Стратегията за индексиране на таблици е един от най-важните ключове за настройка и оптимизация на производителността. В SQL Server индексите (както клъстерирани, така и неклъстерни индекси) се създават с помощта на структура на B-дърво, в която всяка страница действа като двойно свързан списъчен възел, имащ информация за предишната и следващата страница. Тази структура на B-дърво, наречена Forward Scan, улеснява четенето на редовете от индекса чрез сканиране или търсене на страниците му от началото до края. Въпреки че сканирането напред е стандартният и широко известен метод за сканиране на индекси, SQL Server ни предоставя възможността да сканираме индексните редове в структурата на B-дървото от края до началото. Тази способност се нарича обратно сканиране. В тази статия ще видим как става това и какви са плюсовете и минусите на метода за обратно сканиране.
SQL Server ни предоставя възможността да четем данни от индекса на таблицата чрез сканиране на възлите на B-дървовата структура на индекса от началото до края с помощта на метода Forward Scan или четене на възлите на B-дървовата структура от края до началото с помощта на Метод за обратно сканиране. Както показва името, сканирането назад се извършва при четене, противоположно на реда на колоната, включена в индекса, което се изпълнява с опцията DESC в оператора за сортиране ORDER BY T-SQL, който определя посоката на операцията за сканиране.
В специфични ситуации SQL Server Engine установява, че четенето на индексните данни от края до началото с метода за обратно сканиране е по-бързо, отколкото четенето им в нормалния им ред с метода за сканиране напред, което може да изисква скъп процес на сортиране от SQL Двигател. Такива случаи включват използването на агрегатната функция MAX() и ситуации, когато сортирането на резултата от заявката е противоположно на реда на индекса. Основният недостатък на метода за обратно сканиране е, че SQL Server Query Optimizer винаги ще избира да го изпълни чрез изпълнение на последователен план, без да може да се възползва от плановете за паралелно изпълнение.
Да приемем, че имаме следната таблица, която ще съдържа информация за служителите на компанията. Таблицата може да бъде създадена с помощта на оператора CREATE TABLE T-SQL по-долу:
СЪЗДАВАНЕ НА ТАБЛИЦА [dbo].[CompanyEmployees]( [ID] [INT] ИДЕНТИФИКАЦИЯ (1,1) , [EmpID] [int] НЕ NULL, [Emp_First_Name] [nvarchar](50) NULL, [Emp_Last_Name] [ nvarchar](50) NULL, [EmpDepID] [int] НЕ NULL, [Emp_Status] [int] НЕ NULL, [EMP_PhoneNumber] [nvarchar](50) NULL, [Emp_Adress] [nvarchar](max) NULL, [Emp_Emplo] [DATETIME] NULL,ПЪРВЕН КЛУШЕР КЛУСТРИРАН ( [ID] ASC)НА [PRIMARY]))
След като създадем таблицата, ще я попълним с 10K фиктивни записи, като използваме оператора INSERT по-долу:
INSERT INTO [dbo].[CompanyEmployees] ([EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_DaPhoneNumber] ,[Emp_Adress_Ste],[Emp_Adress_Ste],[Emp_Adress_Ste],[Emp_Adress_Ste],[Emp_Status] AAA','BBB',4,1,9624488779,'AMM','2006-10-15')GO 10000
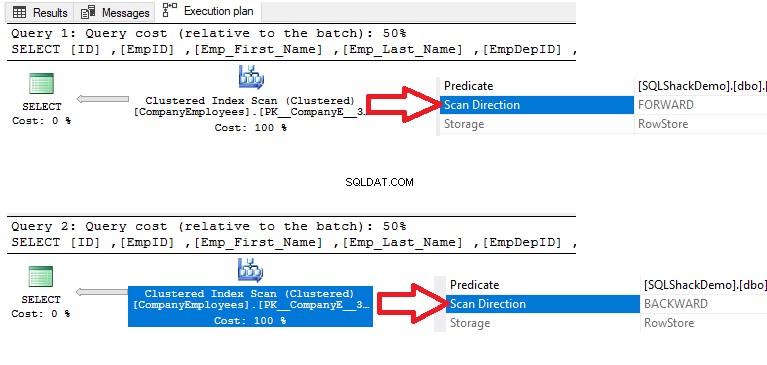
Ако изпълним оператора SELECT по-долу, за да извлечем данни от предварително създадена таблица, редовете ще бъдат сортирани според стойностите на колоната с ID във възходящ ред, който е същият като реда на клъстерирания индекс:
SELECT [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] ,[Emp_EmploymentDate] ,[Emp_EmploymentDate] ,[Emp_Employment_Date] ,[Emp_EmploymentDate] ,[Emp_EmploymentSQue] . ] ПОРЪЧАЙ ПО [ID] ASC
След това, проверявайки плана за изпълнение на тази заявка, ще се извърши сканиране на клъстерирания индекс, за да се получат сортираните данни от индекса, както е показано в плана за изпълнение по-долу:
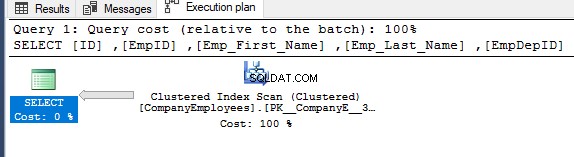
За да получите посоката на сканирането, което се извършва върху клъстерирания индекс, щракнете с десния бутон върху възела за сканиране на индекса, за да прегледате свойствата на възела. От свойствата на възела Clustered Index Scan, свойството Scan Direction ще покаже посоката на сканиране, което се извършва върху индекса в рамките на тази заявка, което е Сканиране напред, както е показано на моментната снимка по-долу:

Посоката на сканиране на индекса може също да бъде извлечена от плана за изпълнение на XML от свойството ScanDirection под възела IndexScan, както е показано по-долу:
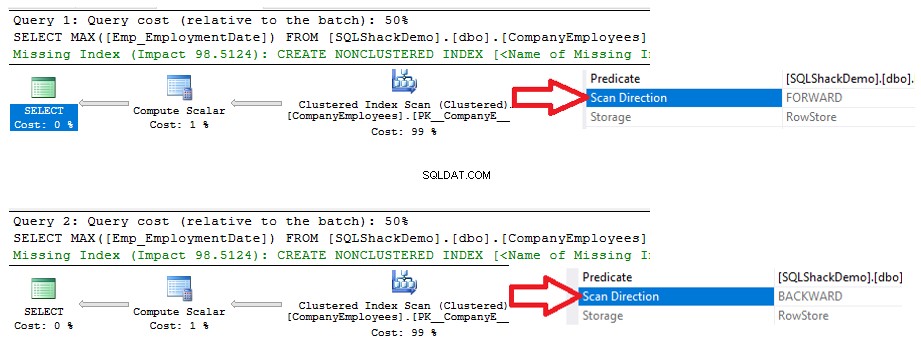
Да приемем, че трябва да извлечем максималната стойност на идентификатора от създадената по-рано таблица CompanyEmployees, използвайки T-SQL заявката по-долу:
ИЗБЕРЕТЕ MAX([ID]) ОТ [dbo].[CompanyEmployees]
След това прегледайте плана за изпълнение, който се генерира от изпълнението на тази заявка. Ще видите, че ще се извърши сканиране на клъстерирания индекс, както е показано в плана за изпълнение по-долу:
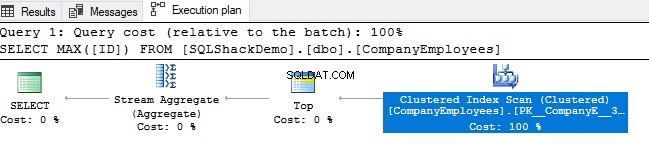
За да проверим посоката на сканирането на индекса, ще прегледаме свойствата на възела Clustered Index Scan. Резултатът ще ни покаже, че SQL Server Engine предпочита да сканира клъстерирания индекс от края до началото, което в този случай ще бъде по-бързо, за да получи максималната стойност на колоната ID, поради факта, че индексът вече е сортиран според колоната ID, както е показано по-долу:
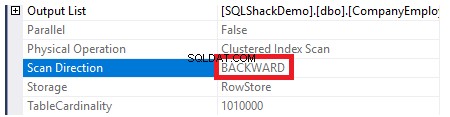
Също така, ако се опитаме да извлечем предварително създадените таблични данни с помощта на следния оператор SELECT, записите ще бъдат сортирани според стойностите на колоната с идентификатор, но този път, обратно на реда на клъстерирания индекс, като посочим опцията за сортиране DESC в ORDER Клауза BY, показана по-долу:
SELECT [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] ,[Emp_EmploymentDate] ,[Emp_EmploymentDate] ,[Emp_Employment_Date] ,[Emp_EmploymentDate] ,[Emp_EmploymentSQue] . ] ПОРЪЧАЙТЕ ПО [ID] DESC
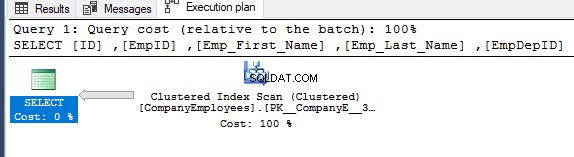
Ако проверите плана за изпълнение, генериран след изпълнение на предишната заявка SELECT, ще видите, че ще бъде извършено сканиране на клъстерирания индекс, за да получите исканите записи на таблицата, както е показано по-долу:
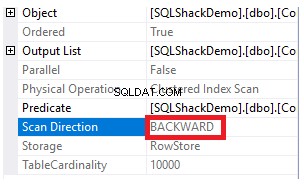
Свойствата на възела Clustered Index Scan ще покажат, че посоката на сканирането, която SQL Server Engine предпочита да предприеме, е посоката на обратно сканиране, която в този случай е по-бърза, поради сортирането на данните, противоположно на реалното сортиране на клъстерирания индекс, като се има предвид, че индексът вече е сортиран във възходящ ред според колоната ID, както е показано по-долу:
Сравнение на производителността
Да приемем, че имаме следните оператори SELECT, които извличат информация за всички служители, които са били наети от 2010 г., два пъти; първия път върнатият набор от резултати ще бъде сортиран във възходящ ред според стойностите на колоната с идентификатор, а втория път върнатият набор от резултати ще бъде сортиран в низходящ ред според стойностите на колоната за идентификатор, като се използват T-SQL изразите по-долу:
SELECT [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] ,[Emp_EmploymentDate] ,[Emp_EmploymentDate] ,[Emp_Employment_Date] ,[Emp_EmploymentDate] ,[Emp_EmploymentSQue] . ] КЪДЕ Emp_EmploymentDate>='2010-01-01' ПОРЪЧАЙ ПО [ID] ASC ОПЦИЯ (MAXDOP 1) ИЗБЕРЕТЕ [ID] , [EmpID] , [Emp_First_Name] , [Emp_Last_Name] , [Emp_Last_Name] , [EmpDepID] , [EmpDepID] EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] ОТ [SQLShackDemo].[dbo].[CompanyEmployees] КЪДЕ Emp_EmploymentDate>='2010-01-01' ПОРЪЧАЙТЕ ПО [ID] ПРЕДВАРИТЕЛНА ОПЦИЯ1Проверявайки плановете за изпълнение, които се генерират чрез изпълнение на двете заявки SELECT, резултатът ще покаже, че ще бъде извършено сканиране на клъстерирания индекс в двете заявки за извличане на данните, но посоката на сканиране в първата заявка ще бъде напред Сканиране поради сортирането на данни ASC и сканиране назад във втората заявка поради използването на сортирането на данни DESC, за да замени необходимостта от повторно подреждане на данните, както е показано по-долу:
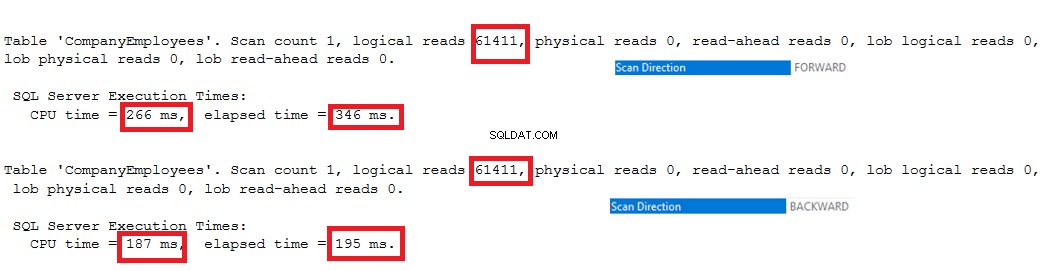
Освен това, ако проверим статистическите данни за изпълнение на IO и TIME на двете заявки, ще видим, че и двете заявки изпълняват едни и същи IO операции и консумират близки стойности на времето за изпълнение и CPU.
Тези стойности ни показват колко интелигентен е SQL Server Engine при избора на най-подходящата и най-бърза посока на сканиране на индекс за извличане на данни за потребителя, което е Сканиране напред в първия случай и Сканиране назад във втория случай, както става ясно от статистическите данни по-долу :
Нека отново да посетим предишния MAX пример. Да приемем, че трябва да извлечем максималния идентификационен номер на служителите, които са били наети през 2010 г. и по-късно. За това ще използваме следните оператори SELECT, които ще сортират прочетените данни според стойността на колоната ID с ASC сортиране в първата заявка и с сортиране по DESC във втората заявка:
ИЗБЕРЕТЕ MAX([Emp_EmploymentDate]) ОТ [SQLShackDemo].[dbo].[CompanyEmployees] КЪДЕ [Emp_EmploymentDate]>='2017-01-01' ГРУПИРАНЕ ПО ИД ПОРЪЧКА ПО [ID] ASC ОПЦИЯ 1) (MAXGODOP ИЗБЕРЕТЕ MAX([Emp_EmploymentDate]) ОТ [SQLShackDemo].[dbo].[CompanyEmployees] КЪДЕ [Emp_EmploymentDate]>='2017-01-01' ГРУПИРА ПО ИД ПОРЪЧКА ПО [ID] ОПЦИЯ НА ОПИСАНИЕ (MAXGODOP 1)>Ще видите от плановете за изпълнение, генерирани от изпълнението на двата оператора SELECT, че и двете заявки ще извършат операция на сканиране на клъстерирания индекс, за да извлекат максималната стойност на ID, но в различни посоки на сканиране; Сканиране напред в първата заявка и обратно сканиране във втората заявка, поради опциите за сортиране ASC и DESC, както е показано по-долу:
IO статистиката, генерирана от двете заявки, няма да показва разлика между двете посоки на сканиране. Но статистиката за ВРЕМЕТО показва голяма разлика между изчисляването на максималния идентификатор на редовете, когато тези редове се сканират от началото до края с помощта на метода за сканиране напред и сканирането му от края до началото с помощта на метода за обратно сканиране. От резултата по-долу става ясно, че методът за обратно сканиране е оптималният метод за сканиране за получаване на максимална стойност на ID:
Оптимизиране на производителността
Както споменах в началото на тази статия, индексирането на заявки е най-важният ключ в процеса на настройка и оптимизация на производителността. В предишната заявка, ако организираме добавяне на неклъстериран индекс към колоната EmploymentDate на таблицата CompanyEmployees, използвайки оператора CREATE INDEX T-SQL по-долу:
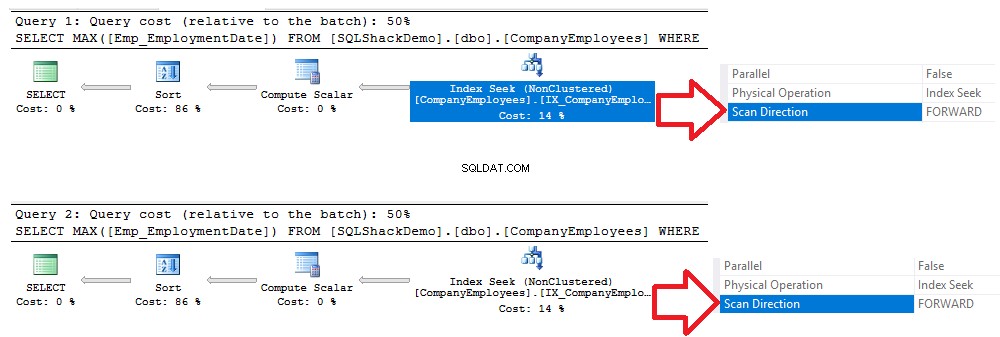
СЪЗДАВАНЕ НА НЕКЛУСТРИРАН ИНДЕКС IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate)След това ще изпълним същите предишни заявки, както е показано по-долу:SELECT MAX([Emp_EmploymentDate]) [Date_EmploymentDate]]] [Emp_EmploymentDate]. ='2017-01-01' ГРУПА ПО ИД ПОРЪЧАЙТЕ ПО [ID] ASC ОПЦИЯ (MAXDOP 1) ИЗБЕРЕТЕ MAX([Emp_EmploymentDate]) ОТ [SQLShackDemo].[dbo].[CompanyEmployees] КЪДЕ [Emp_EmploymentDate>='20] Date] -01-01' ГРУПА ПО ИД ПОРЪЧКА ПО [ID] ОПЦИЯ (MAXDOP 1) GOПроверявайки плановете за изпълнение, генерирани след изпълнение на двете заявки, ще видите, че ще бъде извършено търсене на новосъздадения неклъстериран индекс и двете заявки ще сканират индекса от началото до края, използвайки метода за сканиране напред, без необходимостта от извършване на сканиране назад, за да се ускори извличането на данни, въпреки че използвахме опцията за сортиране по DESC във втората заявка. Това се случи поради директно търсене на индекса, без да е необходимо да се извършва пълно сканиране на индекса, както е показано в сравнението на плановете за изпълнение по-долу:
Същият резултат може да бъде извлечен от статистическите данни за IO и TIME, генерирани от предишните две заявки, където двете заявки ще консумират същото количество време за изпълнение, CPU и IO операции, с много малка разлика, както е показано в статистическата моментна снимка по-долу :
Полезен инструмент:
dbForge Index Manager – удобна добавка за SSMS за анализиране на състоянието на SQL индексите и отстраняване на проблеми с фрагментацията на индекса.