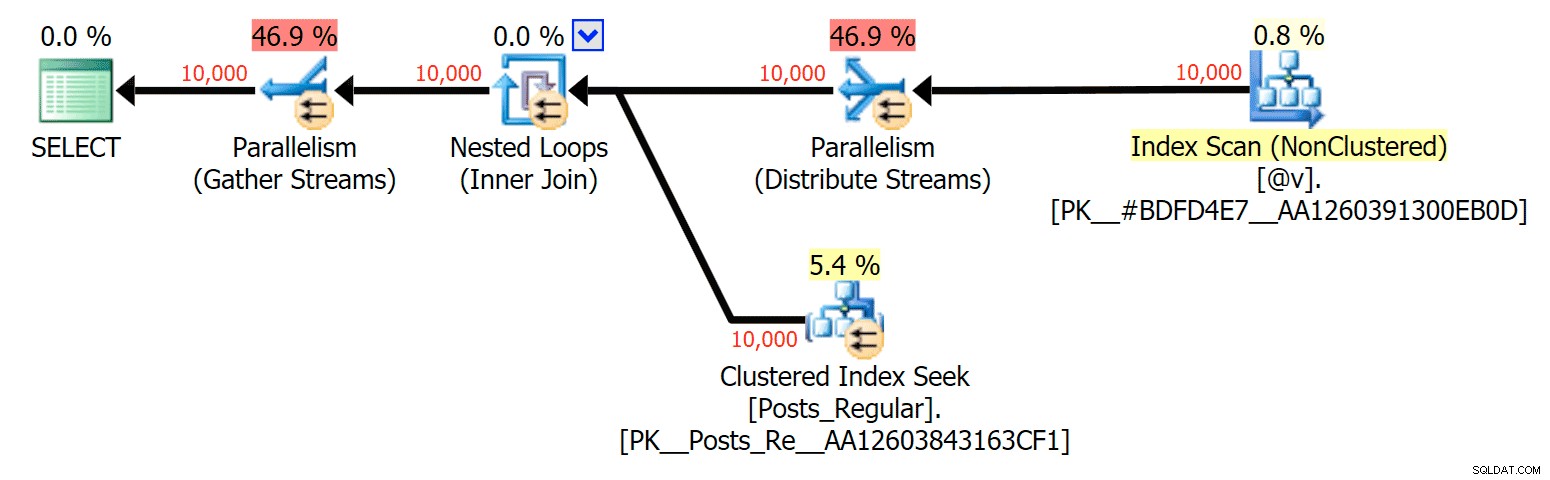 Паралелизъм в план SELECT, свързващ базирана на диск таблица към TVP в паметта
Паралелизъм в план SELECT, свързващ базирана на диск таблица към TVP в паметта
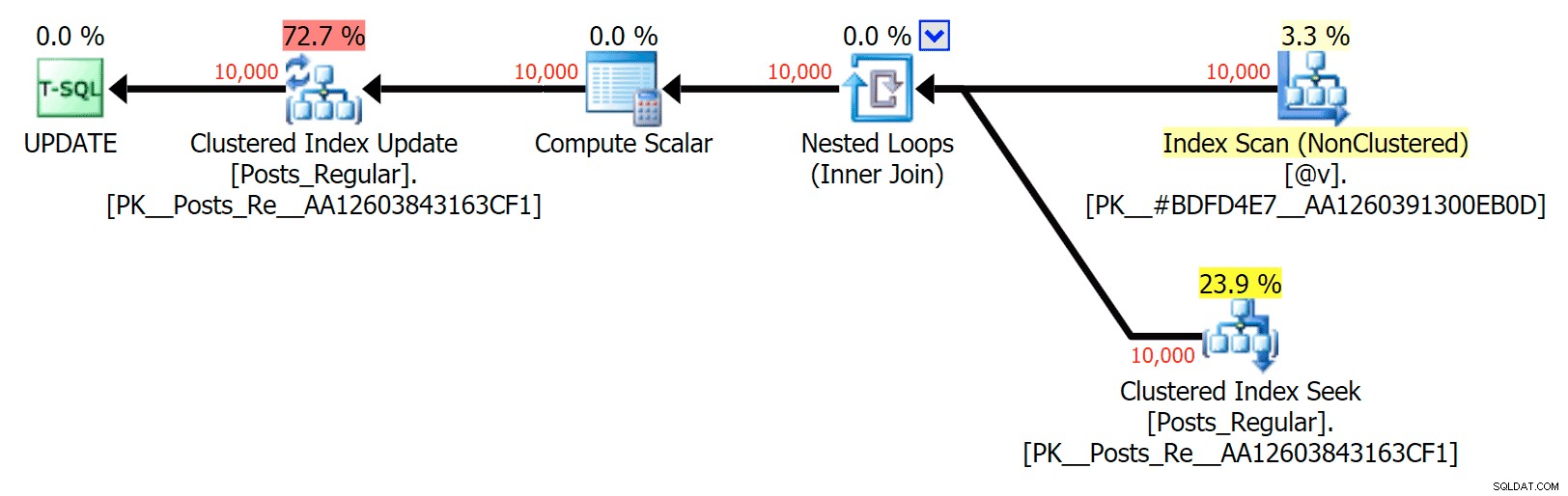 Без паралелизъм в план UPDATE, свързващ базирана на диск таблица към памет в паметта TVP
Без паралелизъм в план UPDATE, свързващ базирана на диск таблица към памет в паметта TVP
Резултати – оптимизирани за паметта таблици
Тук малко повече последователност – четирите метода вдясно са относително равномерни, докато трите отляво изглеждат много нежелателни за разлика от тях. Също така обърнете специално внимание на абсолютния мащаб в сравнение с таблиците, базирани на диск – в по-голямата си част, като използвате същите методи и дори без паралелизъм, в крайна сметка получавате много по-бързи операции срещу оптимизирани за памет таблици, което води до по-ниско общо използване на процесора.
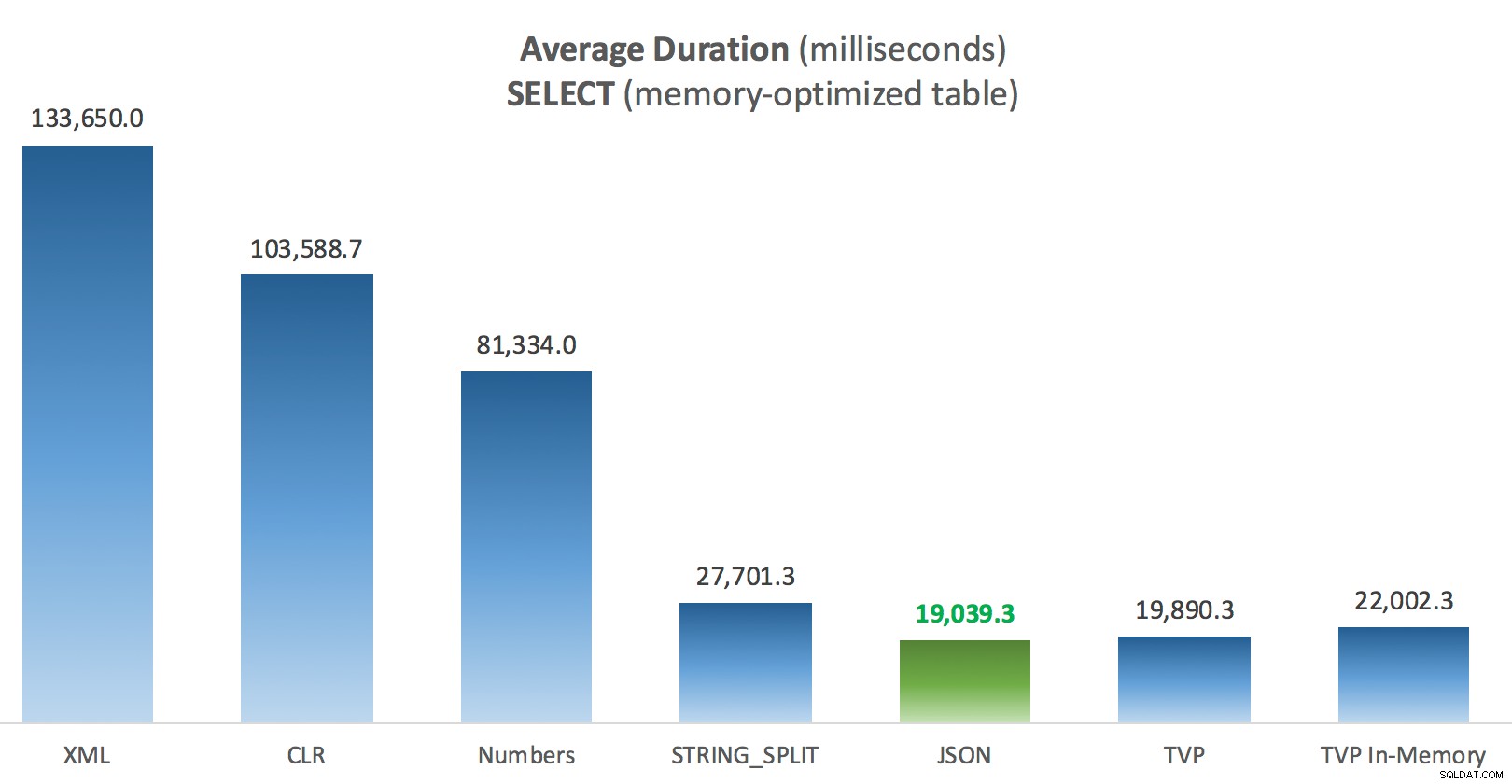 Средна продължителност (милисекунди) за SELECT спрямо оптимизирана за памет таблица с публикации
Средна продължителност (милисекунди) за SELECT спрямо оптимизирана за памет таблица с публикации
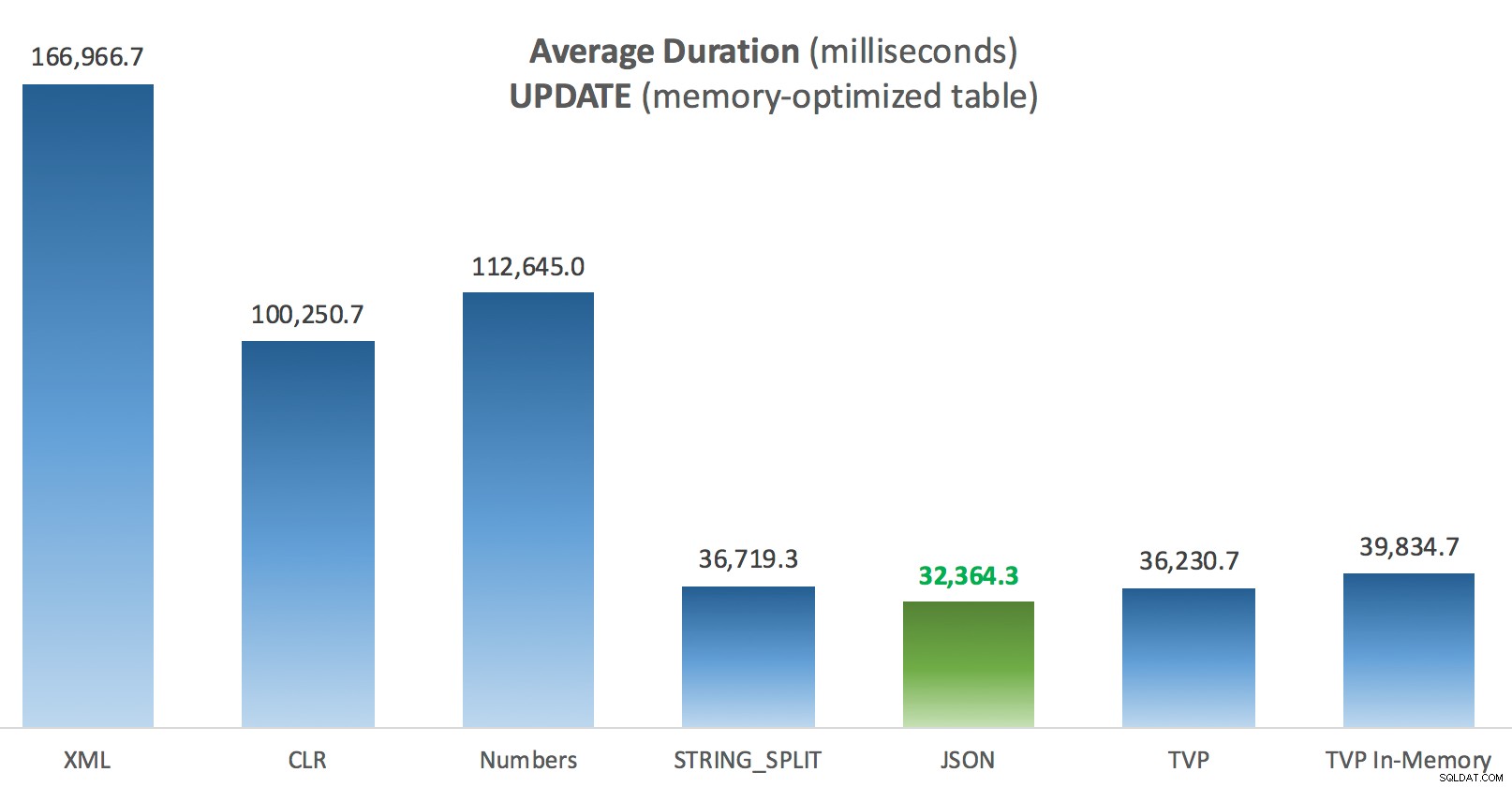 Средна продължителност (милисекунди) за актуализации спрямо оптимизирана за памет таблица с публикации
Средна продължителност (милисекунди) за актуализации спрямо оптимизирана за памет таблица с публикации
Заключение
За този конкретен тест, със специфичен размер на данните, разпределение и брой параметри и на моя конкретен хардуер, JSON беше последователен победител (макар и незначително). За някои от другите тестове в предишни публикации обаче други подходи се справиха по-добре. Само пример за това как това, което правите и къде го правите, може да има драматично въздействие върху относителната ефективност на различните техники, ето нещата, които тествах в тази кратка серия, с моето резюме коя техника да използвайте в този случай и кой да използвате като 2-ри или 3-ти избор (например, ако не можете да внедрите CLR поради корпоративна политика или защото използвате Azure SQL база данни, или не можете да използвате JSON или STRING_SPLIT() защото все още не сте на SQL Server 2016). Имайте предвид, че не се върнах и не тествах повторно присвояването на променлива и SELECT INTO скриптове, използващи TVP – тези тестове са настроени, като се приема, че вече имате съществуващи данни във формат CSV, които така или иначе първо трябва да бъдат разбити. Като цяло, IMHO, ако можете да го избегнете, не изглаждайте наборите си в низове, разделени със запетая.
| Цел | 1-ви избор | 2-ри избор (и 3-ти, където е подходящо) |
|---|---|---|
| Просто присвояване на променлива | STRING_SPLIT() | CLR ако <2016 XML ако няма CLR и <2016 |
| ИЗБЕРЕТЕ В | CLR | XML, ако няма CLR |
| ИЗБЕРЕТЕ В (без макара) | CLR | Таблица с числа, ако няма CLR |
| ИЗБЕРЕТЕ В (без макара + MAXDOP 1) | STRING_SPLIT() | CLR ако <2016 Таблица с числа, ако няма CLR и <2016 |
| ИЗБЕРЕТЕ присъединяване към голям списък (базирано на диск) | JSON (int) | TVP ако <2016 |
| ИЗБЕРЕТЕ присъединяване към голям списък (оптимизиран за памет) | JSON (int) | TVP ако <2016 |
| АКТУАЛИЗИРАНЕ се присъединява към голям списък (базирано на диск) | JSON (int) | TVP ако <2016 |
| АКТУАЛИЗИРАНЕ се присъединява към голям списък (оптимизиран за памет) | JSON (int) | TVP ако <2016 |
За конкретния въпрос на Дъг:JSON, STRING_SPLIT() , и TVPs се представят доста сходно в тези тестове средно – достатъчно близо, че TVPs са очевидният избор, ако не сте на SQL Server 2016. Ако имате различни случаи на използване, тези резултати може да се различават. Страхотно .
Което ни води до морала на това история:аз и други може да извършваме много специфични тестове за производителност, въртящи се около всяка функция или подход, и да стигнем до някакво заключение кой подход е най-бърз. Но има толкова много променливи, че никога няма да имам увереността да кажа „този подход е винаги най-бързият." В този сценарий се опитах много да контролирам повечето от допринасящите фактори и докато JSON спечели и в четирите случая, можете да видите как тези различни фактори повлияха на времето за изпълнение (и драстично за някои подходи). Така че винаги си струва да създадете свои собствени тестове и се надявам, че съм помогнал да илюстрирам как се справям с подобни неща.
Допълнение A:Код на приложението за конзола
Моля, без придирки относно този код; той беше буквално събран като много прост начин за стартиране на тези съхранени процедури 1000 пъти с истински списъци и таблици с данни, събрани в C#, и за регистриране на времето, което всеки цикъл е отделил на таблица (за да сте сигурни, че включвате всички свързани с приложението допълнителни разходи с обработка или голям низ, или колекция). Бих могъл да добавя обработка на грешки, цикъл по различен начин (например конструирам списъците вътре в цикъла, вместо да използвам повторно една единица работа) и така нататък.
използвайки System;използвайки System.Text;използвайки System.Configuration;използвайки System.Data;използвайки System.Data.SqlClient; namespace SplitTesting{ class Program { static void Main(string[] args) { string operation ="Update"; if (args[0].ToString() =="-Select") { operation ="Select"; } var csv =нов StringBuilder(); Елементи на DataTable =new DataTable(); elements.Columns.Add("value", typeof(int)); for (int i =1; i <=10000; i++) { csv.Append((i*300).ToString()); if (i <10000) { csv.Append(","); } елементи.Редове.Добавяне(i*300); } string[] методи ={ "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" }; използване (SqlConnection con =new SqlConnection()) { con.ConnectionString =ConfigurationManager.ConnectionStrings["primary"].ToString(); con.Open(); SqlParameter p; foreach (метод на низ в методите) { SqlCommand cmd =new SqlCommand("dbo." + operation + "Posts_" + method, con); cmd.CommandType =CommandType.StoredProcedure; if (method =="TVP" || method =="TVP_InMemory") { cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value =елементи; } else { cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value =csv.ToString(); } var timer =System.Diagnostics.Stopwatch.StartNew(); for (int x =1; x <=1000; x++) { if (operation =="Update") { cmd.ExecuteNonQuery(); } else { SqlDataReader rdr =cmd.ExecuteReader(); rdr.Close(); } } таймер.Стоп(); long this_time =timer.ElapsedMilliseconds; // време за регистриране - процедурата за регистриране добавя часовник и // записва памет/диск (определя се чрез синоним) SqlCommand log =new SqlCommand("dbo.LogBatchTime", con); log.CommandType =CommandType.StoredProcedure; log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Стойност =операция; log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Стойност =метод; log.Parameters.Add("@Timing", SqlDbType.Int).Value =this_time; log.ExecuteNonQuery(); Console.WriteLine(method + " :" + this_time.ToString()); } } } }} Примерно използване:
SplitTesting.exe -ИзберетеSplitTesting.exe -Актуализация
Допълнение Б:Функции, процедури и таблица за регистриране
Ето функциите, редактирани да поддържат varchar(max) (функцията CLR вече е приета nvarchar(max) и все още не съм склонен да се опитам да го променя):
СЪЗДАВАНЕ НА ФУНКЦИЯ dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))ВЪРНА ТАБЛИЦА С ВЪЗРАЩАНЕ НА SCHEMABINDINGAS (ИЗБЕРЕТЕ [стойност] ОТ STRING_SPLIT(@List, @Delimiter)); ( @List varchar(max), @Delimiter char(1))ВЪРЩА ТАБЛИЦА СЪС SCHEMABINDINGAS ВРЪЩАНЕ (SELECT [value] =y.i.value('(./text())[1]', 'varchar(max)') ОТ (SELECT x =CONVERT(XML, '' + REPLACE(@List, @Delimiter, '') + '').query('.')) КАТО КРЪСТНО ПРИЛОЖИ x.nodes('i') КАТО y(i));GO CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))ВЪРНА ТАБЛИЦА СЪС SCHEMABINDINGAS ВЪЗРАЩАНЕ (ИЗБЕРЕТЕ [стойност] =ПОДНИЗ (@List, Number, CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number) ОТ dbo.Numbers WHERE Number <=CONVERT(INT, LEN(@List)) И SUBSTRING(@Delimiter + @List, Number , LEN(@Delimiter)) =@Delimiter );GO СЪЗДАЙТЕ ФУНКЦИЯ dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))ВЪРНА ТАБЛИЦА СЪС SCH EMABINDINGAS RETURN (ИЗБЕРЕТЕ [стойност] ОТ OPENJSON(CHAR(91) + @List + CHAR(93)) С (стойност int '$'));GO И съхранените процедури изглеждаха така:
СЪЗДАВАНЕ НА ПРОЦЕДУРА dbo.UpdatePosts_Native @PostList varchar(max)ASBEGIN UPDATE p SET HitCount +=1 FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s. [стойност];ENDGOCREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max)ASBEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') P AS s ID ON p. s.[value];ENDGO-- повторете за 4-те други базирани на varchar(max) метода CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular САМО ЧИТАЙТЕ -- превключете _Regular към _InMemoryASBEGIN SET NOCOUNT ON; АКТУАЛИЗАЦИЯ p SET HitCount +=1 FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGOCREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- превключете _InNORegular като _InNOMegular; ИЗБЕРЕТЕ p.PostID, p.HitCount ОТ dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGO-- повторете за в паметта
И накрая, таблицата за регистриране и процедурата:
CREATE TABLE dbo.SplitLog( LogID int IDENTITY(1,1) PRIMARY KEY, ClockTime datetime NOT NULL DEFAULT GETDATE(), OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory или Posts_Regular Operation NOT varchar(32) DEFAULT 'Update', -- или изберете Method varchar(32) NOT NULL DEFAULT 'Native', -- или TVP, JSON и т.н. Timing int NOT NULL DEFAULT 0);GO CREATE PROCEDURE dbo.LogBatchTime @Operation varchar(32), @Method varchar(32), @Timing intASBEGIN SET NOCOUNT ON; INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing) SELECT base_object_name, @Operation, @Method, @Timing FROM sys.synonyms WHERE name =N'Posts';ENDGO -- и заявката за генериране на графиките:;WITH x AS( SELECT OperatingTable,Operation,Method,Timing,Recency =ROW_NUMBER()OVER (PARTITION BY OperatingTable,Operation,Method ORDER BY ClockTime DESC) ОТ dbo.SplitLog)SELECT OperatingTable,Operation,Method,AverageDuration.0*AVTim FROM x WHERE Актуалност <=3GROUP BY OperatingTable,Operation,Method;