Отложената издръжливост е нова, но интересна функция в SQL Server 2014; високото ниво на асансьор на функцията е съвсем просто:
- „Търгувайте издръжливост за производителност.“
Първо малко предистория. По подразбиране SQL Server използва дневник с предварителна запис (WAL), което означава, че промените се записват в дневника, преди да им бъде разрешено да бъдат записани. В системи, където записите в регистъра на транзакциите се превръщат в пречка и където има умерен толеранс за загуба на данни , вече имате опцията временно да спрете изискването за изчакване на изчистване и потвърждение на регистрационния файл. Това се случва буквално да извади D от ACID, поне за малка част от данни (повече за това по-късно).
Вече правиш тази жертва. В режим на пълно възстановяване винаги има известен риск от загуба на данни, той просто се измерва по отношение на времето, а не по размер. Например, ако архивирате дневника на транзакциите на всеки пет минути, можете да загубите до малко под 5 минути данни, ако се случи нещо катастрофално. Тук не говоря за просто отказване, но да кажем, че сървърът буквално се запали или някой се спъне в захранващия кабел – базата данни може много добре да е невъзстановима и може да се наложи да се върнете към момента на последното архивиране на журнала . И това е при условие, че дори тествате резервните си копия, като ги възстановявате някъде – в случай на критична повреда може да нямате точката на възстановяване, която смятате, че имате. Склонни сме да не мислим за този сценарий, разбира се, защото никога не очакваме лоши неща™ да се случи.
Как работи
Отложената издръжливост позволява транзакциите за запис да продължат да работят, сякаш дневникът е бил изтрит на диск; в действителност записите на диска са групирани и отложени, за да се обработват във фонов режим. Сделката е оптимистична; предполага, че изчистването на дневника ще се случи. Системата използва 60KB парче буфер на дневника и се опитва да изтрие дневника на диск, когато този блок от 60KB е пълен (най-късно – може и често ще се случи преди това). Можете да зададете тази опция на ниво база данни, на ниво отделна транзакция или – в случай на нативно компилирани процедури в In-Memory OLTP – на ниво процедура. Настройката на базата данни печели в случай на конфликт; например, ако базата данни е деактивирана, опитът за извършване на транзакция с помощта на отложената опция просто ще бъде игнориран, без съобщение за грешка. Също така, някои транзакции винаги са напълно издръжливи, независимо от настройките на базата данни или настройките за комит; например системни транзакции, транзакции между бази данни и операции, включващи FileTable, проследяване на промените, улавяне на промяна на данни и репликация.
На ниво база данни можете да използвате:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Ако го зададете на ALLOWED , това означава, че всяка отделна транзакция може да използва Delayed Durability; FORCED означава, че всички транзакции, които могат да използват отложена трайност, ще бъдат (изключенията по-горе са все още уместни в този случай). Вероятно ще искате да използвате ALLOWED вместо FORCED – но последното може да бъде полезно в случай на съществуващо приложение, където искате да използвате тази опция навсякъде и също така да сведете до минимум количеството код, който трябва да се докосне. Важно нещо, което трябва да се отбележи относно ALLOWED е, че напълно трайните транзакции може да се наложи да чакат по-дълго, тъй като те първо ще принудят изчистването на всякакви забавени трайни транзакции.
На ниво транзакция можете да кажете:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
И в OLTP, компилирана в паметта процедура, можете да добавите следната опция към BEGIN ATOMIC блок:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Често срещан въпрос е какво се случва със семантиката на заключване и изолация. Нищо не се променя, наистина. Заключването и блокирането все още се случват, а транзакциите се извършват по същия начин и със същите правила. Единствената разлика е, че като се позволи извършването на комит, без да се чака регистрационният файл да се изчисти на диск, всички свързани заключвания се освобождават много по-рано.
Кога трябва да го използвате
В допълнение към ползата, която получавате от разрешаването на транзакциите да продължат, без да чакате да се случи записа в дневника, получавате и по-малко записвания в дневник с по-големи размери. Това може да работи много добре, ако вашата система има голям дял от транзакции, които всъщност са по-малки от 60KB, и особено когато лог дискът е бавен (въпреки че открих подобни предимства при SSD и традиционния HDD). Не работи толкова добре, ако транзакциите ви са в по-голямата си част по-големи от 60KB, ако обикновено са дългосрочни или ако имате висока пропускателна способност и висок едновременност. Това, което може да се случи тук, е, че можете да попълните целия буфер на регистрационния файл, преди изчистването да завърши, което просто означава прехвърляне на вашите изчаквания към друг ресурс и в крайна сметка да не подобрявате възприеманата производителност от потребителите на приложението.
С други думи, ако вашият регистър на транзакциите в момента не е пречка, не включвайте тази функция. Как можете да разберете дали вашият регистър на транзакциите в момента е тесно място? Първият индикатор би бил висок WRITELOG чака, особено когато е свързан с PAGEIOLATCH_** . Пол Рандал (@PaulRandal) има страхотна серия от четири части за идентифициране на проблеми с регистрационните файлове на транзакциите, както и за конфигуриране за оптимална производителност:
- Отрязване на мазнините в регистъра на транзакциите
- Отрязване на повече мазнини в регистъра на транзакциите
- Проблеми с конфигурацията на регистъра на транзакциите
- Наблюдение на регистъра на транзакциите
Вижте също тази публикация в блога на Kimberly Tripp (@KimberlyLTripp), 8 стъпки за по-добра производителност на регистрационните файлове на транзакциите и публикацията в блога на SQL CAT екипа, Диагностициране на проблеми с производителността на регистрационните файлове и ограничения на Log Manager.
Това разследване може да ви доведе до заключението, че отложената издръжливост си струва да се разгледа; може и да не. Тестването на вашето работно натоварване ще бъде най-надеждният начин да знаете със сигурност. Подобно на много други допълнения в последните версии на SQL Server (*cough* Hekaton ), тази функция НЕ е предназначена да подобри всяко едно работно натоварване – и както беше отбелязано по-горе, всъщност може да влоши някои натоварвания. Вижте тази публикация в блога на Саймън Харви за някои други въпроси, които трябва да си зададете относно работното си натоварване, за да определите дали е възможно да пожертвате известна издръжливост, за да постигнете по-добра производителност.
Потенциал за загуба на данни
Ще спомена това няколко пъти и ще добавя акцент всеки път, когато го правя:Трябва да бъдете толерантни към загубата на данни . При добре работещ диск максимумът, който трябва да очаквате да загубите при катастрофа – или дори планирано и грациозно изключване – е до един пълен блок (60KB). Въпреки това, в случай, че вашата I/O подсистема не може да се справи, е възможно да загубите толкова, колкото целия буфер на журнала (~7MB).
За да поясня, от документацията (подчертавам моя):
За забавена издръжливост, няма разлика между неочаквано изключване и очаквано изключване/рестартиране на SQL Server . Подобно на катастрофални събития, трябва да планирате загуба на данни . При планирано изключване/рестартиране някои транзакции, които не са записани на диск, могат първо да бъдат записани на диск, но не трябва да планирате това. Планирайте така, сякаш изключване/рестартиране, независимо дали е планирано или непланирано, губи данните по същия начин като катастрофално събитие.Затова е много важно да прецените риска от загуба на данни с нуждата си да облекчите проблемите с производителността на регистрационния файл на транзакциите. Ако управлявате банка или нещо, занимаващо се с пари, може да е много по-безопасно и по-подходящо за вас да преместите дневника си на по-бърз диск, отколкото да хвърлите заровете с помощта на тази функция. Ако се опитвате да подобрите времето за реакция в приложението си Web Gamerz Chat Room, може би рискът е по-малко сериозен.
Можете да контролирате това поведение до известна степен, за да сведете до минимум риска от загуба на данни. Можете да принудите всички забавени трайни транзакции да бъдат прехвърлени на диск по един от двата начина:
- Извършете всяка напълно трайна транзакция.
- Обадете се на
sys.sp_flush_logръчно.
Това ви позволява да се върнете към контролиране на загубата на данни по отношение на времето, а не по размер; бихте могли да насрочите промиването на всеки 5 секунди, например. Но вие ще искате да намерите вашето сладко място тук; твърде честото промиване може на първо място да компенсира ползата от отложена издръжливост. Във всеки случай, ще трябва да сте толерантни към загуба на данни , дори ако струва само
Бихте си помислили, че CHECKPOINT може да помогне тук, но тази операция всъщност не гарантира технически, че журналът ще бъде изтрит на диск.
Взаимодействие с HA/DR
Може да се чудите как функционира Delayed Durability с функции за HA/DR, като доставка на регистрационни файлове, репликация и групи за наличност. С повечето от тях работи непроменено. Доставката и репликацията на регистрационни файлове ще възпроизведат записите в регистрационните файлове, които са били втвърдени, така че там съществува същият потенциал за загуба на данни. С AG в асинхронен режим ние така или иначе не чакаме вторичното потвърждение, така че то ще се държи по същия начин като днес. Със синхронен обаче не можем да извършим ангажимент на първичния, докато транзакцията не бъде ангажирана и затвърдена към отдалечения журнал. Дори в този сценарий може да имаме някаква полза локално, като не се налага да чакаме локалния дневник да запише, все пак трябва да изчакаме отдалечената дейност. Така че в този сценарий има по-малко полза, а потенциално никаква; освен може би в редкия сценарий, при който регистрационният диск на първичния е наистина бавен, а лог дискът на вторичния е наистина бърз. Подозирам, че същите условия са валидни и за синхронизиране/асинхронно огледално копиране, но няма да получите никакъв официален ангажимент от мен за това как една лъскава нова функция работи с остаряла. :-)
Наблюдения за ефективността
Това нямаше да е кой знае каква публикация тук, ако не покажа някои действителни наблюдения на производителността. Настроих 8 бази данни, за да тествам ефектите от два различни модела на натоварване със следните атрибути:
- Модел за възстановяване:просто срещу пълно
- Местоположение на регистрационния файл:SSD срещу HDD
- Издръжливост:забавено спрямо напълно издръжливо
Наистина, наистина, наистина съм мързелив ефективно за този вид неща. Тъй като искам да избегна повтарянето на едни и същи операции във всяка база данни, създадох временно следната таблица в model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
След това създадох набор от динамични SQL команди за изграждане на тези 8 бази данни, вместо да създавам базите данни поотделно и след това да се занимавам с настройките:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Чувствайте се свободни да стартирате този код сами (с EXEC все още е коментиран), за да видите, че това ще създаде 4 бази данни с ИЗКЛЮЧЕНА отложена издръжливост (две в ПЪЛНО възстановяване, две в SIMPLE, една от всяка с вход на бавен диск и една от всяка с влизане на SSD). Повторете този модел за 4 бази данни с принудителна отложена издръжливост – направих това, за да опростя кода в теста, вместо да отразявам какво бих направил в реалния живот (където вероятно бих искал да третирам някои транзакции като критични, а някои като, добре, по-малко от критично).
За проверка на здравия разум изпълних следната заявка, за да гарантирам, че базите данни имат правилната матрица от атрибути:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Резултати:
| име | модел_възстановяване | отложена_издръжливост | log_disk |
|---|---|---|---|
| dd1 | ПЪЛЕН | Принудително | SSD |
| dd2 | Просто | Принудително | SSD |
| dd3 | ПЪЛЕН | Принудително | HDD |
| dd4 | Просто | Принудително | HDD |
| dd5 | ПЪЛЕН | ИЗКЛЮЧЕНО | SSD |
| dd6 | Просто | ИЗКЛЮЧЕНО | SSD |
| dd7 | ПЪЛЕН | ИЗКЛЮЧЕНО | HDD |
| dd8 | Просто | ИЗКЛЮЧЕНО | HDD |
Съответна конфигурация на 8-те тестови бази данни
Също така проведох чисто теста няколко пъти, за да се уверя, че файл с данни от 1 GB и регистрационен файл от 1 GB ще бъдат достатъчни за изпълнение на целия набор от работни натоварвания, без да се въвеждат събития за автоматично нарастване в уравнението. Като най-добра практика, аз рутинно полагам усилия, за да гарантирам, че системите на клиентите имат достатъчно разпределено пространство (и вградени правилни сигнали), така че никога да не настъпи събитие за растеж в неочакван момент. В реалния свят знам, че това не винаги се случва, но е идеално.
Настроих системата да се наблюдава с SQL Sentry – това ще ми позволи лесно да покажа повечето от показателите за производителност, които исках да подчертая. Но също така създадох временна таблица за съхраняване на пакетни показатели, включително продължителност и много специфичен изход от sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Това ще ми позволи да записвам началния и крайния час на всяка отделна партида и да измервам делтите в DMV между началния и крайния час (надежден само в този случай, защото знам, че съм единственият потребител в системата).
Много малки транзакции
Първият тест, който исках да направя, беше много малки транзакции. За всяка база данни исках да получа 500 000 отделни партиди от една вмъкнала всяка:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Не забравяйте, че се опитвам да бъда мързелив ефективно за този вид неща. За да генерирам кода за всичките 8 бази данни, изпълних това:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Проведох този тест и след това погледнах #Metrics таблица със следната заявка:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Това даде следните резултати (и потвърдих чрез множество тестове, че резултатите са последователни):
| база данни | пише | байта | байтове/запис | io_stall_ms | начален_час | краен_час | продължителност (секунди) |
|---|---|---|---|---|---|---|---|
| dd1 | 8 068 | 261 894 656 | 32 460,91 | 6232 | 26.04.2014 17:20:00 | 26.04.2014 г. 17:21:08 | 68 |
| dd2 | 8 072 | 261 682 688 | 32 418,56 | 2740 | 26.04.2014 г. 17:21:08 | 26.04.2014 г. 17:22:16 | 68 |
| dd3 | 8 246 | 262 254 592 | 31 803,85 | 3996 | 26.04.2014 г. 17:22:16 | 26.04.2014 г. 17:23:24 | 68 |
| dd4 | 8 055 | 261 688 320 | 32 487,68 | 4231 | 26.04.2014 г. 17:23:24 | 26.04.2014 17:24:32 | 68 |
| dd5 | 500 012 | 526 448 640 | 1052,87 | 35 593 | 26.04.2014 17:24:32 | 26.04.2014 г. 17:26:32 | 120 |
| dd6 | 500 014 | 525 870 080 | 1051,71 | 35 435 | 26.04.2014 г. 17:26:32 | 26.04.2014 г. 17:28:31 | 119 |
| dd7 | 500 015 | 526 120 448 | 1052,20 | 50 857 | 26.04.2014 г. 17:28:31 | 26.04.2014 17:30:45 | 134 |
| dd8 | 500 017 | 525 886 976 | 1051,73 | 49 680 | 133 |
Малки транзакции:Продължителност и резултати от sys.dm_io_virtual_file_stats
Определено някои интересни наблюдения тук:
- Броят на отделните операции на запис беше много малък за базите данни с отложена издръжливост (~60X за традиционните).
- Общият брой записани байтове беше намален наполовина с помощта на отложена издръжливост (предполагам, защото всички записи в традиционния случай съдържаха много загубено пространство).
- Броят на байтовете на запис е много по-висок за отложена издръжливост. Това не беше твърде изненадващо, тъй като цялата цел на функцията е да обедини записите в по-големи партиди.
- Общата продължителност на I/O спиранията беше променлива, но приблизително с порядък по-малка за отложена издръжливост. Сергиите при напълно трайни транзакции бяха много по-чувствителни към типа диск.
- Ако нещо не ви е убедило досега, колоната за продължителност е много показателна. Напълно издръжливите партиди, които отнемат две минути или повече, се нарязват почти наполовина.
Колоните за начален/краен час ми позволиха да се съсредоточа върху таблото за управление на Performance Advisor за точния период, в който са се случвали тези транзакции, където можем да начертаем много допълнителни визуални индикатори:
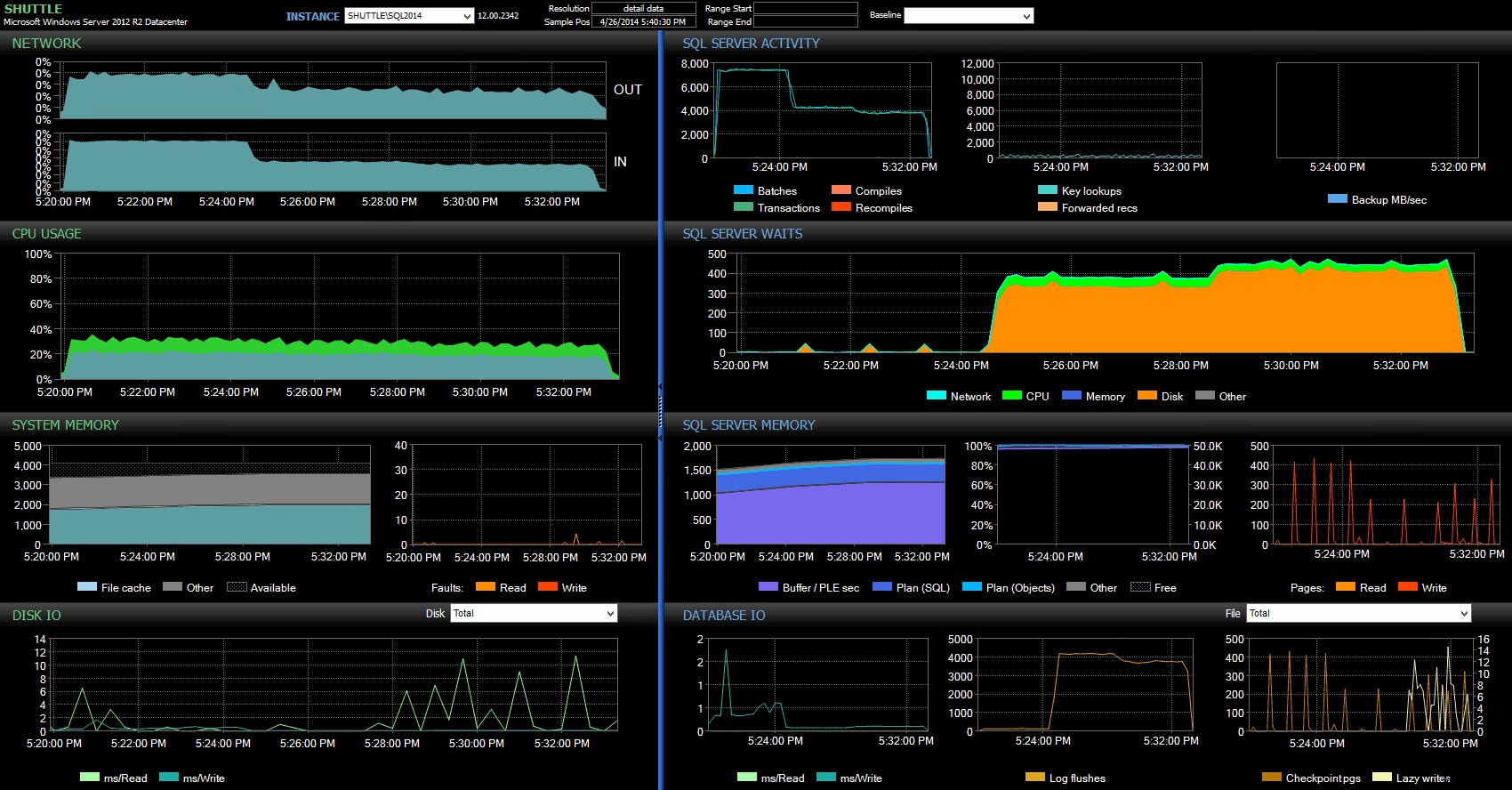
Табло за управление на SQL Sentry – щракнете, за да увеличите
Допълнителни наблюдения тук:
- На няколко графики можете ясно да видите кога точно частта с неотложена издръжливост на партидата е поела (~17:24:32 ч.).
- Няма видимо въздействие върху процесора или паметта при използване на отложена издръжливост.
- Можете да видите огромно въздействие върху партидите/транзакциите в секунда в първата графика под Активност на SQL Server.
- Изчакванията на SQL Server преминават през покрива, когато започнат напълно издръжливите транзакции. Те се състояха почти изключително от
WRITELOGчака, с малък бройPAGEIOLOATCH_EXиPAGEIOLATCH_UPчака добра мярка. - Общият брой изтривания на регистрационни файлове по време на операциите за отложена издръжливост беше доста малък (ниски 100 s/sec), докато този скочи до над 4000/сек за традиционното поведение (и малко по-нисък за продължителността на HDD на теста).
По-малко, по-големи транзакции
За следващия тест исках да видя какво ще се случи, ако извършим по-малко операции, но се уверих, че всяко изявление засяга по-голямо количество данни. Исках тази партида да работи срещу всяка база данни:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Така че отново използвах мързеливия метод, за да създам 8 копия на този скрипт, по едно на база данни:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Изпълних тази партида, след което промених заявката срещу #Metrics по-горе, за да разгледате втория тест вместо първия. Резултатите:
| база данни | пише | байта | байтове/запис | io_stall_ms | начален_час | краен_час | продължителност (секунди) |
|---|---|---|---|---|---|---|---|
| dd1 | 20 970 | 1,271,911,936 | 60 653,88 | 12 577 | 26.04.2014 г. 17:41:21 | 26.04.2014 г. 17:43:46 | 145 |
| dd2 | 20 997 | 1,272,145,408 | 60 587,00 | 14 698 | 26.04.2014 г. 17:43:46 | 26.04.2014 г. 17:46:11 | 145 |
| dd3 | 20 973 | 1 272 982 016 | 60 696,22 | 12 085 | 26.04.2014 г. 17:46:11 | 26.04.2014 17:48:33 | 142 |
| dd4 | 20 958 | 1,272,064,512 | 60 695,89 | 11 795 | 143 | ||
| dd5 | 30 138 | 1,282,231,808 | 42 545,35 | 7402 | 26.04.2014 г. 17:50:56 | 26.04.2014 г. 17:53:23 | 147 |
| dd6 | 30 138 | 1,282,260,992 | 42 546,31 | 7806 | 26.04.2014 г. 17:53:23 | 26.04.2014 г. 17:55:53 | 150 |
| dd7 | 30 129 | 1,281,575,424 | 42 536,27 | 9 888 | 26.04.2014 г. 17:55:53 | 26.04.2014 17:58:25 | 152 |
| dd8 | 30 130 | 1,281,449,472 | 42 530,68 | 11 452 | 26.04.2014 17:58:25 | 26.04.2014 18:00:55 | 150 |
По-големи транзакции:Продължителност и резултати от sys.dm_io_virtual_file_stats
Този път въздействието на Delayed Durability е много по-малко забележимо. Виждаме малко по-малък брой операции на запис, при малко по-голям брой байтове на запис, като общият брой записани байтове е почти идентичен. В този случай всъщност виждаме, че задръжките на I/O са по-високи за отложена издръжливост и това вероятно обяснява факта, че продължителността също е била почти идентична.
От таблото за управление на Performance Advisor имаме някои прилики с предишния тест, както и някои сериозни разлики:
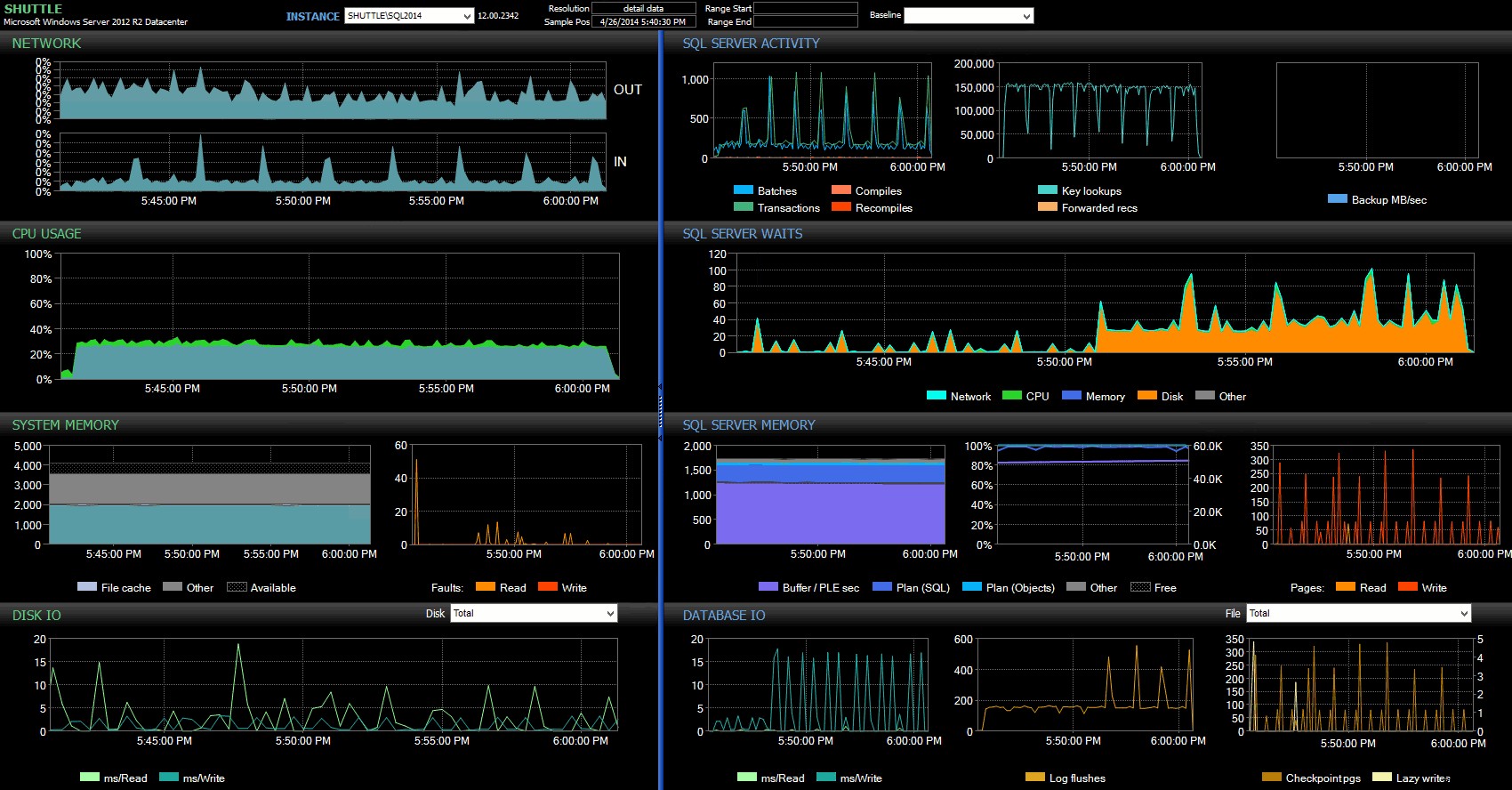
Табло за управление на SQL Sentry – щракнете, за да увеличите
Една от големите разлики, които трябва да се отбележи тук, е, че делтата в статистиката за чакане не е толкова изразена, колкото при предишния тест – все още има много по-висока честота на WRITELOG чака напълно издръжливите партиди, но далеч не до нивата, наблюдавани при по-малките транзакции. Друго нещо, което можете да забележите веднага, е, че наблюдаваното по-рано въздействие върху партидите и транзакциите в секунда вече не присъства. И накрая, въпреки че има повече изтривания на регистрационни файлове при напълно трайни транзакции, отколкото при забавени, това несъответствие е много по-слабо изразено, отколкото при по-малките транзакции.
Заключение
Трябва да е ясно, че има определени типове натоварвания, които могат да се възползват много от отложената издръжливост – при условие, разбира се, че имате толерантност към загуба на данни . Тази функция не е ограничена до OLTP в паметта, налична е във всички издания на SQL Server 2014 и може да бъде внедрена с малки или никакви промени в кода. Със сигурност може да бъде мощна техника, ако работното ви натоварване може да я поддържа. Но отново ще трябва да тествате работното си натоварване, за да сте сигурни, че ще се възползва от тази функция, и също така силно да обмислите дали това увеличава излагането ви на риска от загуба на данни.
Като настрана, това може да изглежда на тълпата на SQL Server като нова нова идея, но в действителност Oracle представи това като „Асинхронно записване“ през 2006 г. (вижте COMMIT WRITE ... NOWAIT както е документирано тук и публикувано в блога през 2007 г.). А самата идея съществува от близо 3 десетилетия; вижте кратката хроника на Хал Беренсън за неговата история.
Следващия път
Една идея, с която се замислих, е да се опитам да подобря производителността на tempdb като форсира отложена издръжливост там. Едно специално свойство на tempdb което го прави толкова примамлив кандидат е, че е преходен по природа – всичко в tempdb е проектиран изрично да може да се хвърля след голямо разнообразие от системни събития. Казвам това сега, без да имам никаква представа дали има форма на натоварване, при която това ще работи добре; но смятам да го пробвам и ако намеря нещо интересно, можете да сте сигурни, че ще публикувам за него тук.